文章目录
- 一 json数据格式
- 1.1 json数据格式认识
- 1.2 Python数据和Json数据的相互转换
- 二 pyecharts模块
- 2.1 pyecharts概述
- 2.2 pyecharts模块安装
- 三 pyecharts快速入门
- 3.1 基础折线图
- 3.2 pyecharts配置选项
- 3.2.1 全局配置选项
- 3.4 折线图相关配置
- 3.4.1 `.add_yaxis`相关配置选项
- 3.4.2 `.set_global_opts`全局配置选项
- 五 综合案例:对比折线图
- 5.1 数据处理
- 5.2 完整代码
一 json数据格式
1.1 json数据格式认识
-
JSON是一种轻量级的数据交互格式。可以按照JSON指定的格式去组织和封装数据
-
JSON本质上是一个带有特定格式的字符串
-
主要功能:json就是一种在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互. 类似于:国际通用语言-英语、中国56个民族不同地区的通用语言-普通话
-
各种编程语言存储数据的容器不尽相同,在Python中有字典dict这样的数据类型, 而其它语言可能没有对应的字典。
-
为了让不同的语言都能够相互通用的互相传递数据,JSON就是一种非常良好的中转数据格式。如下图,以Python和C语言互传数据为例:
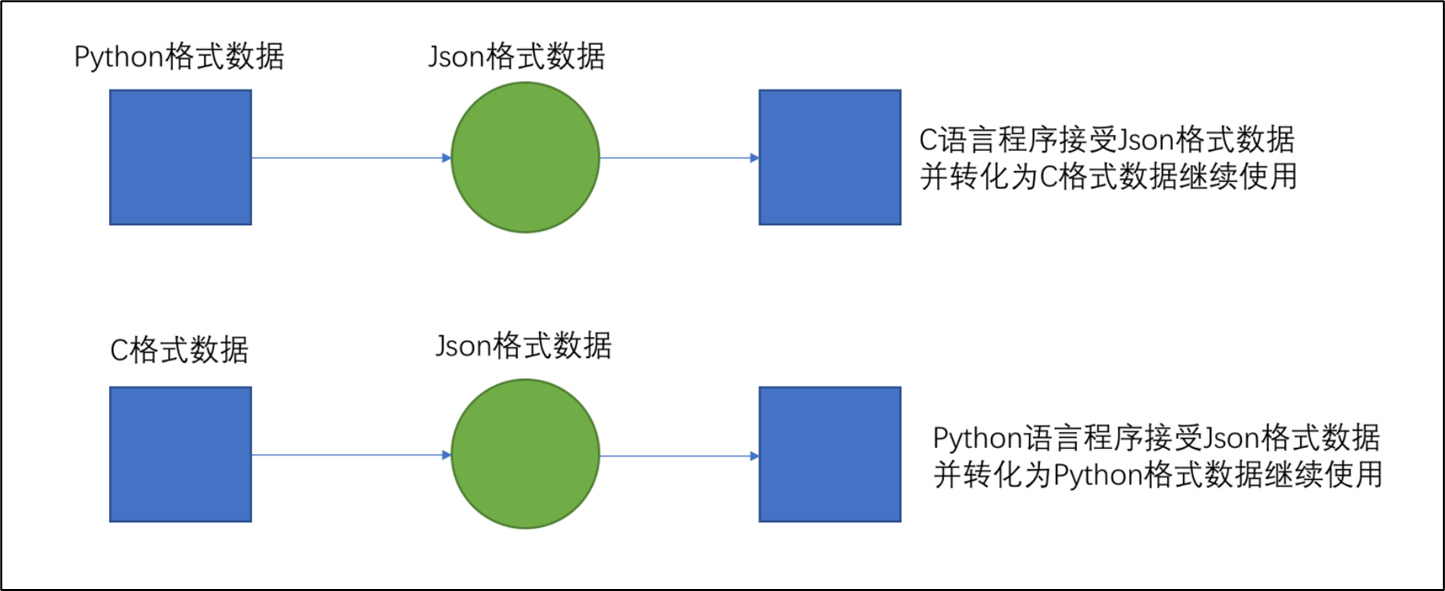
-
简单的JSON数据示例:
{"name": "John","age": 30,"city": "New York" } -
JSON还支持嵌套结构,数组和对象的组合:
{"person": {"name": "Alice","age": 25},"friends": ["Bob","Charlie","David"] }
1.2 Python数据和Json数据的相互转换
- 使用内置的
json模块来进行Python数据和JSON数据之间的相互转换。这个模块提供了方法来将Python数据结构转换为JSON格式,以及将JSON格式转换为Python数据结构。
基本的示例:
- 将Python数据转换为JSON:
import json# Python字典
python_data = {"name": "John","age": 30,"city": "New York"
}# 将Python字典转换为JSON字符串
json_data = json.dumps(python_data)
print(json_data)
import json
# 准备列表,列表内每一个元素都是字典,将其转换为JSON
data = [{"name": "张大山", "age": 11}, {"name": "王大锤", "age": 13}, {"name": "赵小虎", "age": 16}]
json_str = json.dumps(data, ensure_ascii=False)
print(type(json_str))
print(json_str)
# 准备字典,将字典转换为JSON
d = {"name":"周杰轮", "addr":"台北"}
json_str = json.dumps(d, ensure_ascii=False)
