rcp rapido
Back in 2019, when we were building our data platform, we started building the data platform with Hadoop 2.8 and Apache Hive, managing our own HDFS. The need for managing workflows whether it’s data pipelines, i.e. ETL’s, machine learning predictive, and general generic pipelines was a core requirement where each task is different.
在2019年其他回,当我们建设我们的数据平台,我们开始用Hadoop 2.8和Apache蜂巢建设数据平台,管理我们自己的HDFS。 无论是数据管道(即ETL,机器学习预测性管道还是通用管道),都需要管理工作流,这是每个任务都不同的核心要求。
Some just schedule a task on GCP like creating a Cloud Run an instance or Dataproc Spark cluster at a scheduled time and some tasks are different because they can only be scheduled based on data availability or Hive partition availability.
有些仅在GCP上安排任务,例如在创建Cloud时运行实例或Dataproc Spark集群,而有些任务则不同,因为它们只能基于数据可用性或Hive分区可用性进行计划。
To sum up, the requirements at that time in the data platform which required a scheduling system were like:
综上所述,当时需要调度系统的数据平台需求如下:
- ETL pipelines ETL管道
- Machine learning workflows 机器学习工作流程
- Maintenance: Database backups 维护:数据库备份
API Calls: Example can be Kafka Connect connectors management
API调用:示例可以是Kafka Connect连接 器管理
Run naive cron based jobs where the task is to spin up some infra in a public cloud, for example, to spin up a new cluster or scale-up existing Dataproc cluster, stop the instances or scale the Cloud Run, etc..
运行基于天真的cron的作业,其中的任务是在公共云中启动一些基础架构,例如,启动新集群或扩展现有Dataproc集群,停止实例或扩展Cloud Run等。
- Deployments: Git -> Code deployments 部署:Git->代码部署
ETL pipelines consist of a complex network of dependencies which are not just data-dependent, and these dependencies can vary based on the use cases metrics, creating canonical forms of datasets, model training
ETL管道由复杂的依赖关系网络组成,这些依赖关系不仅仅依赖于数据,而且这些依赖关系可以根据用例指标,创建数据集的规范形式,模型训练而变化
To create immutable datasets (no update, upsert, or delete) we started with a stack of Apache Hive, Apache Hadoop (HDFS), Apache Druid, Apache Kafka, and Apache Spark with the following requirements or goals:
为了创建不可变的数据集(不进行更新,更新或删除),我们从满足以下要求或目标的Apache Hive , Apache Hadoop ( HDFS ), Apache Druid , Apache Kafka和Apache Spark堆栈开始:
Creating reproducible pipelines, i.e. Pipelines output need to be deterministic like with Functional programming if there is retry or we retrigger the tasks the outcome should be same, i.e. Pipelines and tasks need to be idempotent
创建可重现的管道,例如,如果有重试,则管道输出必须像函数式编程一样具有确定性;如果重试或重新触发任务, 结果应该是相同的,即管道和任务必须是幂等的
Backfilling is a must since data can evolve.
因为数据可以发展,所以回填是必须的。
Robust — Easy changes to the configuration
坚固耐用 —轻松更改配置
Versioning of configuration, data, and tasks, i.e. easily add or remove new tasks over time or update the existing dags code
配置,数据和任务的版本控制 ,即随时间轻松添加或删除新任务,或更新现有的dags代码
Transparency with data flow: we discussed that something similar to Jaeger Tracing for data platform would be tremendous and checked at possible options like Atlas and Falcon
数据流的透明度 :我们讨论过,类似于Jaeger Tracing的数据平台将是巨大的,并在Atlas和Falcon等可能的选项中进行了检查
Cloud Scheduler之旅(托管cron) (Journey with Cloud Scheduler(Managed cron))
We started using Cloud Scheduler with shell scripts, and python scripts since it was fully managed by google cloud, and setting up cron jobs is just a few clicks. Cloud Scheduler is a fully managed cron job scheduler.
我们开始将Cloud Scheduler与Shell脚本和python脚本一起使用,因为它完全由Google Cloud管理,并且只需单击几下即可设置cron作业。 Cloud Scheduler是完全托管的cron作业调度程序。
The main reason to go with Cloud Scheduler was unlike the self-managed cron instance, there is no single point of failure, and it’s designed to provide “at least once” delivery on jobs from cron tasks to automating resource creation like we used to run jobs which were creating Virtual Machine’s, Cloud Run, etc.
使用Cloud Scheduler的主要原因与自我管理的cron实例不同, 没有单点故障 ,它旨在为从cron任务到自动化资源创建的作业提供“ 至少一次”交付,就像我们以前运行的那样创建虚拟机,Cloud Run等的作业。

