Behind the scenes of modern Web Browsers
现代Web浏览器的幕后花絮
The Web Browser is inarguably the most common portal for users to access the web. The advancement of the web browsers (through the series of history) has led many traditional “thick clients” to be replaced by browser enhancing its usability and ubiquity. The web browser is an application that provides access to the webserver, sends a network request to URL, obtain resources, and interactively represent them. Common Browsers today include Firefox, Google Chrome, Safari, Internet Explorer and Opera.
Web浏览器无疑是用户访问Web的最常用门户。 网络浏览器的发展(经过一系列的历史发展 )已导致许多传统的“胖客户端”被浏览器所取代,从而增强了其可用性和普遍性。 Web浏览器是一种应用程序,它提供对Web服务器的访问,向URL发送网络请求,获取资源并以交互方式表示它们 。 今天的常见浏览器包括Firefox , Google Chrome , Safari , Internet Explorer和Opera 。
Web浏览器的结构 (Structure of Web Browser)
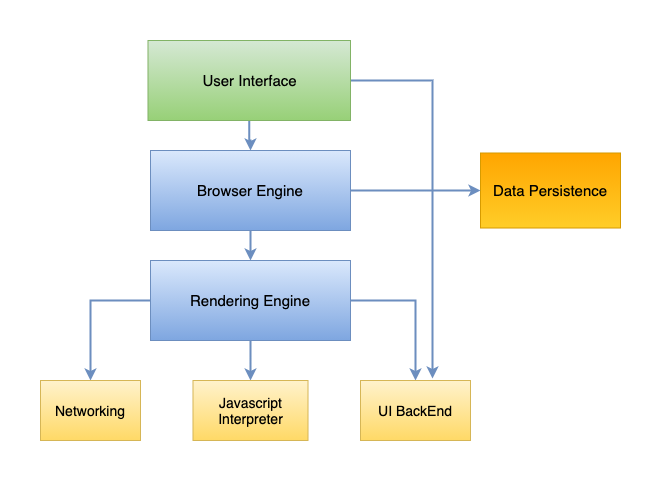
1.用户界面 (1. User Interface)
It is a space where interaction between user and browser (application) occurs via the control presented in the browser. No specific standards are imposed on how web browsers should look and feel. The HTML5 specification doesn’t define UI elements but lists some common elements: location bar, personal bar, scrollbars, status bar, and toolbar.
在该空间中,用户和浏览器(应用程序)之间的交互通过浏览器中显示的控件发生。 Web浏览器的外观和感觉没有任何特定标准。 HTML5规范没有定义UI元素,而是列出了一些常见的元素:位置栏,个人栏,滚动条,状态栏和工具栏。
2.浏览器引擎 (2. Browser Engine)
It provides a high-level interface between UI and the underlying rendering engine. It makes a query and manipulates the rendering engine based upon the user interaction. It provides a method to initiate loading the URL, takes care of reloading, back, and forward browsing action.
它在UI和基础渲染引擎之间提供了高级接口。 它进行查询并根据用户交互操作渲染引擎。 它提供了一种启动加载URL的方法,负责重新加载,后退和前进浏览操作。
3.渲染引擎 (3. Rendering Engine)
The Rendering Engine is responsible for displaying the content of the web page on the screen. The primary operation of a Rendering engine is to parse HTML. By default, it displays HTML, XML, and images and supports other data types via plugin or extension.
渲染引擎负责在屏幕上显示网页的内容。 渲染引擎的主要操作是解析HTML。 默认情况下,它显示HTML,XML和图像,并通过插件或扩展名支持其他数据类型。
Rendering Engine for modern web Browsers
适用于现代Web浏览器的渲染引擎
Firefox — Gecko Software
Firefox — Gecko软件
Safari — WebKit
Safari — WebKit
Chrome, Opera (15 onwards) — Blink
Chrome,Opera(15以上)- 闪烁
Internet Explorer — Trident
Internet Explorer — 三叉戟
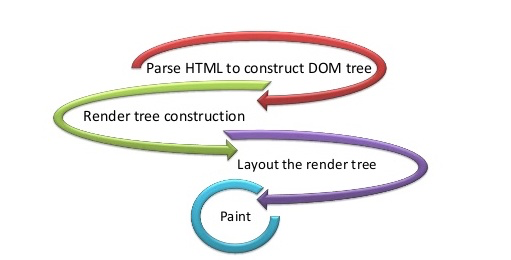
关键渲染路径 (Critical Rendering Path)
To plot the pixels in the screen (first render), the browser after receiving the data (HTML, CSS, JavaScript) from the network has to go through a series of processes/techniques called Critical Rendering Path. This includes DOM, CSSOM, Render Tree, Layout, and Painting.
