同学你好!本文章于2021年末编写,获得广泛的好评!
故在2022年末对本系列进行填充与更新,欢迎大家订阅最新的专栏,获取基于Pytorch1.10版本的理论代码(2023版)实现,
Pytorch深度学习·理论篇(2023版)目录地址为:
CSDN独家 | 全网首发 | Pytorch深度学习·理论篇(2023版)目录本专栏将通过系统的深度学习实例,从可解释性的角度对深度学习的原理进行讲解与分析,通过将深度学习知识与Pytorch的高效结合,帮助各位新入门的读者理解深度学习各个模板之间的关系,这些均是在Pytorch上实现的,可以有效的结合当前各位研究生的研究方向,设计人工智能的各个领域,是经过一年时间打磨的精品专栏!https://v9999.blog.csdn.net/article/details/127587345欢迎大家订阅(2023版)理论篇
以下为2021版原文~~~~

1 Inception系列模型
Incepton系列模型包括V1、V2、V3、V4等版本,主要解决深层网络的三个问题:
- 训练数据集有限,参数太多,容易过拟合;
- 网络越大,计算复杂度越大,难以应用;
- 网络越深,梯度越往后传,越容易消失(梯度弥散),难以优化模型。
1.1 多分支结构
原始的Inception模型采用多分支结构(见图1-1),它将1×1卷积、3×3卷积最大池化堆叠在一起。这种结构既可以增加网络的宽度,又可以增强网络对不同尺寸的适应性。
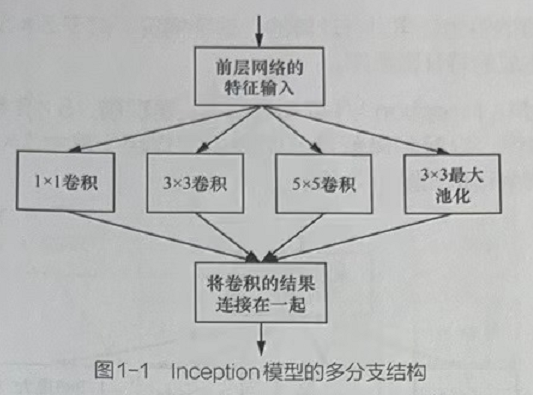
Inception模型包含3种不同尺寸的卷积和1个最大池化,增强了网络对不同尺寸的适应性。
Inception模型可以让网络的深度和宽度高效率地扩充,提高准确率。
Inceρtion模型本身如同大网络中的一个小网络,其结构可以反复堆叠在一起形成大网络。
1.2 全局均值池化(文章来源:Network in Network)
全局均值池化是指在平均池化层中使用同等大小的过滤器对特征进行过滤。一般使用它用来代替深层网络结构中最后的全连接输出层。
1.2.1 全局均值池化的具体用法
在卷积处理之后,对每个特征图的一整张图片进行全局均值池化,生成一个值,即每个特征图相当于一个输出特征,这个特征就表示我们输出类的特征。
即在做1000个分类任务时,最后一层的特征图个数要选择1000,这样就可以直接得出分类。
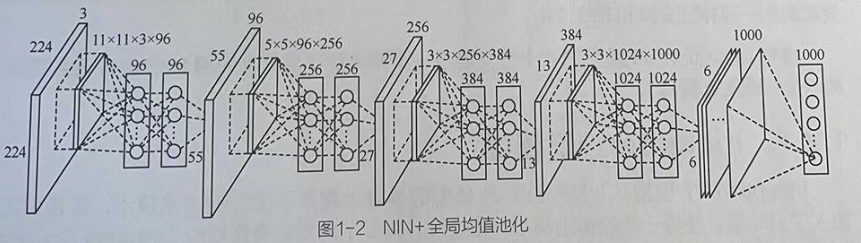
1.2.2 Network in Network中的实现
作者利用其进行1000个物体分类,最后设计了一个4层的NIN(Network In Network)+全局均值池化,如图1-2所示。
2 Inception V1模型
Inception V1模型在原有的Inception模型上做了一些改进。原因是在Inception模型中,
3 Inception V2模型
卷积核是针对其上一层的输出结果进行计算的,因此会存在,5×5卷积核所需的计算量就会很大,所生成的特征图很厚。
为了避免这一现象,InceptionV1模型在3×3卷积前、5×5卷积前、3×3最大池化后分别加上了1×1卷积,以起到降低特征图厚度的作用(其中1×1卷积主要用来降维)
3.1 InceptionV1模型图
InceptionV1模型中有4个分支。
3.1.1 分支介绍
第1个分支:对输入进行1×1卷积,1×1卷积既可以跨通道组织信息,提高网络的表达能力,又可以对输出通道升维和降维。
第2个分支:先使用1×1卷积,然后使用3×3卷积,相当于进行了两次特征变换。
第3个分支:先使用1×1卷积,然后使用5×5卷积。
第4个分支:3×3最大池化后直接使用1×1卷积。
3.1.2 InceptionV1模型图

