
一、Glove模型简介
语义文本向量表示可以应用在信息抽取,文档分类,问答系统,NER(Named Entity Recognition)和语义解析等领域中,大都需要计算单词或者文本之间的距离或者相似度,因此,能够表达语义的文本的向量表示非常重要。
单词的语义向量生成主要有两种方式:(1)LSA(term-document)、HAL(term-term)等矩阵分解方法利用全局统计信息生成词向量;(2)skip-gram、CBOW等词向量利用语言模型的局部信息生成词向量,在词类比( king -queen = man-woman)方面具有独特优势。
作者的想法是将以上两种方式的优点结合,提出了全局对数双线性回归模型。该模型采用LSA类似想法利用单词与单词的共现矩阵获取全局统计信息,但只使用非零数据;另一方面采用和skip和cbow一样的词向量方式进行训练。
二、相关工作
1、矩阵分解方法(全局信息)
LSA(term-document)、HAL(term-term)。
HAL方法的主要缺点是最常出现的单词在相似性度量中占据了不合理的分量,比如与the、and协同出现的单词,其相似性通常会比较高。论文中提到的解决方法有 positive pointwise mu-tual information (PPMI)和 Hellinger PCA (HPCA) 。
2、词向量方法(局部信息)
Mikolov在2013年提出的skip-gram、CBOW方法采用语言模型,依据一个局部窗口中的单词都是相关的这个思想来训练词向量,在词类比任务上具有非常优秀的表现。这种方法没有使用全局统计信息,比如单词A和单词B经常在一起出现,那么就应该给予更大的权重,而该模型则是对所有的训练语料都给予相同的权重。
三、Glove建模过程
1、公式的推理过程。
定义好相关符号:
对于冰(ice)与水蒸汽(steam),作者希望训练得到的词向量具有如下特性:
(1)与冰具有相似属性单词,如固体(solid),要求
(2)与水蒸气具有相似属性单词,如固体(solid),要求
(3)与冰、水蒸气不相关单词,如时尚(fashion),要求
给定单词
现在需要解决的问题是函数
首先要考虑单词
其次等式右边是个标量,那么式子左边也应该是个标量,现在输入为向量
