
1 图像分割
所谓图像分割指的是根据灰度、颜色、纹理和形状等特征把图像划分成若干互不交迭的区域,并使这些特征在同一区域内呈现出相似性,而在不同区域间呈现出明显的差异性。我们先对目前主要的图像分割方法做个概述,后面再对个别方法做详细的了解和学习。
1、基于阈值的分割方法
阈值法的基本思想是基于图像的灰度特征来计算一个或多个灰度阈值,并将图像中每个像素的灰度值与阈值相比较,最后将像素根据比较结果分到合适的类别中。因此,该类方法最为关键的一步就是按照某个准则函数来求解最佳灰度阈值。
2、基于边缘的分割方法
所谓边缘是指图像中两个不同区域的边界线上连续的像素点的集合,是图像局部特征不连续性的反映,体现了灰度、颜色、纹理等图像特性的突变。通常情况下,基于边缘的分割方法指的是基于灰度值的边缘检测,它是建立在边缘灰度值会呈现出阶跃型或屋顶型变化这一观测基础上的方法。
3、基于区域的分割方法
此类方法是将图像按照相似性准则分成不同的区域,主要包括种子区域生长法、区域分裂合并法和分水岭法等几种类型。
3.1种子区域生长法是从一组代表不同生长区域的种子像素开始,接下来将种子像素邻域里符合条件的像素合并到种子像素所代表的生长区域中,并将新添加的像素作为新的种子像素继续合并过程,直到找不到符合条件的新像素为止。该方法的关键是选择合适的初始种子像素以及合理的生长准则。
3.2区域分裂合并法(Gonzalez,2002)的基本思想是首先将图像任意分成若干互不相交的区域,然后再按照相关准则对这些区域进行分裂或者合并从而完成分割任务,该方法既适用于灰度图像分割也适用于纹理图像分割。
3.3分水岭法(Meyer,1990)是一种基于拓扑理论的数学形态学的分割方法,其基本思想是把图像看作是测地学上的拓扑地貌,图像中每一点像素的灰度值表示该点的海拔高度,每一个局部极小值及其影响区域称为集水盆,而集水盆的边界则形成分水岭。该算法的实现可以模拟成洪水淹没的过程,图像的最低点首先被淹没,然后水逐渐淹没整个山谷。当水位到达一定高度的时候将会溢出,这时在水溢出的地方修建堤坝,重复这个过程直到整个图像上的点全部被淹没,这时所建立的一系列堤坝就成为分开各个盆地的分水岭。分水岭算法对微弱的边缘有着良好的响应,但图像中的噪声会使分水岭算法产生过分割的现象。
4、基于图论的分割方法
此类方法把图像分割问题与图的最小割(min cut)问题相关联。首先将图像映射为带权无向图G=,图中每个节点N∈V对应于图像中的每个像素,每条边∈E连接着一对相邻的像素,边的权值表示了相邻像素之间在灰度、颜色或纹理方面的非负相似度。而对图像的一个分割s就是对图的一个剪切,被分割的每个区域C∈S对应着图中的一个子图。而分割的最优原则就是使划分后的子图在内部保持相似度最大,而子图之间的相似度保持最小。基于图论的分割方法的本质就是移除特定的边,将图划分为若干子图从而实现分割。目前所了解到的基于图论的方法有GraphCut,GrabCut和Random Walk等。
2 阈值分割
图像阈值分割是一种传统的最常用的图像分割方法,因其实现简单、计算量小、性能较稳定而成为图像分割中最基本和应用最广泛的分割技术。它特别适用于目标和背景占据不同灰度级范围的图像。它不仅可以极大的压缩数据量,而且也大大简化了分析和处理步骤,因此在很多情况下,是进行图像分析、特征提取与模式识别之前的必要的图像预处理过程。
图像阈值的目的是要按照灰度级,对像素集合进行一个划分,得到的每个子集形成一个与现实景物相对应的区域,各个区域内部具有一致的属性,而相邻区域不具有这种一致属性。这样的划分可以通过从灰度级出发选取一个或多个阈值来实现。
2.1 全阈值分割
全阈值分割指将灰度值大于thresh(阈值)的像素设为一种颜色,小于或等于阈值的像素设为另外一种颜色,那在OPenCV中实现全阈值分割使用的API 是:
ret,th = threshold(src, thresh, maxval, type)
参数:
-
src: 要处理的图像,一般是灰度图
-
thresh: 设定的阈值
-
maxval: 灰度中的最大值,一般为255,用来指明阈值分割中最大值的取值,主要指阈值二值化和阈值反二值化中
-
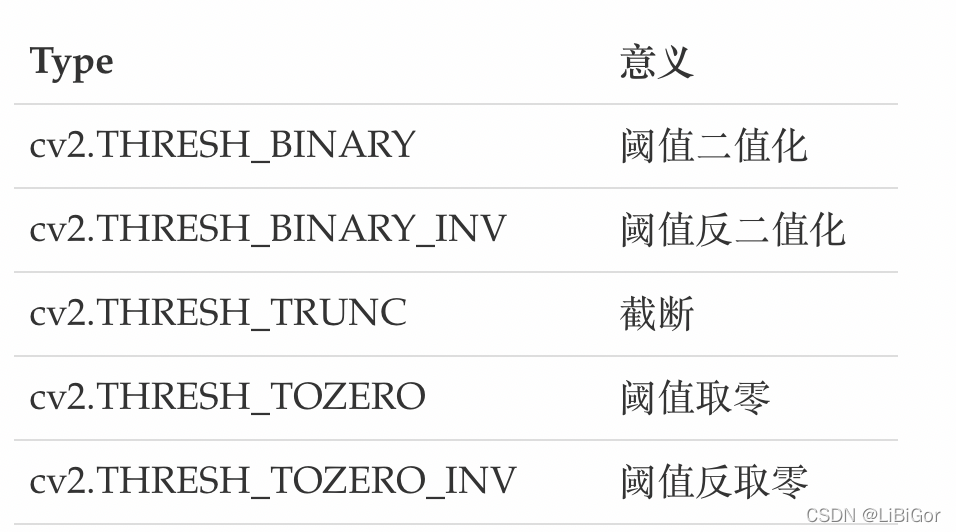
type:阈值分割的方式,取值主要有以下五种:
-
返回:
- ret: return value 的缩写,代表当前的阈值
- th: 阈值分割后的结果
下面我们看下各个分割方式的表现形式:
-
阈值二值化(threshold binary)
红色部分是当前图像的灰度值,蓝色线对应值为选定的阈值。所有像素值小于这一值的设定为0,否则设定为最大值1。