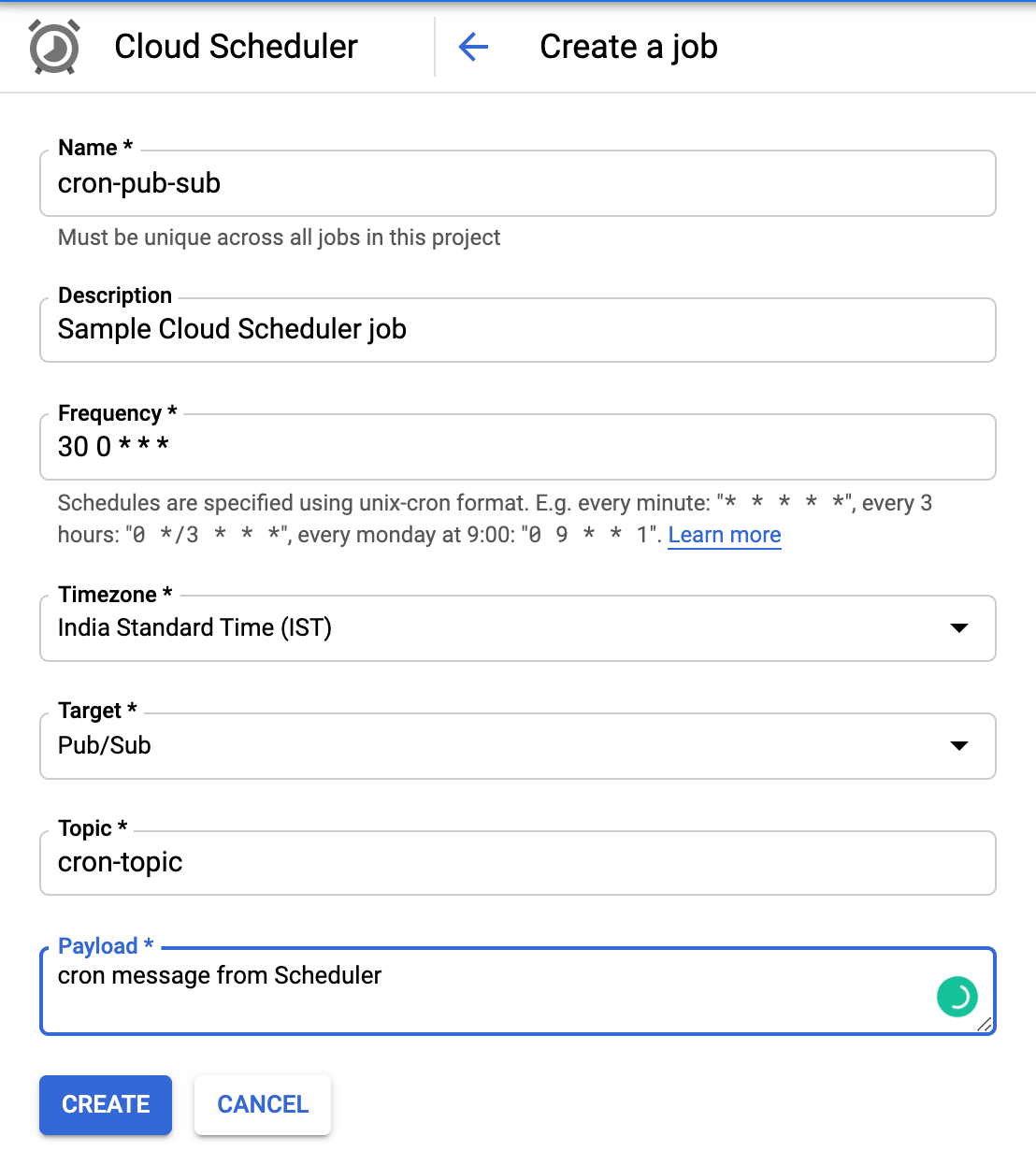
Cloud scheduler or cron doesn’t offer dependency management, so we have to “hope dependent pipelines finished in the correct order”. Had to scratch from the start for each pipeline or task (starting from blank for each pipeline won’t scale), though cloud scheduler has timezone supported we faced few timezone problems in druid ingestions and subsequent dependent tasks since the jobs were submitted manually via UI brings it can introduce human errors in pipelines, Cloud scheduler can also retry in case of failure to reduce manual toil and intervention, but there is no task dependency and managing complex workflows or backfilling was not available out of the box. So in few weeks, we decided that this may not be suitable for running data and ML pipelines since these involve lof of backfilling requirements, also cross DAG dependencies, and also may require data sharing between tasks.