为了在屏幕上绘制像素(第一次渲染),浏览器从网络接收到数据(HTML,CSS,JavaScript)后,必须经过一系列称为“关键渲染路径”的过程/技术。 这包括DOM,CSSOM,渲染树,布局和绘画。
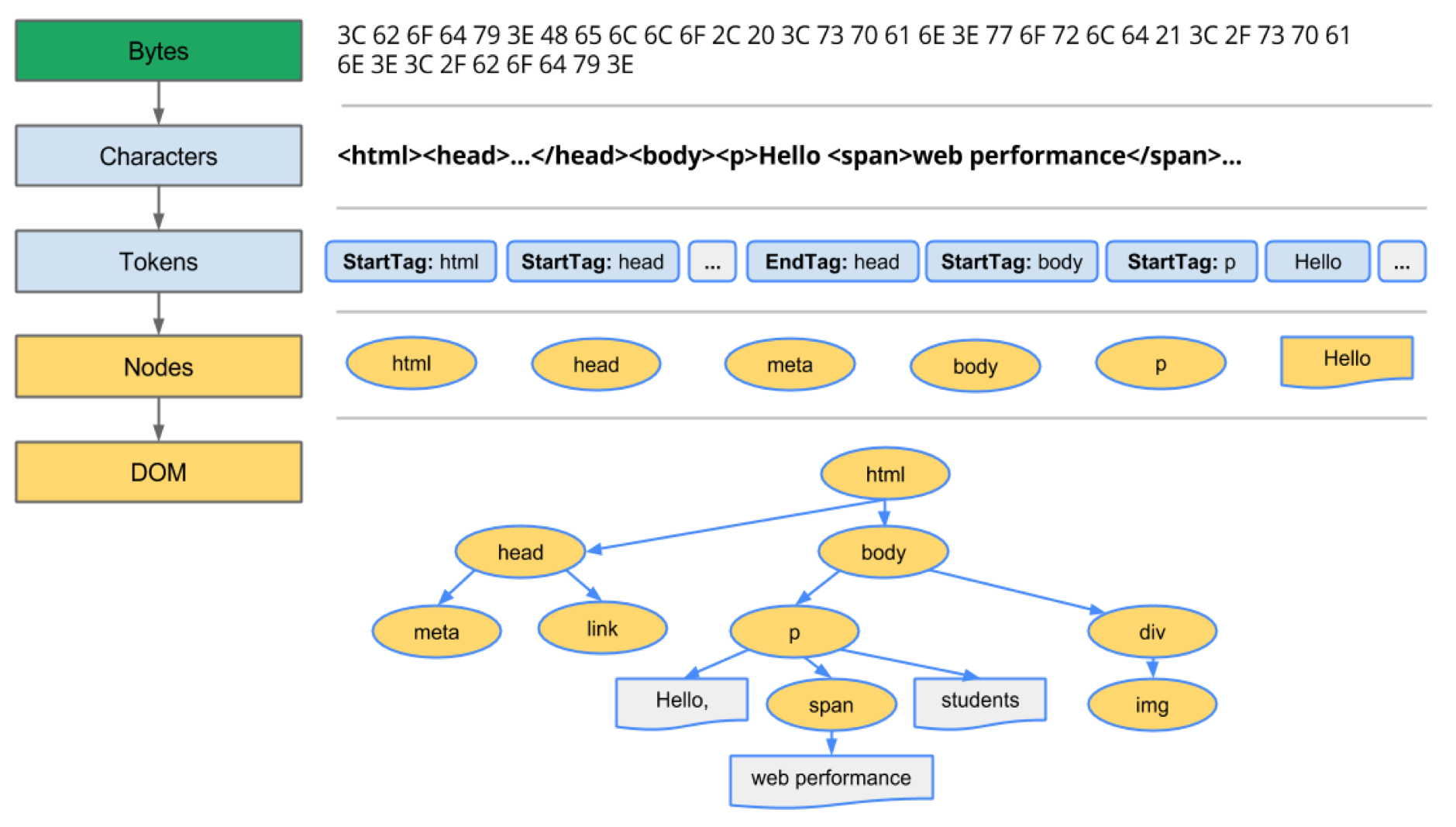
数据到DOM (Data to DOM)
The requested content from the networking layer is received in the rendering engine (8 kb chunks generally) in the binary stream format. The raw bytes are then converted to a character (based upon character encoding) of the HTML file.
