如何识别媒体偏见
TGumGum can do to bring change by utilizing our Natural Language Processing technology to shed light on potential bias that websites may have in their content. The ideas and techniques shared in this blog are a result of the GumGum Hackathon Project: Verity E-Quality (Aditya Ramesh, Erica Nishimura, Ishan Shrivastava, Lane Schechter and Trung Do).
T GumGum可以利用我们的自然语言处理技术来带来变化,从而揭示网站内容可能存在的潜在偏见。 本博客中分享的想法和技术是GumGum Hackathon项目:Verity E-Quality(Aditya Ramesh,Erica Nishimura,Ishan Shrivastava,Lane Schechter和Trung Do)的结果。
In this blog, we will look into how we can utilize and build upon the existing product offering from GumGum to understand the Gender Representation in a website’s content. We aren’t saying that one publisher is more biased than the other, rather we are merely providing the awareness around the representation as it exists. With Natural Language Processing, we can compare between the descriptive language being used around Males and Females to provide this awareness.
在此博客中,我们将研究如何利用和建立GumGum提供的现有产品,以了解网站内容中的性别表示形式。 我们并不是说一个出版商比另一个出版商有更大的偏见,相反,我们只是在提供有关表示形式的意识。 通过自然语言处理,我们可以在男性和女性周围使用的描述性语言之间进行比较,以提供这种意识。
In order to facilitate meaningful change, we need to be aware and mindful of where that change is needed. — Lane Schechter, Product Manager, GumGum Inc.
为了促进有意义的变更,我们需要意识到并铭记需要进行哪些变更。 —口香糖公司产品经理Lane Schechter
口香糖的产品 (GumGum’s Product Offerings)
Before we move ahead to understand how we build upon the existing product offerings, let us first take a brief look at them. GumGum’s Verity Product does a complete contextual analysis of a publisher’s webpage. Some of the key offerings of this product are:
在继续了解如何在现有产品基础上发展之前,让我们首先简要地了解一下它们。 GumGum的Verity产品对发布者的网页进行了完整的上下文分析。 该产品的一些主要产品包括:
Contextual Classification & Targeting: This feature identifies and scores publisher’s content (webpages) for contextual classification based on standard IAB Content Taxonomy v1.0 and v2.0. Some of those categories are “Sports”, “Food & Drinks”, “Automotive”, “Medical Health” etc. Going forward, we will refer to them as IAB verticals.
内容相关分类和定位 :此功能可根据标准IAB内容分类标准v1.0和v2.0对发布者的内容(网页)进行识别和评分,以进行内容相关分类。 其中一些类别是“体育”,“食品和饮料”,“汽车”,“医疗保健”等。展望未来,我们将其称为IAB行业。
Brand Safety & Suitability: This feature flags and rates brand safety threats based on GumGum’s proprietary threat classification taxonomy and in compliance with The 4A’s Advertising Assurance Brand Safety Framework.
品牌安全性和适用性 :此功能基于GumGum专有的威胁分类法并符合4A的广告保证品牌安全框架来标记和评估品牌安全威胁。
Named Entity Recognition (NER): This feature identifies and extracts any mention of a named entity in the publisher’s content. A named entity could be any mention of a ‘Person’, ‘Location’ or ‘Organization’.
命名实体识别(NER) :此功能可以识别并提取发布者内容中对命名实体的任何提及。 命名实体可以是对“人员”,“位置”或“组织”的任何提及。
Sentiment Analysis: This feature analyzes the attitudes, opinions and emotions expressed online to provide the most nuanced brand safety and contextual insights.
情感分析 :此功能可分析在线表达的态度,观点和情感,以提供最细微的品牌安全性和上下文相关见解。
Here is one way we can provide the Descriptive Language Understanding Associated with Gender. We can use the Named Entity Recognition (NER) feature to extract Names of “Person” named entity type which can be used to identify the gender of the person being talked about. We can also use the Sentiment Analysis feature to extract sentiment of the sentences in which Males and Females are being talked about. We can use all of this information to understand the descriptive language being used around Males and Females (more on how to do this in the next section) and compare it across different IAB verticals extracted using our Contextual Classification feature.
这是我们提供与性别相关的描述性语言理解的一种方法。 我们可以使用命名实体识别( NER )功能来提取“个人”命名实体类型的名称,该名称可用于识别所谈论人员的性别。 我们还可以使用情感分析功能来提取正在谈论男性和女性的句子的情感。 我们可以使用所有这些信息来理解男性和女性周围使用的描述性语言(在下一节中将详细介绍如何操作),并使用上下文分类功能将其与不同的IAB垂直行业进行比较。
与性别相关的描述性语言理解方法 (Approach for Descriptive Language Understanding Associated with Gender)
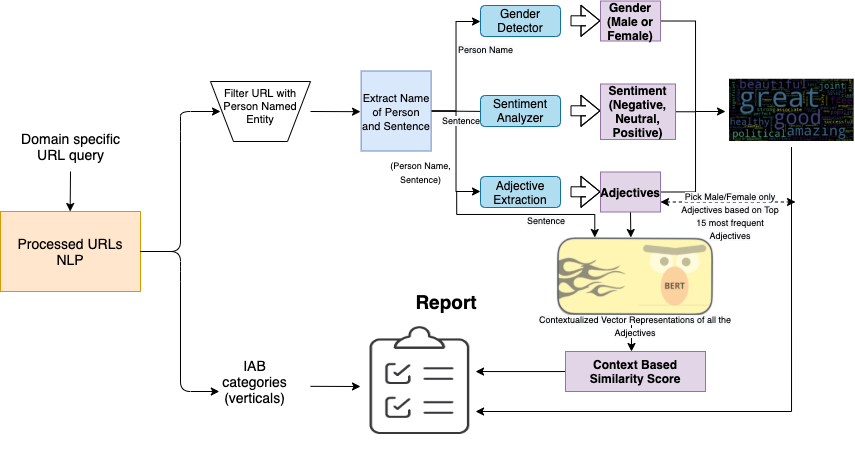
We start by running a Domain Specific Query on our NLP Databases to extract URL’s for the given publisher. We then utilize the Named Entity Recognition Feature of Verity to filter out pages that do not contain any “Person” Named Entity. From the remaining pages, we extract all “Person Names” and the Sentences in which those “Person Names” occur. As a future step, we can also perform coreference resolution, to extract more sentences where the “Persons” are mentioned using their respective pronouns.
我们首先在NLP数据库上运行特定于域的查询,以提取给定发布者的URL。 然后,我们利用Verity的命名实体识别功能来过滤掉不包含任何“人”命名实体的页面。 从其余页面中,我们提取所有“人名”和出现这些“人名”的句子。 作为未来的步骤,我们还可以执行共指解析,以提取更多句子,并使用各自的代词提及“人物”。
We then use the “Person Names” to detect the gender of the person using an open source package called Gender Guesser. We also use the “Sentences” to extract the sentiment of the Sentence by utilizing our own FastText based Sentiment Classification model. This model is trained on our publisher data which classifies a sentence into Negative, Neutral or Positive Sentiment.
然后,我们使用称为“性别名称”的开源软件包Gender Guesser来检测人员的性别 。 我们还使用“句子”通过利用我们自己的基于FastText的情感分类模型来提取句子的情感。 此模型是根据我们的发布者数据训练的,该数据将句子分为负面,中性或正面情绪。
We also use “Person Names” and the Sentences they occur in to extract Adjectives used in the surrounding context for a given person. To achieve this we used Spacy’s Part of Speech Tokenizer and extract adjectives used within a proximity of a mention of a person name. Consider the example given below:
我们还使用“人物名称”及其出现的句子来提取给定人物在周围环境中使用的形容词。 为了达到这个目的,我们使用了Spacy的语音词性分词器,并提取了在提及某人名时使用的形容词。 考虑下面给出的示例:

