第一题:
输出月份英文名设计思路:
1:看题目:主函数与函数声明,知道它要你干什么2:理解与分析:在main中,给你一个月份数字n,要求你通过调用函数char *getmonth,来判断:若它小于等于12,则将它转化为英文单词输出,若它大于等于12,则输出wrong input!3:解答:第一步:定义一个二维数组*a[12][15],并赋值给它1-12月的英文单词第二步:定义i,i作为a[]的下标第三步:利用一个for循环,判断i是否等于n,若相等,返回a[i-1];若出了for循环,则返回 NULL流程图:
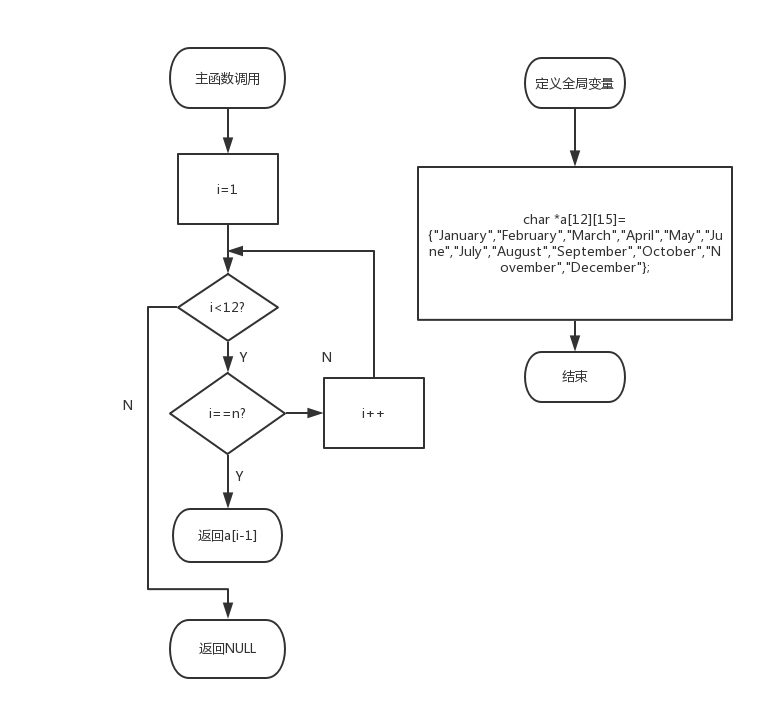
实验代码:
char *a[12][15]={"January","February","March","April","May","June","July","August","September","October","November","December"};
char *getmonth( int n )
{int i;for(i=1;i<=12;i++){if(i==n){return a[i-1];}}return NULL;}错误信息:
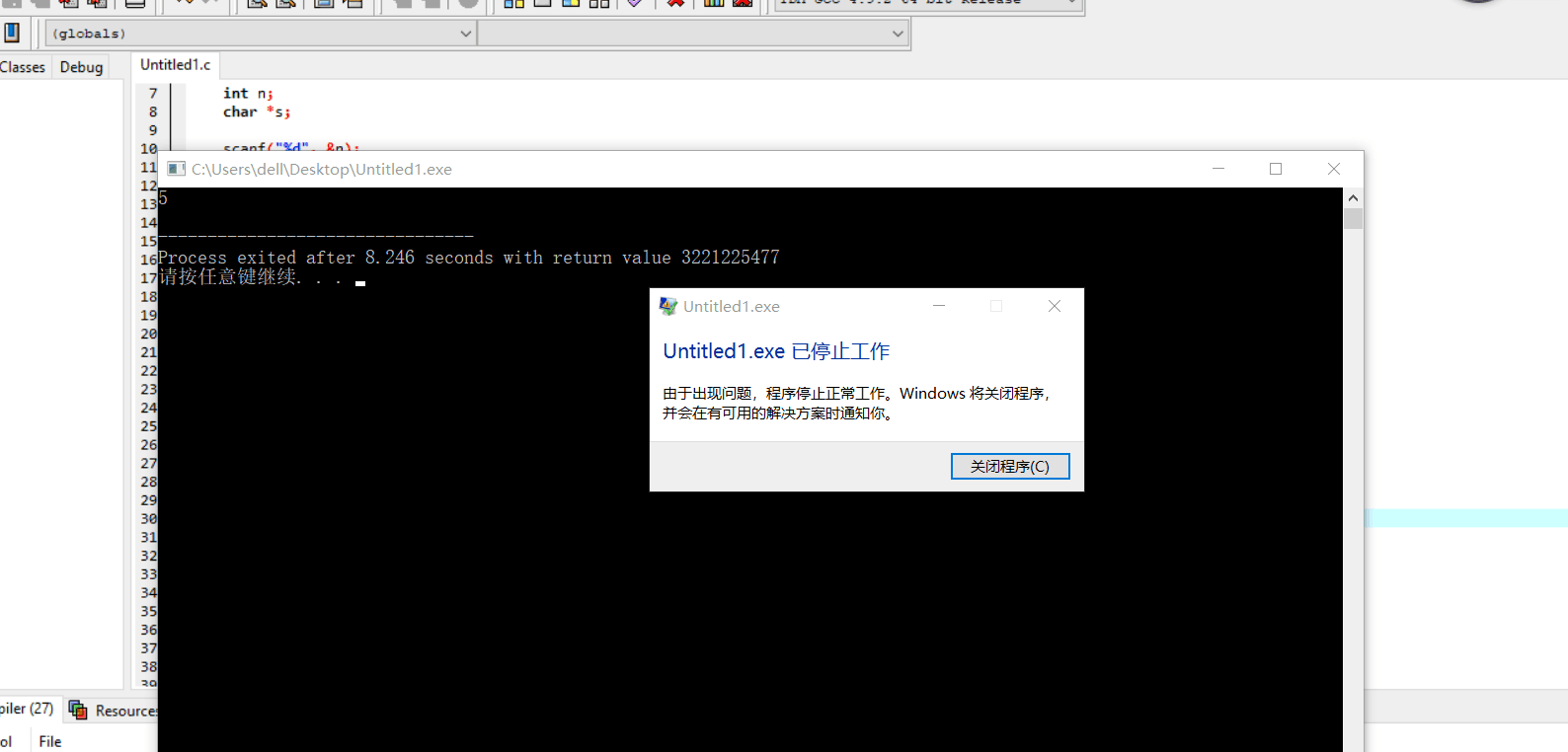
错误1: a[12][15]中的号一直没打,找了好久,害我在其它地方一直改,没改对
解决方案1:加*号
第二题:
查找星期设计思路:
1:看题目:主函数与函数声明,知道它要你干什么2:理解与分析:在main中,给你星期1-7的英文单词及它们对应的序号,再给你一个字符串,通过调用函数getindex,要你判断它是否为星期1-7的英文单词,若是则输出它的序号,否则输出wrong input!3:解答:第一步:定义一个二维数组*a[][],并赋值给它星期7-1的英文单词第二步:定义i,i作为a[]的下标第三步:利用一个for循环,判断strcmp(s,a[i])是否等于0,若成立,返回序号i;若不成立,跳出for循环后,返回-1流程图:
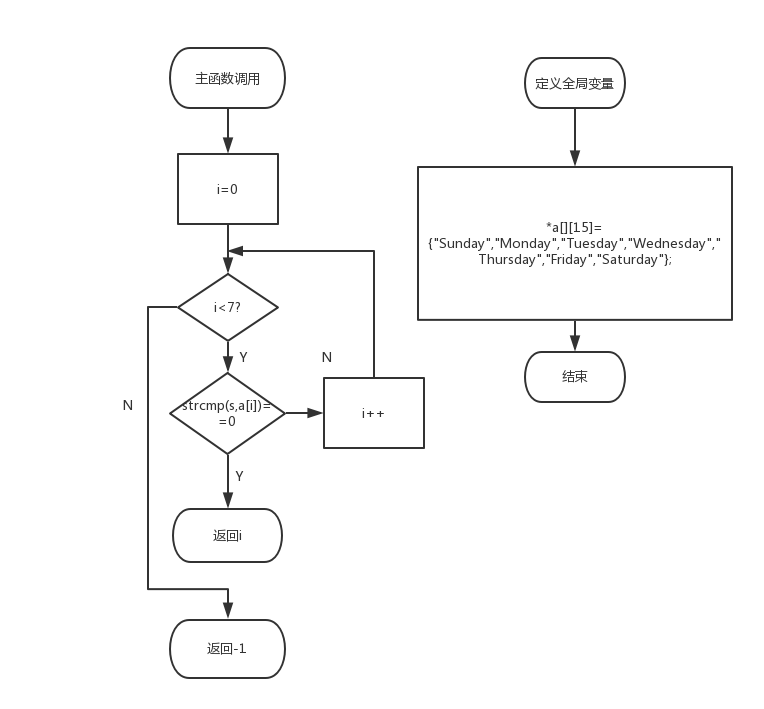
实验代码:
char *a[][15]={"Sunday","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday"};
int getindex( char *s )int i;for(i=0;i<7;i++){if(strcmp(s,a[i])==0)return i;}return -1;
}错误信息:
这题没错误,因为第一题的错误避免了,还有我知道strcmp(s,a[i])==0
第三题:
计算最长的字符串长度设计思路:
1:看题目:主函数与函数声明,知道它要你干什么2:理解与分析:在main中,题目给你n个字符串,要求你通过调用函数 max_len,计算n个元素的指针数组s中最长的字符串的长度3:解答:第一步:定义i,max=0,t=0;其中i为s[]的下标,max记录s中最长的字符串的长度,t为记录s中字符串的长度第二步:将strlen(s[0])赋值给max第三步:利用for循环,从i=1开始,令 t=strlen(s[i]);再判断max是否小于t,若小于,将t赋值给max,跳出for循环后,返回max流程图:

实验代码:
int max_len( char *s[], int n )