来自网络层的请求内容以二进制流格式在呈现引擎(通常为8 kb块)中接收。 然后将原始字节转换为HTML文件的字符 (基于字符编码)。
Characters are then converted into tokens. Lexer carries out lexical analysis, breaking input into tokens. During tokenization, every start and end tags in the file are accounted for. It knows out how to strip out irrelevant characters like white space and line breaks. The parser then carries out syntax analysis, applying the language syntax rule to construct a parse tree by analyzing the document structure.
然后将字符转换为令牌 。 Lexer进行词法分析 ,将输入分解为标记。 在标记化期间,将考虑文件中的每个开始和结束标记。 它知道如何去除不相关的字符,例如空格和换行符。 然后,解析器执行语法分析 ,通过分析文档结构,应用语言语法规则来构建解析树 。
The parsing process is iterative. It will ask the lexer for a new token and the token will be added to the parse tree if the language syntax rule match. The parser will then ask for another token. If no rule matches, the parser will store the token internally and keep asking for tokens until rule matching all the internally stored token is found. If no rule is found, then the parser will raise the exception. This means the document was not valid and contained syntax errors.
解析过程是迭代的 。 如果语言语法规则匹配,它将向词法分析器询问新的令牌,并将该令牌添加到解析树。 然后解析器将要求另一个令牌。 如果没有规则匹配,则解析器将在内部存储令牌,并继续请求令牌,直到找到与所有内部存储的令牌匹配的规则。 如果未找到任何规则,则解析器将引发exception 。 这意味着文档无效并且包含语法错误。
These nodes are linked in the tree data structure called DOM (Document Object Model) which establishes the parent-child relationship, adjacent sibling relationships.
这些节点在称为DOM(文档对象模型)的树数据结构中链接,该结构建立父子关系,相邻的兄弟关系。
从CSS数据到CSSOM (CSS Data to CSSOM)
Raw bytes of CSS data are converted into character, token, node, and finally in CSSOM (CSS Object Model). CSS has something called cascade which determines what styles are applied to the element. Styling data to the element can come from parents (via inheritance) or are set to the elements themselves. The browser has to recursively go through the CSS tree structure and determine the style of the particular element.
