1. 制造业与供应链数字化转型的必然性
1.1. 核心概念与战略重要性
制造业的数字化转型,是利用新一代数字技术(如工业互联网、人工智能、大数据、云计算、边缘计算等)对制造业的整体价值链进行根本性重塑的过程。这不仅涉及技术的应用,更涵盖了发展理念、组织架构、经营方式乃至盈利模式的全方位变革。其本质目标在于通过要素的优化配置,提升经济增长的质量和数量,是推进新型工业化、建设现代化产业体系的关键举措。
在数字经济时代,市场竞争日益激烈,数字化转型已成为制造商提升竞争力、实现可持续发展的必由之路。转型的驱动力源于多方面:一是应对多样化、个性化的市场需求; 二是提升运营效率,降低成本(如库存、生产及分销费用); 三是优化整体流程质量,消除错误成本和异常事件; 四是加速产品创新和新产品开发; 五是充分挖掘数据价值,提升生产过程的智能控制水平。
表1:制造业数字化转型五大驱动力
| 序号 | 驱动因素 | 具体表现 | 预期收益 |
|---|---|---|---|
| 1 | 市场需求变化 | 多样化、个性化需求增加 | 提高客户满意度,增加市场份额 |
| 2 | 运营效率提升 | 降低库存、生产及分销费用 | 成本节约,资源优化配置 |
| 3 | 流程质量优化 | 减少错误成本和异常事件 | 提高产品质量,降低返工率 |
| 4 | 产品创新加速 | 缩短新产品开发周期 | 增加创新产品比例,提高利润率 |
| 5 | 数据价值挖掘 | 提升生产过程智能控制 | 实现预测性维护,降低设备故障率 |
制造业数字化转型并非一蹴而就,而是呈现阶段性演进的特征。它通常从点状应用(单一职能优化)开始,发展到线状和面状集成(单一业务、单一组织或企业的运营效率提升、集成化、规范化),最终迈向生态圈层面的协同化、共享化发展。具体而言,企业可能经历数据集成、信息可视、精益分析、高阶分析(如AI驱动的预测与决策)和全面转型等关键阶段。最终目标是构建基于5G、工业互联网等新技术的供应链协同制造体系,提升产业整体的整合水平。这种从"点"到"圈"的演进过程表明,孤立的技术应用价值有限,真正的转型红利来自于系统性的变革和跨企业的协同,这为后续探讨"链主"企业的角色奠定了基础。
图1:制造业数字化转型演进路径
1.2. "链主"企业的关键作用 (链主企业)
在现代供应链体系中,“链主"企业(或称核心企业)扮演着至关重要的角色。这些企业通常在资源、市场和技术方面拥有显著优势。其核心能力体现为"供应链领导力”,即通过影响供应链上游供应商和下游客户的行为与绩效,以实现共同供应链目标的能力。这种领导力整合了经典的领导力理论和供应链管理实践,是提升供应链整体竞争力的重要保障。
表2:链主企业的五大核心功能
| 功能类别 | 具体表现 | 影响范围 | 实现机制 |
|---|---|---|---|
| 目标引领与协同促进 | 设定共同目标,引导伙伴行为 | 整个供应链网络 | 战略合作协议、绩效考核体系 |
| 生态系统构建与协调 | 整合采购、研发、生产、销售环节 | 上下游企业 | 平台建设、标准制定、资源共享 |
| 治理与风险控制 | 建立治理机制,协调利益冲突 | 整个供应链体系 | 供应链金融、合同管理、风险共担 |
| 创新驱动与能力提升 | 推动技术升级和创新 | 关键合作伙伴 | 联合研发、技术赋能、人才培养 |
| 提升供应链整体绩效 | 实施战略性供应链管理 | 供应链全流程 | KPI体系、共同改进计划、价值共创 |
"链主"企业的功能和重要性体现在多个层面:
- 目标引领与协同促进: 链主企业设定共同目标,并引导、影响合作伙伴的行为,以达成这些目标,促进成员间形成良好的协作关系。
- 生态系统构建与协调: 链主企业整合从采购、研发、生产到销售的各个环节,促进链上企业的协调发展,优化整个供应链的运作。
- 治理与风险控制: 通过建立治理机制(如利用供应链金融),协调各方利益冲突,维护链上企业的利益,确保供应链的稳定运行,降低在复杂全球环境下的风险与混乱。缺乏领导核心的供应链将面临更大的风险。
- 创新驱动与能力提升: 链主企业不仅自身进行数字化转型,还通过其影响力推动链上伙伴进行技术升级和创新。这对于国家实现从"制造大国"向"制造强国"的转变至关重要。
- 提升供应链整体绩效: 链主企业的领导力是实施战略性供应链管理的前提,有助于提升整个链条的绩效和竞争力。
图2:链主企业在供应链生态系统中的角色
链主企业通过供应链金融等手段进行治理,是其发挥影响力的一个具体体现。通过利用自身的信息和信用优势,链主企业可以帮助上下游伙伴(尤其是中小企业)获得信贷支持,缓解资金融通的冲突,减少信息不对称带来的效率损失,并将资金引导至关键的研发和技术创新活动中。这不仅是一种运营层面的影响,更是一种利用金融杠杆推动整个生态系统转型的战略手段。理解链主企业的核心作用,对于后续分析曼娜内衣案例以及"双边溢出效应"的实现机制至关重要。
2. 技术深潜:工业互联网预测性维护 (PDM)
2.1. PDM 成熟度演进:从监测到预测,再到决策优化
预测性维护(Predictive Maintenance, PDM)并非孤立的技术,而是企业维护策略成熟度演进过程中的一个重要阶段。理解这一演进路径对于成功实施PDM至关重要。该模型最早由Winston Ledet于1999年提出,旨在勾勒资产在其生命周期中处理和维护方式的成熟度级别。
维护成熟度演进路径
维护成熟度模型通常包含以下几个关键阶段:
- 第一级:反应式维护 (Reactive Maintenance):这是最基础的阶段,只有在设备发生故障后才进行维修,即"坏了再修" (run-to-failure)。这种方式虽然在过去很常见,但会导致不可预测的停机时间和高昂的维修成本。
- 第二级:预防性维护 (Preventive Maintenance):基于预定的时间间隔或使用周期进行计划性维护,在潜在故障发生前进行干预。这种方式旨在主动解决潜在问题,减少意外停机。然而,它可能导致过度维护(在设备状况良好时进行维护)或维护不足(计划间隔长于实际故障周期),从而产生不必要的停机时间和成本。