云调度程序或cron不提供依赖项管理,因此我们必须“希望以正确的顺序完成依赖的管道”。 尽管云调度程序已支持时区,但由于调度程序是通过UI手动提交的,因此在德鲁伊和后续依赖任务中几乎没有时区问题 ,尽管云调度程序已支持时区,但必须从头开始为每个管道或任务从头开始(每个管道的空白都不会扩展)。带来的好处是可以在管道中引入人为错误,Cloud Scheduler还可以在失败的情况下重试,以减少人工劳动和干预,但是它没有任务依赖性 ,管理复杂的工作流程或开箱即用也无法回填 。 因此,在几周内,我们认为这可能不适合运行数据和ML管道,因为它们涉及回填要求的不足,还涉及DAG依赖性,并且还可能需要任务之间进行数据共享。
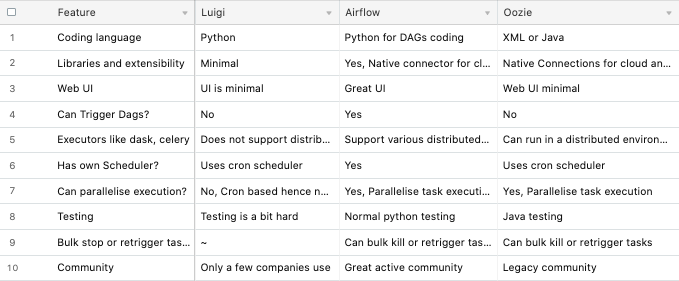
Then, we started looking into the popular open-source workflow management platforms which can handle 100’s of task with failures and callback strategies and tried to code a few tasks, and deploy them in GCP to complete the POC. Projects which were considered were Apache Airflow, Apache Oozie, Luigi, Argo, and Azkaban.
然后,我们开始研究流行的开源工作流管理平台 ,该平台可处理带有故障和回调策略的 100多个任务,并尝试编写一些任务,并将其部署在GCP中以完成POC。 被考虑的项目是Apache Airflow , Apache Oozie , Luigi , Argo和Azkaban 。
Both Apache Oozie and Azkaban were top projects at that time with the stable release. Oozie is a reliable workflow scheduler system to manage Apache Hadoop jobs. Oozie is integrated with the rest of the Hadoop stack supporting several types of Hadoop jobs out of the box (such as Java map-reduce, Streaming map-reduce, Pig, Hive, Sqoop, and Distcp) as well as system-specific tasks (such as Java programs and shell scripts).
