在NLP领域,语义相似度的计算一直是个难题:搜索场景下query和Doc的语义相似度、feeds场景下Doc和Doc的语义相似度、机器翻译场景下A句子和B句子的语义相似度等等。本文通过介绍DSSM、CNN-DSSM、LSTM-DSSM等深度学习模型在计算语义相似度上的应用,希望给读者带来帮助。
1. 背景
以搜索引擎和搜索广告为例,最重要的也最难解决的问题是语义相似度,这里主要体现在两个方面:召回和排序。
在召回时,传统的文本相似性如 BM25,无法有效发现语义类 query-Doc 结果对,如"从北京到上海的机票"与"携程网"的相似性、"快递软件"与"菜鸟裹裹"的相似性。
在排序时,一些细微的语言变化往往带来巨大的语义变化,如"小宝宝生病怎么办"和"狗宝宝生病怎么办"、"深度学习"和"学习深度"。
DSSM(Deep Structured Semantic Models)为计算语义相似度提供了一种思路。
本文的最后,笔者结合自身业务,对 DSSM 的使用场景做了一些总结,不是所有的业务都适合用 DSSM。
2. DSSM
DSSM [1](Deep Structured Semantic Models)的原理很简单,通过搜索引擎里 Query 和 Title 的海量的点击曝光日志,用 DNN 把 Query 和 Title 表达为低纬语义向量,并通过 cosine 距离来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低纬语义向量表达。
DSSM 从下往上可以分为三层结构:输入层、表示层、匹配层
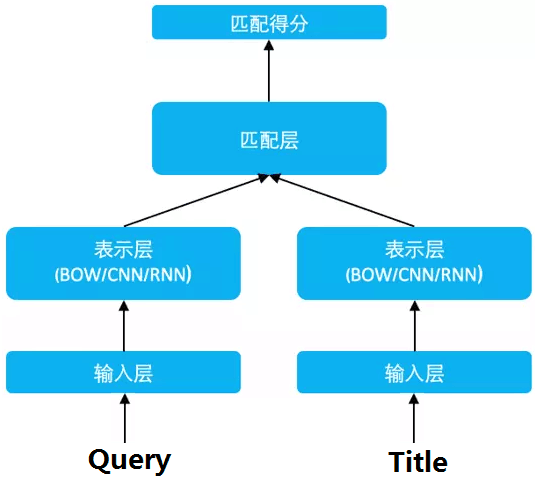
2.1 输入层
输入层做的事情是把句子映射到一个向量空间里并输入到 DNN 中,这里英文和中文的处理方式有很大的不同。
(1)英文
英文的输入层处理方式是通过word hashing。举个例子,假设用 letter-trigams 来切分单词(3 个字母为一组,#表示开始和结束符),boy 这个单词会被切为 #-b-o, b-o-y, o-y-#
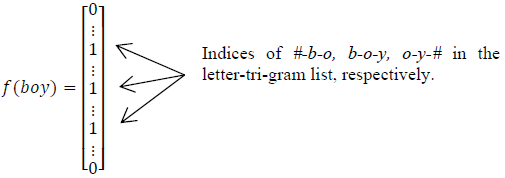
这样做的好处有两个:首先是压缩空间,50 万个词的 one-hot 向量空间可以通过 letter-trigram 压缩为一个 3 万维的向量空间。其次是增强范化能力,三个字母的表达往往能代表英文中的前缀和后缀,而前缀后缀往往具有通用的语义。
这里之所以用 3 个字母的切分粒度,是综合考虑了向量空间和单词冲突:
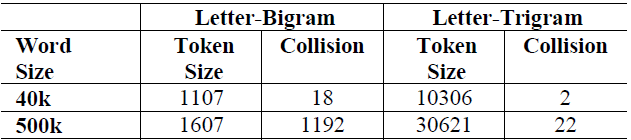
以 50 万个单词的词库为例,2 个字母的切分粒度的单词冲突为 1192(冲突的定义:至少有两个单词的 letter-bigram 向量完全相同),而 3 个字母的单词冲突降为 22 效果很好,且转化后的向量空间 3 万维不是很大,综合考虑选择 3 个字母的切分粒度。
(2)中文
中文的输入层处理方式与英文有很大不同,首先中文分词是个让所有 NLP 从业者头疼的事情,即便业界号称能做到 95%左右的分词准确性,但分词结果极为不可控,往往会在分词阶段引入误差。所以这里我们不分词,而是仿照英文的处理方式,对应到中文的最小粒度就是单字了。(曾经有人用偏旁部首切的,感兴趣的朋友可以试试)
由于常用的单字为 1.5 万左右,而常用的双字大约到百万级别了,所以这里出于向量空间的考虑,采用字向量(one-hot)作为输入,向量空间约为 1.5 万维。
2.2 表示层
DSSM 的表示层采用 BOW(Bag of words)的方式,相当于把字向量的位置信息抛弃了,整个句子里的词都放在一个袋子里了,不分先后顺序。当然这样做会有问题,我们先为 CNN-DSSM 和 LSTM-DSSM 埋下一个伏笔。
紧接着是一个含有多个隐层的 DNN,如下图所示:

用 Wi 表示第 i 层的权值矩阵,bi 表示第 i 层的 bias 项。则第一隐层向量 l1(300 维),第 i 个隐层向量 li(300 维),输出向量 y(128 维)可以分别表示为:
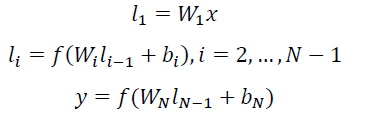
用 tanh 作为隐层和输出层的激活函数:

最终输出一个 128 维的低纬语义向量。
2.3 匹配层
Query 和 Doc 的语义相似性可以用这两个语义向量(128 维) 的 cosine 距离来表示:
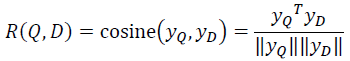
通过softmax 函数可以把Query 与正样本 Doc 的语义相似性转化为一个后验概率:
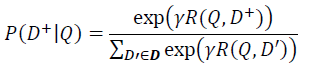
其中 r 为 softmax 的平滑因子,D 为 Query 下的正样本,D-为 Query 下的负样本(采取随机负采样),D 为 Query 下的整个样本空间。
在训练阶段,通过极大似然估计,我们最小化损失函数:

残差会在表示层的 DNN 中反向传播,最终通过随机梯度下降(SGD)使模型收敛,得到各网络层的参数{Wi,bi}。
2.4 优缺点
优点:DSSM 用字向量作为输入既可以减少切词的依赖,又可以提高模型的范化能力,因为每个汉字所能表达的语义是可以复用的。另一方面,传统的输入层是用 Embedding 的方式(如 Word2Vec 的词向量)或者主题模型的方式(如 LDA 的主题向量)来直接做词的映射,再把各个词的向量累加或者拼接起来,由于 Word2Vec 和 LDA 都是无监督的训练,这样会给整个模型引入误差,DSSM 采用统一的有监督训练,不需要在中间过程做无监督模型的映射,因此精准度会比较高。
缺点:上文提到 DSSM 采用词袋模型(BOW),因此丧失了语序信息和上下文信息。另一方面,DSSM 采用弱监督、端到端的模型,预测结果不可控。
3. CNN-DSSM
针对 DSSM 词袋模型丢失上下文信息的缺点,CLSM[2](convolutional latent semantic model)应运而生,又叫 CNN-DSSM。CNN-DSSM 与 DSSM 的区别主要在于输入层和表示层。
3.1 输入层
(1)英文
英文的处理方式,除了上文提到的 letter-trigram,CNN-DSSM 还在输入层增加了word-trigram
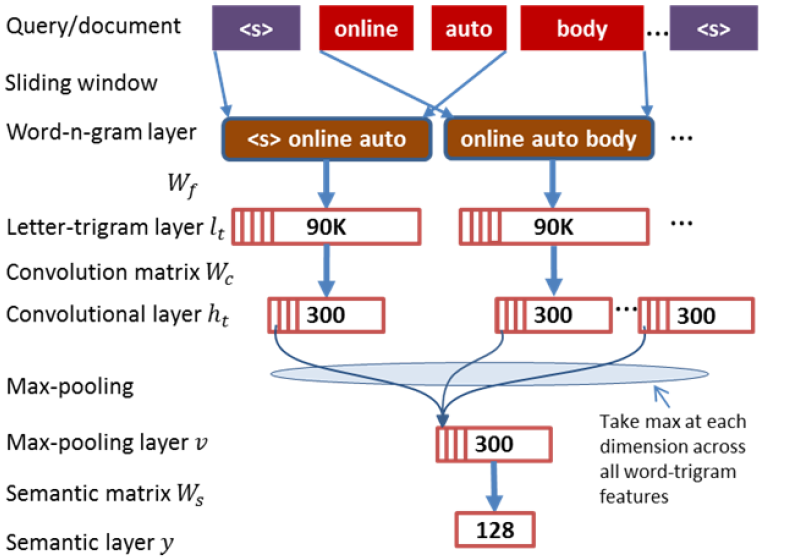
如上图所示,word-trigram其实就是一个包含了上下文信息的滑动窗口。举个例子:把<s> online auto body ... <s>这句话提取出前三个词<s> online auto,之后再分别对这三个词进行letter-trigram映射到一个 3 万维的向量空间里,然后把三个向量 concat 起来,最终映射到一个 9 万维的向量空间里。
(2)中文
英文的处理方式(word-trigram letter-trigram)在中文中并不可取,因为英文中虽然用了 word-ngram 把样本空间拉成了百万级,但是经过 letter-trigram 又把向量空间降到可控级别,只有 3*30K(9 万)。而中文如果用 word-trigram,那向量空间就是百万级的了,显然还是字向量(1.5 万维)比较可控。
3.2 表示层
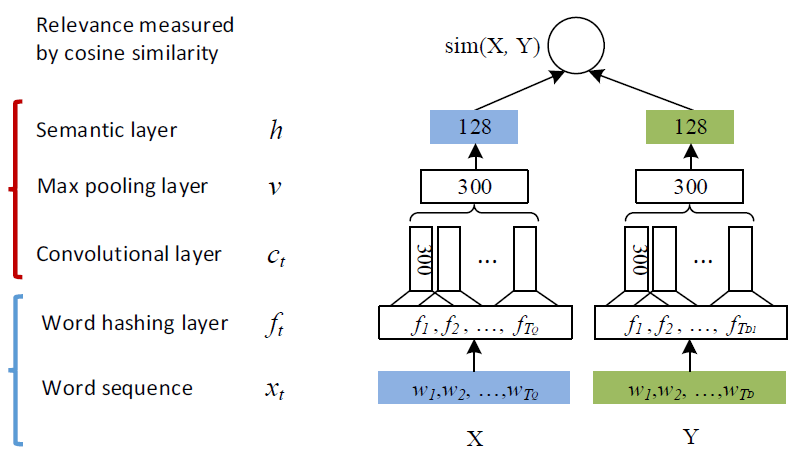
CNN-DSSM 的表示层由一个卷积神经网络组成,如下图所示:
(1)卷积层——Convolutional layer
卷积层的作用是提取滑动窗口下的上下文特征。以下图为例,假设输入层是一个 302*90000(302 行,9 万列)的矩阵,代表 302 个字向量(query 的和 Doc 的长度一般小于 300,这里少了就补全,多了就截断),每个字向量有 9 万维。而卷积核是一个 3*90000 的权值矩阵,卷积核以步长为 1 向下移动,得到的 feature map 是一个 300*1 的矩阵,feature map 的计算公式是(输入层维数 302-卷积核大小 3 步长 1)/步长 1=300。而这样的卷积核有 300 个,所以形成了 300 个 300*1 的 feature map 矩阵。