- 第三级:基于状态的维护 (Condition-Based Maintenance, CBM):通过实时监测设备的关键参数(如温度、振动),当参数超过预设阈值时触发维护报警。CBM利用实时数据做出更明智的维护决策,比预防性维护更具针对性。但其局限性在于通常只关注单一故障点或模式,缺乏对设备整体健康状况的全面评估和未来趋势的预测。
- 第四级:预测性维护 (Predictive Maintenance, PDM):这是向智能化维护迈进的关键一步。PDM利用历史数据和实时监测数据,结合统计模型、机器学习(ML)和人工智能(AI)算法,来预测设备未来可能发生故障的时间和类型。它不仅关注当前状态,更着眼于未来趋势,旨在通过分析评估来预测维护需求,然后进行计划、排程和协调。PDM的目标是优化维护时机,最大限度地减少停机时间,延长设备寿命,并降低维护成本,最终提升整体设备效率(OEE)。
- 第五级:规范性/指令性维护 (Prescriptive Maintenance):这是维护成熟度的最高级别,被认为是维护成熟度模型的最终目标。它不仅预测故障,更能提供具体的、可操作的维护建议(例如,应采取何种修复措施、何时执行、需要哪些资源),甚至能够建议调整操作参数以规避潜在的故障模式。规范性维护旨在消除缺陷、提高精度、优化设计,并实现资产性能和运营流程的全面优化。它高度依赖先进的AI/ML算法和数字化技术,使设备能够主动参与自身的维护需求协调。
表1:预测性维护成熟度模型比较
| 级别 | 名称 | 描述 | 关键技术/方法 | 主要目标 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
| 1 | 反应式 (Reactive) | 故障发生后维修 | 手动检查、基本维修工具 | 恢复功能 | 简单直接 | 不可预测的停机、高维修成本、潜在安全风险 |
| 2 | 预防性 (Preventive) | 按计划定期维护 | 时间/使用量计数器、维护计划 | 预防故障 | 减少意外停机、延长寿命 | 可能过度/不足维护、不必要的停机和成本 |
| 3 | 基于状态 (CBM) | 基于实时状态监测和阈值触发维护 | 传感器、状态监测系统 (CMMS) | 基于状态决策 | 仅在需要时维护、提高效率 | 关注单一故障点、缺乏预测性、仍可能发生意外故障 |
| 4 | 预测性 (PDM) | 利用数据和算法预测未来故障 | IIoT、传感器、大数据分析、AI/ML | 优化维护时机、最大化正常运行时间 | 显著减少停机、降低成本、延长寿命 | 需要数据基础、技术投入和分析能力 |
| 5 | 规范性 (Prescriptive) | 预测故障并提供具体行动建议和优化方案 | 高级AI/ML (含强化学习)、数字孪生 | 优化性能、消除缺陷 | 主动优化、最高效率、企业级协同 | 技术复杂性高、成本高、数据和模型要求极高 |
数据来源: 综合
这一成熟度模型的演进路径,不仅仅是技术的迭代升级,更深层次地反映了企业维护理念和组织能力的变革。从被动响应到主动预防,再到基于状态的干预,直至最终实现基于数据洞察的预测和优化决策,每一步都要求企业在数据采集、数据管理、分析能力、流程整合以及人员技能方面进行相应的投入和提升。因此,向更高级别的维护策略迈进,本身就是一项系统性的组织转型工程,需要战略层面的规划和持续投入。
2.2. 核心使能技术:IIoT、传感器与数据采集
预测性维护的实现离不开一系列关键技术的支撑,其中,工业物联网(IIoT)、传感器和高效的数据采集传输系统构成了其技术基石。
PDM技术架构图
- 工业物联网 (IIoT) 作为骨干: IIoT是将物理世界的工业设备(如机器、传感器)与数字世界连接起来的网络和平台体系。它为PDM提供了基础架构,实现了数据的互联互通和共享。一个有效的基于IIoT的PDM系统,需要整合数据采集、设备管理、跨系统(OT/IT/ET)实时集成、数据管理、网络安全、AI分析、数字孪生以及应用支持等多方面能力。IIoT平台是实现整体资产绩效管理、资产策略和投资规划的支柱。
传感器类型及应用
| 传感器类型 | 监测参数 | 适用设备 | 主要应用场景 |
|---|---|---|---|
| 振动传感器 | 振动幅度、频率、相位 | 旋转机械、电机、涡轮机 | 检测不平衡、不对中、松动 |
| 温度传感器 | 温度 | 各类设备关键部位 | 监测过热、冷却系统故障 |
| 压力传感器 | 流体/气体压力 | 管道、压力容器、液压系统 | 检测泄漏、压力异常 |
| 声学/超声波传感器 | 声波、超声波 | 密封系统、轴承、电气系统 | 检测泄漏、轴承磨损、电弧放电 |
| 油液分析传感器 | 油液成分、污染物 | 润滑系统、变压器 | 监测油质变化、设备磨损状态 |
| 电流/电压传感器 | 电流、电压、功率 | 电气设备、电机 | 检测电气故障、负载异常 |
- 数据采集与传输 (Data Acquisition & Transmission): 传感器收集到的原始数据需要被高效、可靠地采集并传输到处理中心(边缘或云端)。
- 连接协议与网络: 需要标准化的通信协议(如MQTT, OPC UA)和可靠的网络连接(如有线网络,或无线网络如eLTE、NB-IoT)来传输数据。MQTT因其轻量级、发布/订阅模式等特性,在IIoT领域应用广泛。
- IIoT平台/数据管理系统: 这些平台负责管理连接的设备、收集数据、进行初步处理、提供可视化界面(如仪表盘)和历史数据分析工具,并将数据输送给AI分析引擎。例如,华为的智能制造解决方案提供了设备接入、连接管理、数据分析和能力开放等功能。
- 时间序列数据的重要性: PDM的核心在于分析设备状态随时间的变化趋势。因此,连续不断的时间序列数据(如温度、振动随时间的变化)是识别异常模式、预测未来故障的基础。
