
Multi-sample Dropout是Dropout的一个变种方法,该方法比普通Dropout的泛化能力更好,同时又可以缩短模型的训练时间。XMuli-sampleDropout还可以降低训练集和验证集的错误率和损失,参见的论文编号为arXⅳ:1905.09788,2019
1 实例说明
本例就使用Muli-sampleDropout方法为图卷积模型缩短训练时间。
1.1 Multi-sample Dropout方法/多样本联合Dropout
是在Dropout随机选取节点丢弃的部分上进行优化,即将Dropout随机选取的一组节点变成随机选取多组节点,并计算每组节点的结果和反向传播的损失值。最终,将计算多组的损失值进行平均,得到最终的损失值,并用其更新网络,如图9-19所示。
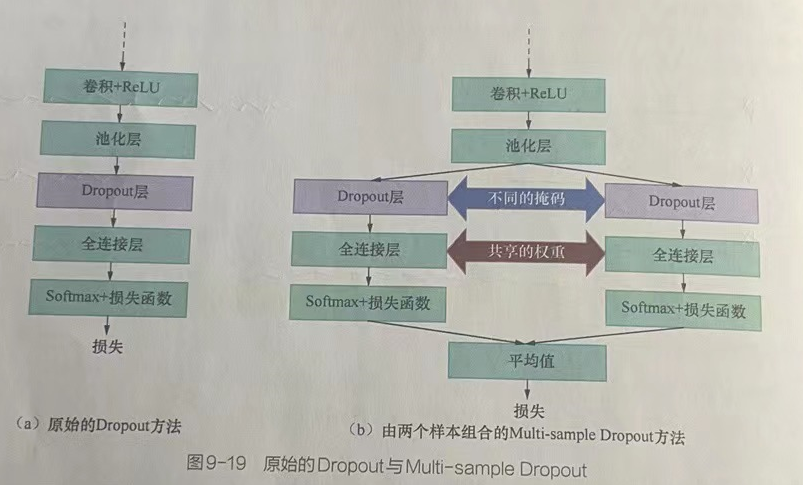
Multi-sampleDropout在Dropout层使用两套不同的掩码选取出两组节点进行训练,这种做法相当于网络层只运行了一次样本,却输出了多个结果,进行了多次训练。因此,它可以大大减少训练的迭代次数。
1.1.2 特点
在深层神经网络中,太部分运算发生在Dropout层之前的卷积层中,Muiti-sample Dropout并不会重复这些计算,所以Multi-sampleDropout对每次迭代的计算成本影响不大。它可以大幅加快训练速度。
2 代码实现
Pytorch神经网络实战学习笔记_40 【实战】图卷积神经网络进行论文分类_LiBiGor的博客-CSDN博客1 案例说明(图卷积神经网络)CORA数据集里面含有每一篇论文的关键词以及分类信息,同时还有论文间互相引用的信息。搭建AI模型,对数据集中的论文信息进行分析,根据已有论文的分类特征,从而预测出未知分类的论文类别。1.1 使用图卷积神经网络的特点使用图神经网络来实现分类。与深度学习模型的不同之处在于,图神经网通会利用途文本身特征和论文间的关系特征进行处理,仅需要少量样本即可达到很好的效果。1.2 CORA数据集CORA数据集是由机器学习的论文整理而来的,记录每篇论文用到的关键...https://blog.csdn.net/qq_39237205/article/details/123863327基于上述代码进行修改2.7搭建多层图卷积与训练部分
2 代码编写
2.1 代码实战:引入基础模块,设置运行环境----Cora_GNN.py(第1部分)
from pathlib import Path # 引入提升路径的兼容性
# 引入矩阵运算的相关库
import numpy as np
import pandas as pd
from scipy.sparse import coo_matrix,csr_matrix,diags,eye
# 引入深度学习框架库
import torch
from torch import nn
import torch.nn.functional as F
# 引入绘图库
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"# 1.1 导入基础模块,并设置运行环境
# 输出计算资源情况
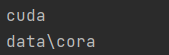
device = torch.device('cuda')if torch.cuda.is_available() else torch.device('cpu')
print(device) # 输出 cuda# 输出样本路径
path = Path('./data/cora')
print(path) # 输出 cuda输出结果:
2.2 代码实现:读取并解析论文数据----Cora_GNN.py(第2部分)
# 1.2 读取并解析论文数据
# 读取论文内容数据,将其转化为数据
paper_features_label = np.genfromtxt(path/'cora.content',dtype=np.str_) # 使用Path对象的路径构造,实例化的内容为cora.content。path/'cora.content'表示路径为'data/cora/cora.content'的字符串
print(paper_features_label,np.shape(paper_features_label)) # 打印数据集内容与数据的形状# 取出数据集中的第一列:论文ID
papers = paper_features_label[:,0].astype(np.int32)
print("论文ID序列:",papers) # 输出所有论文ID
# 论文重新编号,并将其映射到论文ID中,实现论文的统一管理
paper2idx = {k:v for v,k in enumerate(papers)}# 将数据中间部分的字标签取出,转化成矩阵
features = csr_matrix(paper_features_label[:,1:-1],dtype=np.float32)
print("字标签矩阵的形状:",np.shape(features)) # 字标签矩阵的形状# 将数据的最后一项的文章分类属性取出,转化为分类的索引
labels = paper_features_label[:,-1]
lbl2idx = { k:v for v,k in enumerate(sorted(np.unique(labels)))}
