数组的定义和特性
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
-
线性表(Linear List):数组、链表、队列、栈 非线性表:树 图
-
连续的内存空间和相同类型的数据
-
性能 低效“插入”和“删除”

-
警惕 数组越界
数组和链表的区别
“链表适合插入、删除,时间复杂度 O(1);数组适合查找,数组支持随机访问,根据下标随机访问的时间复杂度为 O(1)”。
(数组是适合查找操作,但是查找的时间复杂度并不为 O(1)。即便是排好序的数组,你用二分查找,时间复杂度也是 O(logn))
数组缺点
1)若申请内存空间很大,比如100M,但若内存空间没有100M的连续空间时,则会申请失败,尽管内存可用空间超过100M。
2)大小固定,若存储空间不足,需进行扩容,一旦扩容就要进行数据复制,而这时非常费时的。
链表缺点
1)内存空间消耗更大,因为需要额外的空间存储指针信息。
2)对链表进行频繁的插入和删除操作,会导致频繁的内存申请和释放,容易造成内存碎片,如果是Java语言,还可能会造成频繁的GC(自动垃圾回收器)操作。
如何选择?
数组简单易用,在实现上使用连续的内存空间,可以借助CPU的缓冲机制预读数组中的数据,所以访问效率更高,而链表在内存中并不是连续存储,所以对CPU缓存不友好,没办法预读。
如果代码对内存的使用非常苛刻,那数组就更适合。
容器能否完全替代数组?
Java 使用ArrayList
ArrayList 最大的优势就是可以将很多数组操作的细节封装起来。比如前面提到的数组插入、删除数据时需要搬移其他数据等。另外,它还有一个优势,就是支持动态扩容(不足扩容1.5倍)。
-
Java ArrayList 无法存储基本类型,比如 int、long,需要封装为 Integer、Long 类,而 Autoboxing、Unboxing 则有一定的性能消耗,所以如果特别关注性能,或者希望使用基本类型,就可以选用数组。
-
如果数据大小事先已知,并且对数据的操作非常简单,用不到 ArrayList 提供的大部分方法,也可以直接使用数组。
-
当要表示多维数组时,用数组往往会更加直观。比如 Object[][] array;而用容器的话则需要这样定义:ArrayList object array。