-
阈值反二值化 (threshold binary Inverted)
红色部分是当前图像的灰度值,蓝色线对应值为选定的阈值。所有像素值小于这一值的设定为1,否则设定为0。
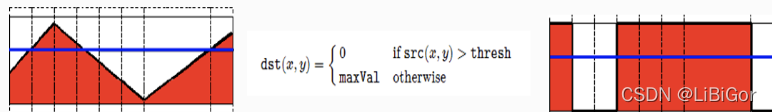
-
截断(truncate)
像素值大于阈值的就设定为阈值大小,否则保持原有的灰度值不变。

-
阈值取零(threshold to zero)
像素值小于阈值的全部设为0,大于的保持不变。

-
阈值反取零(threshold to zero inverted)
像素值大于阈值的全部设为0,小于的保持不变。

在opencv中进行阈值分割实例如下所示:
import cv2 as cv
import matplotlib.pyplot as plt# 1.读取图像
img = cv.imread('./img/p1.png', 0)
# 2. 阈值分割 threshold(要处理的图像,一般是灰度图, 设定的阈值, 灰度中的最大值, 阈值分割的方式)
# 阈值二值化
ret, th1 = cv.threshold(img, 127, 255, cv.THRESH_BINARY)
# 阈值反二值化
ret, th2 = cv.threshold(img, 127, 255, cv.THRESH_BINARY_INV)
# 截断
ret, th3 = cv.threshold(img, 127, 255, cv.THRESH_TRUNC)
# 阈值取零
ret, th4 = cv.threshold(img, 127, 255, cv.THRESH_TOZERO)
# 阈值反取零
ret, th5 = cv.threshold(img, 127, 255, cv.THRESH_TOZERO_INV)# 3. 图像显示
titles = ['原图', '阈值二值化', '阈值反二值化', '截断', '阈值取零', '阈值反取零']
images = [img, th1, th2, th3, th4, th5]
plt.figure(figsize=(10, 6))
# 使用Matplotlib显示
for i in range(6):plt.subplot(2, 3, i + 1)plt.imshow(images[i], 'gray')plt.title(titles[i], fontsize=8)plt.xticks([]), plt.yticks([]) # 隐藏坐标轴
plt.show()
2.2 自适应阈值分割(局部阈值化)
自适应阈值分割也叫做局部阈值化,它是根据像素的邻域块的像素值分布来确定该像素位置上的阈值。这样做的好处在于每个像素位置处的阈值不是固定不变的,而是由其周围邻域像素的分布来决定的。
亮度较高的图像区域的阈值通常会较高,而亮度较低的图像区域的阈值则会相适应地变小。
不同亮度、对比度、纹理的局部图像区域将会拥有相对应的局部阈值。
常用的局部自适应阈值有:1)局部邻域块的均值;2)局部邻域块的高斯加权和。
在OPenCV中实现自适应阈值分割的API是:
dst = cv.adaptiveThreshold(src, maxval, thresh_type, type, Block Size, C)
参数:
-
src: 输入图像,一般是灰度图
-
Maxval:灰度中的最大值,一般为255,用来指明像素超过或小于阈值(与type类型有关),赋予的最大值
-
thresh_type : 阈值的计算方法,主要有以下两种:

-
type: 阈值方式,与threshold中的type意义相同
-
block_size: 计算局部阈值时取邻域的大小,如果设为11,就取11*11的邻域范围,一般为奇数。
-
C: 阈值计算方法中的常数项,即最终的阈值是邻域内计算出的阈值与该常数项的差值
返回:
- dst:自适应阈值分割的结果
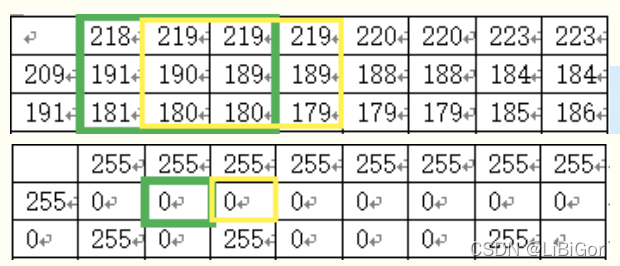
当block_size设为3,阈值计算方法为取均值,C设为5,阈值类型为阈值二值化时的阈值分割结果如下图所示:
示例:
import cv2 as cv
import matplotlib.pyplot as plt# 1. 图像读取
img = cv.imread('img/2.jpg', 0)# 2.固定阈值/阈值分割 threshold(要处理的图像,一般是灰度图, 设定的阈值, 灰度中的最大值, 阈值分割的方式)
ret, th1 = cv.threshold(img, 127, 255, cv.THRESH_BINARY)# 3.自适应阈值
# 3.1 邻域内求均值 cv.adaptiveThreshold(输入图像, 灰度中的最大值, 阈值的计算方法, 阈值方式,计算局部阈值时取邻域的大小,阈值计算方法中的常数项)
th2 = cv.adaptiveThreshold(img, 255, cv.ADAPTIVE_THRESH_MEAN_C, cv.THRESH_BINARY, 11, 4)
# 3.2 邻域内高斯加权
th3 = cv.adaptiveThreshold(img, 255, cv.ADAPTIVE_THRESH_GAUSSIAN_C, cv.THRESH_BINARY, 17, 6)# 4 结果绘制
titles = ['Original drawing', 'Global threshold (v = 127)', 'Adaptive threshold (averaging)', 'Adaptive threshold (Gaussian weighted)']
images = [img, th1, th2, th3]
plt.figure(figsize=(10, 6))
for i in range(4):plt.subplot(2, 2, i + 1), plt.imshow(images[i], 'gray')plt.title(titles[i], fontsize=8)plt.xticks([]), plt.yticks([])
plt.show()结果:

从图中我们图可以看出,全局阈值化使用唯一的阈值,对于亮度分布差异较大的图像,难以找到一个合适的阈值。在上述图片中青椒与其他水果的亮度相差较大,难以找到合适的阈值将其分割出来。而使用自适应的阈值分割时,因为阈值是自适应的,所以可以将物体分割出来。但因为要计算阈值,所以其计算量较大,效率低。
2.3 Otsu 阈值(大津法)
在全阈值分割中,我们选取127作为我们的阈值,那我们怎么知道这个阈值的效果呢?那就是不断的进行尝试,也就是获得经验阈值。Otsu算法提供了一种自动高效的二值化方法,我们现在就来看下这个算法。
大津法是一种图像灰度自适应的阈值分割算法,按照图像上灰度值的分布,将图像分成背景和前景两部分看待,前景就是我们要按照阈值分割出来的部分。背景和前景的分界值就是我们要求出的阈值。遍历不同的阈值,计算不同阈值下对应的背景和前景之间的类内方差,当类内方差取得极大值时,此时对应的阈值就是大津法(OTSU算法)所求的阈值。
对于图像I(x,y),前景(即目标)和背景的分割阈值记作T,属于前景的像素点数占整幅图像的比例记为ω0,其平均灰度μ0;背景像素点数占整幅图像的比例为ω1,其平均灰度为μ1。图像的总平均灰度记为μ,类间方差记为g。假设图像的大小为M×N,图像中像素的灰度值小于阈值T的像素个数记作N0,像素灰度大于阈值T的像素个数记作N1,则有:
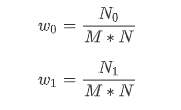
则图像的总平均灰度为:

类间方差的计算方法如下式所示:

将总平均灰度带入到类间方差的计算公式中,得到等价公式:
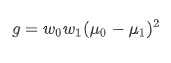
这个就是类间方差的公式。
采用遍历的方法得到使类间方差g最大的阈值T,即为所求的阈值结果。
该算法实现思路是:
-
计算0~255各灰阶对应的像素个数,保存至一个数组中,该数组下标是灰度值,保存内容是当前灰度值对应像素数,即灰度直方图;
-
遍历0~255各灰阶,设置为阈值T
2.1 计算背景图像的平均灰度、背景图像像素数所占比;
2.2 计算前景图像的平均灰度、前景图像像素数所占比例
2.3 计算对应的类间方差极大值,并保存下来
-
寻找类间方差极大值,就得到阈值结果。
在opencv 中实现Ostu算法使用的是cv.threshold()函数,指定使用cv.THRESH_OTSU即可。
import cv2 as cv
import matplotlib.pyplot as plt
# 1. 图像读取
img = cv.imread('img/wulin.png', 0)# 2.固定阈值 threshold(要处理的图像,一般是灰度图, 设定的阈值, 灰度中的最大值, 阈值分割的方式)
ret, th1 = cv.threshold(img, 12,255, cv.THRESH_BINARY)
# 3. OSTU阈值 threshold(要处理的图像,一般是灰度图, 设定的阈值, 灰度中的最大值, 阈值分割的方式)
ret2,th2 = cv.threshold(img,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)# 4. 结果绘制
plt.figure(figsize=(10,8),dpi=100)
plt.subplot(131),plt.imshow(img,'gray'),plt.title('原图')
plt.xticks([]), plt.yticks([])
plt.subplot(132),plt.imshow(th1,'gray'),plt.title('全阈值分割')
plt.xticks([]), plt.yticks([])
plt.subplot(133),plt.imshow(th2,'gray'),plt.title('OStu分割')
plt.xticks([]), plt.yticks([])
plt.show()
结果如下所示:
3 分水岭算法
3.1 原理
分水岭算法是一种图像区域分割算法,在分割过程中,会将临近像素间的相似性作为参考依据,从而将在空间位置上相近并且灰度值相近的像素点互相连接起来构成一个封闭的区域。分水岭算法因实现方便,已在医疗影像,模式识别等领域得到了广泛的应用。
分水岭算法的基本思想是基于浸泡理论实现的,假设图像每个位置的像素值为不同的地形,那势必会形成山峰和山谷,那在山底不断的注水,直到各个山头之间形成明显的分水线,那分水线就是我们图像分割的分解线。
下图中左边为灰度图,它可以描述为右边的地形图,地形的高度是由灰度图的灰度值决定,灰度为0对应地形图的地面,灰度值最大的像素对应地形图的最高点。
这样看起来会好一些:
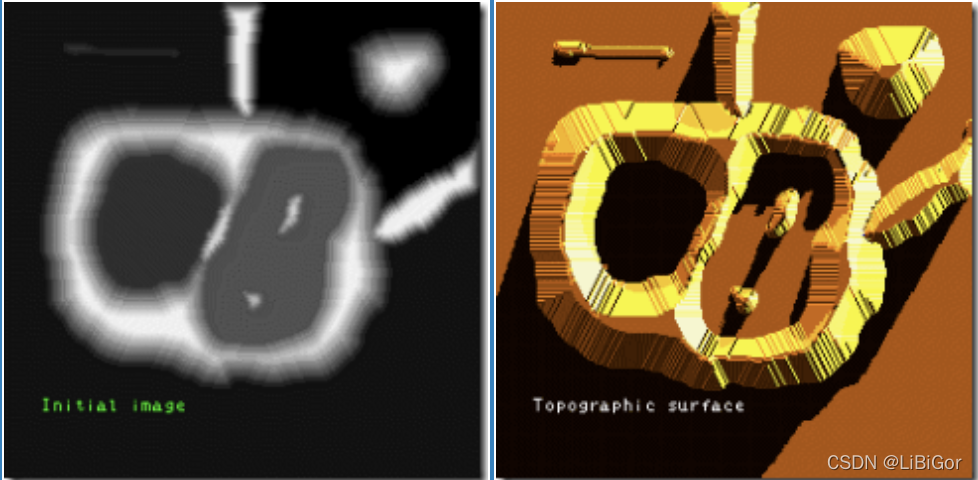
对于灰度图地形学的解释,我们考虑以下三点:
1、局部最小值点,该点对应一个盆地的最低点,当我们在盆地里注入一滴水的时候,由于重力作用,水最终会汇聚到该点。注意:可能存在一个最小值面,该平面内的都是最小值点。
2、盆地的其它位置点,该位置注入的水滴会汇聚到局部最小点。
3、盆地的边缘点,是该盆地和其它盆地交接点,在该点注入一滴水,会等概率的流向任何一个盆地
假设在盆地的最小值点,打一个洞,然后往盆地里面注水,并阻止两个盆地的水汇集,我们会在两个盆地的水汇集的时刻,在交接的边缘线上(也即分水岭线),建一个坝,来阻止两个盆地的水汇集成一片水域。这样图像就被分成2个像素集,一个是注水盆地像素集,一个是分水岭线像素集。那图像就被我们分割开了。如下图所示:
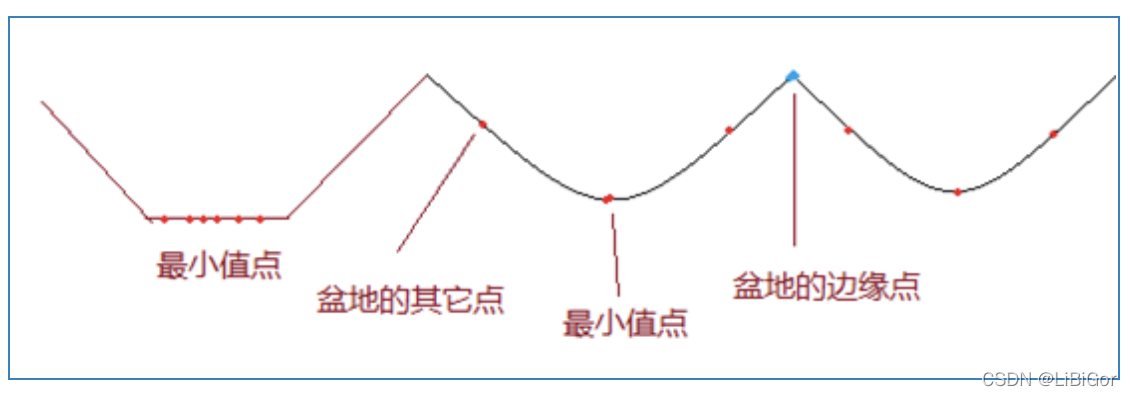
在实际应用中,由于噪声点或者其它干扰因素的存在,使用分水岭算法常常存在过度分割的现象,这是因为过多局部极值点的存在而产生许多小的集水盆地,从而导致分割后的图像不能将图像中有意义的区域表示出来。
为了解决过分割的问题,提出了改进算法:基于标记(mark)图像的分水岭算法,本质上就是通过先验知识,来指导分水岭算法,以便获得更好的图像分割效果。通常的mark图像,都是在某个区域定义了一些灰度层级,在这个区域的洪水淹没过程中,水平面都是从定义的高度开始的,这样可以避免一些很小的噪声极小值区域的分割。
3.2 实现
OPenCV中提供了基于标记图像的分水岭算法的实现,使用cv.watershed()方法,输入一个标记对象,对图像中的部分像素进行标记,表明其所属的区域是已知的,分水岭算法根据这个标签确定各个像素所属的区域。如下图所示:
从上图可以看出,传统的分水岭算法由于局部最小值过多造成分割后的分水岭较多。
而基于标记的分水岭算法,水淹过程从预先定义好的标记图像(像素)开始,较好的克服了过度分割的不足。本质上讲,基于标记点的改进算法是利用先验知识来帮助分割的一种方法。
因此,改进算法的关键在于如何获得准确的标记图像。
分水岭算法的API:
res = watershed(image,markers)
参数:
- image: 输入图像,必须是8位的3通道彩色图像
- marker: 标记图像,32位单通道图像,它包括种子点信息,使用轮廓信息作为种子点。在进行分水岭算法之前,必须设置好marker信息,它包含不同区域的轮廓,每个轮廓有唯一的编号,使用findCountours方法确定轮廓位置,不同区域的交界位置为-1
返回:
- res: 图像分割之后的结果
分水岭算法实现图像自动分割的步骤:
- 对原图像进行灰度化处理,并进行边缘检测或二值化
- 查找轮廓,并且把轮廓信息按不同的编号绘制在标记图像上,即标记种子点,将其传给marker参数
- 进行分水岭算法检测
- 绘制分割出来的区域,使用随机颜色进行填充
我们现在按照上述流程,对下述图片使用分水岭算法进行图像分割:

代码:
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt# 1.读入图片
img = cv.imread('img/wulin.png')
gray_img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)# 2.canny边缘检测
canny = cv.Canny(gray_img, 80, 150)# 3.轮廓检测并设置标记图像
# 寻找图像轮廓 返回修改后的图像 图像的轮廓 以及它们的层次
canny, contours, hierarchy = cv.findContours(canny, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
# 32位有符号整数类型,
marks = np.zeros(img.shape[:2], np.int32)
# findContours检测到的轮廓
imageContours = np.zeros(img.shape[:2], np.uint8)# 轮廓颜色
compCount = 0
index = 0
# 绘制每一个轮廓
for index in range(len(contours)):# 对marks进行标记,对不同区域的轮廓使用不同的亮度绘制,相当于设置注水点,有多少个轮廓,就有多少个轮廓# 图像上不同线条的灰度值是不同的,底部略暗,越往上灰度越高marks = cv.drawContours(marks, contours, index, (index, index, index), 1, 8, hierarchy)# 绘制轮廓,亮度一样imageContours = cv.drawContours(imageContours, contours, index, (255, 255, 255), 1, 8, hierarchy)# 4 使用分水岭算法,并给不同的区域随机填色
#cv.watershed(输入图像,标记图像)
marks = cv.watershed(img, marks)
#实现图像增强等相关操作的快速运算 图像sobely转换回灰度
afterWatershed = cv.convertScaleAbs(marks)# 生成随机颜色
colorTab = np.zeros((np.max(marks) + 1, 3))
# 生成0~255之间的随机数
for i in range(len(colorTab)):aa = np.random.uniform(0, 255)bb = np.random.uniform(0, 255)cc = np.random.uniform(0, 255)colorTab[i] = np.array([aa, bb, cc], np.uint8)bgrImage = np.zeros(img.shape, np.uint8)# 遍历marks每一个元素值,对每一个区域进行颜色填充
for i in range(marks.shape[0]):for j in range(marks.shape[1]):# index值一样的像素表示在一个区域index = marks[i][j]# 判断是不是区域与区域之间的分界,如果是边界(-1),则使用白色显示if index == -1:bgrImage[i][j] = np.array([255, 255, 255])else:bgrImage[i][j] = colorTab[index]
# 5 图像显示
plt.imshow(bgrImage[:, :, ::-1])
plt.title('result')
plt.xticks([]), plt.yticks([])
plt.show()分割结果如下所示:

4.GrabCut算法
4.1 GraphCut
GrabCut算法是基于图论的分割方法,在这里我们先介绍GraphCuts,然后再到GrabCut。
Graph cuts是一种十分有用和流行的能量优化算法,在计算机视觉领域普遍应用于前背景分割(Image segmentation)、立体视觉(stereo vision)、抠图(Image matting)等。
该方法把图像分割问题与图的最小割(min cut)问题相关联。首先用一个无向图G=表示要分割的图像,V和E分别是顶点(vertex)和边(edge)的集合。此处的Graph和普通的Graph稍有不同。普通的图由顶点和边构成,如果边的有方向的,这样的图被则称为有向图,否则为无向图,且边是有权值的,不同的边可以有不同的权值,分别代表不同的物理意义。而Graph Cuts图是在普通图的基础上多了2个顶点,这2个顶点分别用符号”S”和”T”表示,统称为终端顶点。其它所有的顶点都必须和这2个顶点相连形成边集合中的一部分。所以Graph Cuts中有两种顶点,也有两种边。
第一种顶点和边:第一种普通顶点对应于图像中的每个像素。每两个邻域顶点(对应于图像中每两个邻域像素)的连接就是一条边。这种边也叫n-links。
第二种顶点和边:除图像像素外,还有另外两个终端顶点,叫S(source:源点,取源头之意)和T(terminal : 汇点,取汇聚之意)。每个普通顶点和这2个终端顶点之间都有连接,组成第二种边。这种边也叫t-links。
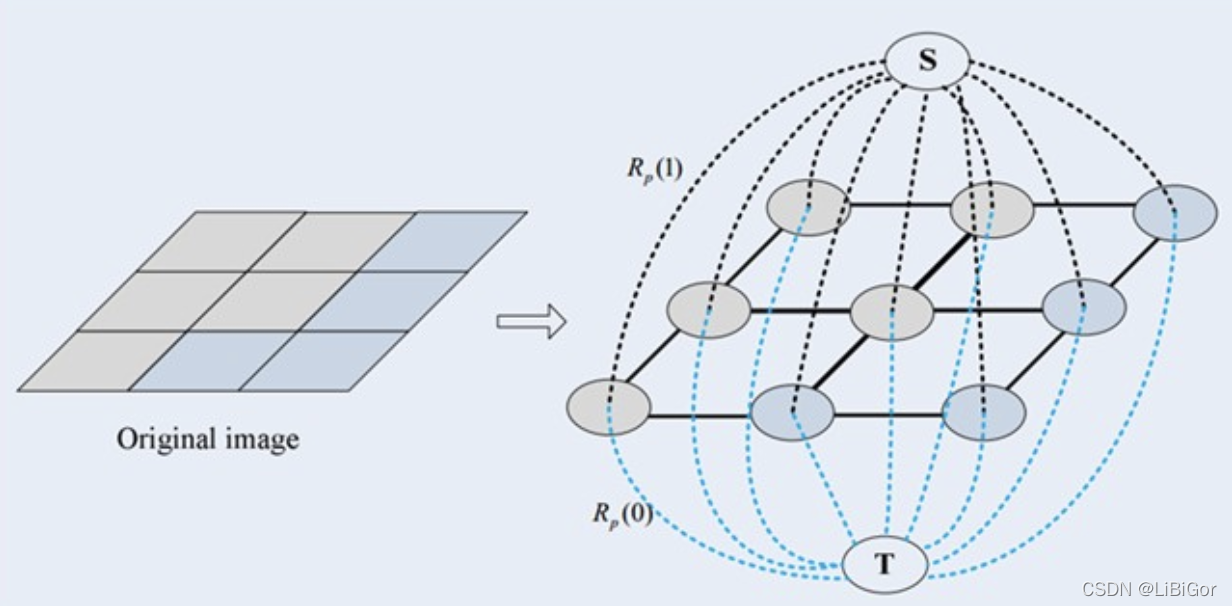
上图就是一个图像对应的s-t图,每个像素对应图中的一个相应顶点,另外还有s和t两个顶点。上图有两种边,实线的边表示每两个邻域普通顶点连接的边n-links,虚线的边表示每个普通顶点与s和t连接的边t-links。在前后景分割中,s一般表示前景目标,t一般表示背景。
图中每条边都有一个非负的权值,也可以理解为cost(代价或者费用)。一个cut(割)就是图中边集合E的一个子集C,那这个割的cost(表示为|C|)就是边子集C的所有边的权值的总和。
那这个权值怎么确定呢?
拿到待分割的图像后,图的节点与边已确定,即图的形状已确定下来,仅仅需要做的就是给图中所有边赋值相应的权值,在赋值之前需要指定前景和背景的种子点,那构建的图中的权值就有3种情况:
-
种子点t-link权值:种子点认为是硬约束,其用户预设类别后,类别不会随分割算法而改变。
1.1 对于正类别种子点,s-t-link必须保留,t-t-link必须割去。工程中,通过将s-t-link权值设置为超级大值,t-t-link设置为0。保证一定仅仅割去t-t-link,否则一定不是最小割,因为当前w(s-t-link)权值是超级大值,割去这条边的代价一定是最大的。