然后作者又往公式的外面套了一层指数运算exp,最终得到
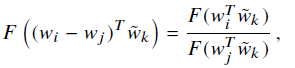
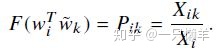
本来我们需要求
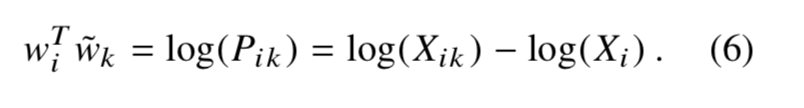
在这里我们发现等式左边是可以交换位置的,可是右边的
添了一个偏差项b,并将log(Xi)吸收到偏差项bi中。到这里我们就可以写出损失函数,
作者进行了进一步的优化,考虑到语料库中经常协同出现的单词具有更为密切的联系,作者提出来加权损失函数。
权重函数要满足如下特性:
(1) 考虑连续性,
(2)
(3) 当
作者选择的满足以上要求的函数,如下:
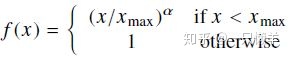
2、与skip以及cbow的关系
我们知道这两个模型的损失函数如下,
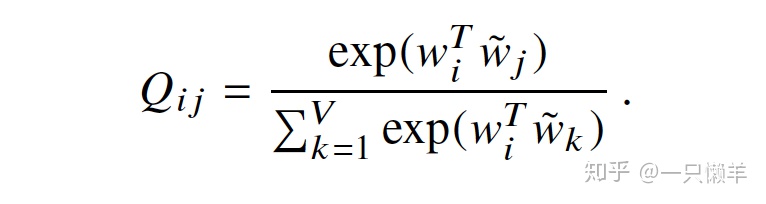
全局的目标函数可以写成:
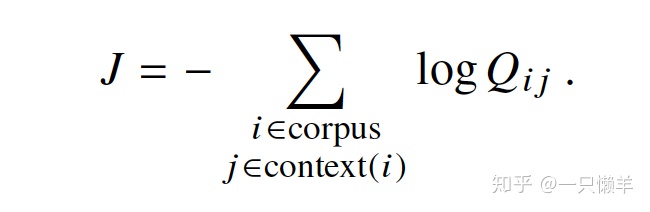
对于大量的预料计算求和非常消耗资源,为了提高计算效率,可以把提前把那些有相同值的词分组,目标函数改写为按照词典来统计。
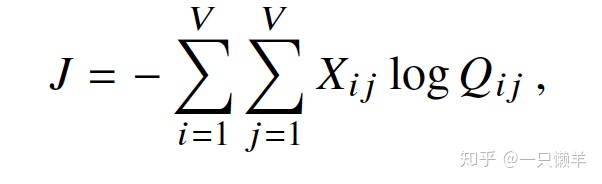
由于之前定义
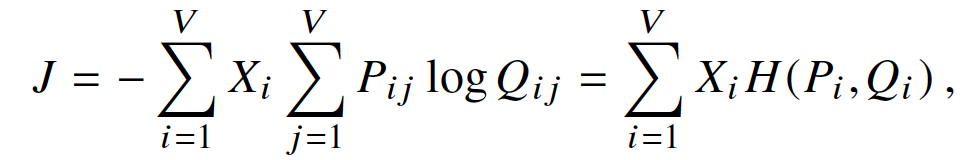
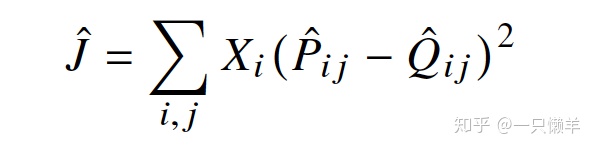
其中
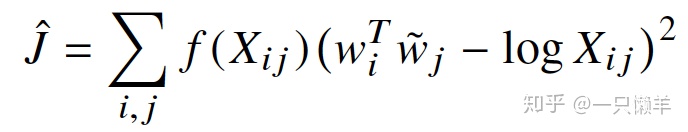
这里的公式与我们最开始推导出来的公式非常相似。从这里可以看出,skip-gram模型与这篇论文提出模型差异,本质上是度量概率分布采用的方法不一致。前者使用的是交叉熵损失,后者使用的是加权平方误差损失。
3、复杂度估算
模型的复杂度 为
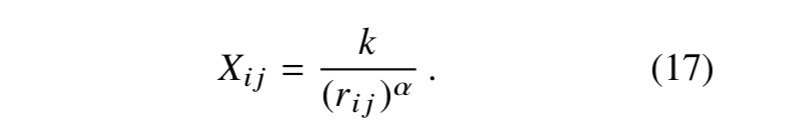
语料库词的总数正比于次数共现次数矩阵元素的加和,
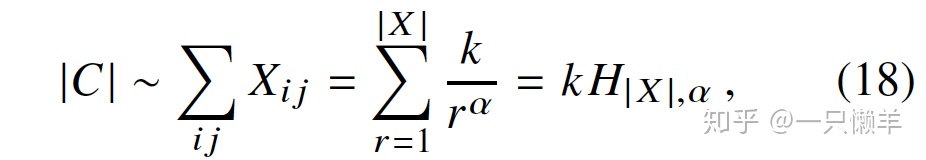