对于业务开发,直接使用容器就足够了,省时省力。毕竟损耗一丢丢性能,完全不会影响到系统整体的性能。但如果你是做一些非常底层的开发,比如开发网络框架,性能的优化需要做到极致,这个时候数组就会优于容器,成为首选。
为什么很多编程语言中数组都从0开始编号?
-
移角度理解a[0] 0为偏移量,如果从1计数,会多出K-1。增加cpu负担。

-
为什么循环要写成for(int i = 0;i<3;i++) 而不是for(int i = 0 ;i<=2;i++)。第一个直接就可以算出3-0 = 3 有三个数据,而后者 2-0+1个数据,多出1个加法运算,很恼火。
-
有一定的历史原因 C语言设计者用0开始计数数组下标 其他高级语言纷纷效仿
链表的定义和特性
- 和数组一样,链表也是一种线性表。
- 从内存结构来看,链表的内存结构是不连续的内存空间,是将一组零散的内存块串联起来,从而进行数据存储的数据结构。
- 链表中的每一个内存块被称为节点Node。节点除了存储数据外,还需记录链上下一个节点的地址,即后继指针next。
数组需要一块连续的内存空间来存储,对内存的要求比较高。
链表并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用。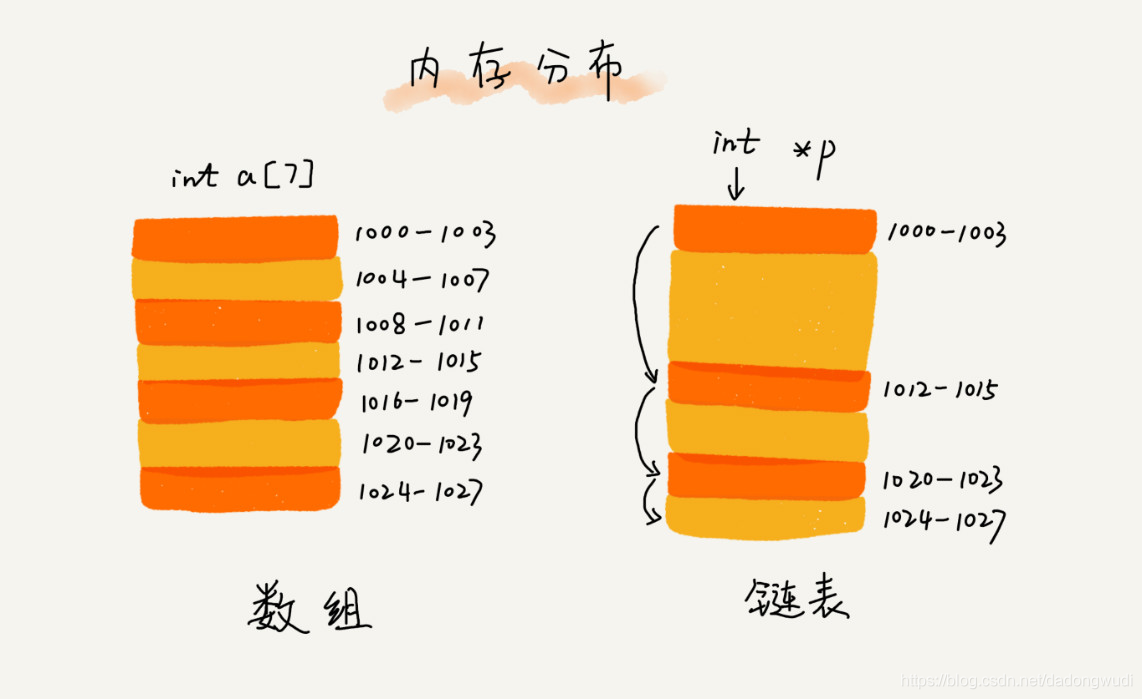
链表常见分类
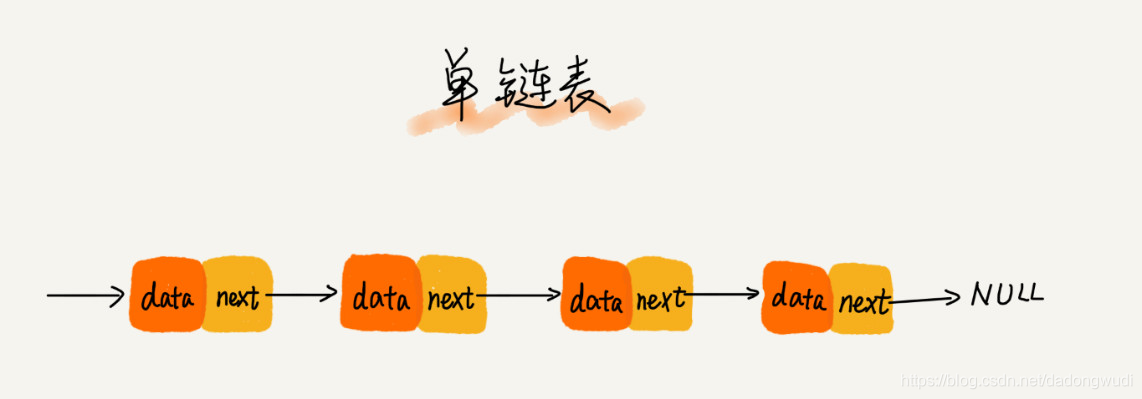
单链表
1)每个节点只包含一个指针,即后继指针。
2)单链表有两个特殊的节点,即首节点和尾节点。为什么特殊?用首节点地址表示整条链表,尾节点的后继指针指向空地址null。
3)性能特点:插入和删除节点的时间复杂度为O(1),查找的时间复杂度为O(n)。
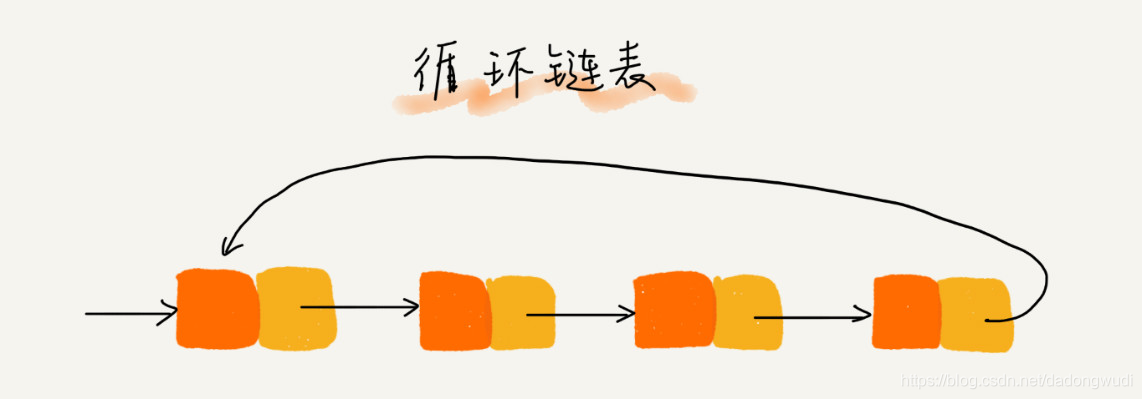
循环链表
1)除了尾节点的后继指针指向首节点的地址外均与单链表一致。
2)适用于存储有循环特点的数据,比如约瑟夫问题。
循环链表是一种特殊的单链表。和单链表相比,循环链表的优点是从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表。