1.2 反之同理。
-
非种子点的t-link权值:通过正负类种子点,我们能建立2类的颜色直方图。将直方图归一化成概率密度函数,定义为H_F,H_B。其中s-t-link权值为-ln(H_F(x)),t-t-link权值为-ln(H_B(x)),x为该像素点颜色值。
-
n-link权值:n-link用于度量相邻像素点之间颜色的差异性。设一对相邻点Pi,Pj,则n-link(Pi-Pj)的权值w等于:
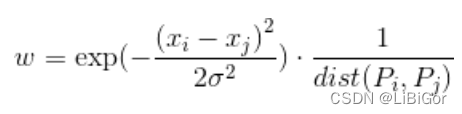
其中,xi 和xj 表示点的像素值,dist()是距离函数,表示点之间的图像距离。在4邻域内,邻域点距离均为1,8邻域,对角像素点距离为√2 。
设种子点的超级大值是1000,σ=1。图像是3*2的灰度图,数字表示灰度值,红色和蓝色节点表示用户选择的前景和背景种子点。当然种子点过少时,计算的H_F,H_B可能不准,可将种子点附近的像素点也算入先验直方图中,往往可以取得更好效果。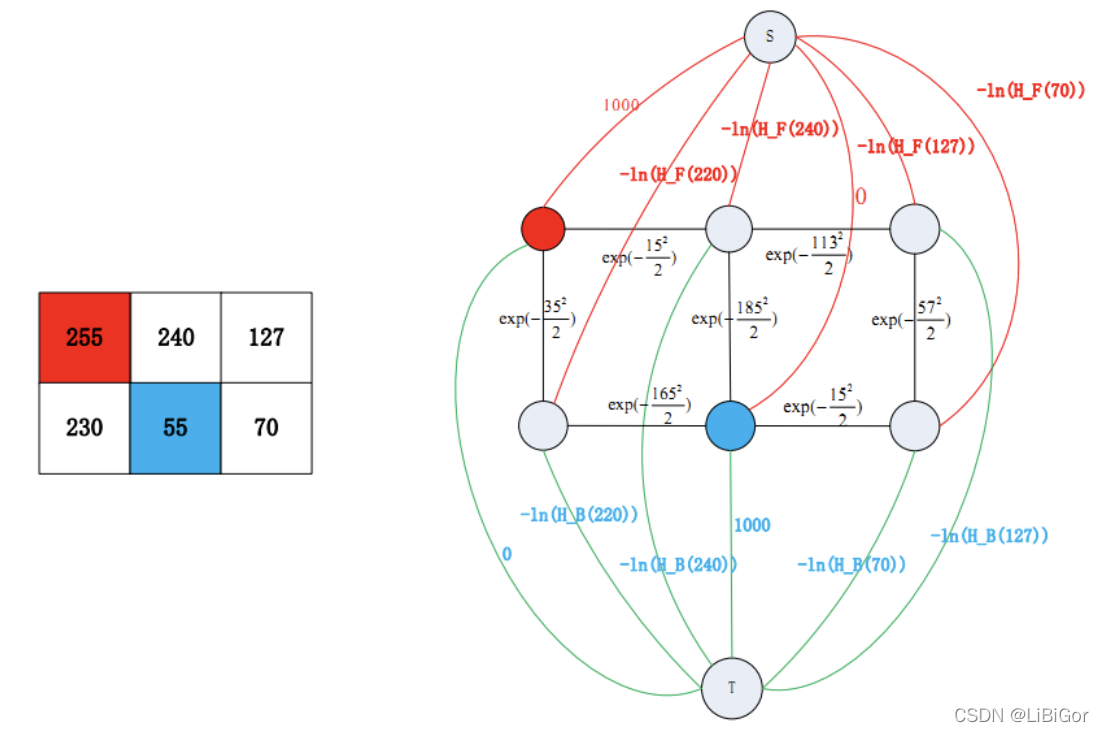
如上图所示,将所有边的权值赋值后,图就建立完毕。
Graph Cuts中的Cuts是指这样一个边的集合,很显然这些边集合包括了上面2种边,该集合中所有边的断开会导致残留”S”和”T”图的分开,所以就称为“割”。如果一个割,它的边的所有权值之和最小,那么这个就称为最小割,也就是图割的结果。而福特-富克森定理表明,网路的最大流max flow与最小割min cut相等。所以由Boykov和Kolmogorov发明的max-flow/min-cut算法就可以用来获得s-t图的最小割。这个最小割把图的顶点划分为两个不相交的子集S和T,其中s ∈S,t∈ T和S∪T=V 。这两个子集就对应于图像的前景像素集和背景像素集,那就相当于完成了图像分割。
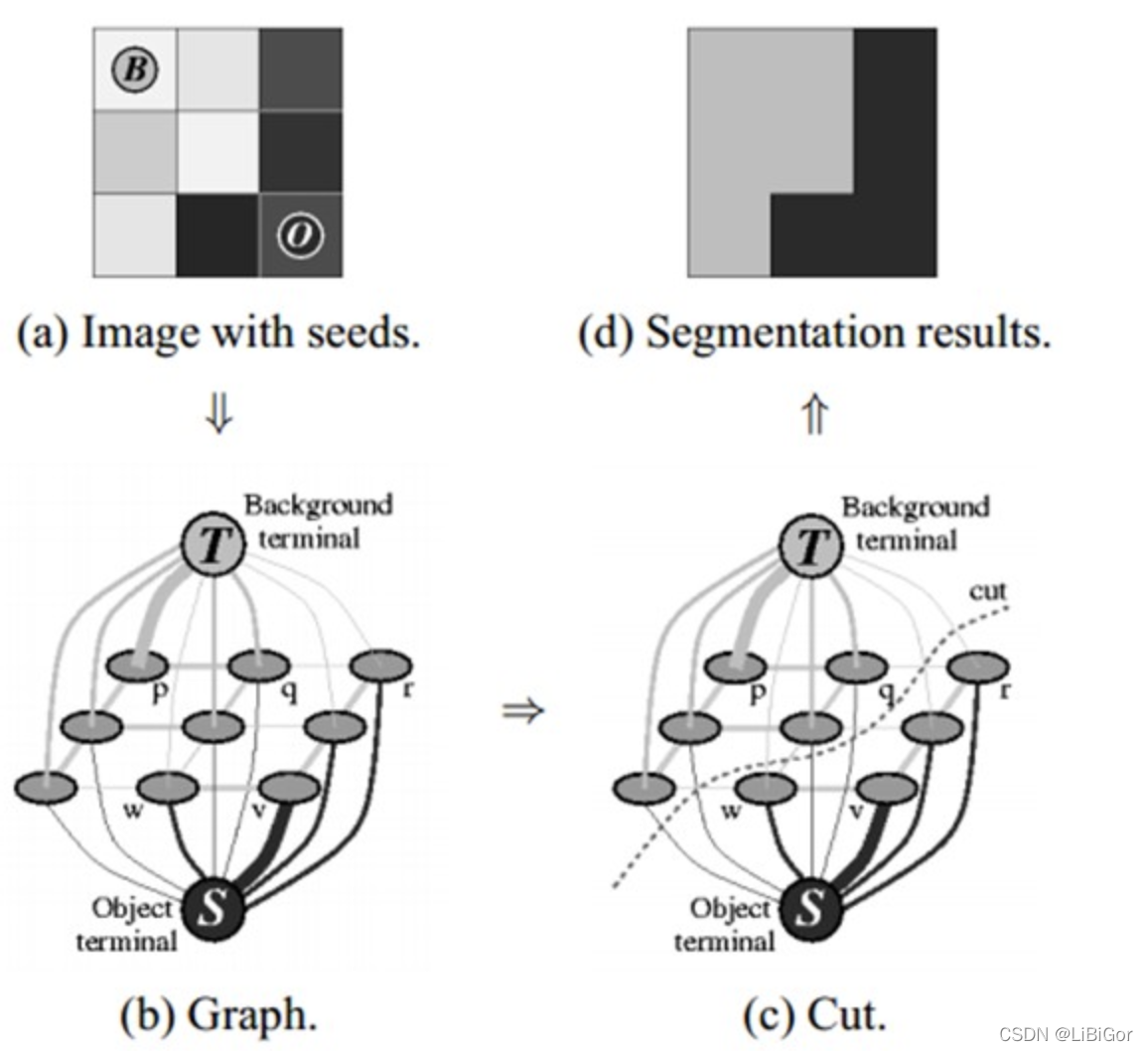
Graph cut的3x3图像分割示意图:我们取两个种子点(就是人为的指定分别属于目标和背景的两个像素点),然后我们建立一个图,图中边的粗细表示对应权值的大小,然后找到权值和最小的边的组合,也就是(c)中的cut,即完成了图像分割的功能。
4.2 GrabCut
GrabCut是微软研究院的一个课题,主要功能是分割和抠图,该算法利用了图像中的纹理(颜色)信息和边界(反差)信息,只要少量的用户交互操作即可得到比较好的分割结果。
GrabCut算法的优势是:
- 只需要在目标外面画一个框,把目标框住,它就可以完成良好的分割:

-
如果增加额外的用户交互(由用户指定一些像素属于目标),那么效果会更好

2.它的边界处理技术会使目标分割边界更加自然和柔和:
-
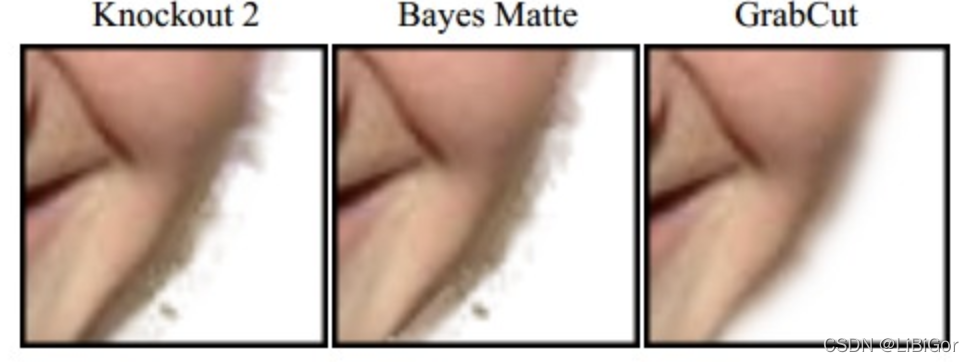
该算法也有不完美的地方,如果背景比较复杂或者背景和目标的相似度很大,那分割效果就不好,而且该算法的速度较慢。
那GrabCut算法是怎么实现的呢?和GraphCut算法的区别是什么?
首先我们看下与GraphCut算法的区别:
-
Graph Cut的目标和背景的模型是灰度模型,Grab Cut取代为RGB三通道的混合高斯模型GMM;
-
Graph Cut的能量最小化(分割)是一次达到的,而Grab Cut取代为一个不断进行分割估计和模型参数学习的交互迭代过程;
-
Graph Cut需要用户指定目标和背景的一些种子点,但是Grab Cut只需要提供背景区域的像素集就可以了。也就是说只需要框选目标,那么在方框外的像素全部当成背景,这时候就可以对GMM进行建模和完成良好的分割了,即Grab Cut允许不完全的标注。
现在我们看下GrabCut算法的实现过程:
-
颜色模型
我们采用RGB颜色空间,分别用K(一般取5)个高斯分量的全协方差GMM(混合高斯模型)来对目标和背景进行建模。那就要创建向量k = {k1, . . ., kn, . . ., kN},其中kn是第n个像素对应于高斯分量。
混合高斯密度模型如下所示:
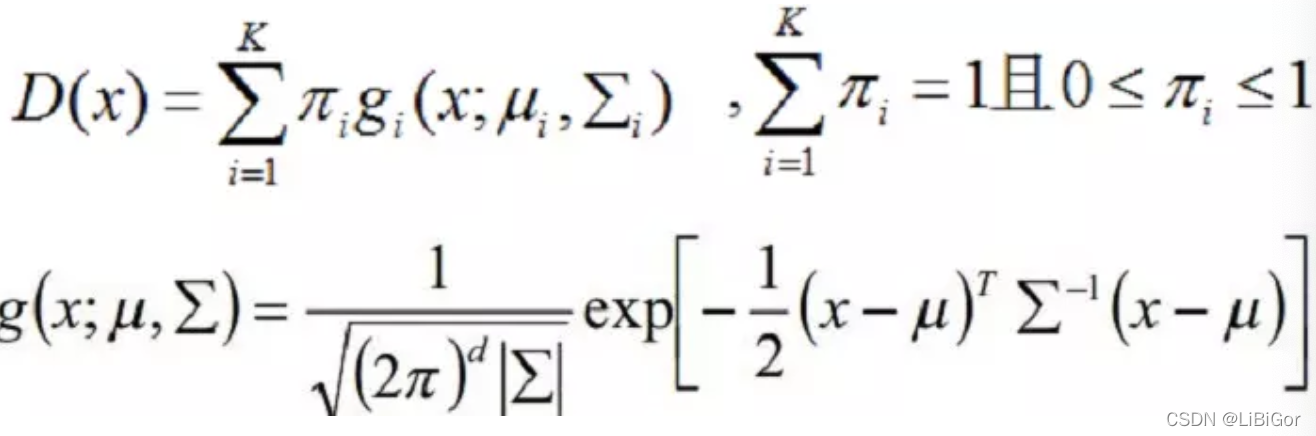
其中,x表示bgr三通道向量。GMM的参数有三个:每个高斯分量的权重\piπ ,每个高斯分量的均值向量μ(BGR三个通道,固为三个元素的向量)和协方差矩阵\SigmaΣ(BGR三个通道,为33的矩阵)。描述目标的GMM和描述背景的GMM的这三个参数都需要学习确定。一旦确定了这三个参数,知道一个像素的RGB颜色值之后,就可以代入目标的GMM和背景的GMM,就可以得到该*像素分别属于目标和背景的概率了。
-
迭代能量最小化分割算法
每次迭代过程都使得对目标和背景建模的GMM的参数更优,使得图像分割更优。
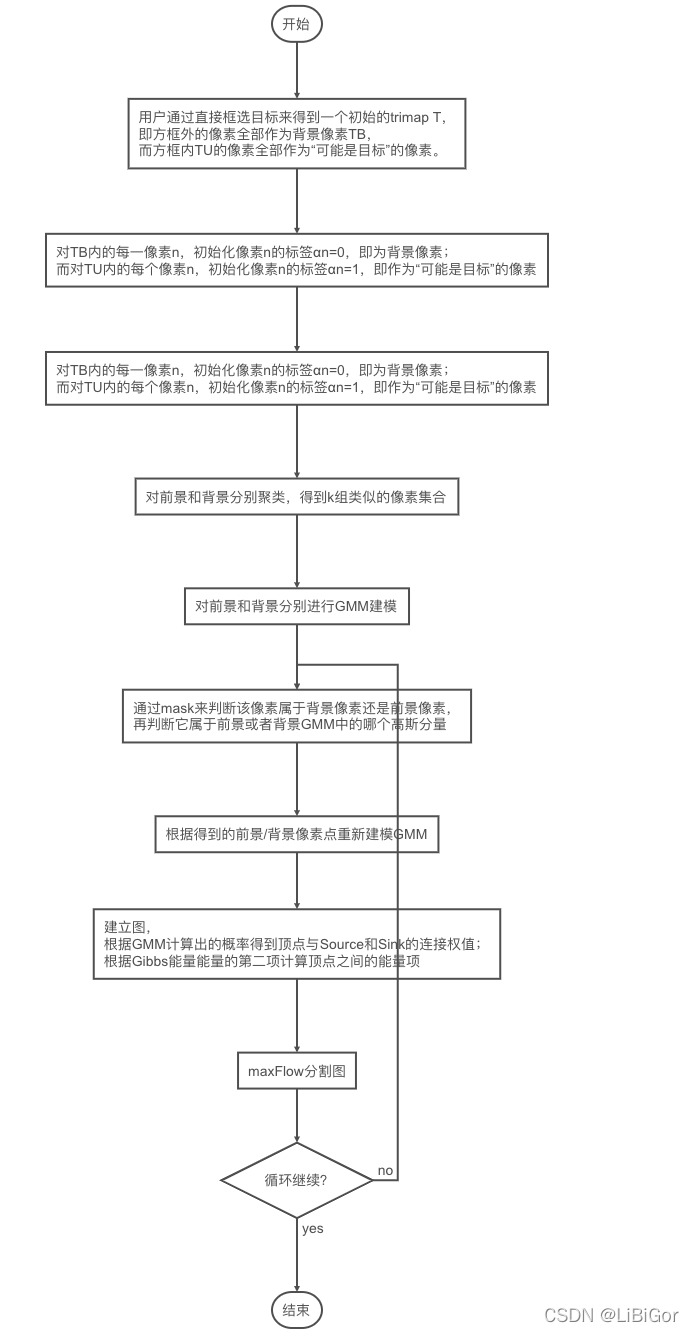
2.1. 初始化
- 用户通过直接框选目标来得到一个初始的trimap T,即方框外的像素全部作为背景像素TB,而方框内TU的像素全部作为“可能是目标”的像素。
- 对TB内的每一像素n,初始化像素n的标签αn=0,即为背景像素;而对TU内的每个像素n,初始化像素n的标签αn=1,即作为“可能是目标”的像素。
- 通过k-mean算法分别把属于目标和背景的像素聚类为K类,即GMM中的K个高斯模型,这时候GMM中每个高斯模型就具有了一些像素样本集,这时候它的参数均值和协方差就可以通过他们的RGB值估计得到,而该高斯分量的权值可以通过属于该高斯分量的像素个数与总的像素个数的比值来确定。
2.2 迭代最小化
-
对每个像素分配GMM中的高斯分量,例如像素n是目标像素,那么把像素n的RGB值代入目标GMM中的每一个高斯分量中,概率最大的那个就是最有可能生成n的,也即像素n的第kn个高斯分量。
-
对于给定的掩膜数据,学习优化GMM的参数,因为在上一步中我们已经为每个像素归为哪个高斯分量做了归类,那么每个高斯模型就具有了一些像素样本集,这时候它的参数均值和协方差就可以通过这些像素样本的RGB值估计得到,而该高斯分量的权值可以通过属于该高斯分量的像素个数与总的像素个数的比值来确定。
-
分割估计,与GraphCut类似,建立一个图,并求出权值t-link和n-link,然后通过max flow/min cut算法来进行分割。
-
重复以上步骤,直到收敛。经过分割后,每个像素属于目标GMM还是背景GMM就变了,所以每个像素的kn就变了,故GMM也变了,所以每次的迭代会交互地优化GMM模型和分割结果。
-
采用border matting对分割的边界进行平滑等后期处理。
把上述过程绘成流程图,如下所示:
4.3 实现
在openCV中实现GrabCut算法,使用的API:
grabCut(img,mask,rect,bgdModel,fgdModel,iterCount,mode )
参数:
- img:输入图像,必须是8位的3通道彩色图像
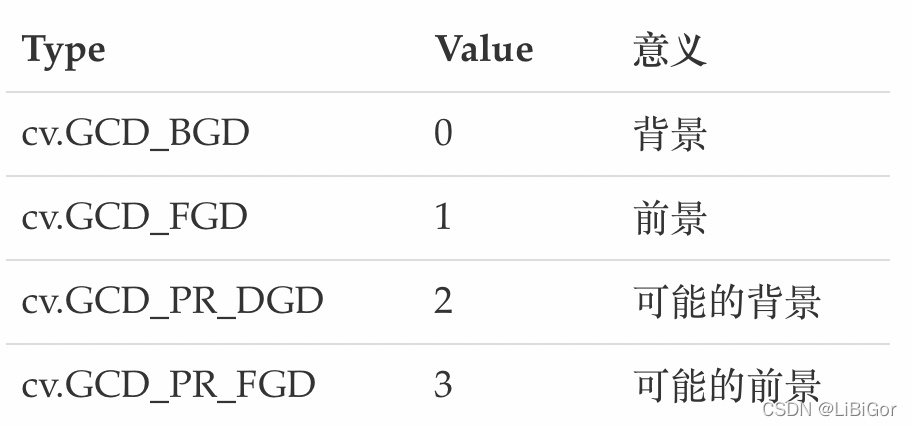
- mask: 掩码图像,如果使用掩码进行初始化,那么mask保存初始化掩码信息;也可以将用户交互所设定的前景与背景保存到mask中,然后再传入grabCut函数;在处理结束之后,mask中会保存结果。mask只能取以下四种值:
- rect:用于限定需要进行分割的图像范围,只有该矩形窗口内的图像部分才被处理
- bgdModel:背景模型,如果为None,函数内部会自动创建一个bgdModel;bgdModel必须是单通道浮点型图像,且行数只能为1,列数只能为13x5
- fgdModel:前景模型,如果为None,函数内部会自动创建一个fgdModel;fgdModel必须是单通道浮点型图像,且行数只能为1,列数只能为13x5
- iterCount:迭代次数,必须大于0
- mode:指明grabcut函数进行哪种操作,如下所示:

我们演示利用矩形窗进行抠图,将下图中的热气球扣取出来:

import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt#1. 读取图片
img = cv.imread('ballon.jpeg')
#2. 掩码图像
mask = np.zeros(img.shape[:2],np.uint8)#3.矩形窗口(x,y,w,h);
rect = [140,45,330,335]#4.物体分割
cv.grabCut(img,mask,tuple(rect),None,None,5,cv.GC_INIT_WITH_RECT)#5.抠取图像
mask2 = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img_show = img*mask2[:,:,np.newaxis]# 将矩形框绘制在图像上
cv.rectangle(img,(140,45),(470,380),(0,255,0),3)#6.图像显示
plt.figure(figsize=(10,8),dpi=100)
plt.subplot(121),plt.imshow(img[:,:,::-1]),plt.title('矩形框选位置')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img_show[:,:,::-1]),plt.title('抠取结果')
plt.xticks([]), plt.yticks([])
plt.show()
效果:

总结:
-
图像分割方法
基于阈值的,基于边缘的,基于区域的,基于图论的等
-
阈值分割
全阈值分割:指将灰度值大于thresh(阈值)的像素设为一种颜色,小于或等于阈值的像素设为另外一种颜色
API:cv.threshold()
自适应阈值分割:根据像素的邻域块的像素值分布来确定该像素位置上的阈值
API:cv.adaptiveThreshold()
大津法:遍历不同的阈值,计算不同阈值下对应的背景和前景之间的类内方差,当类内方差取得极大值时,此时对应的阈值就是大津法
API:cv.threshold(,,cv.Ostu)
-
分水岭算法
分水岭算法是一种图像区域分割算法,在分割过程中,会将临近像素间的相似性作为参考依据,从而将在空间位置上相近并且灰度值相近的像素点互相连接起来构成一个封闭的区域.
传统的分水岭算法会导致过分割,提出了改进算法:基于标记(mark)图像的分水岭算法,本质上就是通过先验知识,来指导分水岭算法。
API:cv.waterShed()
分水岭算法实现图像自动分割的步骤:
- 对原图像进行灰度化处理,并进行边缘检测或二值化
- 查找轮廓,并且把轮廓信息按不同的编号绘制在标记图像上,即标记种子点,将其传给marker参数
- 进行分水岭算法检测
- 绘制分割出来的区域,使用随机颜色进行填充
-
GrabCut算法
GrabCut算法是基于图论的分割方法
GraphCut:把图像分割问题与图的最小割(min cut)问题相关联
GrabCut: 基于RGB三通道的混合高斯模型GMM,不断进行分割估计和模型参数学习的交互迭代,完成图像的分割
优势:只需一个框,就可完成很好的分割;边缘处理较柔和
API : cv.GrabCut()



