print(type(json_str))
print(json_str)
- 通过设置ensure_ascii参数为False,你可以确保在生成JSON字符串时不会将非ASCII字符转义为Unicode转义序列。这对于处理包含非英文字符的数据非常有用,因为它能够保持原始的字符表示,而不是进行转义。
- 将JSON转换为Python数据:
# JSON字符串
json_data = '{"name": "Alice", "age": 25, "city": "London"}'# 将JSON字符串转换为Python字典
python_data = json.loads(json_data)
print(python_data)
# 将JSON字符串转换为Python数据类型[{k: v, k: v}, {k: v, k: v}]
s = '[{"name": "张大山", "age": 11}, {"name": "王大锤", "age": 13}, {"name": "赵小虎", "age": 16}]'
l = json.loads(s)
print(type(l))
print(l)
# 将JSON字符串转换为Python数据类型{k: v, k: v}
s = '{"name": "周杰轮", "addr": "台北"}'
d = json.loads(s)
print(type(d))
print(d)
注意:
- 使用
json.dumps()函数可以将Python数据结构转换为JSON字符串。 - 使用
json.loads()函数可以将JSON字符串转换为Python数据结构。 - JSON中的键必须是字符串,因此在Python字典中,键应为字符串。
二 pyecharts模块
2.1 pyecharts概述
Pyecharts是一个基于 Python 的用于生成交互式图表的模块。它是对 ECharts 图表库的封装,ECharts 是百度开发的一款功能强大的数据可视化库。- 通过
Pyecharts,可以在 Python 中轻松地生成各种类型的图表,如折线图、柱状图、饼图、地图等,并且这些图表支持交互和动态效果。
Pyecharts 具有以下特点:
- 提供了多种图表类型,适用于不同的数据展示需求。
- 支持生成静态图像和动态网页交互图表。
- 可以通过链式调用的方式配置图表样式、数据和交互行为。
- 可以与常见的 Python 数据库和数据处理库(如 Pandas)集成。
2.2 pyecharts模块安装
- 方式一:打开终端,使用命令行安装
pip install pyecharts
- 方式二:使用PyCharm进行安装

- 配置镜像网站,参看探索Python异常世界:玩转异常、模块与包 6.5 PyCharm配置镜像网站
三 pyecharts快速入门
3.1 基础折线图
"""
演示pyecharts的基础入门
"""
# 导包
from pyecharts.charts import Line
# 创建一个折线图对象
line = Line()
# 给折线图对象添加x轴的数据
line.add_xaxis(["中国", "美国", "英国"])
# 给折线图对象添加y轴的数据
line.add_yaxis("GDP", [30, 20, 10])# 通过render方法,将代码生成为图像
line.render()