数据就绪度评估表
| 评估维度 | 关键指标 | 达标标准 | 常见问题 |
|---|---|---|---|
| 数据可用性 | 覆盖率、采集频率 | >95%关键参数覆盖 满足最小采样频率要求 | 传感器部署不足 数据采集中断 |
| 数据质量 | 准确度、完整性、一致性 | 传感器校准误差<5% 缺失值比例<1% | 传感器失准 数据丢失严重 |
| 数据接入 | 数据格式统一性 实时性 | 标准化数据格式 延迟<规定阈值 | 数据格式不兼容 传输延迟严重 |
| 数据存储 | 存储容量 访问性能 | 满足预估数据量需求 查询响应时间达标 | 存储容量不足 数据库性能瓶颈 |
| 数据整合 | 多源数据关联性 上下文信息 | 可实现跨系统数据关联 包含必要上下文信息 | 数据孤岛 缺乏关联ID |
因此,成功部署高级别的预测性维护(第四、五级),其关键瓶颈往往不在于AI算法的潜力本身,而在于前期基础工作的扎实程度——即确保拥有高质量、可访问、集成化的数据流,这些数据流来自于可靠的传感器和稳定的数据采集系统。企业在投入巨资购买复杂AI模型之前或之初,就应高度重视数据基础设施的建设和数据治理体系的完善。
2.3. AI/ML算法:驱动预测与决策的核心引擎
人工智能(AI)和机器学习(ML)算法是预测性维护(PDM)和规范性维护(RxM)系统的"大脑",它们负责处理从传感器和IIoT平台收集的海量数据,识别其中隐藏的复杂模式和细微异常,从而实现故障预测、剩余使用寿命(RUL)估计,并为规范性维护提供行动建议。AI/ML的应用使得维护策略超越了简单的基于状态的阈值报警,进入了智能预测和决策优化的新阶段。其核心优势在于能够从数据中持续学习并提升预测精度。
PDM中的AI/ML算法框架
主要的AI/ML算法类别及其在PDM/RxM中的应用包括:
- 监督学习 (Supervised Learning): 这类算法利用带有"标签"的历史数据进行训练,即输入数据(如传感器读数、运行参数)与已知的输出结果(如是否发生故障、故障类型、RUL值)相关联。
- 分类 (Classification):用于预测设备状态(如正常、警告、危险)或判断是否会在特定时间窗口内发生故障。常用算法包括逻辑回归 (Logistic Regression)、支持向量机 (Support Vector Machines, SVM)、决策树 (Decision Trees, DT)、随机森林 (Random Forests, RF)以及各种深度神经网络 (Deep Neural Networks, DNNs),如前馈神经网络 (FNN)、卷积神经网络 (CNN,尤其适用于处理图像类或振动信号频谱数据)、循环神经网络 (RNN) 及其变种长短期记忆网络 (LSTM,擅长处理时间序列数据)。这些算法是故障诊断 (Fault Diagnosis) 的核心。
- 回归 (Regression):用于预测连续值,最典型的应用是预测设备的剩余使用寿命 (RUL)。常用算法包括线性回归 (Linear Regression)、支持向量回归 (Support Vector Regression, SVR)、决策树/随机森林回归,以及基于回归任务的神经网络架构。
监督学习算法对比表
| 算法类型 | 优势 | 局限性 | PDM适用场景 |
|---|---|---|---|
| 逻辑回归 | 简单、易解释、计算效率高 | 只能处理线性关系、特征工程要求高 | 简单的故障分类、初筛 |
| 支持向量机(SVM) | 适用于小样本、高维数据 | 计算成本高、参数调优复杂 | 多类型故障分类 |
| 决策树/随机森林 | 可处理非线性关系、特征重要性评估 | 可能过拟合、森林解释性较差 | 设备状态分类、健康评估 |
| 神经网络(DNN) | 可学习复杂模式、自动特征提取 | 需大量数据、计算资源要求高 | 复杂设备故障预测 |
| CNN | 适合处理空间相关数据 | 需大量标记数据、调参复杂 | 图像型缺陷检测、振动分析 |
| RNN/LSTM | 适合时序数据处理 | 训练复杂、计算开销大 | 时间序列故障预测、RUL估计 |
- 无监督学习 (Unsupervised Learning): 这类算法在没有标签的数据上进行训练,旨在发现数据中隐藏的结构、模式或异常。在缺乏充足故障标签数据的情况下尤其有用。
- 聚类 (Clustering):将相似的数据点分组。可用于识别设备的不同运行工况或状态,或者发现与正常状态不同的数据簇。常用算法包括K-Means、层次聚类 (Hierarchical Clustering)、基于密度的噪声应用空间聚类 (DBSCAN)、高斯混合模型 (Gaussian Mixture Models, GMMs)以及主成分分析 (Principal Component Analysis, PCA)(常用于降维,也可辅助聚类)。
- 异常检测 (Anomaly Detection):识别与正常行为模式显著不同的数据点或序列。这对于发现早期、未知的或罕见的故障迹象至关重要。常用算法包括孤立森林 (Isolation Forest)、单类支持向量机 (One-Class SVM) 以及自编码器 (Autoencoders,一种神经网络,通过重构误差识别异常)。
无监督学习算法适用场景
| 算法类型 | 核心机制 | PDM应用场景 | 数据要求 |
|---|---|---|---|
| K-Means聚类 | 基于距离划分数据点 | 设备运行工况识别 | 数值型数据、簇形状规则 |
| DBSCAN | 基于密度识别数据簇 | 复杂工况模式识别 | 适合非规则形状的簇 |
| 主成分分析(PCA) | 降维、提取主要变异 | 故障特征提取、降噪 | 线性相关性数据 |
| 孤立森林 | 随机分割空间识别异常 | 快速异常检测筛查 | 适用于高维数据 |
| 自编码器 | 通过重构误差识别异常 | 复杂设备异常检测 | 需大量正常样本训练 |