labels = [lbl2idx[e] for e in labels]
print("论文类别的索引号:",lbl2idx,labels[:5])输出:

2.3 读取并解析论文关系数据
载入论文的关系数据,将数据中用论文ID表示的关系转化成重新编号后的关系,将每篇论文当作一个顶点,论文间的引用关系作为边,这样论文的关系数据就可以用一个图结构来表示。

计算该图结构的邻接矩阵并将其转化为无向图邻接矩阵。
2.3.1 代码实现:转化矩阵----Cora_GNN.py(第3部分)
# 1.3 读取并解析论文关系数据
# 读取论文关系数据,并将其转化为数据
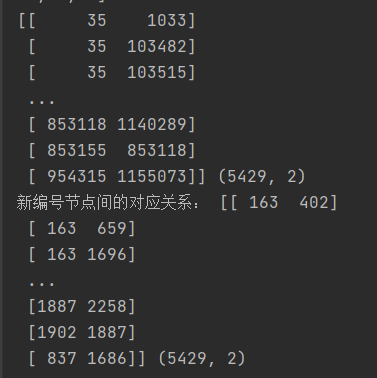
edges = np.genfromtxt(path/'cora.cites',dtype=np.int32) # 将数据集中论文的引用关系以数据的形式读入
print(edges,np.shape(edges))
# 转化为新编号节点间的关系:将数据集中论文ID表示的关系转化为重新编号后的关系
edges = np.asarray([paper2idx[e] for e in edges.flatten()],np.int32).reshape(edges.shape)
print("新编号节点间的对应关系:",edges,edges.shape)
# 计算邻接矩阵,行与列都是论文个数:由论文引用关系所表示的图结构生成邻接矩阵。
adj = coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),shape=(len(labels), len(labels)), dtype=np.float32)
# 生成无向图对称矩阵:将有向图的邻接矩阵转化为无向图的邻接矩阵。Tip:转化为无向图的原因:主要用于对论文的分类,论文的引用关系主要提供单个特征之间的关联,故更看重是不是有关系,所以无向图即可。
adj_long = adj.multiply(adj.T < adj)
adj = adj_long + adj_long.T输出:
2.4 加工图结构的矩阵数据
对图结构的矩阵数据进行加工,使其更好地表现出图结构特征,并参与神经网络的模型计算。
2.4.1 加工图结构的矩阵数据的步骤
1、对每个节点的特征数据进行归一化处理。
2、为邻接矩阵的对角线补1:因为在分类任务中,邻接矩阵主要作用是通过论文间的关联来帮助节点分类。对于对角线上的节点,表示的意义是自己与自己的关联。将对角线节点设为1(自环图)、表明节点也会帮助到分类任务。
3、对补1后的邻接矩阵进行归一化处理。

2.4.2 代码实现:加工图结构的矩阵数据----Cora_GNN.py(第4部分)
# 1.4 加工图结构的矩阵数据
def normalize(mx): # 定义函数,对矩阵的数据进行归一化处理rowsum = np.array(mx.sum(1)) # 计算每一篇论文的字数==>02 对A中的边数求和,计算出矩阵A的度矩阵D^的特征向量r_inv = (rowsum ** -1).flatten() # 取总字数的倒数==>03 对矩阵A的度矩阵D^的特征向量求逆,并得到D^逆的特征向量r_inv[np.isinf(r_inv)] = 0.0 # 将NaN值取为0r_mat_inv = diags(r_inv) # 将总字数的倒数变为对角矩阵===》对图结构的度矩阵求逆==>04 D^逆的特征向量转化为对角矩阵,得到D^逆mx = r_mat_inv.dot(mx) # 左乘一个矩阵,相当于每个元素除以总数===》对每个论文顶点的边进行归一化处理==>05 计算D^逆与A加入自环(对角线为1)的邻接矩阵所得A^的点积,得到拉普拉斯矩阵。return mx
# 对features矩阵进行归一化处理(每行总和为1)
features = normalize(features) #在函数normalize()中,分为两步对邻接矩阵进行处理。1、将每篇论文总字数的倒数变成对角矩阵。该操作相当于对图结构的度矩阵求逆。2、用度矩阵的逆左乘邻接矩阵,相当于对图中每个论文顶点的边进行归一化处理。
# 对邻接矩阵的对角线添1,将其变为自循环图,同时对其进行归一化处理
adj = normalize(adj + eye(adj.shape[0])) # 对角线补1==>01实现加入自环的邻接矩阵A2.5 将数据转化为张量,并分配运算资源
将加工好的图结构矩阵数据转为PyTorch支持的张量类型,并将其分成3份,分别用来进行训练、测试和验证。
2.5.1 代码实现:将数据转化为张量,并分配运算资源----Cora_GNN.py(第5部分)
# 1.5 将数据转化为张量,并分配运算资源
adj = torch.FloatTensor(adj.todense()) # 节点间关系 todense()方法将其转换回稠密矩阵。
features = torch.FloatTensor(features.todense()) # 节点自身的特征
labels = torch.LongTensor(labels) # 对每个节点的分类标签# 划分数据集
n_train = 200 # 训练数据集大小
n_val = 300 # 验证数据集大小
n_test = len(features) - n_train - n_val # 测试数据集大小