稳定版发布时,Apache Oozie和Azkaban都是当时的顶级项目。 Oozie是一个可靠的工作流计划程序系统,用于管理Apache Hadoop作业。 Oozie与其余Hadoop堆栈集成在一起,支持开箱即用的几种类型的Hadoop作业(例如Java map-reduce ,Streaming map-reduce,Pig,Hive,Sqoop和Distcp)以及特定于系统的任务(例如Java程序和Shell脚本)。
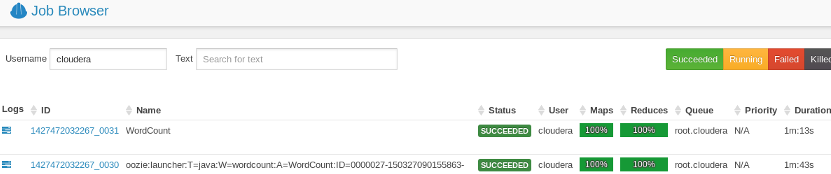
Still, with Oozie, we had to deal with XML definitions or had to zip a directory which contains the task-related dependencies, development workflow wasn’t as convincing as Airflow. Instead of managing multiple directories of XML configs and worrying about the dependencies between directories, the option to write python code can be tested, and since it’s a code all the software best practices can be applied to it.
仍然,对于Oozie,我们必须处理XML定义或压缩包含与任务相关的依赖关系的目录,开发工作流程并不像Airflow那样令人信服。 无需管理XML配置的多个目录并担心目录之间的依赖关系,而是可以测试编写python代码的选项,并且由于它是一种代码,因此可以将所有软件最佳实践应用于该代码。
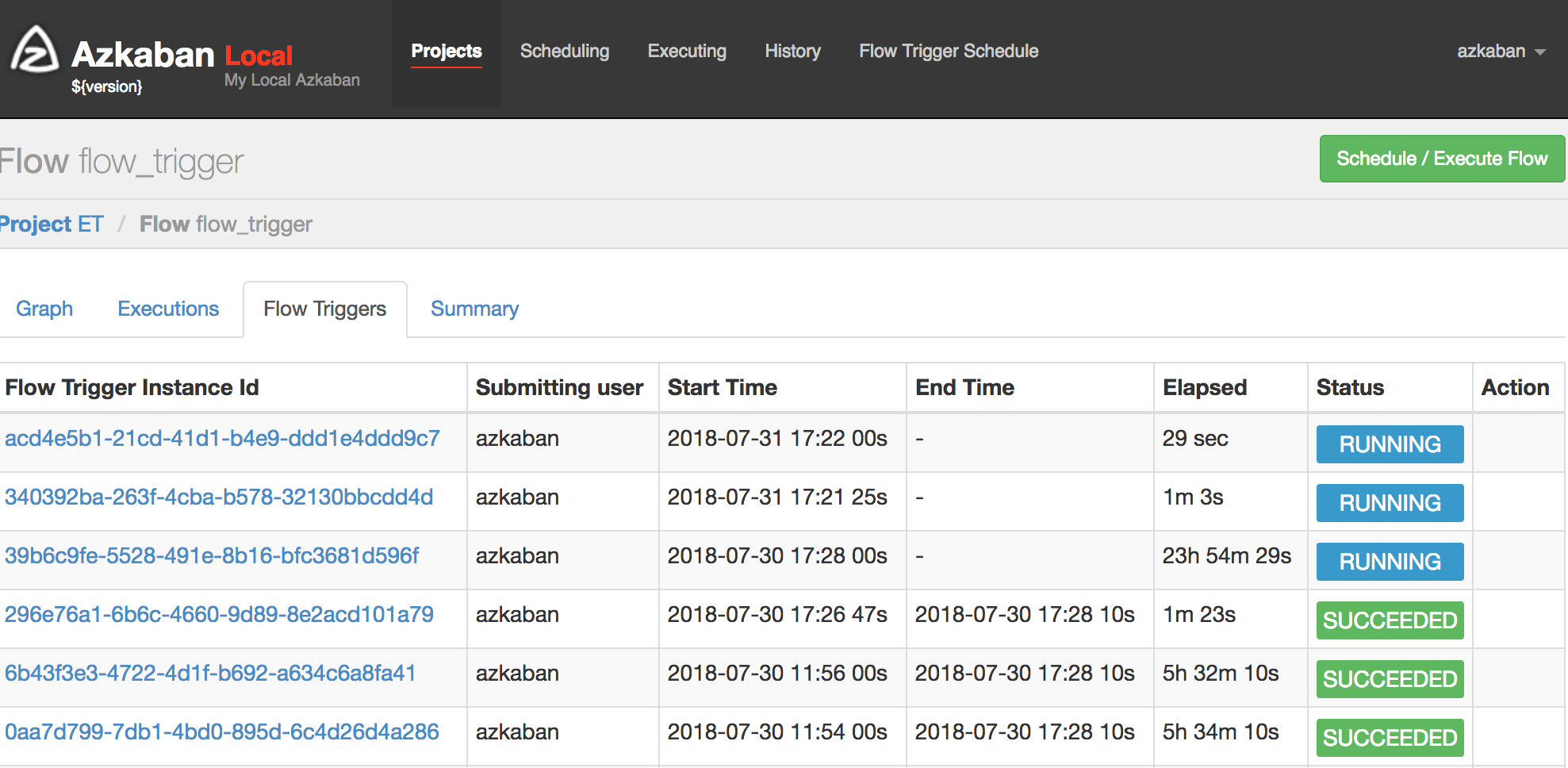
Azkaban has distributed multiple-executor mode and beautiful UI visualizations, option to retry failed jobs, good alerting options are available, can track user actions, i.e. auditing was available, but since the workflows are defined using property files finally, we didn’t consider this option.