{int i,max=0,t=0;max=strlen(s[0]);for(i=1;i<n;i++){t=strlen(s[i]);if(max<t)max=t;}return max;
}错误信息:
无
第四题:
指定位置输出字符串设计思路:
1:看题目:主函数与函数声明,知道它要你干什么2:理解与分析:要你用函数match应打印s中从ch1到ch2之间的所有字符,并且返回ch1的地址3:解答:在match中,定义i=0,j=0,len=0;i,j作为s[]的下标,len用于记录s[]长度。还定义 *p=NULL,*p用于记录ch1的地址第一步:计算s[]的长度——len = strlen(s)第二步:用for循环遍历s[],先找 s[i]==ch1,若找到,则p=&s[i],再用for循环找ch2,若找到,则输出 ch1到 ch2之间的字符,并返回p;若没找到,输出ch1后面的所有字符,并返回p;若没找到ch1,则p=&s[len],并返回p; 实验代码:
char *match( char *s, char ch1, char ch2 ){ int i=0,j=0,len=0; char *p=NULL; len = strlen(s); for(i=0;i<len;i++){ if(s[i]==ch1){ p=&s[i]; for(j=i;j<len;j++){ if(s[j]!=ch2){ printf("%c", s[j]); } if(s[j]==ch2){ printf("%c\n", s[j]); return p; } } printf("\n"); return p; } } p=&s[len];printf("\n"); return p;
} 错误信息:
原因:一开始我题目理解错了: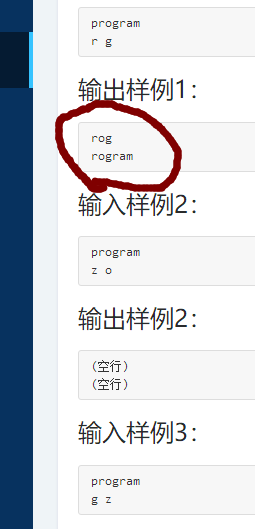
我以为在主函数中输出也是rog,然后我就一直在这个地方错误,后来我仔细看题才知道返回的是ch1的地址
第五题:
用筛选法求质数;题目:

设计思路:
1:看题目:主函数与函数声明,知道它要你干什么2:先定义一个宏——MAX_N=10000000,然后定义一个全局变量的数组prime[MAX_N],再定义一个全局变量bool型的数组is_prime[MAX_N+1];3:在主函数中,先定义b,c,d,i;其中b为你的学号,c为你学号的前三位,d为你学号的后四位,i为prime[]的下标第一步:输入你的学号b,然后求出你学号的前三位和学号的后四位——c=b/10000000,d=b%10000;第二步:调用函数sieve——sieve(c*d);第三步:输出4:在sieve中,用n接收c*d,定义p=0,i,j;p作为质数的下标,i作为数组的下标、还为1—n之间的某个数,j为i的倍数第一步:用一个for循环,令所以的is_prime[i]的值都为true,出for循环后,令is_prime[0]=is_prime[1]=false;第二步:用两个for循环,外层for循环为for( i=2;i<=n;i++),进入外层for循环后,判断is_prime[i]==true是否成立,若成立,代表i为质数,令prime[p]=i,然后p++,再用一个for循环令所以i的倍数的值全为is_prime[j]=false,实现为内层for循环for(int j=2*i;j<n;j=j+i)is_prime[j]=false;实验代码:基地学长教我的
#include <stdio.h>
#include <math.h>
int MAX_N=10000000;
int prime[MAX_N];