np.random.seed(34)
idxs = np.random.permutation(len(features)) # 将原有的索引打乱顺序# 计算每个数据集的索引
idx_train = torch.LongTensor(idxs[:n_train]) # 根据指定训练数据集的大小并划分出其对应的训练数据集索引
idx_val = torch.LongTensor(idxs[n_train:n_train+n_val])# 根据指定验证数据集的大小并划分出其对应的验证数据集索引
idx_test = torch.LongTensor(idxs[n_train+n_val:])# 根据指定测试数据集的大小并划分出其对应的测试数据集索引# 分配运算资源
adj = adj.to(device)
features = features.to(device)
labels = labels.to(device)
idx_train = idx_train.to(device)
idx_val = idx_val.to(device)
idx_test = idx_test.to(device)2.6 图卷积
图卷积的本质是维度变换,即将每个含有in维的节点特征数据变换成含有out维的节点特征数据。
图卷积的操作将输入的节点特征、权重参数、加工后的邻接矩阵三者放在一起执行点积运算。
权重参数是个in×out大小的矩阵,其中in代表输入节点的特征维度、out代表最终要输出的特征维度。将权重参数在维度变换中的功能当作一个全连接网络的权重来理解,只不过在图卷积中,它会比全连接网络多了执行节点关系信息的点积运算。
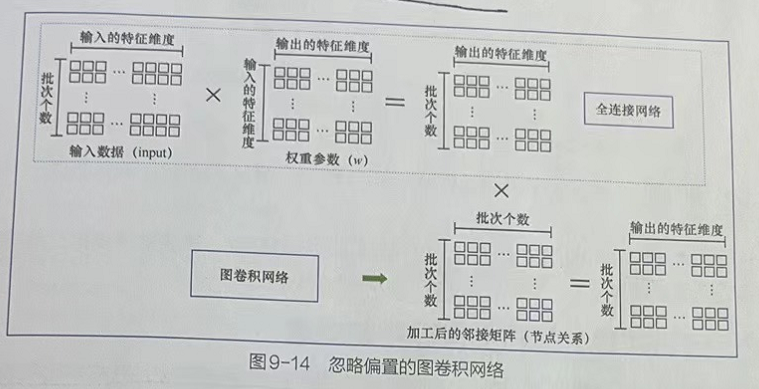
如上图所示,列出全连接网络和图卷积网络在忽略偏置后的关系。从中可以很清晰地看出,图卷积网络其实就是在全连接网络基础之上增加了节点关系信息。
2.6.1 代码实现:定义Mish激活函数与图卷积操作类----Cora_GNN.py(第6部分)
在上图的所示的算法基础增加偏置,定义GraphConvolution类
# 1.6 定义Mish激活函数与图卷积操作类
def mish(x): # 性能优于RElu函数return x * (torch.tanh(F.softplus(x)))
# 图卷积类
class GraphConvolution(nn.Module):def __init__(self,f_in,f_out,use_bias = True,activation=mish):# super(GraphConvolution, self).__init__()super().__init__()self.f_in = f_inself.f_out = f_outself.use_bias = use_biasself.activation = activationself.weight = nn.Parameter(torch.FloatTensor(f_in, f_out))self.bias = nn.Parameter(torch.FloatTensor(f_out)) if use_bias else Noneself.initialize_weights()def initialize_weights(self):# 对参数进行初始化if self.activation is None: # 初始化权重nn.init.xavier_uniform_(self.weight)else:nn.init.kaiming_uniform_(self.weight, nonlinearity='leaky_relu')if self.use_bias:nn.init.zeros_(self.bias)def forward(self,input,adj): # 实现模型的正向处理流程support = torch.mm(input,self.weight) # 节点特征与权重点积:torch.mm()实现矩阵的相乘,仅支持二位矩阵。若是多维矩则使用torch.matmul()output = torch.mm(adj,support) # 将加工后的邻接矩阵放入点积运算if self.use_bias:output.add_(self.bias) # 加入偏置if self.activation is not None:output = self.activation(output) # 激活函数处理return output2.7 搭建带有Multi_Sample Dropout的多层图卷积网络模型---Cora_GNN_MUti-sample-Dropout.py(修改的第1部分)