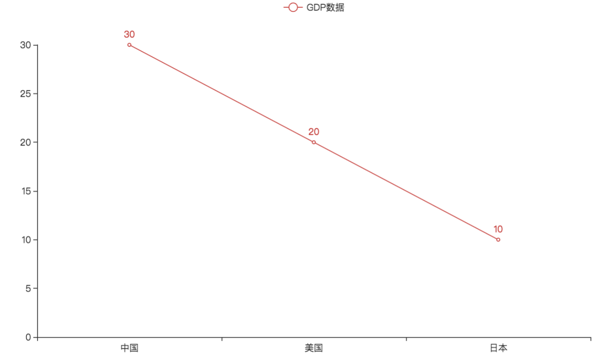
3.2 pyecharts配置选项
- pyecharts模块中有很多的配置选项, 常用到2个类别的选项:
- 全局配置选项
- 系列配置选项
3.2.1 全局配置选项
- Pyecharts 提供了一些全局配置选项,可以用来在整个图表中设置一些通用的属性,比如图表标题、图例、工具箱等。这些选项会应用于整个图表,而不仅仅是某个特定系列或组件。
- 全局配置选项可以通过
set_global_opts方法来进行配置
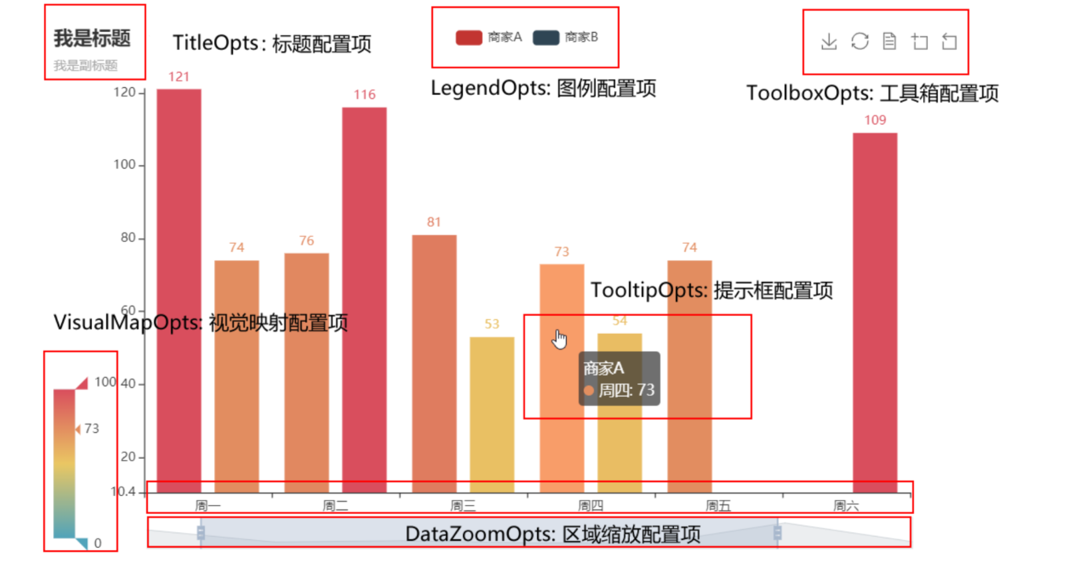
- 以下是一些常用的全局配置选项及其说明:
- 标题设置:
title_opts=opts.TitleOpts(title="图表标题", subtitle="副标题")
- 图例设置:
legend_opts=opts.LegendOpts(type_="scroll", pos_left="center", orient="horizontal")
- 工具箱设置:
toolbox_opts=opts.ToolboxOpts(is_show=True, feature=opts.ToolBoxFeatureOpts(save_as_image=True))
- 数据标签设置:
label_opts=opts.LabelOpts(is_show=True, position="top")
- 全局系列样式设置:
itemstyle_opts=opts.ItemStyleOpts(color="blue", border_color="red")
- 动画效果设置:
animation_opts=opts.AnimationOpts(animation_delay=1000, animation_easing="elasticOut")
- 提示框设置
tooltip_opts=opts.TooltipOpts(formatter="{a}: {c}",
)
# formatter 参数可以设置提示框内容的显示格式。{a} 表示数据系列的名称,{c} 表示数据值。
这些全局配置选项通常可以通过 set_global_opts() 方法来应用于整个图表。
以下是一个示例,展示如何在折线图中使用全局配置选项:
# 导包
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts
# 创建一个折线图对象
line = Line()
# 给折线图对象添加x轴的数据
line.add_xaxis(["中国", "美国", "英国"])
# 给折线图对象添加y轴的数据
line.add_yaxis("GDP", [30, 20, 10])# 设置全局配置项set_global_opts来设置,
line.set_global_opts(title_opts=TitleOpts(title="GDP展示", pos_left="center", pos_bottom="1%"),legend_opts=LegendOpts(is_show=True),toolbox_opts=ToolboxOpts(is_show=True),visualmap_opts=VisualMapOpts(is_show=True),
)# 通过render方法,将代码生成为图像