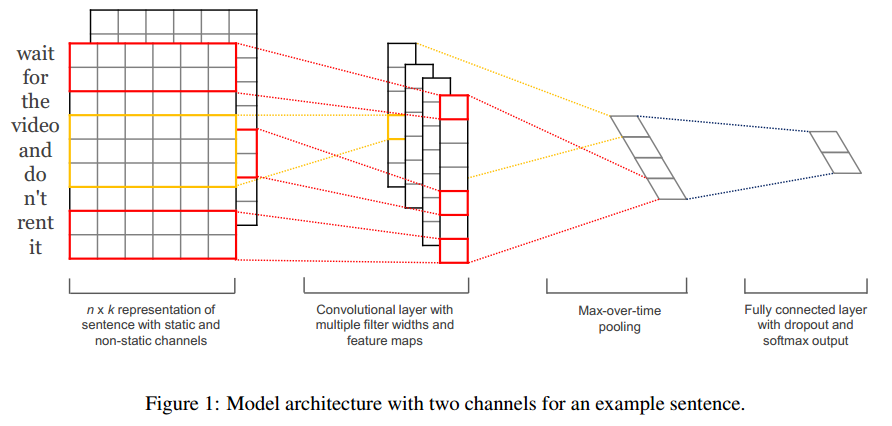
(2)池化层——Max pooling layer
池化层的作用是为句子找到全局的上下文特征。池化层以 Max-over-time pooling 的方式,每个 feature map 都取最大值,得到一个 300 维的向量。Max-over-pooling 可以解决可变长度的句子输入问题(因为不管 Feature Map 中有多少个值,只需要提取其中的最大值)。不过我们在上一步已经做了句子的定长处理(固定句子长度为 302),所以就没有可变长度句子的问题。最终池化层的输出为各个 Feature Map 的最大值,即一个 300*1 的向量。这里多提一句,之所以 Max pooling 层要保持固定的输出维度,是因为下一层全链接层要求有固定的输入层数,才能进行训练。
(3)全连接层——Semantic layer
最后通过全连接层把一个 300 维的向量转化为一个 128 维的低维语义向量。全连接层采用 tanh 函数:
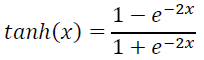
3.3 匹配层
CNN-DSSM 的匹配层和 DSSM 的一样,这里省略。
3.4 优缺点
优点:CNN-DSSM 通过卷积层提取了滑动窗口下的上下文信息,又通过池化层提取了全局的上下文信息,上下文信息得到较为有效的保留。
缺点:对于间隔较远的上下文信息,难以有效保留。举个例子,I grew up in France... I speak fluent French,显然 France 和 French 是具有上下文依赖关系的,但是由于 CNN-DSSM 滑动窗口(卷积核)大小的限制,导致无法捕获该上下文信息。
4. LSTM-DSSM
针对 CNN-DSSM 无法捕获较远距离上下文特征的缺点,有人提出了用LSTM-DSSM[3](Long-Short-Term Memory)来解决该问题。不过说 LSTM 之前,要先介绍它的"爸爸""RNN。
4.1 RNN
RNN(Recurrent Neural Networks)可以被看做是同一神经网络的多次复制,每个神经网络模块会把消息传递给下一个。如果我们将这个循环展开:
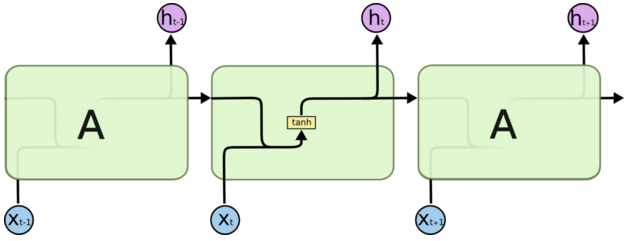
假设输入 xi 为一个 query 中几个连续的词,hi 为输出。那么上一个神经元的输出 h(t-1) 与当前细胞的输入 Xt 拼接后经过 tanh 函数会输出 ht,同时把 ht 传递给下一个细胞。
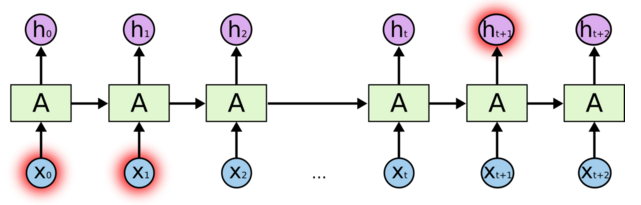
不幸的是,在这个间隔不断增大时,RNN 会逐渐丧失学习到远距离信息的能力。因为 RNN 随着距离的加长,会导致梯度消失。简单来说,由于求导的链式法则,直接导致梯度被表示为连乘的形式,以至梯度消失(几个小于 1 的数相乘会逐渐趋向于 0)。
4.2 LSTM
LSTM[4]((Long-Short-Term Memory)是一种 RNN 特殊的类型,可以学习长期依赖信息。我们分别来介绍它最重要的几个模块:
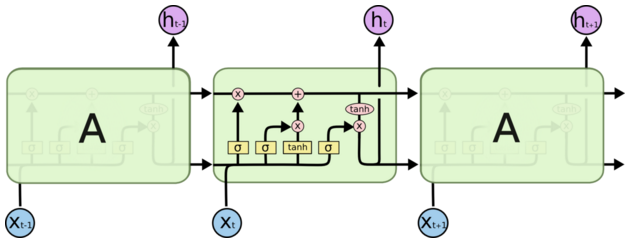
(0)细胞状态
细胞状态这条线可以理解成是一条信息的传送带,只有一些少量的线性交互。在上面流动可以保持信息的不变性。