# 1.7 搭建带有Multi_Sample Dropout的多层图卷积网络模型:根据GCN模型,
class GCNTD(nn.Module):def __init__(self,f_in,n_classes,hidden=[16],dropout_num = 8,dropout_p=0.5 ): # 默认使用8组dropout,每组丢弃率为0.5# super(GCNTD, self).__init__()super().__init__()layer = []for f_in,f_out in zip([f_in]+hidden[:-1],hidden):layer += [GraphConvolution(f_in,f_out)]self.layers = nn.Sequential(*layer)# 默认使用8个Dropout分支self.dropouts = nn.ModuleList([nn.Dropout(dropout_p,inplace=False) for _ in range(dropout_num)] )self.out_layer = GraphConvolution(f_out,n_classes,activation=None)def forward(self,x,adj):# Multi - sampleDropout结构默认使用了8个Dropout分支。在前向传播过程中,具体步骤如下。# ①输入样本统一经过多层图卷积神经网络来到Dropout层。# ②由每个分支的Dropout按照指定的丢弃率对多层图卷积的结果进行Dropout处理。# ③将每个分支的Dropout数据传入到输出层,分别得到结果。# ④将所有结果加起来,生成最终结果。for layer,d in zip(self.layers,self.dropouts):x = layer(x,adj)if len(self.dropouts) == 0:return self.out_layer(x,adj)else:for i, dropout in enumerate(self.dropouts): # 将每组的输出叠加if i == 0 :out = dropout(x)out = self.out_layer(out,adj)else:temp_out = dropout(x)out = out + self.out_layer(temp_out,adj)return out # 返回结果n_labels = labels.max().item() + 1 # 获取分类个数7
n_features = features.shape[1] # 获取节点特征维度 1433
print(n_labels,n_features) # 输出7与1433def accuracy(output,y): # 定义函数计算准确率return (output.argmax(1) == y).type(torch.float32).mean().item()### 定义函数来实现模型的训练过程。与深度学习任务不同,图卷积在训练时需要传入样本间的关系数据。
# 因为该关系数据是与节点数相等的方阵,所以传入的样本数也要与节点数相同,在计算loss值时,可以通过索引从总的运算结果中取出训练集的结果。
# 在图卷积任务中,无论是用模型进行预测还是训练,都需要将全部的图结构方阵输入。
def step(): # 定义函数来训练模型model.train()optimizer.zero_grad()output = model(features,adj) # 将全部数据载入模型,只用训练数据计算损失loss = F.cross_entropy(output[idx_train],labels[idx_train])acc = accuracy(output[idx_train],labels[idx_train]) # 计算准确率loss.backward()optimizer.step()return loss.item(),accdef evaluate(idx): # 定义函数来评估模型model.eval()output = model(features, adj) # 将全部数据载入模型loss = F.cross_entropy(output[idx], labels[idx]).item() # 用指定索引评估模型结果return loss, accuracy(output[idx], labels[idx])2.8 代码实现:训练可视化---Cora_GNN_MUti-sample-Dropout.py(修改的第2部分)
model = GCNTD(n_features,n_labels,hidden=[16,32,16]).to(device)
from ranger import *
from functools import partial # 引入偏函数对Ranger设置参数
opt_func = partial(Ranger,betas=(0.9,0.99),eps=1e-6)
optimizer = opt_func(model.parameters())from tqdm import tqdm
# 训练模型
epochs = 400
print_steps = 50
train_loss, train_acc = [], []
val_loss, val_acc = [], []
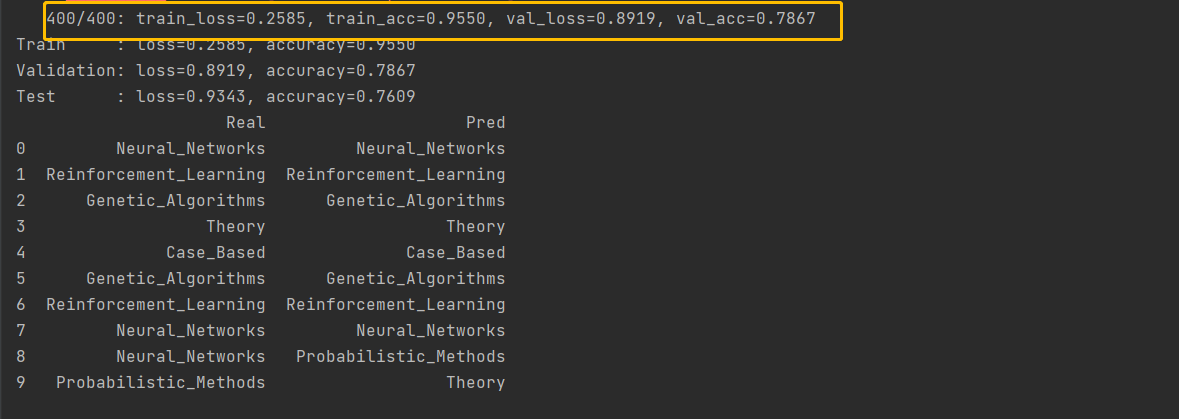
for i in tqdm(range(epochs)):tl,ta = step()train_loss = train_loss + [tl]train_acc = train_acc + [ta]if (i+1) % print_steps == 0 or i == 0:tl,ta = evaluate(idx_train)vl,va = evaluate(idx_val)val_loss = val_loss + [vl]val_acc = val_acc + [va]print(f'{i + 1:6d}/{epochs}: train_loss={tl:.4f}, train_acc={ta:.4f}' + f', val_loss={vl:.4f}, val_acc={va:.4f}')# 输出最终结果