bool is_prime[MAX_N+1];
int sieve(int n){int p=0,i,j;for( i=0;i<=n;i++)is_prime[i]=true;is_prime[0]=is_prime[1]=false;for( i=2;i<=n;i++){if(is_prime[i]==true){prime[p]=i;p++;for(int j=2*i;j<n;j=j+i)is_prime[j]=false;}}
}
int main()
{int b,c,d,i;scanf("%d",&b);c=b/10000000;d=b%10000;int sieve(c*d); for(i=0;i<=MAX_N;i++){if((i+1)%5==0){printf("%d\n",prime[i]);}else{printf("%d ",prime[i]);}}}
}第六题:
学生成绩链表处理设计思路:
1:看题目:主函数与函数声明,知道它要你干什么2:理解与分析:在main中,要求你利用两个函数,一个将输入的学生成绩组织成单向链表;另一个将成绩低于某分数线的学生结点从链表中删除。其中函数createlist利用scanf从输入中获取学生的信息,将其组织成单向链表,并返回链表头指针;而函数deletelist从以head为头指针的链表中删除成绩低于min_score的学生,并返回结果链表的头指针;3:解答:在createlist中,定义三个struct stud_node的指针*p, *ptr, *head=NULL;其中*p用于申请动态空间,*head用于建立链表的表头,*ptr用于建立链表的其它部分第一步:定义num,name[20],score;它们的值用于赋值给struct stud_node结构中的num,name[20],score;第二步:读入一个num,并判断它是否等于0,若不等于,则进入while循环;若等于0,返回head;第三步:进入whlie后,读入name[20],score;再申请一个struct stud_node结构的动态空间p,将num,name[20],score的值赋值或复制给p中的num,name[20],score;第四步:判断head是否为NULL;是则让head=p,建立链表的表头;若不是,则令ptr->next = p;出if语句后,再将ptr=p;第五步:重复操作第二步到第四步,直到num=0,返回head;在deletelist中,定义二个struct stud_node的指针ptr1, ptr2;在第一个while中,ptr2用于查找从head开始第一个不满足head->score < min_score的数;在第二个while中(此时的head肯定不满足head->score < min_score):ptr1用于指向head,ptr2用于指向head的next;第一步:判断head != NULL && head->score < min_score,若成立,则令ptr2=head,再令head = head->next,再free(ptr2);若不成立了,一定是以下两种情况之一:1:学生的分数全部低于min_score,链表全部都释放了,此时head=NULL;2:找到了第一个学生的分数大于min_score的人,并让head指向了他;第二步:出第一个while后,判断head == NULL;若是,则为我说的第一个情况——学生的分数全部低于min_score,链表全部都释放了,此时head=NULL,应该返回NULL;若不是,则为第二种情况——找到了第一个学生的分数大于min_score的人,并让head指向了他,我们还要找是否他后面还有不满足head->score < min_score的数;第三步:令ptr1 = head;ptr2 = head->next;判断ptr2 != NULL,若不为空,进入第二个while中,判断ptr2->score < min_score,若满足,则说明我们要将ptr1的next释放,在释放前,应该先链接——ptr1->next = ptr2->next,再释放——free(ptr2);若不满足ptr2->score < min_score,则说明ptr2不用被释放,我们应该让ptr1指向ptr2——ptr1 = ptr2,再让ptr2指向ptr1的next——ptr2 = ptr1->next;一直重复下去,直到跳出while第四步:返回head;流程图:
无实验代码:
#include<string.h>
struct stud_node *createlist()
{struct stud_node *p, *ptr, *head=NULL;int num;char name[20];int score;scanf("%d",&num);while (num != 0){scanf("%s %d",name,&score);p = (struct stud_node *)malloc(sizeof(struct stud_node));p->num = num;strcpy(p->name, name);p->score = score;p->next = NULL;if (head == NULL){head = p;}else{ptr->next = p;}ptr = p;scanf("%d",&num);}return head;
}
struct stud_node *deletelist( struct stud_node *head, int min_score )
{struct stud_node *ptr1, *ptr2;while (head != NULL && head->score < min_score){ptr2 = head;head = head->next;free(ptr2);}if (head == NULL)return NULL;ptr1 = head;ptr2 = head->next;while (ptr2 != NULL){if (ptr2->score < min_score) {ptr1->next = ptr2->next;free(ptr2);}elseptr1 = ptr2;ptr2 = ptr1->next;}return head;
}错误信息:
一开始再老师没讲之前,错误太多了,不是我们没做,而是天天在做,天天在错,删除链表好多情况没有考虑到,例如:第一个低于min_score;当全部是低于min_score;还有最后一个低于min_score;老师讲了之后好一点了,还是有上面的一些问题,最后经过仔细琢磨终于想出想出来了
小结:这题做的太辛苦了,不过嘛,也受到了好多东西,下次在遇到相似的题也不会这么费劲了
第七题:
奇数值结点链表设计思路:
1:看题目:主函数与函数声明,知道它要你干什么2:理解与分析:在main中,要求你用两个函数,分别将读入的数据存储为单链表、将链表中奇数值的结点重新组成一个新的链表。其中函数readlist从标准输入读入一系列正整数,按照读入顺序建立单链表。当读到−1时表示输入结束,函数应返回指向单链表头结点的指针。而函数getodd将单链表L中奇数值的结点分离出来,重新组成一个新的链表。返回指向新链表头结点的指针,同时将L中存储的地址改为删除了奇数值结点后的链表的头结点地址(所以要传入L的指针)。3:解答:在readlist中,定义三个struct ListNode的指针*p, *tail, *head=NULL;其中*p用于申请动态空间,*head用于建立链表的表头,*tail用于建立链表的其它部分第一步:定义data;data的值用于赋值给struct ListNode结构中的data;第二步:读入一个data,并判断它是否等于-1,若不等于,则进入while循环;若等于-1,返回head第三步:进入whlie后,申请一个struct ListNode结构的动态空间p,将data的值赋给p中的data;p->next=NULL;第四步:判断head是否为NULL;是则让head=p,建立链表的表头;若不是,则令tail->next = p;出if语句后,再将tail=p;第五步:重复操作第二步到第四步,直到data=-1,返回head;在getodd中,定义七个struct stud_node的指针*p=*L,*a,*b,*head1,*head2,*p1,*p2;其中head1,head2用于申请动态空间,p用于接收*L,p1用于建立奇数链表的表头,a用于建立奇数链表的其它部分,p2用于建立偶数链表的表头,b用于建立偶数链表的其它部分第一步:申请两个struct ListNode结构的动态空间head1,head2;令a指向head1,b指向head2;第二步:判断p!=NULL?,若成立,则p->data%2!=0?,若是,则建立奇数链表,否则建立偶数链表,若不成立,令*L指向偶数链表的表头p2,返回奇数链表的表头p1;流程图:
无实验代码:
struct ListNode *readlist()
{struct ListNode *head=NULL,*p=NULL,*tail=NULL;int data;scanf("%d",&data);while(data!=-1){p=(struct ListNode *)malloc(sizeof(struct ListNode));p->data=data;p->next=NULL;if(head==NULL){head=p;}else{tail->next=p;}tail=p;scanf("%d",&data);}return head;
}
struct ListNode *getodd( struct ListNode **L )
{ struct ListNode *p=*L,*a,*b,*head1,*head2,*p1=NULL,*p2=NULL;head1=(struct ListNode*)malloc(sizeof(struct ListNode));head2=(struct ListNode*)malloc(sizeof(struct ListNode));head1->next=NULL;head2->next=NULL;a=head1;b=head2;for(;p!=NULL;p=p->next){if(p->data%2!=0){if(p1==NULL)p1=p;elsea->next=p;a=p;}else{if(p2==NULL)p2=p;elseb->next=p;b=p;}}a->next=NULL;b->next=NULL;*L=p2;return p1;