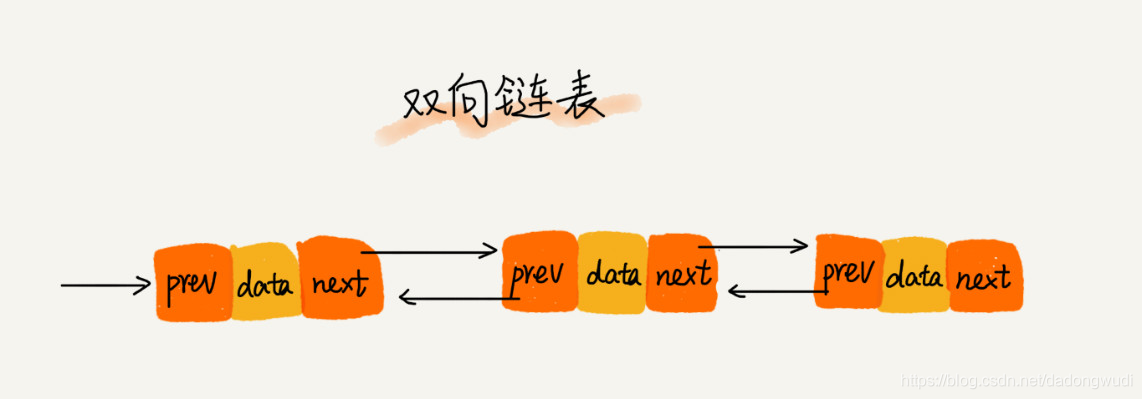
双向链表
1)节点除了存储数据外,还有两个指针分别指向前一个节点地址(前驱指针prev)和下一个节点地址(后继指针next)。
2)首节点的前驱指针prev和尾节点的后继指针均指向空地址。
3)性能特点:
3.1 和单链表相比,存储相同的数据,需要消耗更多的存储空间。
3.2 插入、删除操作比单链表效率更高O(1)级别。以删除操作为例,删除操作分为2种情况:给定数据值删除对应节点和给定节点地址删除节点。对于前一种情况,单链表和双向链表都需要从头到尾进行遍历从而找到对应节点进行删除,时间复杂度为O(n)。对于第二种情况,要进行删除操作必须找到前驱节点,单链表需要从头到尾进行遍历直到p->next = q,时间复杂度为O(n),而双向链表可以直接找到前驱节点,时间复杂度为O(1)。
3.3对于一个有序链表,双向链表的按值查询效率要比单链表高一些。因为我们可以记录上次查找的位置p,每一次查询时,根据要查找的值与p的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。
双向链表需要额外的两个空间来存储后继结点和前驱结点的地址。所以,如果存储同样多的数据,双向链表要比单链表占用更多的内存空间。
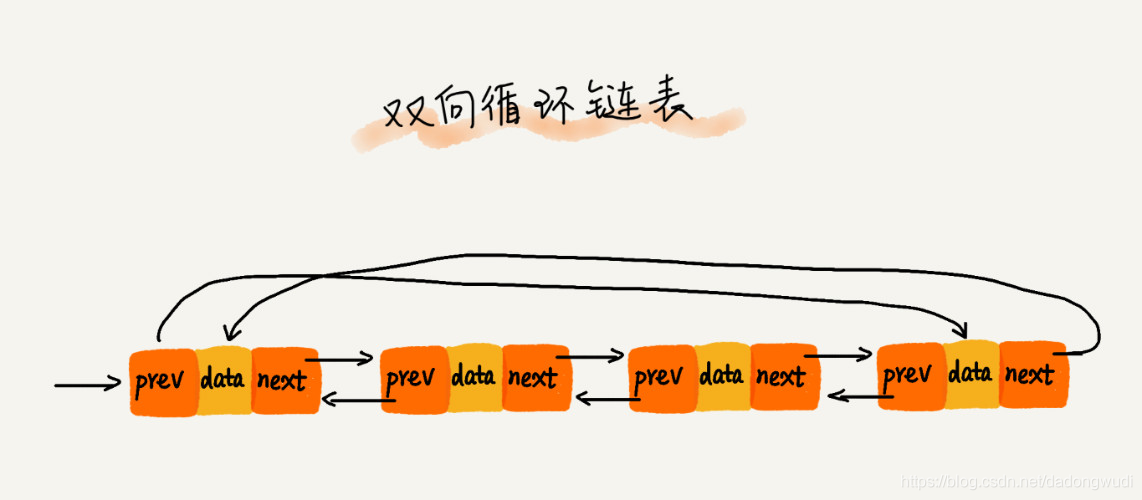
双向循环链表
首节点的前驱指针指向尾节点,尾节点的后继指针指向首节点。
应用
1. 如何分别用链表和数组实现LRU缓冲淘汰策略?
1)什么是缓存?
缓存是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非广泛的应用,比如常见的CPU缓存、数据库缓存、浏览器缓存等等。
2)为什么使用缓存?即缓存的特点
缓存的大小是有限的,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?就需要用到缓存淘汰策略。
3)什么是缓存淘汰策略?
指的是当缓存被用满时清理数据的优先顺序。
4)有哪些缓存淘汰策略?