final_train, final_val, final_test = evaluate(idx_train), evaluate(idx_val), evaluate(idx_test)
print(f'Train : loss={final_train[0]:.4f}, accuracy={final_train[1]:.4f}')
print(f'Validation: loss={final_val[0]:.4f}, accuracy={final_val[1]:.4f}')
print(f'Test : loss={final_test[0]:.4f}, accuracy={final_test[1]:.4f}')# 可视化训练过程
fig, axes = plt.subplots(1, 2, figsize=(15,5))
ax = axes[0]
axes[0].plot(train_loss[::print_steps] + [train_loss[-1]], label='Train')
axes[0].plot(val_loss, label='Validation')
axes[1].plot(train_acc[::print_steps] + [train_acc[-1]], label='Train')
axes[1].plot(val_acc, label='Validation')
for ax,t in zip(axes, ['Loss', 'Accuracy']): ax.legend(), ax.set_title(t, size=15)# 输出模型的预测结果
output = model(features, adj)
samples = 10
idx_sample = idx_test[torch.randperm(len(idx_test))[:samples]]
# 将样本标签与预测结果进行比较
idx2lbl = {v:k for k,v in lbl2idx.items()}
df = pd.DataFrame({'Real': [idx2lbl[e] for e in labels[idx_sample].tolist()],'Pred': [idx2lbl[e] for e in output[idx_sample].argmax(1).tolist()]})
print(df)输出:
仅仅经过400轮就可以得到更好的结果
3 代码总览
Cora_GNN_MUti-sample-Dropout.py
from pathlib import Path # 引入提升路径的兼容性
# 引入矩阵运算的相关库
import numpy as np
import pandas as pd
from scipy.sparse import coo_matrix,csr_matrix,diags,eye
# 引入深度学习框架库
import torch
from torch import nn
import torch.nn.functional as F
# 引入绘图库
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"# 1.1 导入基础模块,并设置运行环境
# 输出计算资源情况
device = torch.device('cuda')if torch.cuda.is_available() else torch.device('cpu')
print(device) # 输出 cuda# 输出样本路径
path = Path('./data/cora')
print(path) # 输出 cuda# 1.2 读取并解析论文数据
# 读取论文内容数据,将其转化为数据
paper_features_label = np.genfromtxt(path/'cora.content',dtype=np.str_) # 使用Path对象的路径构造,实例化的内容为cora.content。path/'cora.content'表示路径为'data/cora/cora.content'的字符串
print(paper_features_label,np.shape(paper_features_label)) # 打印数据集内容与数据的形状# 取出数据集中的第一列:论文ID
papers = paper_features_label[:,0].astype(np.int32)
print("论文ID序列:",papers) # 输出所有论文ID
# 论文重新编号,并将其映射到论文ID中,实现论文的统一管理
paper2idx = {k:v for v,k in enumerate(papers)}# 将数据中间部分的字标签取出,转化成矩阵
features = csr_matrix(paper_features_label[:,1:-1],dtype=np.float32)
print("字标签矩阵的形状:",np.shape(features)) # 字标签矩阵的形状# 将数据的最后一项的文章分类属性取出,转化为分类的索引
labels = paper_features_label[:,-1]
