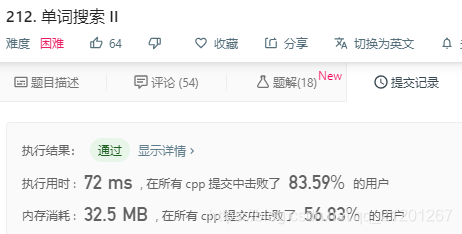
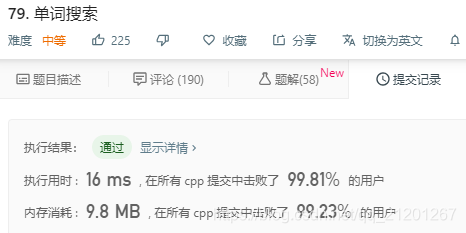
文 | 陈萍、杜伟
源 | 机器之心
CNN 通过堆叠更多的卷积层来提高性能,而 transformer 在层次更深时会很快进入饱和。基于此,来自新加坡国立大学和字节跳动 AI Lab 的研究者引入了 Re-attention 机制,以很小的计算代价重新生成注意力图以增强各层之间的多样性。提出的 DeepViT 模型也实现了非常不错的性能。
视觉 transformer (ViT) 现已成功地应用于图像分类任务。近日,来自新加坡国立大学和字节跳动美国 AI Lab 的研究者表明,不同于卷积神经网络通过堆叠更多的卷积层来提高性能,ViT 的性能在扩展至更深时会迅速饱和。
他们是如何得出这一结论的呢?
具体而言,研究者根据经验观察到,这种扩展困难是由注意力崩溃(attention collapse)引起的:随着 Transformer 加深,注意力图在某些层之后逐渐变得相似甚至几乎相同。换句话说,在 deep ViT 模型的顶层中,特征图趋于相同。这一事实表明,在更深层的 ViT 中,自注意力机制无法学习有效的表征学习概念,并且阻碍了模型获得预期的性能提升。
基于以上观察,研究者提出了一种简单而有效的方法 Re-attention,它可以忽略计算和存储成本重新生成注意力图以增加其在不同层的多样性。借助于该方法,我们可以通过对现有 ViT 模型的微小修改来训练具有持续性能改进的更深的 ViT 模型。此外,当使用 32 个 transformer 块训练 DeepViT 模型时,在 ImageNet 数据集上实现了颇具竞争力的 Top-1 图像分类准确率。相较于 ViT-32B, 变体模型 DeepViT-32B 的 Top-1 准确率提升了 1.6%。

论文链接:
https://arxiv.org/pdf/2103.11886.pdf
 ViT 模型
ViT 模型
如下图 2 所示,ViT 模型由三部分组成:用于 patch 嵌入的线性层、具有多头自注意力和特征编码前馈层的 transformer 块、以及用于分类得分预测的线性层。研究者首先回顾了 transformer 块的独特性,特别是自注意力机制,然后研究了自注意力的崩溃问题。

具有 N 个 transformer 块的原版 ViT 模型与该研究所提 DeepViT 模型的结构对比。
注意力崩溃
受深度 CNN 成功的启发,研究者对 ViT 随深度的增加带来的性能改变进行了系统的研究。在不失一般性的情况下,他们首先将隐藏维数和注意力头数分别固定为 384 和 12,然后堆叠不同数量的 transformer 块(数量从 12 到 32),以建立对应不同深度的多个 ViT 模型。在 ImageNet 数据集上,原版 ViT 和 DeepViT 的图像分类 Top-1 准确率变化曲线如下图 1 所示:

结果表明,随着模型深度的增加,分类准确率提升缓慢,饱和速度加快。更具体地说,在采用 24 个 transformer 块时,性能停止提升。这种现象表明,现有的 ViT 很难在更深的架构中提高性能。
为了衡量注意力图在不同层上的改变,研究者计算了来自不同层的注意力图之间的跨层相似性:

其中 和四个因素有关:p 和 q 是两个不同的层、h 是注意力头、t 是具体的输入,结果如下图 3 所示。图(a)表明了随着深度的增加,注意力图和 k 个附近块的注意力图越来越相似;图(c)表明了即使到了第 32 个 block,同层注意力头之间的相似度还是比较低的,这说明主要的相似还是层之间的相似。
和四个因素有关:p 和 q 是两个不同的层、h 是注意力头、t 是具体的输入,结果如下图 3 所示。图(a)表明了随着深度的增加,注意力图和 k 个附近块的注意力图越来越相似;图(c)表明了即使到了第 32 个 block,同层注意力头之间的相似度还是比较低的,这说明主要的相似还是层之间的相似。

为了了解注意力崩溃如何影响 ViT 模型的性能,研究者进一步探索了它是如何影响更深层次的特征学习。对于特定的 32 块 ViT 模型,通过研究它们的余弦相似性,将最终输出特征与每个中间 transformer 块的输出进行比较。
下图 4 中的结果表明:特征图与注意力图相似性非常高,并且学习的特征在第 20 个块之后停止变化。注意力相似度的增加与特征相似度之间存在着密切的相关性。这一观察表明注意力崩溃是 ViT 不可扩展的原因。

 DeepViT 中的 Re-attention
DeepViT 中的 Re-attention
如上所述,将 ViT 扩展到更深层的一个主要障碍是注意力崩溃问题。因此,研究者提出了两种解决方法,一种是增加计算自注意力的隐藏维度,另一种是新的 re-attention 机制。
高维空间中的自注意力
克服注意力崩溃的一个解决方案是增加每个 token 的嵌入维度,这将提升每个 token 嵌入的表征能力,以编码更多信息。因此,所得到的注意力图更具多样性,降低每个块注意力图之间的相似性。在不丧失一般性的前提下,该研究通过一组基于 ViT 模型的实验验证了这种方法,其中有 12 个块用于快速实验。根据先前基于 transformer 的工作,研究者选择了四个嵌入维度,范围从 256 到 768。详细配置结果如下表所示:

下图 5 展示了嵌入维数对生成的跨层自注意力图相似性的影响。可见,随着嵌入维数的增加,相似注意力图的数目减少。然而,模型尺寸也迅速增加。

Re-attention
上文证明了在高维、尤其在深层网络中,不同 transformer 块之间注意力图存在相似性。然而,研究者发现同一 transformer 块不同 head 的注意力图相似性相当小,如上图 3(c) 所示。显然,来自同一自注意力层的不同 head 关注输入 token 的不同方面。基于这一观察,研究者建议建立 cross-head 通信来重新生成注意力图,训练 deep ViT 性能会更好。
具体而言,该研究以 head 的注意力图为基础,通过动态地聚合它们来生成一组新的注意力图。采用一个变换矩阵和 multi-head attention maps 相乘来得到新的 map,这个变换矩阵是可学习的。公式如下:

 实验
实验
在实验部分,研究者首先通过实验进一步证明注意力崩溃问题,然后通过大量的控制变量实验来证明 Re-attention 方法的优势。该研究通过将 Re-attention 融入到 transformer 中,设计了两个改进版 ViT,并命名为 DeepViT。最后将 DeepViT 与具有 SOTA 性能的模型进行了比较。
注意力崩溃分析
当模型越深时,越深区块的注意力图就越相似。这意味着在 deep ViT 模型上添加更多的块可能不会提高模型性能。为了进一步验证这一说法,研究者设计了一个实验,以重用在 ViT 早期块上计算的注意力图并替换它之后的注意力图。结果如下表 3 所示:

Re-attention 机制
Re-attention 与 Self-attention 对比。研究者首先评估了 Re-attention 有效性,直接将 ViT 中的 self-attention 替换为 Re-attention 模块。下表 4 展示了在 ImageNet 数据集上,不用数量 transformer 块时的 Top-1 准确率对比:

与 SOTA 模型对比
研究者在 Re-attention 基础上设计了两个 ViT 变体,即 DeepViT-S 与 DeepViT-L,两个变体分别具有 16 和 32 个 transformer 块。对于这两个模型,Re-attention 均替代 self-attention。
为了得到和其他 ViT 模型相似的参数量,研究者相应地调整了嵌入维度,结果如下表 6 所示:DeepViT 模型在参数量更少的情况下实现了比最近 CNN 和 ViT 模型更好的 Top-1 准确率。

寻求报道、约稿、文案投放:
添加微信xixiaoyao-1,备注“商务合作”
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!