| Seq2Seq模型 | 序列对序列学习 | 时序数据异常检测 | 时间序列数据 |
- 强化学习 (Reinforcement Learning, RL): 这类算法通过让"代理"(Agent)与环境交互,在试错过程中学习最优策略(一系列行动),以最大化累积奖励(如最大化设备正常运行时间、最小化维护成本)。RL特别适用于规范性维护(RxM)场景,因为它不仅能预测,还能学习并推荐最优的应对措施。例如,RL可以用来优化维护计划的制定、动态调整设备运行参数以延长寿命,或者在多种可选维护方案中做出最佳选择。常用算法包括Q-Learning、深度Q网络 (Deep Q-Networks, DQN)、策略梯度方法 (Policy Gradient Methods) 等。
AI/ML技术之所以能够超越传统的基于状态的监测(CBM),关键在于它们能够:
- 学习复杂的多变量模式: 能够识别多个传感器数据之间以及数据与历史故障之间的复杂、非线性关系,这是基于单一阈值的CBM难以做到的。
- 预测未来状态: 监督学习算法可以直接预测未来的故障概率或RUL,而不仅仅是报告当前状态异常。
- 发现未知异常: 无监督学习算法能够在没有先验知识的情况下,检测出偏离正常运行模式的早期、微弱信号。
- 提供优化建议: 强化学习等技术能够评估不同维护决策的长期影响,并推荐最优化的行动方案,实现规范性维护的目标。
通过应用这些先进的AI/ML技术,企业能够将维护策略从被动响应和固定周期的预防性维护,提升到更主动、更精准、更高效的预测性乃至规范性维护水平,从而实现显著的成本节约、设备可用性提升和资产可靠性增强。
3. 技术深潜:区块链赋能供应链诚信体系
3.1. 提升透明度、可追溯性与信任度
区块链技术通过其独特的分布式、加密和不可篡改的特性,为解决传统供应链中长期存在的透明度低、追溯困难和信任缺失等问题提供了革命性的解决方案。
区块链技术与传统中心化系统对比
| 特性 | 传统中心化系统 | 区块链技术 | 供应链价值体现 |
|---|---|---|---|
| 数据存储架构 | 中心化数据库 | 分布式账本 | 提高系统可靠性、避免单点故障 |
| 信息可信度 | 依赖中心化机构 | 密码学保证 | 降低对中间方的依赖、减少摩擦成本 |
| 数据记录特性 | 可修改、可删除 | 不可篡改、永久记录 | 提供可靠历史追溯、增强审计能力 |
| 系统安全机制 | 中心化安全防护 | 去中心化共识机制 | 分散风险、提高整体安全性 |
| 数据透明度 | 有限、不对等共享 | 高度透明、共享一致 | 打破信息孤岛、增强供应链协作 |
| 自动化程度 | 依赖人工处理 | 智能合约自动执行 | 提高流程效率、减少人为干预 |
- 核心机制: 区块链本质上是一个分布式的数字账本。供应链中的每一笔交易或状态变更(如产品出入库、质检认证、物流节点更新)都被记录为一个"区块",该区块通过加密算法(如哈希函数)与前一个区块链接起来,形成一个不可逆的"链条"。这个账本由网络中的多个参与者共同维护,而非由单一中心机构控制。
- 增强透明度 (Transparency): 区块链为所有获得授权的供应链参与者提供了一个共享的、统一的、实时更新的信息视图。每一次产品流转和状态更新都被记录在案,且对相关方可见7。这种高度透明性打破了传统供应链中各环节的信息孤岛,使得企业和最终消费者都能了解商品的来源、流转路径和质量信息,从而建立起基于事实的信任和问责机制。
- 强化可追溯性 (Traceability): 区块链的链式结构和时间戳特性使其能够精确地记录产品从原材料采购、生产加工、仓储物流到最终交付给消费者的完整生命周期轨迹。这种端到端的可追溯性对于验证产品真伪、高效管理产品召回、确保原材料的合规性与道德采购(如环境、社会和治理(ESG)方面的要求)以及打击假冒伪劣产品至关重要。
- 建立信任 (Trust) 与提升安全 (Security): 区块链的不可篡改性是其建立信任的核心基础。一旦数据被写入区块并添加到链上,就极难被单个节点恶意修改或删除,任何篡改企图都会被网络中的其他节点检测到。数据的加密存储和传输,以及基于共识机制的验证过程,确保了信息的完整性和安全性。这减少了对传统中间商或第三方验证机构的依赖,降低了交易对手方的信任成本,并有效防范了欺诈行为。根据应用场景和隐私需求,可以选择不同类型的区块链网络,如完全公开的公有链、需要授权访问的私有链或由多个组织共同管理的联盟链,以平衡透明度与数据访问控制。
- 提高效率与降低成本: 通过自动化流程(例如利用智能合约)和减少对纸质文件及人工核对的依赖,区块链可以简化供应链操作,加快交易速度,减少人为错误8。智能合约是嵌入在区块链上的自执行代码,当预设条件(如货物送达确认、质量检验合格)满足时,可以自动触发相应的动作(如支付货款、放行货物),从而提高流程效率。
区块链赋能供应链流程图
区块链在供应链中的价值,并非仅仅是技术的叠加,而是对传统基于信任中介、信息不对称的运作模式的根本性改变。它通过技术手段构建了一个可信的数据基础,为供应链各参与方提供了一个共享的、不可篡改的"单一事实来源",从而解决了长期困扰供应链管理的诸多痛点。
3.2. 跨行业应用实例分析
区块链技术在供应链领域的应用已经从概念验证走向实际部署,并在多个行业展现出显著成效。
- 食品行业: 主要解决食品安全和来源追溯问题。通过区块链记录食品从农场到餐桌的全过程,消费者扫描产品二维码即可获取其产地、加工、物流等信息,提升食品安全透明度和消费者信任。
- 沃尔玛 (Walmart): 作为早期采用者,沃尔玛利用基于Hyperledger Fabric的IBM Food Trust平台追踪猪肉(在中国市场)和生菜等产品的供应链。此举将问题产品的溯源时间从几天甚至几周缩短至几秒钟3,极大提高了食品安全事件的响应效率。
- 雀巢 (Nestlé): 在中国市场,为应对婴儿奶粉信任危机,雀巢利用区块链技术记录奶粉的生产和流通过程,消费者可通过手机扫描包装上的芯片查验产品信息,并结合防伪包装设计,重塑品牌信任。