Azkaban已分发了多个执行程序模式和精美的UI可视化效果,可以选择重试失败的作业,可以使用良好的警报选项,可以跟踪用户操作,即可以进行审核,但是由于最终使用属性文件定义了工作流程,因此我们没有考虑此选项。
Luigi was promising since the deployment in Kubernetes was so simple, and it handles dependency resolution, workflow management, visualization, handling failures, command line integration, and much more.
Luigi很有前途,因为在Kubernetes中的部署是如此简单,它可以处理依赖关系解析,工作流管理,可视化,处理故障,命令行集成等。
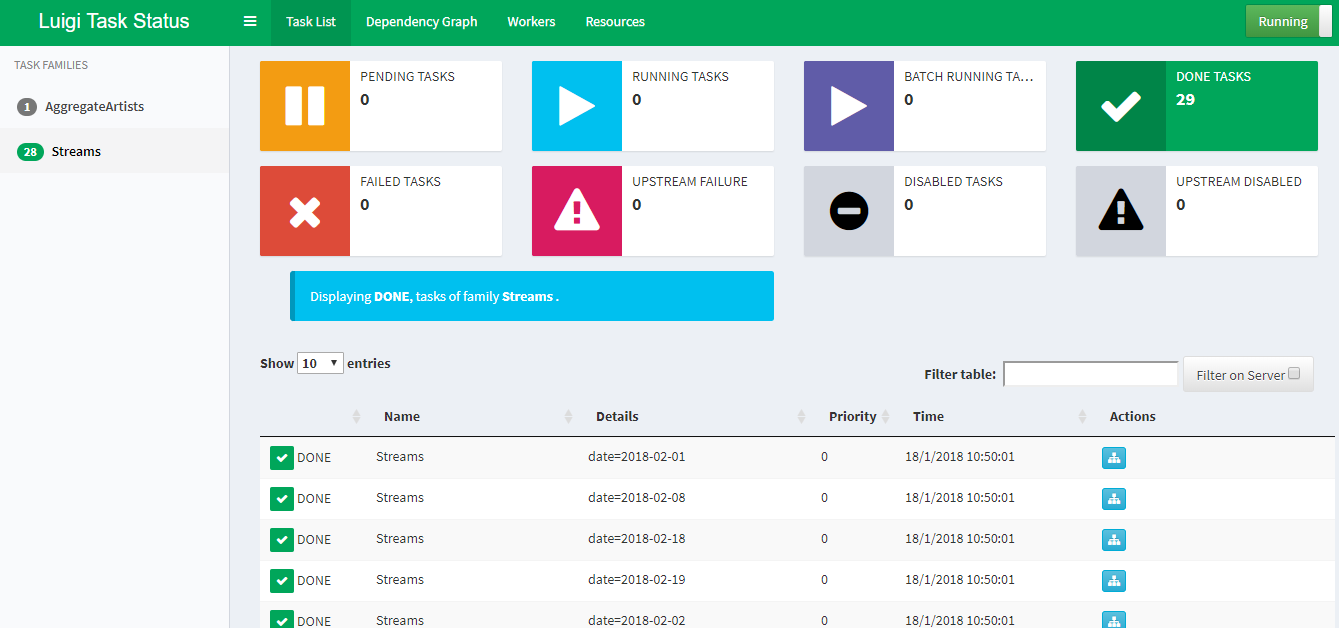
But re-running old tasks or pipelines was not clear, i.e. No option to retrigger the tasks. Since it uses the cron feature to schedule we have to wait for Luigi scheduler to schedule it again after updating the code where Airflow has its own scheduler hence we can retrigger the dag using Airflow CLI or UI.
但是重新运行旧任务或管道并不清楚,即没有重新触发任务的选项。 由于它使用cron功能进行计划,因此我们必须等待Luigi计划程序在更新代码后重新安排它,其中Airflow拥有自己的计划程序,因此我们可以使用Airflow CLI或UI重新触发dag。