常见的3种包括先进先出策略FIFO(First In,First Out)、最少使用策略LFU(Least Frenquently Used)、最近最少使用策略LRU(Least Recently Used)。
5)链表实现LRU缓存淘汰策略
当访问的数据没有存储在缓存的链表中时,直接将数据插入链表表头,时间复杂度为O(1);
如果缓存被占满,则从链表尾部的数据开始清理,将新的数据结点插入链表的头部,时间复杂度为O(1)。
当访问的数据存在于存储的链表中时,将该数据对应的节点删除,插入到链表表头,时间复杂度为O(n)。
6)数组实现LRU缓存淘汰策略
首位置保存最新访问数据,末尾位置优先清理
当访问的数据未存在于缓存的数组中时,直接将数据插入数组第一个元素位置,此时数组所有元素需要向后移动1个位置,时间复杂度为O(n);
当访问的数据存在于缓存的数组中时,查找到数据并将其插入数组的第一个位置,此时亦需移动数组元素,时间复杂度为O(n)。
缓存用满时,则清理掉末尾的数据,时间复杂度为O(1)。
(优化:清理的时候可以考虑一次性清理一定数量,从而降低清理次数,提高性能。)
2.如何通过单链表实现“判断某个字符串是否为水仙花字符串”?(比如 上海自来水来自海上)
1)前提:字符串以单个字符的形式存储在单链表中。
2)遍历链表,判断字符个数是否为奇数,若为偶数,则不是。
3)将链表中的字符倒序存储一份在另一个链表中。
4)同步遍历2个链表,比较对应的字符是否相等,若相等,则是水仙花字串,否则,不是。
写链表代码技巧
技巧一:理解指针或引用的含义
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。
技巧二:警惕指针丢失和内存泄漏
插入结点时,一定要注意操作的顺序
删除链表结点时,也一定要记得手动释放内存空间
技巧三:利用哨兵简化实现难度
哨兵最大的作用就是简化边界条件的处理
针对链表的插入、删除操作,需要对插入第一个结点和删除最后一个结点的情况进行特殊处理。
如果我们引入哨兵结点,在任何时候,不管链表是不是空,head 指针都会一直指向这个哨兵结点。我们也把这种有哨兵结点的链表叫带头链表。相反,没有哨兵结点的链表就叫作不带头链表。

技巧四:重点留意边界条件处理
- 如果链表为空时,代码是否能正常工作?