- 家乐福 (Carrefour): 同样加入了IBM Food Trust网络,提升其产品的可追溯性。
- 星巴克 (Starbucks): 实施"从豆到杯"计划,利用区块链追踪咖啡豆从种植、采购、烘焙到最终销售的全过程。
- 医药行业: 核心应用在于打击假药、满足严格的监管要求(如美国的DSCSA法案)以及优化药品召回流程。区块链提供了药品流通环节中不可篡改的记录,确保药品来源的真实性和流通过程的合规性。
- MediLedger联盟: 由多家领先的制药公司和分销商组成,利用区块链技术进行药品序列化信息的验证和追踪,防止假药流入市场。沃尔玛也是该联盟成员。
- IBM Blockchain Transparent Supply: 被多家药企用于实时追踪药品,降低假药风险。
- SAP Pharma Blockchain: 提供端到端的供应链可见性和可追溯性解决方案。
- SkyCell: 结合物联网传感器和区块链技术,为温敏药品的冷链运输提供智能温控集装箱,确保运输过程中的温度和湿度得到有效监控和记录,保障药品质量。
- FDA DSCSA试点项目: 证明了区块链技术能够将药品召回通知时间从几天缩短至几秒钟,显著提升应急响应能力。
- 唯链 (VeChain): 提供企业级区块链解决方案,其智能合约可用于改善医药供应链的透明度、自动化合规流程和确保产品质量。
- 奢侈品与汽车行业: 主要用于验证产品真伪和追踪零部件来源。
- 奢侈品防伪: Aura联盟(由LVMH、普拉达、卡地亚等品牌组成)利用区块链为奢侈品(如手袋)提供数字真品证书,消费者可扫描验证。百年灵 (Breitling) 为其手表提供数字护照。戴比尔斯 (De Beers) 追踪钻石从矿山到零售的全过程。
- 汽车零部件追溯与可持续性: 汽车制造商利用区块链追踪零部件的来源和历史,加强质量控制和安全管理。特斯拉 (Tesla) 利用区块链确保其原材料(如电池金属)来源的可持续性5。宝马 (BMW) 的车辆数字护照结合了物联网和区块链,记录车辆的里程、维修、事故和保险等完整历史5。
- 物流与支付: 提升货物运输的实时可见性,简化跨境支付流程。
- 货运追踪: 区块链可提供防篡改的实时货运状态记录,减少货物丢失和延误8。
- 简化支付: 澳大利亚汽车制造商Tomcar使用比特币向部分国际供应商支付货款,利用其跨境、低费用的特点。智能合约也可用于在满足交付条件时自动触发支付。
区块链供应链应用案例图表
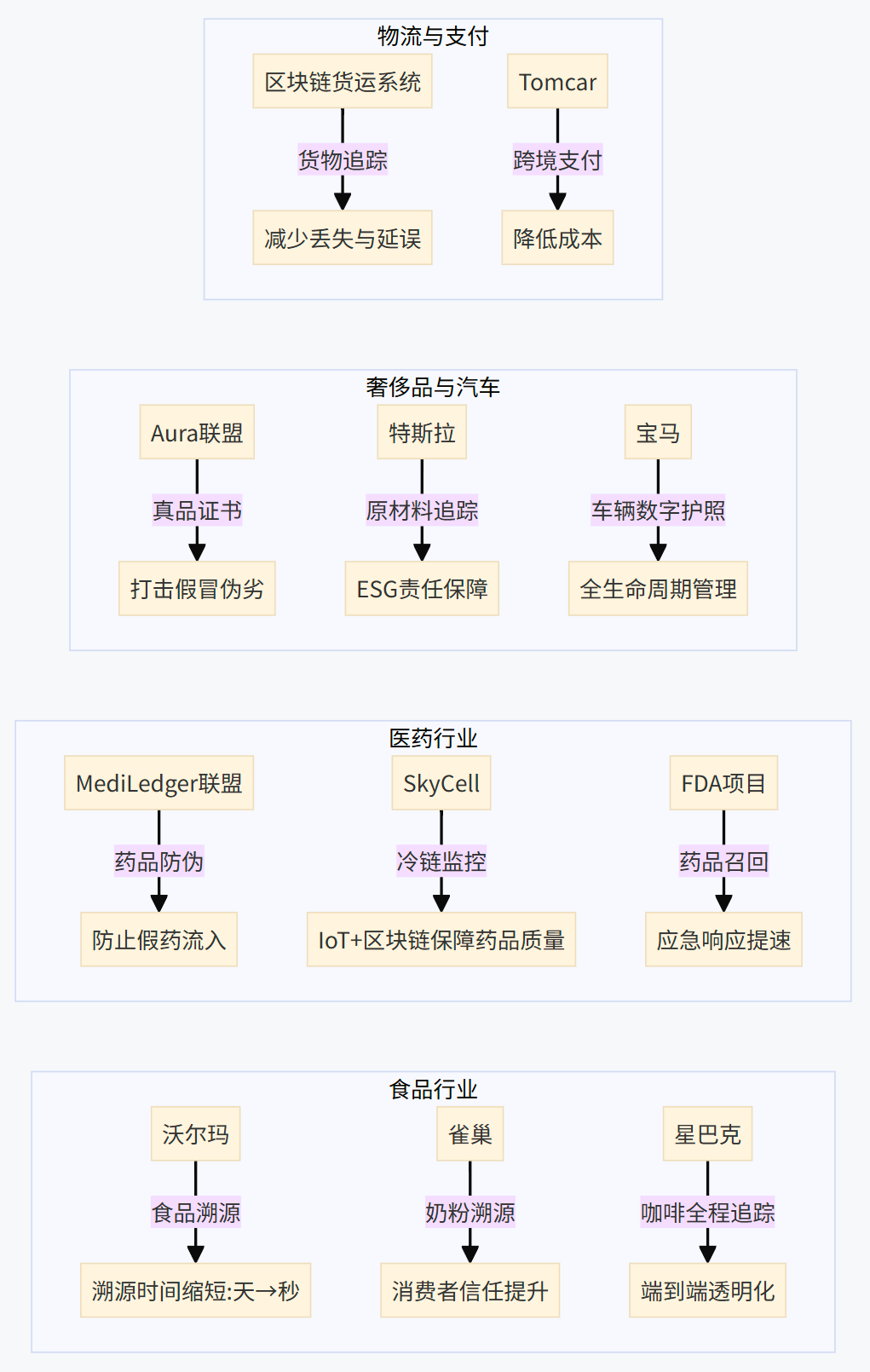
表2:区块链供应链应用案例
| 行业 | 具体应用场景 | 案例/计划 | 展示的关键效益 |
|---|---|---|---|
| 🍎 食品 | 产品溯源、食品安全 | 沃尔玛/IBM Food Trust | 溯源时间大幅缩短 (秒级 vs 天级) |
| 🍎 食品 | 重塑信任、消费者验证 | 雀巢 (婴儿奶粉) | 提升消费者信任度 提供透明的产品信息 |
| 🍎 食品 | 咖啡豆全程追踪 | 星巴克 “Bean-to-Cup” | 端到端供应链透明化 |
| 💊 医药 | 药品验证、防伪、合规 | MediLedger联盟 | 防止假药流入 加强产品验证 |
| 💊 医药 | 实时追踪、降低假药风险 | IBM Blockchain Transparent Supply | 提升供应链实时可见性 |
| 💊 医药 | 冷链物流监控 | SkyCell | 结合IoT确保温敏药品 运输质量 |
| 👜 奢侈品 | 产品真伪验证 | Aura联盟 (LVMH, Prada等) | 提供数字真品证书 打击假冒 |
| 🚗 汽车 | 零部件追溯、质量控制 | 汽车制造商 | 提升零部件供应链 透明度和安全性 |
| 🚗 汽车 | 原材料可持续性追踪 | 特斯拉 | 确保供应链符合ESG要求 |
| 🚗 汽车 | 车辆全生命周期记录 | 宝马车辆数字护照 | 结合IoT提供可信的 车辆历史数据 |
| 🚚 物流/支付 | 跨境支付效率 | Tomcar (比特币支付) | 降低交易费用 加快支付速度 |
数据来源: 综合7
区块链应用场景流程示例:食品供应链
这些案例清晰地表明,区块链在供应链管理中的应用并非空中楼阁,而是能够切实解决行业痛点、创造商业价值的实用技术。值得注意的是,许多成功的应用案例,如沃尔玛的食品追溯和医药行业的MediLedger联盟,都体现了行业领导者或联盟组织在推动标准制定和平台建设方面的重要作用。这再次印证了在供应链这样一个多方参与的复杂系统中,单靠技术本身往往不够,强大的组织协调能力和生态构建意愿是技术落地并发挥价值的关键前提。此外,区块链与物联网(如SkyCell案例)、人工智能等其他数字化技术的融合,正在进一步拓展其应用边界,创造出更为强大的协同效应。
4. 技术深潜:边缘计算与物联网 (IoT) 集成
4.1. 边缘计算在制造与物流中的作用
边缘计算是一种分布式计算范式,它将数据处理和存储能力尽可能地部署在靠近数据源(即产生或消费信息的"物"和"人"所在的位置)的网络边缘,而不是完全依赖于遥远的、集中的云计算中心。在工业物联网 (IIoT) 场景下,边缘计算通常涉及在工厂车间、仓库、运输工具等现场部署边缘网关、边缘服务器或其他具备计算能力的设备。
边缘计算在制造业和物流供应链中发挥着关键作用,主要得益于以下核心优势:
| 核心优势 | 描述 | 工业应用示例 |
|---|---|---|
| 降低延迟 (Reduced Latency) | 通过在数据源附近进行计算处理,显著减少数据往返云端所需时间,实现近乎实时的响应 | • 实时质量控制 • 预测性维护 • 机器人控制与自动化 • AR/VR应用支持 |
| 优化带宽利用 (Bandwidth Optimization) | 在本地进行数据预处理、过滤、聚合和分析,只将有价值的结果或异常数据上传至云端 | • 工业相机图像预处理 • 传感器数据降采样 • 异常数据优先传输 |