lbl2idx = { k:v for v,k in enumerate(sorted(np.unique(labels)))}
labels = [lbl2idx[e] for e in labels]
print("论文类别的索引号:",lbl2idx,labels[:5])# 1.3 读取并解析论文关系数据
# 读取论文关系数据,并将其转化为数据
edges = np.genfromtxt(path/'cora.cites',dtype=np.int32) # 将数据集中论文的引用关系以数据的形式读入
print(edges,np.shape(edges))
# 转化为新编号节点间的关系:将数据集中论文ID表示的关系转化为重新编号后的关系
edges = np.asarray([paper2idx[e] for e in edges.flatten()],np.int32).reshape(edges.shape)
print("新编号节点间的对应关系:",edges,edges.shape)
# 计算邻接矩阵,行与列都是论文个数:由论文引用关系所表示的图结构生成邻接矩阵。
adj = coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),shape=(len(labels), len(labels)), dtype=np.float32)
# 生成无向图对称矩阵:将有向图的邻接矩阵转化为无向图的邻接矩阵。Tip:转化为无向图的原因:主要用于对论文的分类,论文的引用关系主要提供单个特征之间的关联,故更看重是不是有关系,所以无向图即可。
adj_long = adj.multiply(adj.T < adj)
adj = adj_long + adj_long.T# 1.4 加工图结构的矩阵数据
def normalize(mx): # 定义函数,对矩阵的数据进行归一化处理rowsum = np.array(mx.sum(1)) # 计算每一篇论文的字数==>02 对A中的边数求和,计算出矩阵A的度矩阵D^的特征向量r_inv = (rowsum ** -1).flatten() # 取总字数的倒数==>03 对矩阵A的度矩阵D^的特征向量求逆,并得到D^逆的特征向量r_inv[np.isinf(r_inv)] = 0.0 # 将NaN值取为0r_mat_inv = diags(r_inv) # 将总字数的倒数变为对角矩阵===》对图结构的度矩阵求逆==>04 D^逆的特征向量转化为对角矩阵,得到D^逆mx = r_mat_inv.dot(mx) # 左乘一个矩阵,相当于每个元素除以总数===》对每个论文顶点的边进行归一化处理==>05 计算D^逆与A加入自环(对角线为1)的邻接矩阵所得A^的点积,得到拉普拉斯矩阵。return mx
# 对features矩阵进行归一化处理(每行总和为1)
features = normalize(features) #在函数normalize()中,分为两步对邻接矩阵进行处理。1、将每篇论文总字数的倒数变成对角矩阵。该操作相当于对图结构的度矩阵求逆。2、用度矩阵的逆左乘邻接矩阵,相当于对图中每个论文顶点的边进行归一化处理。
# 对邻接矩阵的对角线添1,将其变为自循环图,同时对其进行归一化处理
adj = normalize(adj + eye(adj.shape[0])) # 对角线补1==>01实现加入自环的邻接矩阵A# 1.5 将数据转化为张量,并分配运算资源
adj = torch.FloatTensor(adj.todense()) # 节点间关系 todense()方法将其转换回稠密矩阵。
features = torch.FloatTensor(features.todense()) # 节点自身的特征
labels = torch.LongTensor(labels) # 对每个节点的分类标签# 划分数据集
n_train = 200 # 训练数据集大小
n_val = 300 # 验证数据集大小
n_test = len(features) - n_train - n_val # 测试数据集大小
np.random.seed(34)
idxs = np.random.permutation(len(features)) # 将原有的索引打乱顺序# 计算每个数据集的索引
idx_train = torch.LongTensor(idxs[:n_train]) # 根据指定训练数据集的大小并划分出其对应的训练数据集索引
idx_val = torch.LongTensor(idxs[n_train:n_train+n_val])# 根据指定验证数据集的大小并划分出其对应的验证数据集索引
idx_test = torch.LongTensor(idxs[n_train+n_val:])# 根据指定测试数据集的大小并划分出其对应的测试数据集索引# 分配运算资源
adj = adj.to(device)
features = features.to(device)
labels = labels.to(device)
idx_train = idx_train.to(device)
idx_val = idx_val.to(device)
idx_test = idx_test.to(device)# 1.6 定义Mish激活函数与图卷积操作类
def mish(x): # 性能优于RElu函数return x * (torch.tanh(F.softplus(x)))