3.1.3 InceptionV1的特点
4个分支都使用了1×1卷积,有的分支只使用了1×1卷积,有的分支使用了1×1的卷积后也会再使用其他尺寸卷积。
因为1×1卷积的性价比很高,用很小的计算量就能增加一层特征变换和非线性化。最终lnceptionV1模型的4个分支通过一个聚合操作合并(使用torch.cat函数在输出通道数的维度上聚合)。
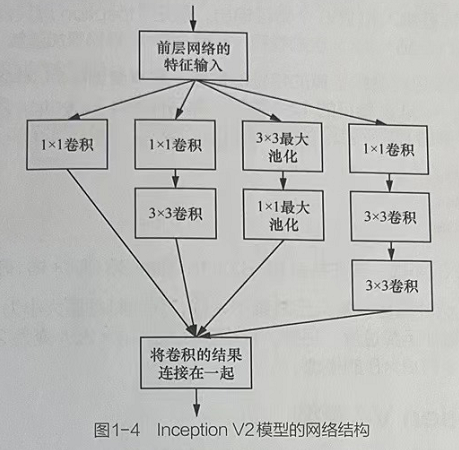
4 Inception V2模型
4.1 Inception V2模型的改进措施
Inception V2模型在lnceptionV1模型的卷积之后加入了BN层,使每一层的输出都归一化处理,减少了内部协变量移位问题;同时还使用梯度截断的技术,增加了训练的稳定性。
lnceptionV2模型还借鉴VGG模型,用两个3×3卷积替代InceptionV1模型中的5×5卷积,降低参数数量,提升运算速度。
4.2 Inception V2 模型
5 Inception V3模型
Inception V3模型没有再加入其他的技术,只是将Inception V2的卷积核变得更小
5.1 Inception V3模型具体做法
将nception V2模型的3×3分解成两个一维的卷积(1×3,3×1)。这种方法主要是基于线性代数的原理,即一个[n,n]的矩阵,可以分解成矩阵[n,1]×矩阵[1,n]。
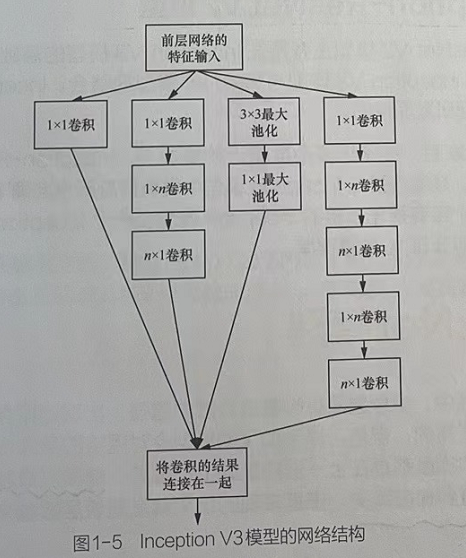
5.2 Inception V3模型的实际效果计算
假设有256个特征输入和256个特征输出,假定lnception层只能执行3×3卷积,也就是总共要完成256×256×3×3次的卷积(589824次乘积累加运算)。
假设现在需要减少进行卷积运算的特征的数量,将其变为64(即256/4)个。在这种情况下,首先进行256→64的特征的1×1卷积,然后在所有Inception层的分支上进行64次卷积,最后使用一个来自64→256的特征的1×1卷积。
256×64×1×1=16384
64×64×3×3 = 36864
64×256×1×1=16384
相比之前的589824次,现在共有69632(16384+36864+16384)次的计算量。
在实际测试中,这种结构在前几层效果不太好,但对特征图大小为12~20的中间层效果明显,也可以大大增加运算速度。另外,网络输入从224×224变为299×299,设计了35×35/17×17/8×8的模块。
6 Inception V4模型
6.1 Inception V4模型改进手段
在InceptionV3模型的基础上结合残差连接技术进行结构的优化调整,通过二者的结合,得到了两个比较出色的网络模型。
6.2 lnception V4模型
Inception V4模型仅是在InceptionV3模型的基础上由4个卷积分支变为6个卷积分支,但没有使用残差连接。
6.3 Inception-ResNet V2模型
Inception-ResNet V2模型主要是在InceptionV3模型的基础上加入ResNet模型的残差连接,是lnceptionV3模型与ResNet模型的结合。
残差连接在Inception模型中具有提高网络准确率,而且不会增加计算量的作用。
6.4 Inception-ResNetV2模型与lnception V4对比
在网络复杂度相近的情况下,Inception-ResNetV2模型略优于Inception V4模型。
通过将3个带有残差连接的inception模型和一个lnceptionV4模型组合,就可以在lmagelNet上得到3.08%的错误率。











)




)


寄存器版本GPIO)