CSS数据的原始字节被转换为字符,令牌,节点,最后转换为CSSOM (CSS对象模型)。 CSS有一个称为层叠的东西,它确定将什么样式应用于元素。 元素数据的样式可以来自父级(通过继承),也可以设置为元素本身。 浏览器必须递归地遍历CSS树结构并确定特定元素的样式。
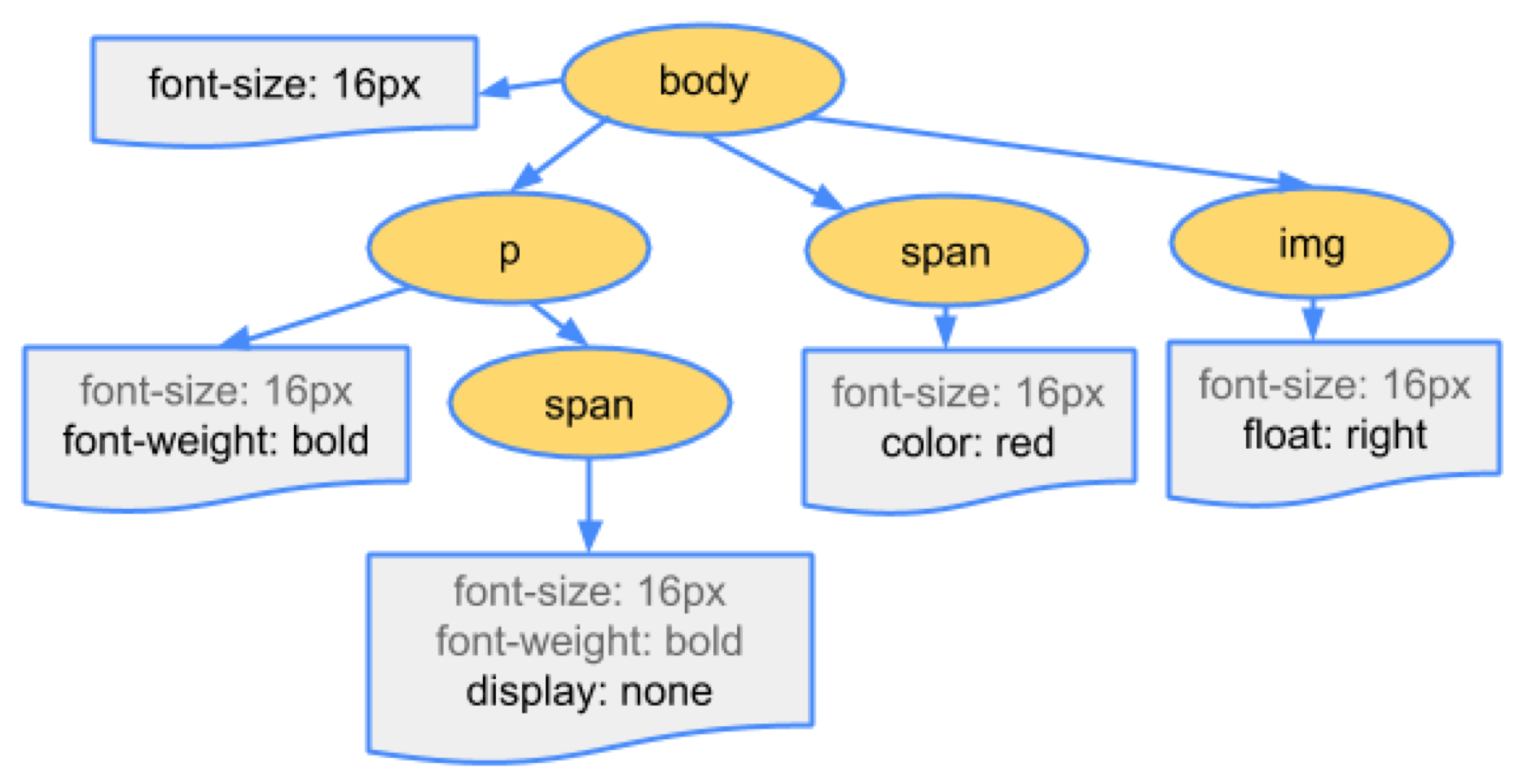
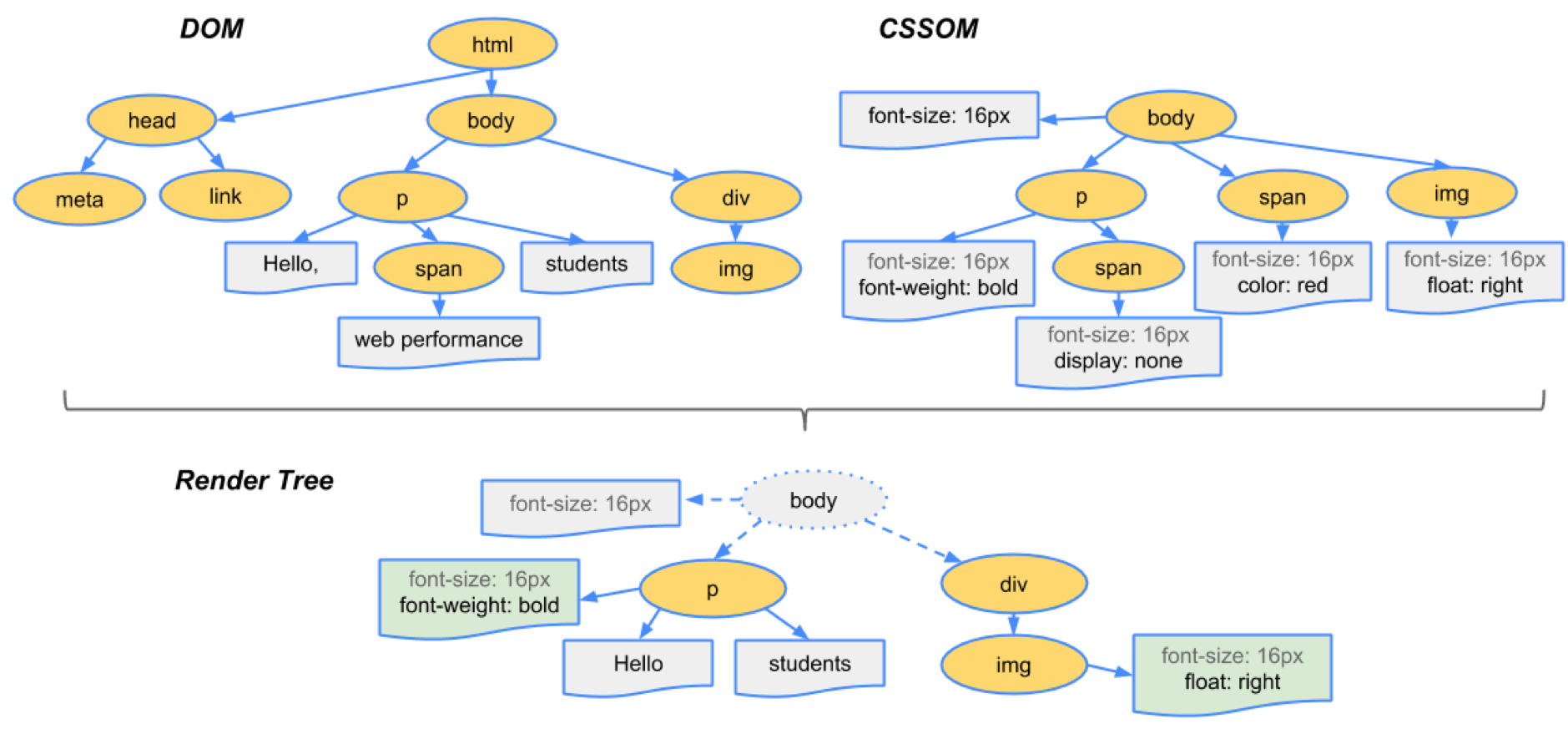
DOM和CSSOM渲染树 (DOM and CSSOM to Render Tree)
DOM tree contains the information about HTML elements relationship and the CSSOM tree contains information on how these elements are styled. Starting from the root node the browser traverses each of the visible nodes. Some nodes are hidden (controlled via CSS) and not reflected in the rendered output. For each visible node, the browser matches the appropriate rule defined in CSSOM and finally, these nodes are emitted with their content and styling called Render tree (Layout Tree).
DOM树包含有关HTML元素关系的信息,而CSSOM树包含有关如何设置这些元素样式的信息。 从根节点开始,浏览器遍历每个可见节点。 有些节点是隐藏的(通过CSS控制),不会反映在渲染的输出中。 对于每个可见节点,浏览器都会匹配CSSOM中定义的适当规则,最后,这些节点将以其内容和样式(称为“ 渲染树”(Layout Tree))发出。
布局 (Layout)
It then proceeds to the next level called layout. The exact size and position of each of the content should be calculated to render on a page (browser viewport). The process is also referred to as reflow. HTML uses a flow-based layout model, meaning geometry is computed in a single pass most of the time. It is a recursive process starting from the root element (<html>) of the document.
然后,它前进到称为布局的下一个级别。 应该计算每个内容的确切大小和位置,以在页面(浏览器视口)上呈现。 该过程也称为回流 。 HTML使用基于流的布局模型,这意味着大多数情况下,几何都是通过一次遍历计算的。 这是一个从文档的根元素(<html>)开始的递归过程。
绘画 (Painting)