| 增强可靠性与韧性 (Enhanced Reliability/Resilience) | 使本地设备和系统能够在网络连接不稳定或中断时继续运行关键任务 | • 离线运行生产线 • 本地故障恢复 • 断网应急处理 |
| 提升数据安全与隐私保护 (Improved Security/Privacy) | 敏感数据在本地处理,减少传输中被截获或泄露的风险 | • 生产配方保护 • 个人信息处理 • 知识产权数据隔离 |
- 降低延迟 (Reduced Latency): 这是边缘计算最核心的价值之一。通过在数据源附近进行计算处理,可以显著减少数据往返云端所需的时间,实现近乎实时的响应7。这对于需要快速决策和控制的工业应用至关重要,例如:
- 实时质量控制: 在生产线上即时分析产品检测数据,发现偏差后立刻调整生产参数,避免批量次品产生。
- 预测性维护: 在本地快速处理传感器数据,及时发现设备异常并发出预警。
- 机器人控制与自动化: 保证工业机器人、自动导引车 (AGV) 等设备的快速响应和协同作业。
- 增强现实/虚拟现实 (AR/VR) 应用: 为现场技术人员提供低延迟的AR操作指导或VR培训,提升工作效率和准确性。
- 优化带宽利用 (Bandwidth Optimization): 工业设备和传感器会产生海量数据。将所有原始数据传输到云端会消耗巨大的网络带宽,成本高昂且可能造成网络拥堵7。边缘计算通过在本地进行数据预处理、过滤、聚合和分析,只将有价值的结果或异常数据上传至云端,从而大幅减少了网络传输负担。
- 增强可靠性与韧性 (Enhanced Reliability/Resilience): 在某些情况下,工厂或物流节点的网络连接可能不稳定或中断。边缘计算使得本地设备和系统能够在离线状态下继续运行关键任务和进行本地决策,提高了系统的整体可靠性和对网络波动的适应能力。
- 提升数据安全与隐私保护 (Improved Security/Privacy): 某些敏感的生产数据或商业数据可能不适合传输到云端。边缘计算允许在本地处理这些数据,减少了数据在传输过程中被截获或泄露的风险,有助于满足数据安全和隐私合规要求。
基于以上优势,边缘计算在制造和物流领域催生了众多应用场景:
- 制造业: 除了上述提到的实时质控、PDM、机器人控制、AR/VR支持外,还包括能源管理优化(根据实时需求调整设备能耗)、柔性制造/制造即服务(MaaS,快速部署和调整生产线以响应市场需求) 等。
- 供应链与物流: 实时库存追踪与管理、运输途中环境监测(如冷链物流中的温湿度监控)、仓库自动化(如控制分拣机器人、优化仓储路径)、优化配送路线等。
边缘计算并非要取代云计算,而是作为云计算的延伸和补充。它将计算能力推向网络的边缘,与云端协同工作,形成云边协同的架构。在这种架构中,边缘负责处理实时性要求高、数据量大或涉及隐私安全的应用,而云端则承担需要全局数据、复杂模型训练和长期存储分析的任务。这种结合能够最大限度地发挥两者的优势,构建更高效、更智能的工业系统。
4.2. 边缘计算架构模式与参考模型
为了规范和指导边缘计算系统的设计与部署,业界提出了一些通用的架构模式和参考模型。理解这些架构有助于构建可扩展、可互操作的边缘计算解决方案。
4.2.1 分层架构 (Layered Architectures)
大多数物联网和边缘计算系统可以抽象为分层结构,尽管具体的层级划分可能略有不同,但核心思想一致:
- 设备层/感知层 (Device/Perception Layer): 位于最底层,包含各种传感器、执行器、PLC、工业设备等物理实体。它们是数据的原始来源和物理动作的执行者。
- 边缘层 (Edge Layer): 这是边缘计算的核心层,介于设备层和云层之间。它负责执行本地的数据处理、分析、过滤、聚合和存储。边缘层本身可能包含多个子层级(见下文"分级边缘")。关键组件包括边缘网关 (Edge Gateways) 和边缘服务器 (Edge Servers)。
- 网络/连接层 (Network/Connectivity Layer): 负责在不同层级之间传输数据,包括设备到边缘、边缘到云的通信。
- 云/企业层 (Cloud/Enterprise Layer): 位于最高层,提供强大的计算资源、大规模数据存储、复杂的模型训练、全局数据分析以及与企业级应用(如ERP、MES)的集成。
4.2.2 分级边缘架构 (Hierarchical Edge Architecture)
认识到边缘计算并非单一节点,而是一个分布式的计算连续体,业界提出了分级边缘的概念。数据在从设备流向云端的过程中,会经过不同层级的边缘节点进行逐步处理和提炼:
- 嵌入式边缘 (Embedded Edge): 计算发生在设备或传感器自身内部,进行最基础的数据处理或信号转换。
- 网关边缘 (Gateway Edge): 汇聚来自多个嵌入式边缘设备的数据,执行初步的数据聚合、过滤、格式转换或简单的分析。例如,一个边缘网关连接工厂车间的多个传感器。
- 网络/计算边缘 (Network/Compute Edge): 部署在更靠近本地网络核心或区域汇聚点的位置,拥有更强的计算能力,可以执行更复杂的分析、运行本地应用或作为连接云端的桥梁9。这一层可以进一步细分为:
- 远边缘 (Far Edge): 更靠近物理设备,如部署在车间或基站的边缘服务器 (L1),甚至传感器/控制器本身 (L2),延迟通常在亚毫秒到几毫秒之间。
- 近边缘 (Near Edge): 通常指部署在企业本地数据中心 (On-Premises) 的边缘服务器,距离设备稍远,延迟在几毫秒到十几毫秒。
这种分级处理的目的是"用数据保真度换取可操作的洞察力",即在数据向上流动的过程中,逐步减少数据量,同时提炼出更有价值的信息。
4.2.3 参考架构模型 (Reference Architecture Models)