# 图卷积类
class GraphConvolution(nn.Module):def __init__(self,f_in,f_out,use_bias = True,activation=mish):# super(GraphConvolution, self).__init__()super().__init__()self.f_in = f_inself.f_out = f_outself.use_bias = use_biasself.activation = activationself.weight = nn.Parameter(torch.FloatTensor(f_in, f_out))self.bias = nn.Parameter(torch.FloatTensor(f_out)) if use_bias else Noneself.initialize_weights()def initialize_weights(self):# 对参数进行初始化if self.activation is None: # 初始化权重nn.init.xavier_uniform_(self.weight)else:nn.init.kaiming_uniform_(self.weight, nonlinearity='leaky_relu')if self.use_bias:nn.init.zeros_(self.bias)def forward(self,input,adj): # 实现模型的正向处理流程support = torch.mm(input,self.weight) # 节点特征与权重点积:torch.mm()实现矩阵的相乘,仅支持二位矩阵。若是多维矩则使用torch.matmul()output = torch.mm(adj,support) # 将加工后的邻接矩阵放入点积运算if self.use_bias:output.add_(self.bias) # 加入偏置if self.activation is not None:output = self.activation(output) # 激活函数处理return output# 1.7 搭建带有Multi_Sample Dropout的多层图卷积网络模型:根据GCN模型,
class GCNTD(nn.Module):def __init__(self,f_in,n_classes,hidden=[16],dropout_num = 8,dropout_p=0.5 ): # 默认使用8组dropout,每组丢弃率为0.5# super(GCNTD, self).__init__()super().__init__()layer = []for f_in,f_out in zip([f_in]+hidden[:-1],hidden):layer += [GraphConvolution(f_in,f_out)]self.layers = nn.Sequential(*layer)# 默认使用8个Dropout分支self.dropouts = nn.ModuleList([nn.Dropout(dropout_p,inplace=False) for _ in range(dropout_num)] )self.out_layer = GraphConvolution(f_out,n_classes,activation=None)def forward(self,x,adj):# Multi - sampleDropout结构默认使用了8个Dropout分支。在前向传播过程中,具体步骤如下。# ①输入样本统一经过多层图卷积神经网络来到Dropout层。# ②由每个分支的Dropout按照指定的丢弃率对多层图卷积的结果进行Dropout处理。# ③将每个分支的Dropout数据传入到输出层,分别得到结果。# ④将所有结果加起来,生成最终结果。for layer,d in zip(self.layers,self.dropouts):x = layer(x,adj)if len(self.dropouts) == 0:return self.out_layer(x,adj)else:for i, dropout in enumerate(self.dropouts): # 将每组的输出叠加if i == 0 :out = dropout(x)out = self.out_layer(out,adj)else:temp_out = dropout(x)out = out + self.out_layer(temp_out,adj)return out # 返回结果
n_labels = labels.max().item() + 1 # 获取分类个数7
n_features = features.shape[1] # 获取节点特征维度 1433
print(n_labels,n_features) # 输出7与1433def accuracy(output,y): # 定义函数计算准确率return (output.argmax(1) == y).type(torch.float32).mean().item()### 定义函数来实现模型的训练过程。与深度学习任务不同,图卷积在训练时需要传入样本间的关系数据。