Each of the renderers is traversed and the paint method is called to display the content on the screen. The painting process can be global (painting the entire tree) or incremental (the render tree validates its rectangle on-screen) and OS generates the paint event on that specific nodes and the whole tree is not affected. Painting is a gradual process where some parts are parsed and rendered while the process continues with the rest of the item from the network.
遍历每个渲染器,并调用paint方法以在屏幕上显示内容。 绘制过程可以是全局的(绘制整个树),也可以是增量的(渲染树在屏幕上验证其矩形),并且OS在该特定节点上生成绘制事件,并且整个树均不受影响。 绘画是一个渐进的过程,其中一些部分将被解析和渲染,而该过程将继续处理网络中的其余项目。
For analyzing, measuring, and optimizing Critical Rendering Path, refer here.
有关分析,测量和优化关键渲染路径的信息,请参见 此处 。
4. JavaScript解释器(JS引擎) (4. JavaScript Interpreter (JS Engine))
JavaScript is a scripting language that allows you to dynamically update the web content, control multimedia, and animated images executed by the browser’s JS engine. DOM and CSSOM provide an interface to JS which can alter both DOM and CSSOM. Since the browser is unsure what particular JS will do, it will immediately pause the DOM tree construction after it encounters the script tag. Every script is a parse blocker; the DOM tree construction is halted.
JavaScript是一种脚本语言,可让您动态更新Web内容,控制多媒体以及由浏览器JS引擎执行的动画图像。 DOM和CSSOM提供了JS的接口,该接口可以同时更改DOM和CSSOM。 由于浏览器不确定特定的JS会做什么,因此在遇到script标签后,它将立即暂停DOM树的构建。 每个脚本都是一个解析阻止程序; DOM树的构建被暂停。
The JS engine begins parsing the code right away after fetching from the server feeding into the JS parser. It converts them into the representative object the machine understands. The object that stores all the parser information in the tree representation of the abstract syntactic structure is called an object syntax tree (AST). The objects are fed into an interpreter which translates those objects into byte code.