line.render()

3.4 折线图相关配置
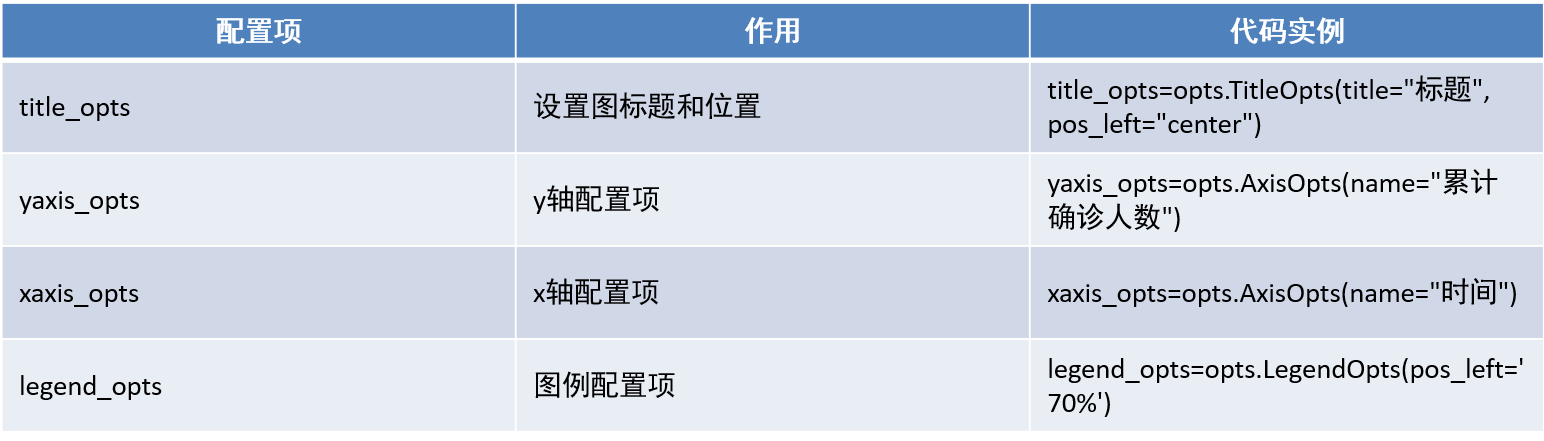
| 配置项 | 作用 | 代码实例 |
|---|---|---|
| init_opts | 对折线图初始化设置宽高 | init_opts=opts.InitOpts(width=“1600px”, height=“800px”) |
| .add_xaxis | 添加x轴数据 | .add_xaxis(列表) |
| .add_yaxis | 添加y轴数据 |
当使用 add_yaxis 方法来向图表中添加数据系列时,你可以使用一些相关的配置选项来自定义该数据系列的样式、标记点、标签等。以下是一些常用的 add_yaxis 相关配置选项:
3.4.1 .add_yaxis相关配置选项
| 配置选项 | 说明 |
|---|---|
is_smooth | 是否使用平滑曲线插值,默认为 False。 |
is_symbol_show | 是否显示标记点,默认为 True。 |
symbol | 标记点的图形,如 “circle”、“rect”、“triangle” 等。 |
symbol_size | 标记点的大小。 |
label_opts | 数据标签的配置选项,可以设置是否显示、位置、颜色等。 |
areastyle_opts | 面积图样式的配置选项,用于区域图,设置填充色、透明度等。 |
linestyle_opts | 线条样式的配置选项,设置线的颜色、宽度、透明度等。 |
itemstyle_opts | 数据项的样式配置选项,包括颜色、边框颜色、透明度等。 |
markpoint_opts | 标记点的配置选项,可以添加最大值、最小值等标记点。 |
markline_opts | 标记线的配置选项,可以添加平均值、趋势线等标记线。 |
tooltip_opts | 提示框的配置选项,用于显示数据信息,包括格式、触发方式等。 |
step | 设置折线图的样式,可选值为 “start”、“middle”、“end”。 |
area_opacity | 面积图的透明度,适用于区域图。值范围为 [0, 1]。 |
label | 用于设置数据项的名称,会在图例和提示框中显示。 |
data | 数据列表,表示 y 轴数据。 |
series_name | 设置图例名称,series_name=“美国确诊人数” |
3.4.2 .set_global_opts全局配置选项
五 综合案例:对比折线图
5.1 数据处理
- 原始数据格式:(使用json工具查看)

- 对数据进行整理, 让数据符合json格式
import json
from pyecharts.charts import Line# 处理数据
f_us = open("C:/美国.txt", "r", encoding="UTF-8")
us_data = f_us.read() # 美国的全部内容f_jp = open("C:/日本.txt", "r", encoding="UTF-8")
jp_data = f_jp.read() # 日本的全部内容f_in = open("C:/印度.txt", "r", encoding="UTF-8")
in_data = f_in.read() # 印度的全部内容# 去掉不合JSON规范的开头