We use all this information to create a Word Cloud for the Adjectives used around each Gender and Sentiment Pair across the entire content as well as specific to different IAB verticals.
我们使用所有这些信息为整个内容以及特定于不同IAB行业的每个性别和情感对使用的形容词创建词云 。
For example, consider the following four word clouds that we got based on the Adjectives used around Males and Females in a Positive and Negative context extracted from a Publisher’s content:
例如,考虑以下四个词云,这些词云是根据从发布者内容中提取的正面和负面上下文中男性和女性周围使用的形容词得出的:
Nothing stereotypical stands out here. It has similarly or equally negative adjectives being used around Males and Females alike.
没有什么定型观念在这里脱颖而出。 它在男性和女性周围都有相似或同等的否定形容词。
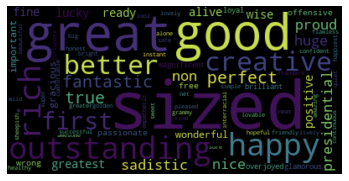

What we see here is that more Intellectual Type Adjectives being used around Males, while more Appearance Type Adjectives being used around Females.
我们在这里看到的是,在男性周围使用更多的智力类型形容词,而在女性周围使用更多的外观类型形容词。
It becomes even more clearer if we look at the most frequent Adjectives used around ONLY Males or Female. We do this be considering the top 15 adjectives and extracting only the Uncommon Adjectives between the two genders and compare it among the Positive and Negative Context.
如果我们只看男性或女性周围最常用的形容词,就会更加清楚。 我们这样做是在考虑前15名形容词,并仅提取两个性别之间的不常见形容词 ,然后将其在正面和负面语境中进行比较。