从服务器获取到JS解析器后,JS引擎立即开始解析代码。 它将它们转换为机器可以理解的代表性对象。 将所有解析器信息存储在抽象语法结构的树表示中的对象称为对象语法树( AST )。 这些对象被馈送到解释器,该解释器将这些对象转换为字节码。
These are Just In Time (JITs) compiler meaning JavaScript files downloaded from the server is compiled in real-time on the client’s computer. The interpreter and compiler are combined. The interpreter executes source code almost immediately; the compiler generates machine code which the client system executes directly.
它们是即时( JIT )编译器,这意味着从服务器下载JavaScript文件是在客户端计算机上实时编译的。 解释器和编译器结合在一起。 解释器几乎立即执行源代码。 编译器生成机器代码,客户端系统直接执行该机器代码。
不同的浏览器使用不同的JS引擎 (Different Browser uses different JS Engine)
Chrome — V8 (JavaScript engine) (Node JS was built on top of this)
Chrome- V8(JavaScript引擎) (Node JS建立在此之上)
Mozilla — SpiderMonkey (formerly known as ‘Squirrel Fish’)
Mozilla- SpiderMonkey (以前称为“ 松鼠鱼 ”)
Microsoft Edge — Chakra
Microsoft Edge-查克拉
Safari — JavaScriptCore / Nitro WebKit
Safari- JavaScriptCore / Nitro WebKit
5. UI后端 (5. UI Back End)
It is used for drawing a basic widget like combo boxes and windows. Underneath it uses operating system user interface methods. It exposes a generic platform that is not platform-specific.
它用于绘制基本的窗口小部件,如组合框和窗口。 它的下面使用操作系统用户界面方法。 它公开了不是特定于平台的通用平台。
6.数据存储 (6. Data Storage)
This layer is persistent which helps the browser to store data (like cookies, session storage, indexed DB, Web SQL, bookmarks, preferences, etc). The new HTML5 specification describes a database that is a complete database in a web browser.
该层是持久层,可帮助浏览器存储数据(例如Cookie,会话存储,索引数据库,Web SQL,书签,首选项等)。 新HTML5规范描述了一个数据库,该数据库是Web浏览器中的完整数据库。
7.联网 (7. Networking)
It handles all kinds of network communication within the browser. It uses a set of communication protocols like HTTP, HTTPs, FTP while fetching the resource from requested URLs.
它处理浏览器内的各种网络通信。 它从请求的URL提取资源时使用HTTP,HTTPs,FTP等一组通信协议。
Web Browser relies on DNS to resolve the URLs. The records are cached in the browser, OS, router, or ISP. If the requested URL is not cached in, the ISP DNS server initiates the DNS query to find the IP of that server. After receiving the correct IP address the browser establishes the connection with the server with protocols. The browser sends the SYN(synchronize) packet to the server asking if it is open for TCP connection. The server responds with ACK(acknowledgment) of the SYN packet using the SYN/ACK packet.
Web浏览器依靠DNS来解析URL。 记录被缓存在浏览器,操作系统,路由器或ISP中。 如果未缓存请求的URL,则ISP DNS服务器将启动DNS查询以查找该服务器的IP。 收到正确的IP地址后,浏览器将使用协议与服务器建立连接。 浏览器将SYN(同步)数据包发送到服务器,询问它是否已打开以进行TCP连接。 服务器使用SYN / ACK数据包以SYN数据包的ACK(确认)响应。
The browser receives an SYN/ACK packet from the server and will acknowledge by sending an ACK packet. Then TCP connection is established for data communication. Once the connection is established, data transfer is ready. To transfer the data, the connection must meet the requirements of HTTP Protocol including connection, messaging, request, and response rules.