为了促进标准化和互操作性,多个组织提出了边缘计算的参考架构模型:
| 参考架构模型 | 提出组织 | 主要特点 | 适用场景 |
|---|---|---|---|
| 工业互联网参考架构 (IIRA) | 工业互联网联盟 (IIC) | • 四个视角: 业务、功能、使用和实施 • 三层系统: 边缘层、平台层、企业层 • 定义了多个功能域 | 大型工业系统 需要完整框架的企业级项目 |
| 边缘计算参考架构模型 (RAMEC) | 学术研究机构 | • 三维模型: 关注点、层级和级别 • 全面描述边缘计算范式 | 研究项目 复杂边缘计算系统规划 |
| 边缘计算产业联盟参考架构3.0 (ECC) | 边缘计算产业联盟 | • 多维度架构 • 强调边缘虚拟化功能(EVF) • 包含智能服务和服务经纬 | 需要硬件解耦的系统 异构设备环境 |
| 国际数据空间参考架构模型 (IDS-RAM) | 国际数据空间协会 | • 核心关注数据主权 • 可信数据共享 • 支持边缘节点数据处理 | 需要严格数据治理 跨企业数据共享场景 |
- 工业互联网参考架构 (Industrial Internet Reference Architecture, IIRA): 由工业互联网联盟 (IIC) 制定。它从业务、功能、使用和实施四个视角来描述系统架构,并将系统划分为边缘层 (Edge Tier)、平台层 (Platform Tier) 和企业层 (Enterprise Tier) 三个层级。IIRA定义了控制域、操作域、信息域、应用域和业务域等功能域,并提出了一些常见的架构模式,如三层架构模式、网关介导的边缘连接与管理模式、数字孪生核心作为中间件模式等。
- 边缘计算参考架构模型 (Reference Architecture Model Edge Computing, RAMEC): 一个提出的三维模型,涵盖关注点、层级和级别等维度,旨在全面描述边缘计算范式。
- 边缘计算产业联盟 (Edge Computing Consortium, ECC) 参考架构.0: 这是一个多维度的架构,包含智能服务、服务经纬 (Service Fabric)、连接与计算经纬 (Connectivity and Computing Fabric, CCF) 以及边缘计算节点 (Edge Computing Nodes, ECNs) 等组件。它特别强调通过边缘虚拟化功能 (Edge Virtualization Function, EVF) 层来实现硬件解耦、连接管理和安全策略6。
- 国际数据空间参考架构模型 (IDS-RAM): 虽然其核心关注点是数据主权和可信数据共享,但IDS-RAM也包含了边缘计算的概念,允许在靠近数据源的边缘节点(如IDS连接器)上进行数据处理,同时遵循数据空间的治理规则2。
这些架构模式和参考模型为企业设计和实施边缘计算系统提供了重要的指导框架,有助于确保系统的结构清晰、功能完整、易于扩展并具备良好的互操作性。选择哪种架构或参考模型取决于具体的应用场景、性能要求和现有的技术基础。
4.3. 实践落地:边缘计算盒子 (华为、树莓派) 与协议转换 (Node-RED)
将边缘计算理念转化为实际应用,需要具体的硬件设备和软件工具。边缘计算盒子(通常指边缘网关或小型边缘服务器)和灵活的集成软件(如Node-RED)是实践中的关键要素。
4.3.1 边缘计算硬件平台对比
边缘计算硬件平台根据性能、成本和适用场景有很大差异,下表对比了两种典型代表:
| 特性 | 华为边缘计算物联网解决方案 | 树莓派 (Raspberry Pi) |
|---|---|---|
| 定位 | 企业级工业物联网边缘计算平台 | 低成本开源单板计算机 |
| 硬件性能 | 高性能处理器、工业级设计 | 中等性能ARM处理器、消费级设计 |
| 可靠性 | 高(工业级温度范围、防护等级) | 中(需额外防护措施) |
| 协议支持 | 全面支持工业协议(OPC UA、Modbus等) | 通过扩展模块和软件支持 |
| 操作系统 | 专用物联网操作系统(如LiteOS) | Linux发行版(Raspberry Pi OS) |
| 云平台集成 | 与华为云紧密集成 | 可与多种云平台集成(灵活但需配置) |
| 成本 | 高 | 低 |
| 适用场景 | 工业生产环境、大规模部署 | 原型设计、教育、小规模项目 |
| 开发生态 | 华为生态系统 | 开源社区支持 |
| 可扩展性 | 通过模块化设计扩展 | 通过GPIO接口和HAT扩展板扩展 |
- 边缘计算硬件平台:
- 华为边缘计算物联网解决方案 (Huawei EC-IoT): 华为提供了一系列边缘计算网关和解决方案,是其智能制造整体方案的一部分。这些网关通常具备:
- 多协议接入能力: 支持多种工业现场总线协议和接口,方便连接不同类型和年代的设备。
- 边缘计算能力: 内置计算和存储资源,可在本地运行应用程序,进行实时数据处理、分析和设备管理维护。
- 集成操作系统: 可能集成华为的物联网操作系统LiteOS,简化设备与云平台的连接和应用开发。
- 云端管理: 通过华为的Agile Controller等平台进行远程的设备管理、配置、监控和维护,降低运维成本。
- 树莓派 (Raspberry Pi): 作为一款低成本、高性价比、功能强大的单板计算机,树莓派在物联网和边缘计算领域得到了广泛应用,尤其是在原型设计、教育和一些非极端严苛的工业场景中。
- 灵活性与可扩展性: 拥有丰富的GPIO接口,可以连接各种传感器和外设。运行基于Linux的操作系统(如Raspberry Pi OS,原Raspbian),拥有庞大的开源社区支持和丰富的软件资源。
- 边缘处理能力: 其CPU、内存和存储能力足以承担一定程度的数据采集、预处理、分析和本地决策任务。研究表明,将其用于边缘层处理数据可以提高效率和响应时间。