Here we can clearly see that in the Negative context, the most frequent Adjectives used around Only Males and Only Females can be considered equally negative. But in the Positive context, that is clearly not the case. Around Males, we see adjectives like “Proud”, “Sized”, “Perfect”, “Fantastic etc while we see adjectives like “Beautiful”, “Healthy”, “Amazing”, “Sweet”, “Supporting”, “Lucky” etc around Females. This is suggestive of more Intellectual Type Adjectives being used around Males and more Appearance Types adjectives being used around Females.
在这里我们可以清楚地看到,在否定语境中,仅男性和仅女性周围使用最频繁的形容词可被视为同等否定。 但是,在积极方面,情况显然并非如此。 在男性周围,我们看到形容词如“骄傲”,“大小”,“完美”,“棒极了”,而我们看到形容词如“美丽”,“健康”,“惊人”,“甜”,“支持”,“幸运”等女性。 这表明在男性周围使用更多的智力类型形容词,在女性周围使用更多的外观类型形容词。
This sort of analysis of the descriptive language being used around different Genders in different Sentimental Context can really help in understanding what sort of Bias if any is present in a publisher’s content. But how can we quantify this? For this we introduce a Context Based Similarity Score.
对在不同情感环境中不同性别之间使用的描述性语言进行的这种分析,确实可以帮助理解发行人内容中存在的哪种偏差(如有)。 但是我们如何量化呢? 为此,我们介绍了一个基于上下文的相似度评分 。
基于上下文的相似度评分 (Context Based Similarity Score)
The idea here is to find a way to compute a single score that shows the degree of similarity between the most frequent adjectives used around only Males and only Females. To achieve this we make use of the famous Transformer based Deep Learning model: BERT by Google Research.
这里的想法是找到一种方法来计算单个分数,该分数显示仅在男性和女性之间使用的最常见形容词之间的相似程度。 为此,我们利用了著名的基于Transformer的深度学习模型: Google Research的BERT 。
Among being awesome at a variety of NLP tasks and breaking the State of the Art results on them, BERT is also great at providing Contextualized Word Vector Representations (Embeddings). What that means is that, BERT doesn’t provide a single and constant representation of a word, rather it looks at the context in which the word was used in the sentence and spits out a context sensitive representation of that word. This is particularly useful as it captures more information than other representations such as Word2Vec or Glove. A famous example used to point this out is that BERT will provide different representations for the word “Bank” depending on the context in which it was used. The context could be of a river bank or of a financial bank. Therefore, to extract a word representation from BERT, you need to send a sentence in which it was used to get a Contextualized Word Vector Representations. (Apart from reading their original paper here, you can also look at this and this to get a more visualistic way of understanding Transformers and BERT. )