浏览器从服务器接收到SYN / ACK数据包,并将通过发送ACK数据包进行确认。 然后建立TCP连接以进行数据通信。 建立连接后,就可以进行数据传输了。 要传输数据,连接必须满足HTTP协议的要求,包括连接,消息传递,请求和响应规则。
渲染阻止和解析器阻止资源 (Render Blocking and Parser Blocking Resources)
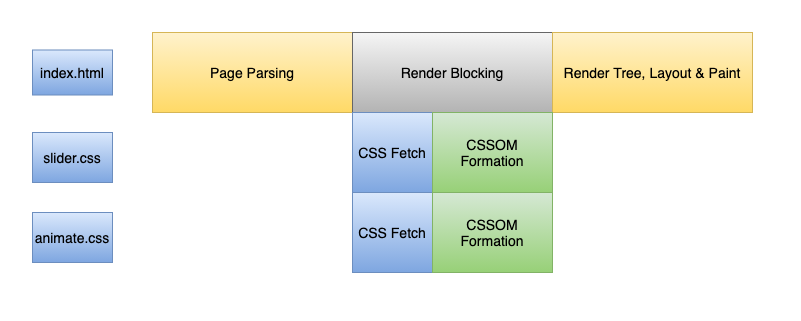
Whenever the Browser encounters an element for loading external CSS a request is sent over the network to fetch the .css file asynchronously. It will move immediately (without waiting for CSS resources to be downloaded) to parse elements below it and the DOM construction process is not halted. However, even after DOM tree construction without CSSOM being ready, the Browser won’t render anything into the screen. In order to render, both DOM and CSSOM have to be constructed. Hence HTML and CSS both are both render-blocking resources. Rendering Content without CSS being fully loaded cause Flash Of Unstyled Content (FOUC).
每当浏览器遇到加载外部CSS的元素时,都会通过网络发送请求以异步方式获取.css文件。 它会立即移动(无需等待CSS资源下载)以解析其下面的元素,并且DOM构造过程不会停止 。 但是,即使在尚未准备好CSSOM的情况下构造DOM树之后,浏览器也不会在屏幕上呈现任何内容 。 为了进行渲染,必须同时构建DOM和CSSOM 。 因此,HTML和CSS都是渲染阻止资源 。 在未完全加载CSS的情况下呈现内容会导致样式样式内容(FOUC)泛滥 。
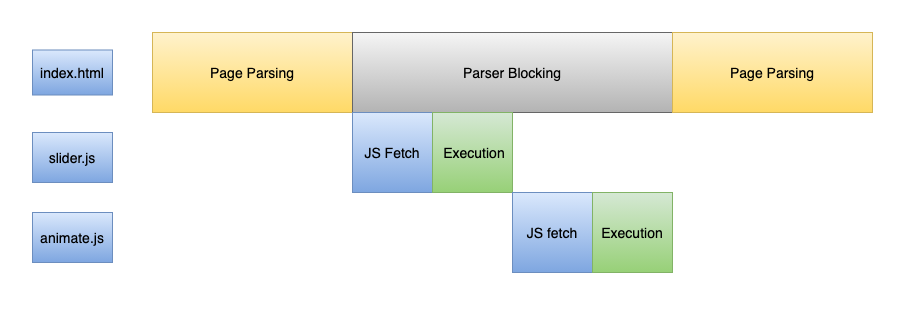
However, that is not the case with Javascript. Whenever the browser encounters a script tag, the DOM construction process is immediately paused until the Js file is downloaded and executed. This is because JavaScript has the capability to alter the parsing of subsequent markup (DOM, CSSOM). This makes Javascript a parser-blocking resource.
但是,Java并非如此。 每当浏览器遇到脚本标签时, DOM构造过程都会立即暂停,直到下载并执行Js文件为止 。 这是因为JavaScript能够更改后续标记(DOM,CSSOM)的解析。 这使Javascript成为了解析器阻止资源 。
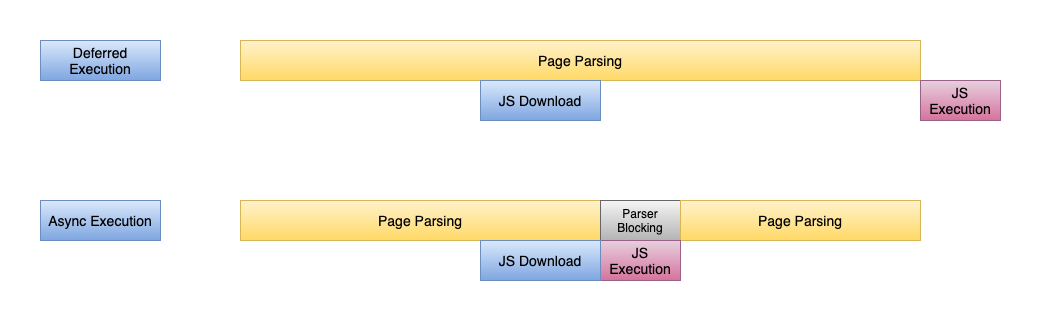
在脚本中延迟和异步 (Defer and Async in Script)
Both defer and async attributes help the developer to specify the asynchronous mode of Javascript Execution.
defer和async属性都可以帮助开发人员指定Javascript执行的异步模式。
投机解析 (Speculative Parsing)
As we have seen whenever a script is encountered, parsing is paused. This will introduce a delay in discovering the rest of the resources. In 2008, Microsoft introduced the concept of preloading named “lookahead downloader” followed by Firefox, Chrome, and Safari the same technique under different names. Chrome and Safari have “the preload scanner” and Firefox — the speculative parser.