Luigi being cron scheduler scaling seem difficult whereas in Airflow the Kubernetes executor was very promising. Creating a task was not as simple as Airflow, also maintaining the dag is a bit difficult as there were no resources for dag versioning.
Luigi作为cron调度程序的扩展似乎很困难,而在Airflow中,Kubernetes执行器非常有前途。 创建任务并不像Airflow那样简单,而且维护dag有点困难,因为没有用于dag版本控制的资源。
Finally, it was down to Airflow and Argo:
最后,归结为Airflow和Argo :
- Both are designed for batch workflows involving the directed Acyclic Graph (DAG) of tasks. 两者都是为涉及任务的有向无环图(DAG)的批处理工作流而设计的。
- Both provide flow control for error handling and conditional logic based on the output of upstream steps. 两者都基于上游步骤的输出提供错误处理和条件逻辑的流控制。
- Both have a great community and actively maintained by a community of contributors. 两者都有一个伟大的社区,并由贡献者社区积极维护。
为什么选择Airflow而不是Argo? (Why choose Airflow over Argo?)
But few main points at the time of decision were Airflow is tightly coupled to the Python ecosystem, and it’s all about dag code. At the same time, Argo provides flexibility to schedule steps which is very useful as anything which can run in the container may be used with Argo. Still, the problem is a longer development time since we will have to prepare each task’s docker container and push to Google Container Registry, which is our private Docker repository via CI/CD.