(1)遗忘门
遗忘门 [5]由 Gers 提出,它用来控制细胞状态 cell 有哪些信息可以通过,继续往下传递。如下图所示,上一层的输出 h(t-1) concat 上本层的输入 xt,经过一个 sigmoid 网络(遗忘门)产生一个从 0 到 1 的数值 ft,然后与细胞状态 C(t-1) 相乘,最终决定有多少细胞状态可以继续往后传递。
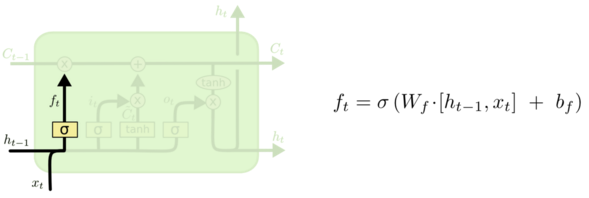
(2)输入门
输入门决定要新增什么信息到细胞状态,这里包含两部分:一个 sigmoid 输入门和一个 tanh 函数。sigmoid 决定输入的信号控制,tanh 决定输入什么内容。如下图所示,上一层的输出 h(t-1) concat 上本层的输入 xt,经过一个 sigmoid 网络(输入门)产生一个从 0 到 1 的数值 it,同样的信息经过 tanh 网络做非线性变换得到结果 Ct,sigmoid 的结果和 tanh 的结果相乘,最终决定有哪些信息可以输入到细胞状态里。
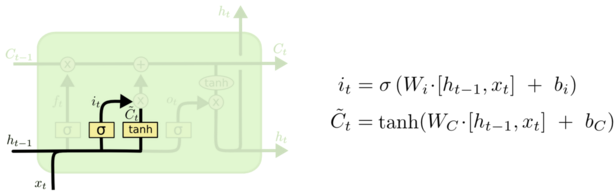
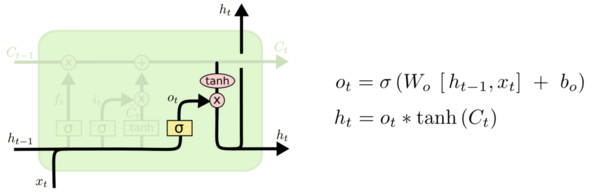
(3)输出门
输出门决定从细胞状态要输出什么信息,这里也包含两部分:一个 sigmoid 输出门和一个 tanh 函数。sigmoid 决定输出的信号控制,tanh 决定输出什么内容。如下图所示,上一层的输出 h(t-1) concat 上本层的输入 xt,经过一个 sigmoid 网络(输出门)产生一个从 0 到 1 的数值 Ot,细胞状态 Ct 经过 tanh 网络做非线性变换,得到结果再与 sigmoid 的结果 Ot 相乘,最终决定有哪些信息可以输出,输出的结果 ht 会作为这个细胞的输出,也会作为传递个下一个细胞。
4.2 LSTM-DSSM
LSTM-DSSM 其实用的是 LSTM 的一个变种——加入了peephole[6]的 LSTM。如下图所示:
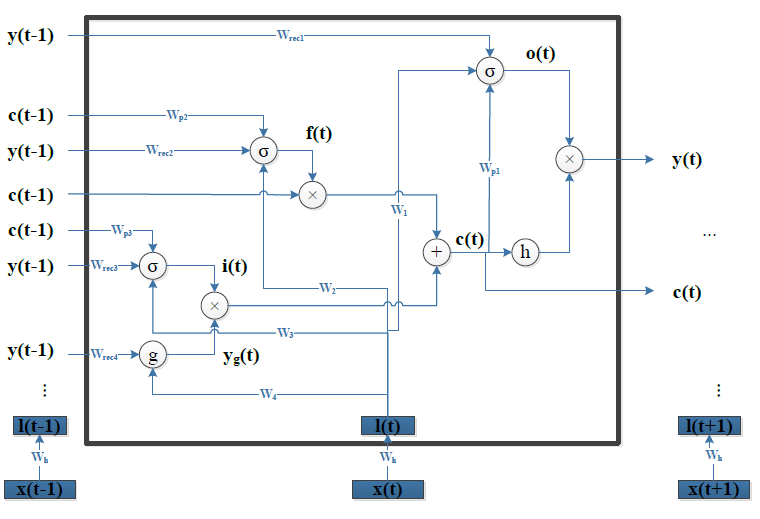
看起来有点复杂,我们换一个图,读者可以看的更清晰:

这里三条黑线就是所谓的 peephole,传统的 LSTM 中遗忘门、输入门和输出门只用了 h(t-1) 和 xt 来控制门缝的大小,peephole 的意思是说不但要考虑 h(t-1) 和 xt,也要考虑 Ct-1 和 Ct,其中遗忘门和输入门考虑了 Ct-1,而输出门考虑了 Ct。总体来说需要考虑的信息更丰富了。
好了,来看一个 LSTM-DSSM 整体的网络结构:
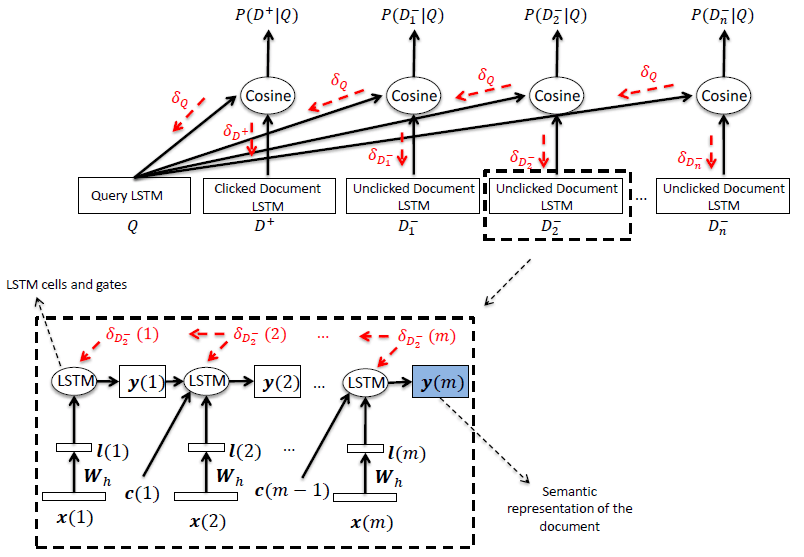
红色的部分可以清晰的看到残差传递的方向。
5. 后记
介绍完了 DSSM 及其几个变种,还要给读者泼点冷水,DSSM 就一定适合所有的业务吗?
这里列出 DSSM 的 2 个缺点以供参考:
1. DSSM 是端到端的模型,虽然省去了人工特征转化、特征工程和特征组合,但端到端的模型有个问题就是效果不可控。对于一些要保证较高的准确率的场景,用有监督人工标注的 query 分类作为打底,再结合无监督的 word2vec、LDA 等进行语义特征的向量化,显然比较可控(至少 query 分类的准确率可以达到 95%以上)。
2. DSSM 是弱监督模型,因为引擎的点击曝光日志里 Query 和 Title 的语义信息比较弱。举个例子,搜索引擎第一页的信息往往都是 Query 的包含匹配,笔者统计过,完全的语义匹配只有不到 2%。这就意味着几乎所有的标题里都包含用户 Query 里的关键词,而仅用点击和曝光就能作为正负样例的判断?显然不太靠谱,因为大部分的用户进行点击时越靠前的点击的概率越大,而引擎的排序又是由 pCTR、CVR、CPC 等多种因素决定的。从这种非常弱的信号里提取出语义的相似性或者差别,那就需要有海量的训练样本。DSSM 论文中提到,实验的训练样本超过 1 亿。笔者和同事也亲测过,用传统 CTR 预估模型千万级的样本量来训练,模型无法收敛。可是这样海量的训练样本,恐怕只有搜索引擎才有吧?普通的搜索业务 query 有上千万,可资源顶多只有几百万,像论文中说需要挑出点击和曝光置信度比较高且资源热度也比较高的作为训练样本,这样就过滤了 80%的长尾 query 和 Title 结果对,所以也只有搜索引擎才有这样的训练语料了吧。另一方面,超过 1 亿的训练样本作为输入,用深度学习模型做训练,需要大型的 GPU 集群,这个对于很多业务来说也是不具备的条件。
NLP 语义相似度计算 整理总结
更新中
更新时间:
2019-12-03 18:29:52
写在前面:
本人是喜欢这个方向的学生一枚,写文的目的意在记录自己所学,梳理自己的思路,同时share给在这个方向上一起努力的同学。写得不够专业的地方望批评指正,欢迎感兴趣的同学一起交流进步。
(参考文献在第四部分,侵删)
一、背景
二、基本概念
三、语义相似度计算方法
四、参考文献
一、背景
在很多NLP任务中,都涉及到语义相似度的计算,例如:
在搜索场景下(对话系统、问答系统、推理等),query和Doc的语义相似度;
feeds场景下Doc和Doc的语义相似度;
在各种分类任务,翻译场景下,都会涉及到语义相似度语义相似度的计算。
所以在学习的过程中,希望能够更系统的梳理一下这方面的方法。
二、基本概念
1. TF
Term frequency即关键词词频,是指一篇文章中关键词出现的频率,比如在一篇M个词的文章中有N个该关键词,则

为该关键词在这篇文章中的词频。
2. IDF
Inverse document frequency指逆向文本频率,是用于衡量关键词权重的指数,由公式

计算而得,其中D为文章总数,Dw为关键词出现过的文章数。
3. 向量空间模型
向量空间模型简称 VSM,是 VectorSpace Model 的缩写。在此模型中,文本被看作是由一系列相互独立的词语组成的,若文档 D 中包含词语 t1,t2,…,tN,则文档表示为D(t1,t2,…,tN)。由于文档中词语对文档的重要程度不同,并且词语的重要程度对文本相似度的计算有很大的影响,因而可对文档中的每个词语赋以一个权值 w,以表示该词的权重,其表示如下:D(t1,w1;t2,w2;…,tN,wN),可简记为 D(w1,w2,…,wN),此时的 wk 即为词语 tk的权重,1≤k≤N。关于权重的设置,我们可以考虑的方面:词语在文本中的出现频率(tf),词语的文档频率(df,即含有该词的文档数量,log N/n。很多相似性计算方法都是基于向量空间模型的。
三、语义相似度计算方法
1. 余弦相似度(Cosine)
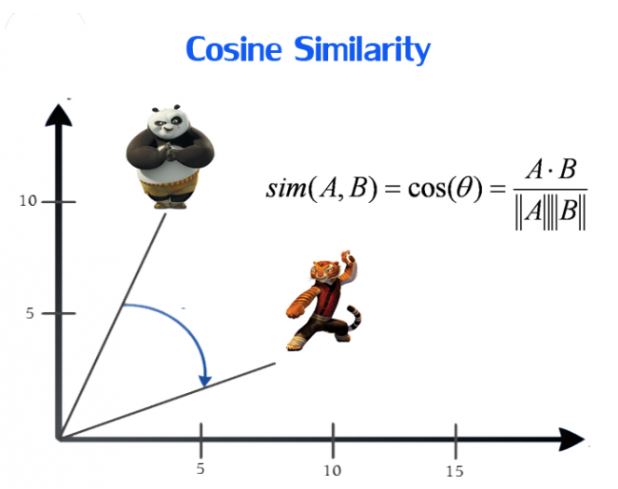
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。
两个向量间的余弦值可以通过使用欧几里得点积公式求出:

余弦相似性θ由点积和向量长度给出,如下所示(例如,向量A和向量B):

这里的 分别代表向量A和B的各分量。
分别代表向量A和B的各分量。
问题:表示方向上的差异,但对距离不敏感。
关心距离上的差异时,会对计算出的每个(相似度)值都减去一个它们的均值,称为调整余弦相似度。
代码:

2. 欧式距离
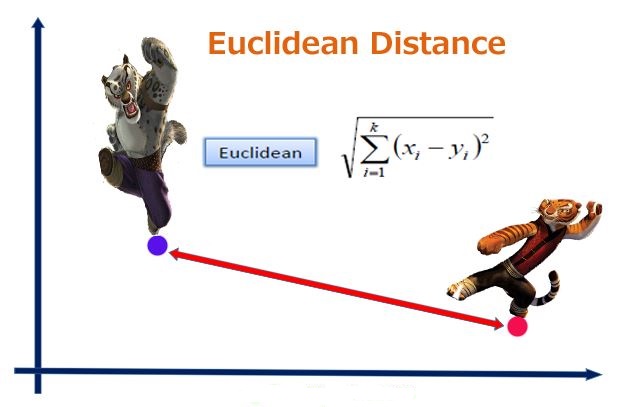

考虑的是点的空间距离,各对应元素做差取平方求和后开方。能体现数值的绝对差异。
代码:

3. 曼哈顿距离(Manhattan Distance)
d(i,j)=|X1-X2|+|Y1-Y2|.
向量各坐标的绝对值做查后求和。
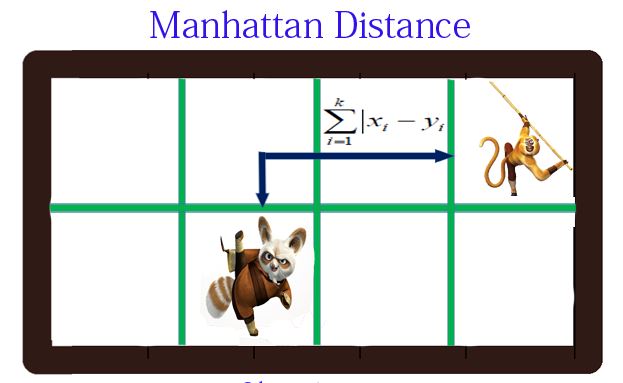
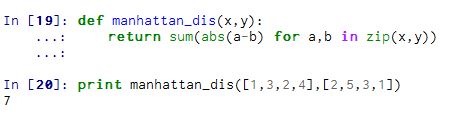
代码:
4. 明可夫斯基距离(Minkowski distance)
明氏距离是欧氏距离的推广,是对多个距离度量公式的概括性的表述。
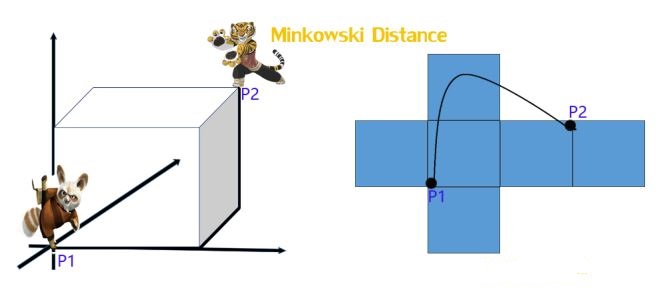
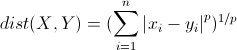
- 当p==1,“明可夫斯基距离”变成“曼哈顿距离”
- 当p==2,“明可夫斯基距离”变成“欧几里得距离”
- 当p==∞,“明可夫斯基距离”变成“切比雪夫距离”
代码:

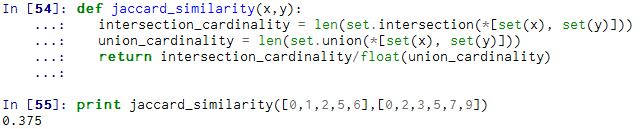
5. Jaccard 相似系数(Jaccard Coefficient)

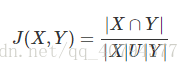
Jaccard系数主要用于计算符号度量或布尔值度量的向量的相似性。即,无需比较差异大小,只关注是否相同。Jaccard系数只关心特征是否一致(共有特征的比例)。
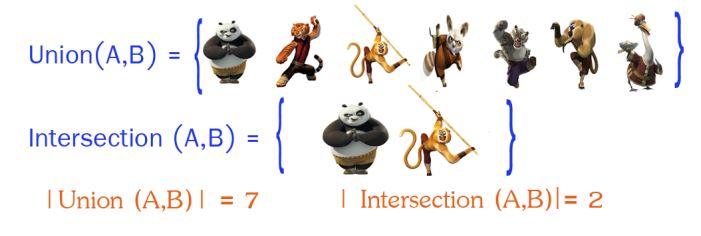
然后利用公式进行计算:

代码:
6. 皮尔森相关系数(Pearson Correlation Coefficient)
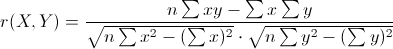
又称为相关相似性。
或表示为:
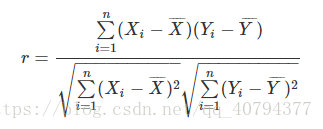
这就是1中所提到的调整余弦相似度,向量内各对应元素减去均值求积后求和,记为结果1;各对应元素减去均值平方求和再求积,记为结果2;结果1比结果2。
针对线性相关情况,可用于比较因变量和自变量间相关性如何。
7. SimHash + 汉明距离(Hamming Distance)
Simhash:谷歌发明,根据文本转为64位的字节,计算汉明距离判断相似性。
汉明距离:在信息论中,两个等长字符串的汉明距离是两者间对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:
“10110110”和“10011111”的汉明距离为3; “abcde”和“adcaf”的汉明距离为3.
8. 斯皮尔曼(等级)相关系数(SRC :Spearman Rank Correlation)
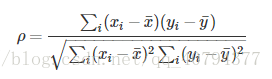
和6上述类似,不同的是将对于样本中的原始数据Xi,Yi转换成等级数据xi,yi,即xi等级和yi等级。并非考虑原始数据值,而是按照一定方式(通常按照大小)对数据进行排名,取数据的不同排名结果代入公式。
实际上,可通过简单的方式进行计算,n表示样本容量,di表示两向量X和Y内对应元素的等级的差值,等级di = xi - yi,则:
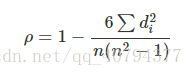
例如( 维基百科):
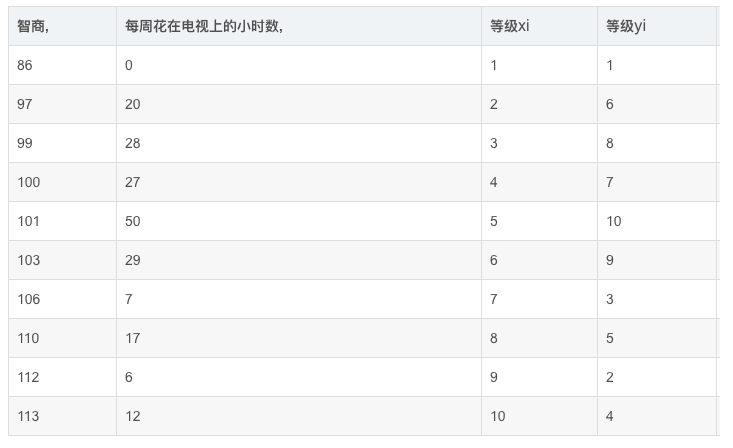
n = 10,di2的和为194,则可代入公式计算出结果为:-0.17575757...,Xi和Yi几乎不相关。
9. BM25算法
原理
BM25算法,通常用来作搜索相关性平分:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法的一般性公式如下:
其中,Q表示Query,qi表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi。);d表示一个搜索结果文档;Wi表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。
定义Wi:
判断一个词与一个文档的相关性的权重,方法有多种,较常用的是IDF。这里以IDF为例,公式如下:
其中,N为索引中的全部文档数,n(qi)为包含了qi的文档数。
根据IDF的定义可以看出,对于给定的文档集合,包含了qi的文档数越多,qi的权重则越低。也就是说,当很多文档都包含了qi时,qi的区分度就不高,因此使用qi来判断相关性时的重要度就较低。
我们再来看语素qi与文档d的相关性得分R(qi,d)。
BM25中相关性得分的一般形式:
其中,k1,k2,b为调节因子,通常根据经验设置,一般k1=2,b=0.75;fi为qi在d中的出现频率,qfi为qi在Query中的出现频率。dl为文档d的长度,avgdl为所有文档的平均长度。由于绝大部分情况下,qi在Query中只会出现一次,即qfi=1,因此公式可以简化为:
从K的定义中可以看到,参数b的作用是调整文档长度对相关性影响的大小。b越大,文档长度的对相关性得分的影响越大,反之越小。而文档的相对长度越长,K值将越大,则相关性得分会越小。这可以理解为,当文档较长时,包含qi的机会越大,因此,同等fi的情况下,长文档与qi的相关性应该比短文档与qi的相关性弱。
综上,BM25算法的相关性得分公式可总结为:
从BM25的公式可以看到,通过使用不同的语素分析方法、语素权重判定方法,以及语素与文档的相关性判定方法,我们可以衍生出不同的搜索相关性得分计算方法,这就为我们设计算法提供了较大的灵活性。
代码实现:

1 import math2 import jieba3 from utils import utils4 5 # 测试文本6 text = '''7 自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。8 它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。9 自然语言处理是一门融语言学、计算机科学、数学于一体的科学。
10 因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,
11 所以它与语言学的研究有着密切的联系,但又有重要的区别。
12 自然语言处理并不是一般地研究自然语言,
13 而在于研制能有效地实现自然语言通信的计算机系统,
14 特别是其中的软件系统。因而它是计算机科学的一部分。
15 '''
16
17 class BM25(object):
18
19 def __init__(self, docs):
20 self.D = len(docs)
21 self.avgdl = sum([len(doc)+0.0 for doc in docs]) / self.D
22 self.docs = docs
23 self.f = [] # 列表的每一个元素是一个dict,dict存储着一个文档中每个词的出现次数
24 self.df = {} # 存储每个词及出现了该词的文档数量
25 self.idf = {} # 存储每个词的idf值
26 self.k1 = 1.5
27 self.b = 0.75
28 self.init()
29
30 def init(self):
31 for doc in self.docs:
32 tmp = {}
33 for word in doc:
34 tmp[word] = tmp.get(word, 0) + 1 # 存储每个文档中每个词的出现次数
35 self.f.append(tmp)
36 for k in tmp.keys():
37 self.df[k] = self.df.get(k, 0) + 1
38 for k, v in self.df.items():
39 self.idf[k] = math.log(self.D-v+0.5)-math.log(v+0.5)
40
41 def sim(self, doc, index):
42 score = 0
43 for word in doc:
44 if word not in self.f[index]:
45 continue
46 d = len(self.docs[index])
47 score += (self.idf[word]*self.f[index][word]*(self.k1+1)
48 / (self.f[index][word]+self.k1*(1-self.b+self.b*d
49 / self.avgdl)))
50 return score
51
52 def simall(self, doc):
53 scores = []
54 for index in range(self.D):
55 score = self.sim(doc, index)
56 scores.append(score)
57 return scores
58
59 if __name__ == '__main__':
60 sents = utils.get_sentences(text)
61 doc = []
62 for sent in sents:
63 words = list(jieba.cut(sent))
64 words = utils.filter_stop(words)
65 doc.append(words)
66 print(doc)
67 s = BM25(doc)
68 print(s.f)
69 print(s.idf)
70 print(s.simall(['自然语言', '计算机科学', '领域', '人工智能', '领域']))
分段再分词结果:
[['自然语言', '计算机科学', '领域', '人工智能', '领域', '中', '一个', '方向'],
['研究', '人', '计算机', '之间', '自然语言', '通信', '理论', '方法'],
['自然语言', '一门', '融', '语言学', '计算机科学', '数学', '一体', '科学'],
[],
['这一', '领域', '研究', '涉及', '自然语言'],
['日常', '语言'],
['语言学', '研究'],
['区别'],
['自然语言', '研究', '自然语言'],
['在于', '研制', '自然语言', '通信', '计算机系统'],
['特别', '软件系统'],
['计算机科学', '一部分']]
s.f
列表的每一个元素是一个dict,dict存储着一个文档中每个词的出现次数
[{'中': 1, '计算机科学': 1, '领域': 2, '一个': 1, '人工智能': 1, '方向': 1, '自然语言': 1},
{'之间': 1, '方法': 1, '理论': 1, '通信': 1, '计算机': 1, '人': 1, '研究': 1, '自然语言': 1},
{'融': 1, '一门': 1, '一体': 1, '数学': 1, '科学': 1, '计算机科学': 1, '语言学': 1, '自然语言': 1},
{},
{'领域': 1, '这一': 1, '涉及': 1, '研究': 1, '自然语言': 1},
{'日常': 1, '语言': 1},
{'语言学': 1, '研究': 1},
{'区别': 1},
{'研究': 1, '自然语言': 2},
{'通信': 1, '计算机系统': 1, '研制': 1, '在于': 1, '自然语言': 1},
{'软件系统': 1, '特别': 1},
{'一部分': 1, '计算机科学': 1}]
s.df
存储每个词及出现了该词的文档数量
{'在于': 1, '人工智能': 1, '语言': 1, '领域': 2, '融': 1, '日常': 1, '人': 1, '这一': 1, '软件系统': 1, '特别': 1, '数学': 1, '通信': 2, '区别': 1, '之间': 1, '计算机科学': 3, '科学': 1, '一体': 1, '方向': 1, '中': 1, '理论': 1, '计算机': 1, '涉及': 1, '研制': 1, '一门': 1, '研究': 4, '语言学': 2, '计算机系统': 1, '自然语言': 6, '一部分': 1, '一个': 1, '方法': 1
s.idf
存储每个词的idf值
{'在于': 2.0368819272610397, '一部分': 2.0368819272610397, '一个': 2.0368819272610397, '语言': 2.0368819272610397, '领域': 1.4350845252893225, '融': 2.0368819272610397, '日常': 2.0368819272610397, '人': 2.0368819272610397, '这一': 2.0368819272610397, '软件系统': 2.0368819272610397, '特别': 2.0368819272610397, '数学': 2.0368819272610397, '通信': 1.4350845252893225, '区别': 2.0368819272610397, '之间': 2.0368819272610397, '一门': 2.0368819272610397, '科学': 2.0368819272610397, '一体': 2.0368819272610397, '方向': 2.0368819272610397, '中': 2.0368819272610397, '理论': 2.0368819272610397, '计算机': 2.0368819272610397, '涉及': 2.0368819272610397, '研制': 2.0368819272610397, '计算机科学': 0.9985288301111273, '研究': 0.6359887667199966, '语言学': 1.4350845252893225, '计算机系统': 2.0368819272610397, '自然语言': 0.0, '人工智能': 2.0368819272610397, '方法': 2.0368819272610397
s.simall(['自然语言', '计算机科学', '领域', '人工智能', '领域'])
['自然语言', '计算机科学', '领域', '人工智能', '领域']与每一句的相似度
[5.0769919814311475, 0.0, 0.6705449078118518, 0, 2.5244316697250033, 0, 0, 0, 0.0, 0.0, 0, 1.2723636062357853]
详细代码
TODO:
Dice 系数法(DiceCoefficient)
最新的:百度报告会中的分享:RBF MM GMM GMM核函数的应用场景?
在目录中添加每个方法
BM25算法的优缺点
四、参考文献
深度学习解决NLP问题:语义相似度计算
自然语言语义相似度计算方法
余弦相似度
常用的相似度计算方法原理及实现
文本相似度算法
文本相似度-bm25算法原理及实现










)





)







)

)