# 因为该关系数据是与节点数相等的方阵,所以传入的样本数也要与节点数相同,在计算loss值时,可以通过索引从总的运算结果中取出训练集的结果。
# 在图卷积任务中,无论是用模型进行预测还是训练,都需要将全部的图结构方阵输入。
def step(): # 定义函数来训练模型model.train()optimizer.zero_grad()output = model(features,adj) # 将全部数据载入模型,只用训练数据计算损失loss = F.cross_entropy(output[idx_train],labels[idx_train])acc = accuracy(output[idx_train],labels[idx_train]) # 计算准确率loss.backward()optimizer.step()return loss.item(),accdef evaluate(idx): # 定义函数来评估模型model.eval()output = model(features, adj) # 将全部数据载入模型loss = F.cross_entropy(output[idx], labels[idx]).item() # 用指定索引评估模型结果return loss, accuracy(output[idx], labels[idx])model = GCNTD(n_features,n_labels,hidden=[16,32,16]).to(device)
from ranger import *
from functools import partial # 引入偏函数对Ranger设置参数
opt_func = partial(Ranger,betas=(0.9,0.99),eps=1e-6)
optimizer = opt_func(model.parameters())from tqdm import tqdm
# 训练模型
epochs = 400
print_steps = 50
train_loss, train_acc = [], []
val_loss, val_acc = [], []
for i in tqdm(range(epochs)):tl,ta = step()train_loss = train_loss + [tl]train_acc = train_acc + [ta]if (i+1) % print_steps == 0 or i == 0:tl,ta = evaluate(idx_train)vl,va = evaluate(idx_val)val_loss = val_loss + [vl]val_acc = val_acc + [va]print(f'{i + 1:6d}/{epochs}: train_loss={tl:.4f}, train_acc={ta:.4f}' + f', val_loss={vl:.4f}, val_acc={va:.4f}')# 输出最终结果
final_train, final_val, final_test = evaluate(idx_train), evaluate(idx_val), evaluate(idx_test)
print(f'Train : loss={final_train[0]:.4f}, accuracy={final_train[1]:.4f}')
print(f'Validation: loss={final_val[0]:.4f}, accuracy={final_val[1]:.4f}')
print(f'Test : loss={final_test[0]:.4f}, accuracy={final_test[1]:.4f}')# 可视化训练过程
fig, axes = plt.subplots(1, 2, figsize=(15,5))
ax = axes[0]
axes[0].plot(train_loss[::print_steps] + [train_loss[-1]], label='Train')
axes[0].plot(val_loss, label='Validation')
axes[1].plot(train_acc[::print_steps] + [train_acc[-1]], label='Train')
axes[1].plot(val_acc, label='Validation')
for ax,t in zip(axes, ['Loss', 'Accuracy']): ax.legend(), ax.set_title(t, size=15)# 输出模型的预测结果
output = model(features, adj)
samples = 10
idx_sample = idx_test[torch.randperm(len(idx_test))[:samples]]
# 将样本标签与预测结果进行比较
idx2lbl = {v:k for k,v in lbl2idx.items()}
df = pd.DataFrame({'Real': [idx2lbl[e] for e in labels[idx_sample].tolist()],'Pred': [idx2lbl[e] for e in output[idx_sample].argmax(1).tolist()]})
print(df)

:定点域+谱域+图卷积的操作步骤)







)
)
机制-不过如此)