但是在做出决定时,很少有要点是Airflow与Python生态系统紧密相关,而这全都是关于dag代码的。 同时, Argo可以灵活地安排步骤,这非常有用, 因为可以在容器中运行的任何内容都可以与Argo一起使用。 尽管如此,问题仍然是更长的开发 时间,因为我们将不得不准备每个任务的docker容器并通过CI / CD推送到Google Container Registry ,这是我们的私有Docker存储库 。
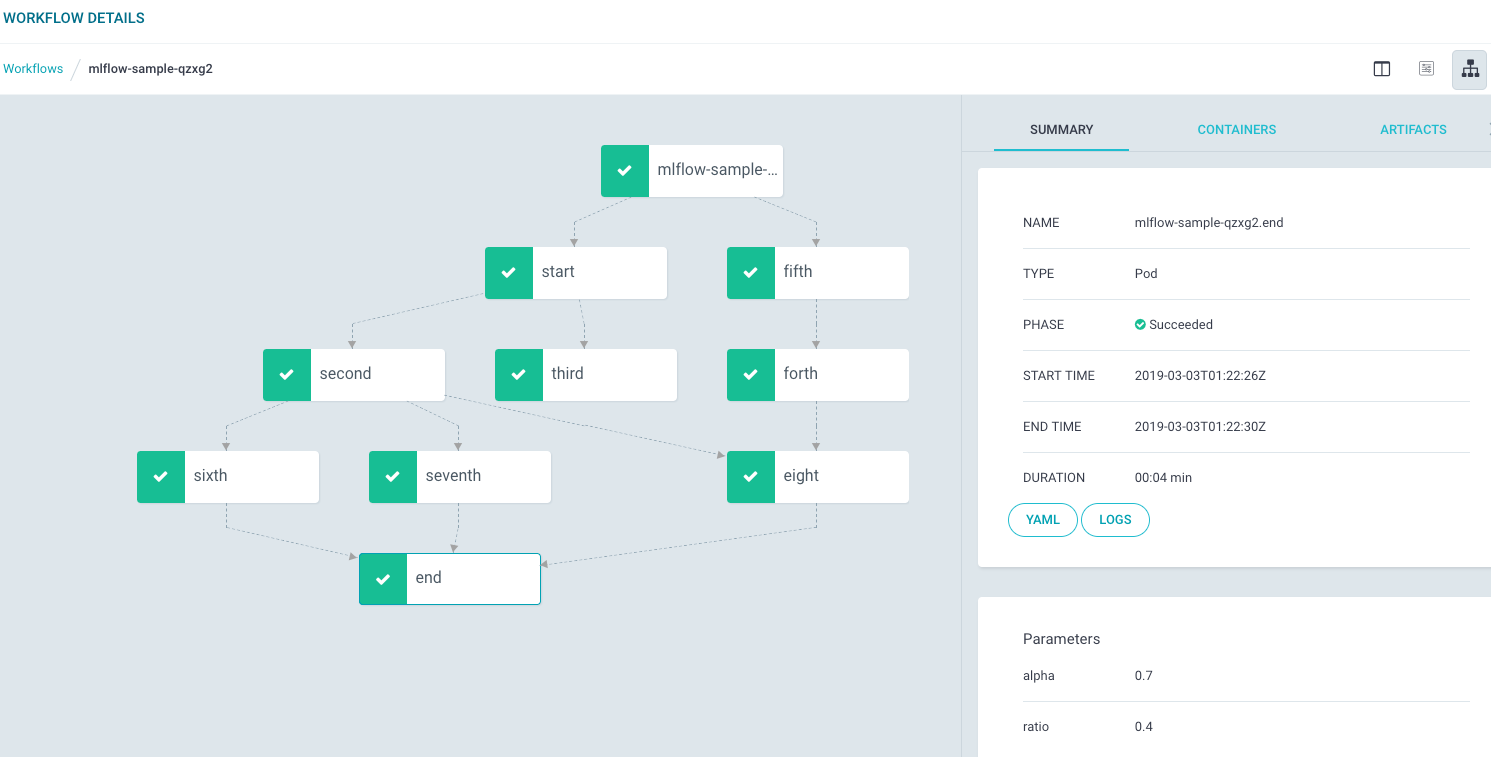
Argo natively schedules steps to run in a Kubernetes cluster, potentially across several hosts or nodes. Airflow also has K8 Pod Operator and Kubernetes Executor which sounded exciting since it will create a new pod for every task instance and no need worry about scaling celery pods
Argo本地计划在Kubernetes集群中运行的步骤 ,可能跨多个主机或节点运行。 Airflow还具有K8 Pod Operator和Kubernetes Executor ,这听起来很令人兴奋,因为它将为每个任务实例创建一个新的Pod,而无需担心缩放芹菜Pod
Airflow and Argo CLI are equally good, Airflow DAGs are expressed in a Python-based DSL, while Argo DAGs are expressed in a K8s YAML syntax with docker containers packing all the task code.
Airflow和Argo CLI都一样好,Airflow DAG用基于Python的DSL表示,而Argo DAG用K8s YAML语法表示,并且Docker容器包装了所有任务代码。