- 如果链表只包含一个结点时,代码是否能正常工作?
- 如果链表只包含两个结点时,代码是否能正常工作?
- 代码逻辑在处理头结点和尾结点的时候,是否能正常工作?
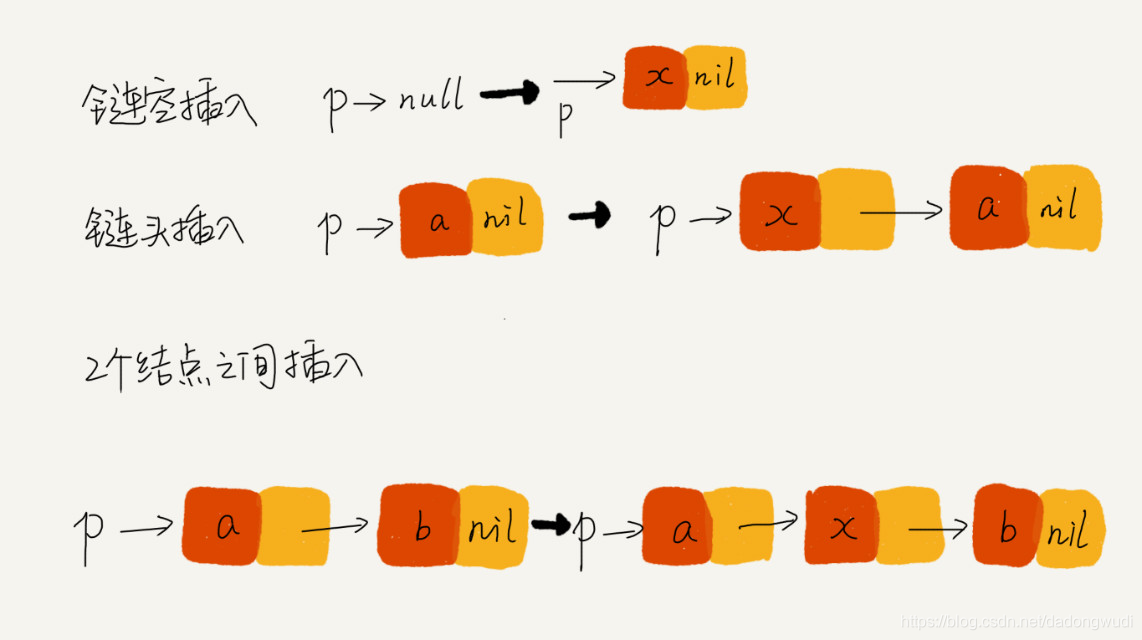
技巧五:举例画图,辅助思考
举例法和画图法
技巧六:多写多练,没有捷径
熟练 写链表代码是最考验逻辑思维能力的
- 单链表反转
- 链表中环的检测
- 两个有序的链表合并
- 删除链表倒数第 n 个结点
- 求链表的中间结点
练习题LeetCode对应编号:206,141,21,19,876
设计思想
对于执行较慢的程序,可以通过消耗更多的内存(空间换时间)来进行优化;而消耗过多内存的程序,可以通过消耗更多的时间(时间换空间)来降低内存的消耗。
笔记整理来源: 王争 数据结构与算法之美














![[Leetcode][第337题][JAVA][打家劫舍3][递归][动态规划]](http://pic.xiahunao.cn/[Leetcode][第337题][JAVA][打家劫舍3][递归][动态规划])

![什么是压缩感知?[简单概括]](http://pic.xiahunao.cn/什么是压缩感知?[简单概括])