如我们所见,每当遇到脚本时,分析就会暂停。 这将导致发现其余资源的延迟。 在2008年,Microsoft引入了预加载的概念,称为“ 先行下载器 ”,随后Firefox,Chrome和Safari以不同的名称使用了相同的技术。 Chrome和Safari具有“ 预加载扫描器 ”和Firefox( 投机解析器) 。
The basic idea is discovered files are added to a list and start downloading in the background on parallel connections. The files may be available by the time script finishes execution. Here the next lightweight parser scans the rest of the markup looking for other required resources. In the case of other Browsers except for Firefox the contents are preloaded but Firefox (version 4 onwards )goes a step ahead to create a DOM tree speculatively. If speculation succeeds, there is no need to re-parse part of the file constitution DOM. The downside is that if speculation fails, there is more work lost.
基本思想是将发现的文件添加到列表中,并在并行连接的后台开始下载。 脚本完成执行时,这些文件可能可用。 在这里,下一个轻量级解析器将扫描其余的标记,以查找其他所需资源。 对于除Firefox以外的其他浏览器,其内容已预加载,但Firefox(第4版及更高版本)向前迈进了一步,以推测方式创建DOM树 。 如果推测成功,则无需重新解析文件组成DOM的一部分。 不利的一面是,如果投机失败,将会失去更多工作。
为什么同一网站在浏览器中看起来有所不同? (Why does the same website looks different across Browsers?)
Many factors come into play for the discrepancy of the same web pages across different Browsers. As different browsers have different Browser engines (Render Engine and Javascript Engine collectively) that interpret source code (HTML and CSS) in slightly different ways causing this inconsistency. Similarly, the styling of web pages often guided by default settings can lead to the discrepancy as the default settings are different across Browsers.
相同网页在不同浏览器中的差异有许多因素起作用。 由于不同的浏览器具有不同的浏览器引擎 (统称为渲染引擎和Javascript引擎),它们以略有不同的方式解释源代码(HTML和CSS),从而导致这种不一致 。 同样,由于默认设置在不同浏览器中的不同,通常以默认设置为指导的网页样式也会导致差异。
Other reasons for the disparity include computer settings (screen resolution, color balancing, OS-level differences, fonts), bugs in the engine, and bugs in the web page.
造成差异的其他原因包括计算机设置(屏幕分辨率,颜色平衡,操作系统级别的差异,字体),引擎中的错误以及网页中的错误。
浏览器比较 (Comparison of Browsers)
There are many different web browsers in the market today. Although the primary application of the browser is the same, they differ from each other in more than one aspect. The distinguishing areas are platform(Linux, Windows, Mac, BSD, and other Unix), protocols, graphical user interface (Real, Headless), HTML5, open-source, and proprietary, explained in detail here.
当今市场上有许多不同的Web浏览器。 尽管浏览器的主要应用程序是相同的,但它们在一个以上的方面彼此不同。 区别区域包括平台(Linux,Windows,Mac,BSD和其他Unix),协议,图形用户界面(Real, Headless ),HTML5,开源和专有,在此进行详细说明。
浏览愉快!!! (Happy Browsing!!!)
翻译自: https://medium.com/dev-genius/how-do-web-browsers-work-1245d5b06c51
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/389160.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

让自己的头脑极度开放

简介DOTNET 编译原理 简介DOTNET 编译原理 简介DOTNET 编译原理

RecyclerView详细了解

案例与案例之间的非常规排版

熊猫分发_熊猫新手:第二部分

浅析微信支付:申请退款、退款回调接口、查询退款
)
view工作原理-计算视图大小的过程(onMeasure)
![[转载]使用.net 2003中的ngen.exe编译.net程序](http://pic.xiahunao.cn/[转载]使用.net 2003中的ngen.exe编译.net程序)
[转载]使用.net 2003中的ngen.exe编译.net程序

基于Redis实现分布式锁实战

数据分析 绩效_如何在绩效改善中使用数据分析



您一直在寻找5+个简单的一线工具来提升Python可视化效果

用C#编写的代码经C#编译器后,并非生成本地代码而是生成托管代码

figma 安装插件_彩色滤光片Figma插件,用于色盲


产品观念:更好的捕鼠器_故事很重要:为什么您需要成为更好的讲故事的人

7月15号day7总结