Airflow has a colossal adoption; hence there is a massive list of “Operators” and “Hooks” with support for other runtimes like Bash, Spark, Hive, Druid, Pinot, etc. Hence, Airflow was the clear winner.
气流的采用非常广泛; 因此,有大量的“ 操作员”和“ 钩子”列表支持其他运行时,例如Bash,Spark,Hive,Druid,Pinot等。因此,Airflow无疑是赢家。
To sum up, Airflow provides:
综上所述,Airflow提供:
Reliability: Airflow provides retries, i.e. can handle task failures by retrying it, that is if upstream dependencies succeed, then downstream tasks can retry if things fail.
可靠性 :Airflow提供重试功能,即可以通过重试来处理任务失败,也就是说,如果上游依赖项成功,那么如果事情失败,则下游任务可以重试。
Alerting: Airflow can report if dag failed or if dag didn’t meet an SLA and inform on any failure.
警报 :Airflow可以报告dag是否失败或dag不符合SLA,并通知任何失败。
Priority-based queue management which ensures the most critical tasks are completed first
基于优先级的队列管理 ,可确保首先完成最关键的任务
Resource pools can be used to limit the execution of parallelism on arbitrary sets of tasks.
资源池可用于限制并行执行任意任务集。
Centralized configuration
集中配置
Centralized metrics of tasks
集中的任务指标
Centralized Performace Views: With views like Gantt we can look at the actual performance of the dag and check if this specific dag has spent five or ten minutes waiting for some data to land in then once data arrived it trigger the spark job which might do some aggregation on that data. So these Views help us to analyze the performance over time.
集中的Performace视图 :使用类似Gantt的视图,我们可以查看dag的实际性能,并检查此特定dag是否花了五到十分钟等待一些数据进入,一旦数据到达,它就会触发火花作业,这可能会做一些对该数据进行汇总。 因此,这些视图可以帮助我们分析一段时间内的效果。
Future of Airflow:
气流的未来:
Since we already have 100s of dags running in production and with Fluidity(inhouse airflow dag generator) we expect the number of dags to grow by twice or thrice in the next few months itself, one of the most-watched features from Airflow 2.0 is the separation of the DAG parsing from DAG scheduling which can reduce the amount of time(time where no tasks are running) wasted in waiting and reduce the task time via fast follow of airflow tasks from workers.
由于我们已经有100多个dag在生产中运行,并且使用Fluidity(内部气流dag发生器),我们预计在接下来的几个月中dag的数量将增长两倍或三倍,因此Airflow 2.0最受关注的功能之一是DAG解析与DAG调度的分离 ,可以减少等待中浪费的时间(无任务运行的时间),并通过快速跟踪工人的气流任务来减少任务时间 。
Improving the DAG versioning to avoid manual creation of versioned dag [i.e. to add new task we go from DAG_SCALE_UP to DAG_SCALE_UP_V1]
改进DAG版本控制,以避免手动创建版本控制的数据[例如,添加新任务,我们从DAG_SCALE_UP转到DAG_SCALE_UP_V1]
High availability of scheduler for performance scalability and resiliency reasons is most with Active-Active models.
出于性能可伸缩性和弹性的原因,调度程序的高可用性在Active-Active模型中最为常见。
The development speed of Airflow is generally slow, and it involves a steep learning curve, so there is Fluidity(full blog coming soon), and the same dev replica exactly like the production environment using Docker and Minikube is spawned.
Airflow的开发速度通常很慢,并且学习曲线陡峭,因此存在Fluidity(即将推出完整博客),并且产生了与使用Docker和Minikube的生产环境完全相同的相同dev副本。
Work on data evaluation, reports and data lineage with Airflow
使用Airflow进行数据评估,报告和数据沿袭
If you enjoyed this blog post, check out what we’ve posted so far over here, and keep an eye out on the same space for some really cool upcoming blogs in the near future. If you have any questions about the problems we face as Data Platform at Rapido or about anything else, please reach out to chethan@rapido.bike, looking forward to answering any questions!
如果您喜欢这篇博客文章,请查看我们到目前为止在这里发布的内容,并在不久的将来留意相同的空间来关注一些即将发布的非常酷的博客。 如果您对我们在Rapido上使用数据平台时遇到的问题或其他任何问题有任何疑问,请联系chethan@rapido.bike ,期待回答任何问题!
*Special Thanks to the Rapido Data Team for making this blog possible.
*特别感谢Rapido数据团队使此博客成为可能。
翻译自: https://medium.com/rapido-labs/why-is-airflow-a-great-fit-for-rapido-d8438ca0d1ab
rcp rapido
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/389336.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

pandas处理丢失数据与数据导入导出

Mysql5.7开启远程

分类结果可视化python_可视化分类结果的另一种方法

算法组合 优化算法_算法交易简化了风险价值和投资组合优化

Symbol Mc1000 快捷键 的 设置 事件 开发

pandas合并concatmerge和plot画图

Android跳转WIFI界面的四种方式

PS抠发丝技巧 「选择并遮住…」

covid 19如何重塑美国科技公司的工作文化

Symbol Mc1000 Text文本阅读器整体代码

python生日悖论分析_生日悖论

统计0-n数字中出现k的次数

房价预测 search Search 中对数据预处理的学习

3.6.1.非阻塞IO

Symbol MC1000 扫描 冲突问题 把下面文件做成scanwedge.reg的注册表文件,放在Application重起

rstudio 管道符号_R中的管道指南

蒙特卡洛模拟预测股票_使用蒙特卡洛模拟来预测极端天气事件

iOS之UITraitCollection

直方图绘制与直方图均衡化实现