用调和级数来表示幂律求和部分,接下来就是如何确定k了,
因此,总是能够找到一个k使得
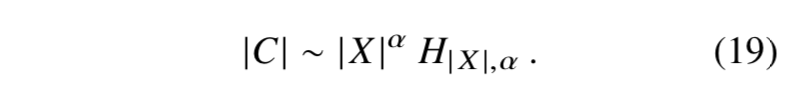
根据调和基数展开式
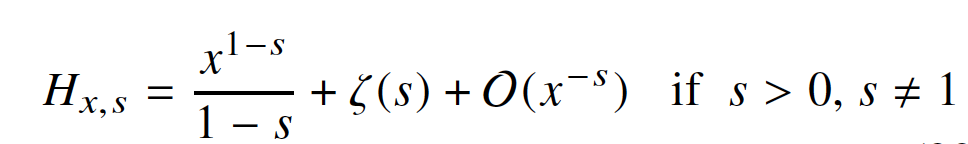
把方程(19)展开得到
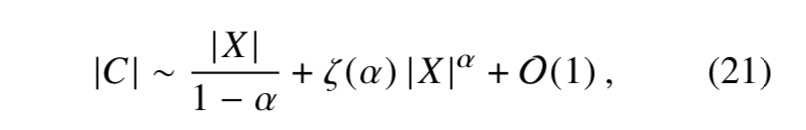
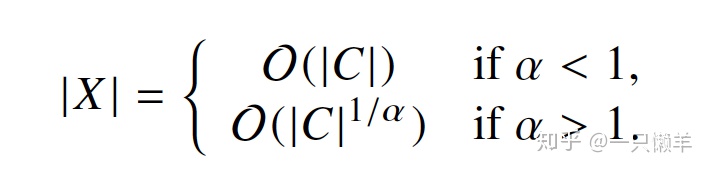
因此,Glove模型的复杂度小于等于skip-gram模型的复杂度。如果
四、实验结果
4.1 word analogy任务
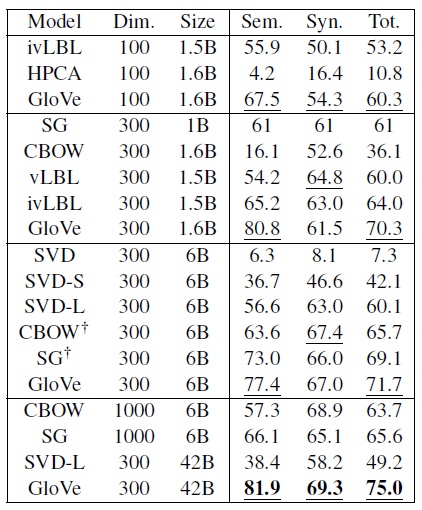
在词语类比任务中,我们看到Glove算法在大多数情况下取得了更好的指标。在semantic subset/语义子集、syntactic subset/句法子集上均表现更佳,具体如下(此任务可以测试向量空间的子结构):
4.2 word similarity任务
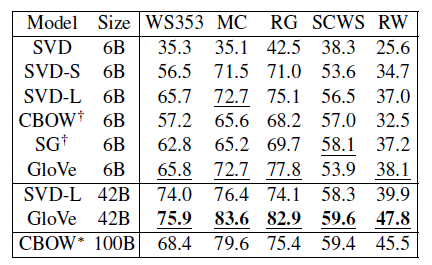
本文用多个模型在一系列word similarity任务上进行测试,结论是:Glove优于其他模型。详细数据如下:
4.3 NER任务
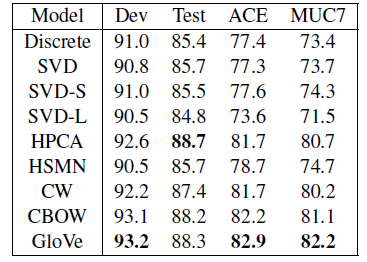
在此任务中基于CoNLL-03数据集训练模型,并在多个数据集(CoNLL-03、ACE、MUC7)上进行测试,结果显示Glove表现最佳。
五、参考文献
1、官方代码:https://nlp.stanford.edu/projects/glove/。
2、paper原文:https://www.aclweb.org/anthology/D14-1162.pdf。
3、好文参考:理解GloVe模型(Global vectors for word representation)




方法的使用)





![[模板]LIS(最长上升子序列)](http://pic.xiahunao.cn/[模板]LIS(最长上升子序列))