us_data = us_data.replace("jsonp_1629344292311_69436(", "")
jp_data = jp_data.replace("jsonp_1629350871167_29498(", "")
in_data = in_data.replace("jsonp_1629350745930_63180(", "")# 去掉不合JSON规范的结尾
us_data = us_data[:-2]
jp_data = jp_data[:-2]
in_data = in_data[:-2]# JSON转Python字典
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)# 获取trend key
us_trend_data = us_dict['data'][0]['trend']
jp_trend_data = jp_dict['data'][0]['trend']
in_trend_data = in_dict['data'][0]['trend']# 获取日期数据,用于x轴,取2020年(到314下标结束)
us_x_data = us_trend_data['updateDate'][:314]
jp_x_data = jp_trend_data['updateDate'][:314]
in_x_data = in_trend_data['updateDate'][:314]# 获取确认数据,用于y轴,取2020年(到314下标结束)
us_y_data = us_trend_data['list'][0]['data'][:314]
jp_y_data = jp_trend_data['list'][0]['data'][:314]
in_y_data = in_trend_data['list'][0]['data'][:314]
5.2 完整代码
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LabelOpts, LegendOpts, AxisOpts# 处理数据
f_us = open("C:/美国.txt", "r", encoding="UTF-8")
us_data = f_us.read() # 美国的全部内容f_jp = open("C:/日本.txt", "r", encoding="UTF-8")
jp_data = f_jp.read() # 日本的全部内容f_in = open("C:/印度.txt", "r", encoding="UTF-8")
in_data = f_in.read() # 印度的全部内容# 去掉不合JSON规范的开头
us_data = us_data.replace("jsonp_1629344292311_69436(", "")
jp_data = jp_data.replace("jsonp_1629350871167_29498(", "")
in_data = in_data.replace("jsonp_1629350745930_63180(", "")# 去掉不合JSON规范的结尾
us_data = us_data[:-2]
jp_data = jp_data[:-2]
in_data = in_data[:-2]# JSON转Python字典