} 错误信息:
原因:我先是在原来链表的基础上修改,然后建一个奇数链表;然而我处理不好,一直错误,后来我建了两个链表,一个奇数,一个偶数,最后让*L=偶数表头,返回奇数表头
第八题:
链表拼接设计思路:
1:看题目:主函数与函数声明,知道它要你干什么2:理解与分析:在main中,要求你实现一个合并两个有序链表的简单函数3:解答:在mergelists中,定义struct ListNode的 *p,*ptr1=list1,*ptr2=list2,*tail=NULL,*head=NULL;其中*p用于申请动态空间,*head用于建立链表的表头,*ptr用于建立链表的其它部分,ptr1指向list1,ptr2指向list2;第一步:定义整形a[1000],i=0,n=0,j=0,t;其中a[]用于储存list1和list2中的所有数,i,j用于冒泡排序法,n用于记录a[]有多少数,t用于冒泡排序法中交换的中间量;第二步:用两个for循环,将list1和list2中的所有数储存到a[]中,再用n=i,记录a[]有多少数;第三步:用两个for循环,用冒泡排序法将a[]升序排列;第四步:建立一个新的链表,将a[]的数全部赋值到链表中,最后返回链表的头部;实验代码:
struct ListNode *mergelists(struct ListNode *list1, struct ListNode *list2)
{struct ListNode *p,*ptr1=list1,*ptr2=list2,*tail=NULL,*head=NULL;int a[1000],i=0,n=0,j=0,t;for(i=0;ptr1!=NULL;ptr1=ptr1->next,i++){a[i]=ptr1->data;}for(;ptr2!=NULL;ptr2=ptr2->next,i++){a[i]=ptr2->data;}n=i;for(i=0;i<n;i++){for(j=i+1;j<n;j++){if(a[i]>a[j]){t=a[i];a[i]=a[j];a[j]=t;}}}for(i=0;i<n;i++){p=(struct ListNode *)malloc(sizeof(struct ListNode));p->data=a[i];p->next=NULL;if(head==NULL){head=p;}else{tail->next=p;}tail=p;}return head;
}错误信息:
原因:
有一些NULL没大写;写成了NUll,一直编译错误总结:
最近两周的学习,我们学了二级指针,我们利用它输出月份英文名,查找星期,计算最长的字符串长度,指定位置输出字符串;我们还学了链表,刚开始,感觉建链表比较简单,而删除链表比较困难,因为有些特殊情况不好处理,后来经过不断的学习,对删除链表也掌握了,这周,我们利用链表奇数值结点链表,学生成绩链表处理,链表拼接;这周我有一些特别的感觉,以前做PTA基本一下就作好了,而这周嘛,为了这几题一直在想,一直在做,也许是我掌握的不够好,不过现在对我来说这种题型都会做了,也可以理解所有代码,不会像以前那样费劲了,因为学了一周了,想的也多了,有时走路也在想,感觉这周收获比较多。我们还学了如何申请动态空间,这样可以节省更多的空间,上面做的题有体现。我的进度:
我点评的人:
李伍壹
辛静瑶
姜健
王文博
点评我的人:
左右羽马钰娟王文博姜健李伍壹:初识Python)















简析)