BERT擅长处理各种NLP任务并打破了最新的技术成果,其中,BERT擅长提供上下文化的词向量表示(嵌入) 。 这就是说,BERT不提供单词的单一且恒定的表示形式,而是查看句子中使用该单词的上下文,并吐出该单词的上下文相关表示形式。 这一点特别有用,因为它比诸如Word2Vec或Glove之类的其他表示形式捕获的信息更多。 指出这一点的一个著名示例是,BERT将根据使用的上下文为“银行”一词提供不同的表示形式。 上下文可以是河岸或金融银行。 因此,要从BERT中提取单词表示形式,您需要发送一个句子,在该句子中使用它来获取上下文化的单词向量表示形式。 (除了这里阅读他们的原始论文,你也可以看看这个和这个得到理解变压器和BERT更visualistic方式。)
Therefore, along with the most frequent Male only and Female Only adjectives, we also extract the sentences in which these Male only and Female Only Adjectives are used. We send these sentences into BERT to extract Contextualized Vector Representations of length 768, for each of these Adjectives based on the context in which these adjectives were used.
因此,与最常见的男性专用和女性专用形容词一起,我们还提取了使用这些男性专用和女性专用形容词的句子。 我们根据使用这些形容词的上下文,将这些句子发送到BERT中,以提取长度为768的上下文化向量表示形式。
We use these representation that have rich context information to compute a Context Based Similarity Score between the Male only Adjectives and Female Only Adjectives used in with Positive or a Negative context. We take the mean of the contextual representations of all Male only Adjectives and Female Only Adjectives to get an averaged representation for all the Male only Adjectives and Female only Adjectives respectively. We then take the cosine similarity between the two vector representations to compute a Context Based Similarity Score as shown in the figure below:
我们使用具有丰富上下文信息的这些表示来计算在正或负上下文中使用的仅男性形容词和仅女性形容词之间的基于上下文的相似性得分 。 我们取所有男性专用形容词和女性专用形容词的上下文表示的平均值,以分别获得所有男性专用形容词和女性专用形容词的平均表示。 然后,我们使用两个向量表示之间的余弦相似度来计算基于上下文的相似度得分,如下图所示:
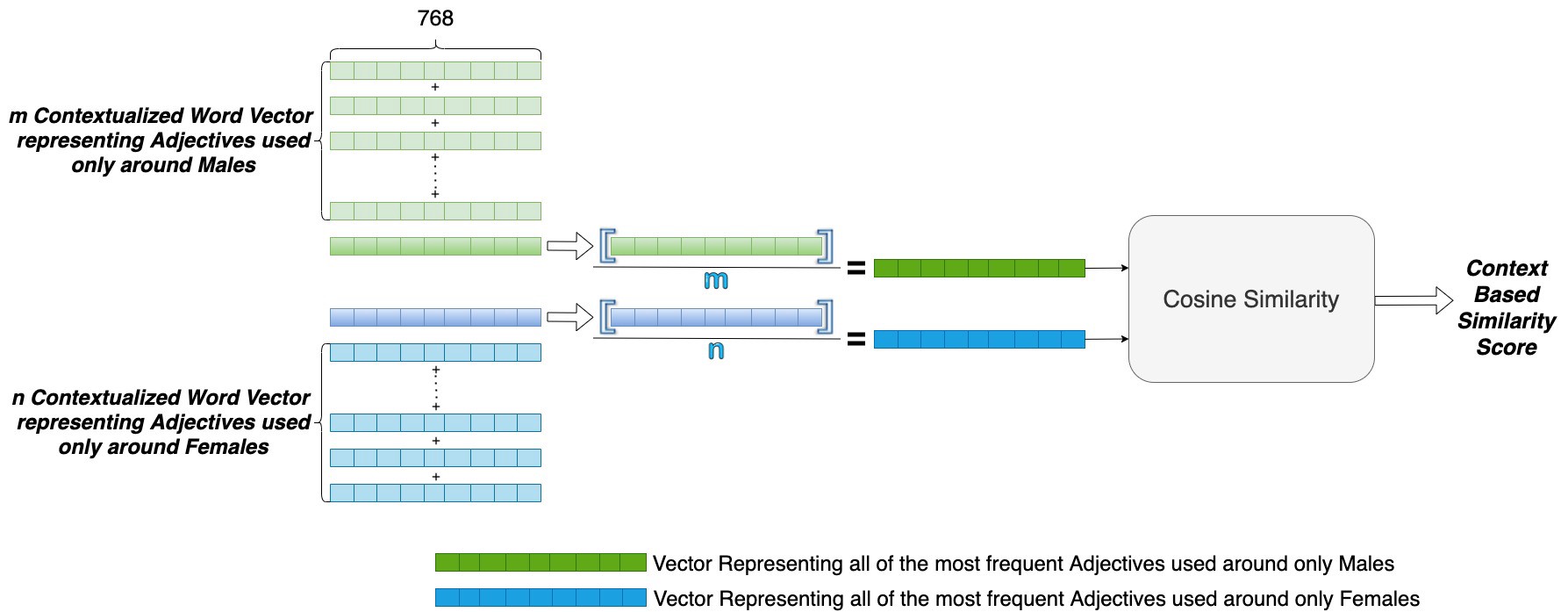
This score is calculated for a given sentiment and a given IAB vertical.
针对给定的情绪和给定的IAB垂直度计算此分数。
The higher this score, the better is the balance between the Adjectives being used around a particular gender in the context of a given sentiment and given IAB vertical.
该分数越高,在给定的情绪和IAB垂直的情况下针对特定性别使用的形容词之间的平衡就越好。
Let us look at the Context Based Similarity score in action:
让我们看一下基于上下文的相似性得分:

Comparing the two scores, we can see that we get a higher score in the case of Negative sentiment, where there were similar kind of Adjectives (equally negative in this case) used around Males and Females. On the other hand, we get a lower score in the case of Positive sentiment, where we did see some form of Bias with Intellectual Type Adjectives being used around Males while Appearance Type Adjectives being used around Females.
比较这两个分数,我们可以发现,在负面情绪的情况下,我们在男性和女性周围使用了相似类型的形容词(在这种情况下,均为负数)时得分更高。 另一方面,在积极情绪的情况下,我们得到了较低的分数,在这种情况下,我们确实看到了某种形式的偏见,其中男性使用智力类型形容词,而女性使用外观类型形容词。
结论 (Conclusion)
In this blog we saw how we can analyze the Descriptive Language used around Males and Females. We analyzed the insights found from such an analysis and saw how it can guide and point us to where the change might be required. We took a look at how GumGum can leverage Product Offerings like Content Classification and Named Entity Recognition from its vast variety of feature arsenal and build upon them to quantify the degree of similarities in the descriptive language being used around Males and Females. As a part of our future works, we can work on identifying Race mentions in a piece of text and easily extend this work to understand the Descriptive Language used around different Races.
在此博客中,我们看到了如何分析男性和女性周围使用的描述性语言。 我们分析了从这种分析中发现的见解,并了解了它如何指导并指出我们可能需要进行更改的地方。 我们研究了GumGum如何利用其功能丰富的功能库中的内容分类和命名实体识别之类的产品,并以此为基础来量化男性和女性使用的描述性语言的相似程度。 作为我们未来工作的一部分,我们可以在一段文字中识别种族提及,并轻松地扩展这项工作以理解围绕不同种族使用的描述性语言。
About Me: Graduated with a Masters in Computer Science from ASU. I am a NLP Scientist at GumGum. I am interested in applying Machine Learning/Deep Learning to provide some structure to the unstructured data that surrounds us.
关于我 :毕业于ASU的计算机科学硕士学位。 我是GumGum的NLP科学家。 我对应用机器学习/深度学习感兴趣,以便为我们周围的非结构化数据提供某种结构。
We’re always looking for new talent! View jobs.
我们一直在寻找新的人才! 查看工作 。
Follow us: Facebook | Twitter | | Linkedin | Instagram
关注我们: Facebook | 推特 | | Linkedin | Instagram
翻译自: https://medium.com/gumgum-tech/descriptive-language-understanding-to-identify-potential-bias-in-text-89936fefbae7
如何识别媒体偏见
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/389516.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

分享 : 警惕MySQL运维陷阱:基于MyCat的伪分布式架构

opencv:图像读取BGR变成RGB

数据不平衡处理_如何处理多类不平衡数据说不可以
思想及实现)
最小二乘法以及RANSAC(随机采样一致性)思想及实现

软键盘弹起,导致底部被顶上去

关于LaaS,PaaS,SaaS一些个人的理解

糖药病数据集分类_使用optuna和mlflow进行心脏病分类器调整

Android MVP 框架
)
相似图像搜索的哈希算法思想及实现(差值哈希算法和均值哈希算法)

腾讯云AI应用产品总监王磊:AI 在传统产业的最佳实践
和归一化实现)
标准化(Normalization)和归一化实现

Toast源码深度分析

序列化框架MJExtension详解 + iOS ORM框架
 or ‘1type‘ as a synonym of type is deprecated解决办法)
运行keras出现 FutureWarning: Passing (type, 1) or ‘1type‘ as a synonym of type is deprecated解决办法
转移方式及参数传递)
RedirectToAction()转移方式及参数传递


mongdb 群集_群集文档的文本摘要

keras框架实现手写数字识别

gdal进行遥感影像读写_如何使用遥感影像进行矿物勘探