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)# 获取trend key
us_trend_data = us_dict['data'][0]['trend']
jp_trend_data = jp_dict['data'][0]['trend']
in_trend_data = in_dict['data'][0]['trend']# 获取日期数据,用于x轴,取2020年(到314下标结束)
us_x_data = us_trend_data['updateDate'][:314]
jp_x_data = jp_trend_data['updateDate'][:314]
in_x_data = in_trend_data['updateDate'][:314]# 获取确认数据,用于y轴,取2020年(到314下标结束)
us_y_data = us_trend_data['list'][0]['data'][:314]
jp_y_data = jp_trend_data['list'][0]['data'][:314]
in_y_data = in_trend_data['list'][0]['data'][:314]
# 生成图表
line = Line() # 构建折线图对象
# 添加x轴数据
line.add_xaxis(us_x_data) # x轴是公用的,所以使用一个国家的数据即可
# 添加y轴数据
line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False)) # 添加美国的y轴数据
line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False)) # 添加日本的y轴数据
line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False)) # 添加印度的y轴数据# 设置全局选项
line.set_global_opts(# 标题设置title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图", pos_left="center", pos_bottom="1%"),# x轴配置项xaxis_opts=AxisOpts(name="时间"), # 轴标题# y轴配置项yaxis_opts=AxisOpts(name="累计确诊人数"), # 轴标题# 图例配置项legend_opts=LegendOpts(pos_left='70%'), # 图例的位置
)# 调用render方法,生成图表
line.render()
# 关闭文件对象
f_us.close()
f_jp.close()
f_in.close()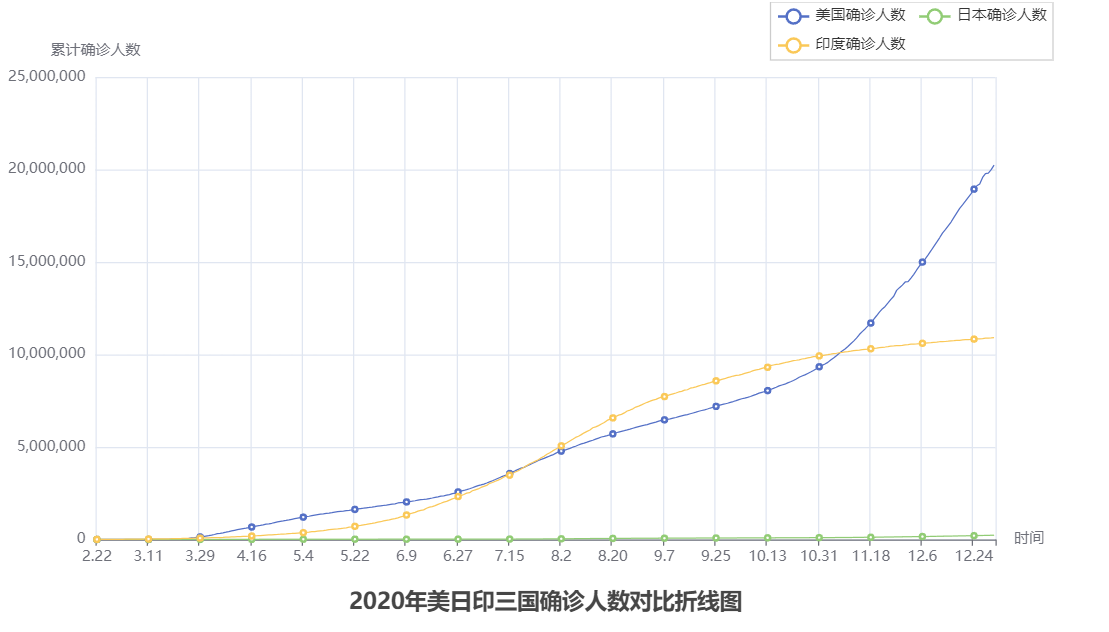

:项目实战|信用卡识别|模板匹配|(附代码解读))

)


![自然语言处理从入门到应用——LangChain:记忆(Memory)-[记忆的类型Ⅰ]](http://pic.xiahunao.cn/自然语言处理从入门到应用——LangChain:记忆(Memory)-[记忆的类型Ⅰ])

)






)