- 适用场景: 可作为轻量级边缘网关、数据采集器、本地控制单元或用于构建边缘计算集群。但需要注意其工业环境适应性(如温湿度、稳定性)可能不如专用工业级设备,性能评估对其应用至关重要。
- 华为边缘计算物联网解决方案 (Huawei EC-IoT): 华为提供了一系列边缘计算网关和解决方案,是其智能制造整体方案的一部分。这些网关通常具备:
4.3.2 Node-RED:可视化物联网集成工具
Node-RED是一个基于Node.js的开源、可视化、流式编程工具,在工业物联网领域越来越受欢迎,特别是在连接异构设备和系统方面发挥着重要作用。
Node-RED在边缘计算场景中的典型应用场景:
| 应用场景 | 描述 | 优势 |
|---|---|---|
| 协议转换与数据集成 | 连接不同协议设备,实现数据互通 | 丰富节点库支持多种工业协议 |
| 实时数据监控 | 创建监控仪表盘,展示关键设备数据 | 内置Dashboard节点,快速可视化 |
| 设备远程控制 | 通过Web界面远程控制工业设备 | 可定制UI,支持权限控制 |
| 能源消耗监测 | 采集能源数据,分析能耗模式 | 支持数据聚合和时间序列分析 |
| 简单故障预警 | 监测异常数据并发出预警 | 低代码实现条件逻辑和通知 |
| 边缘设备逻辑处理 | 在边缘侧实现业务逻辑 | 可部署在资源受限设备上 |
| 机器对机器通信 | 促进设备间自主协作 | 支持多种通信模式和触发机制 |
| 仓储物流数据整合 | 整合仓库设备和系统数据 | 适合异构环境和"棕地"集成 |
- 核心功能:协议转换与数据处理: Node-RED最大的优势之一在于其强大的协议转换能力。工业现场往往存在多种通信协议(如Modbus、OPC UA、西门子S7、MQTT、HTTP、TCP等),Node-RED通过其丰富的节点库(Nodes),可以轻松地在这些协议之间进行桥接和转换。用户可以通过拖拽节点、连接流程的方式,快速构建数据流,实现:
- 数据提取: 从PLC(如WAGO、Phoenix Contact PLCnext)、传感器或其他设备读取数据。
- 数据处理与转换: 对数据进行清洗、格式化、计算、逻辑判断,或将其统一到标准化的数据模型。
- 数据转发与集成: 将处理后的数据发送到MQTT代理、数据库、云平台,或与上层系统(如MES、ERP,可通过REST API等方式集成)进行交互。
- 重要性与应用场景: Node-RED极大地简化了在"棕地"环境(即存在大量老旧、异构设备的现有工厂)中实现设备互联和数据集成的工作。其低代码特性加速了应用开发和原型验证。典型应用包括:实时数据采集与监控仪表盘、设备远程控制与自动化逻辑、能源消耗监测与优化、简单的故障预警支持、边缘设备逻辑处理、机器对机器 (M2M) 通信触发(如AGV调度)、仓储物流数据整合等。
- 采纳趋势: Node-RED在制造业的应用正在增长,一些PLC制造商甚至开始在其产品中直接支持或集成Node-RED。
虽然华为等提供的工业级边缘计算解决方案在稳定性、可靠性和环境适应性方面通常更优,但树莓派等低成本平台为快速原型验证和特定场景应用提供了可能。而Node-RED作为强大的"粘合剂",在连接这些硬件、打通协议壁垒、实现数据在边缘设备、网关和云平台之间顺畅流动方面,扮演着不可或缺的关键角色。然而,需要注意的是,虽然Node-RED易于使用且功能强大,但在将其应用于高可靠性、高安全性的关键工业控制任务时,仍需审慎评估其性能、稳定性和安全机制,可能需要与更专业的工业控制系统或企业级中间件配合使用。
5. 商业洞察:协同效应与溢出效应
5.1. 理解供应链中的"双边溢出效应"
在供应链数字化转型的背景下,核心企业(链主)的数字化进程不仅提升自身效率,还会对链条上的其他伙伴产生积极影响,这种影响被称为"溢出效应"。特别是,“双边溢出效应” (Bilateral Spillover Effect) 理论指出,供应链中处于主导地位的企业(链主)的数字化转型,能够显著地、正向地影响其主要上游供应商和主要下游客户的数字化水平。
- 理论定义与背景: 该理论着眼于"链式"数字化转型,即由链主企业引领,上下游伙伴共同参与的生态系统级转型过程。它旨在解释和解决不同企业间数字化能力差距过大,从而制约供应链整体协同效率的问题。该理论将传统关于链主企业对其伙伴影响的研究,扩展到了企业数字化转型这一新领域。
- 核心观点: 链主企业的数字化投入和能力提升,并不会仅仅停留在企业内部,而是会通过特定的机制,"溢出"到其紧密的合作伙伴,带动整个供应链微观系统的数字化协同能力和整体竞争力的提升。这种溢出是双向的,既影响供应商,也影响客户。
- 重要性与意义: 理解双边溢出效应,为我们认识企业"链式"数字化转型提供了一个新的视角。它揭示了链主企业在推动整个产业现代化进程中的关键杠杆作用,并为政府制定联合推动企业数字化转型的政策,以及大型企业引领上下游伙伴共同转型提供了重要的理论依据和实践启示。同时,这种效应也强化了供应链伙伴之间的经济联动关系。
- 与知识溢出的关联: 双边溢出效应可以看作是供应链中知识溢出的一种特定表现形式。知识溢出是指知识或信息在组织间(有意或无意地)传递和扩散的过程。在供应链这种相互依赖、互动频繁的环境中,知识溢出尤为重要。数字化转型本身就蕴含着大量的技术、流程和管理知识,链主企业的转型实践自然会加速这些知识向合作伙伴的溢出。信任、长期合作关系、相似的技术背景等因素都会促进知识溢出的发生。
- 潜在风险考量: 虽然本报告聚焦于积极的溢出效应,但广义的知识溢出也可能带来负面影响,例如"搭便车" (Free-riding) 行为,即合作伙伴在没有相应投入的情况下,利用了领先企业的知识成果,这可能打击领先企业的创新积极性。然而,研究明确指出了链主企业数字化转型带来的显著 正面 溢出效应。
图1:供应链中的双边溢出效应示意图
双边溢出效应理论为我们理解链主企业(见1.2节)如何发挥其领导力,将自身的数字化优势转化为整个供应链生态的共同进步,提供了一个重要的分析框架。它强调了转型不仅仅是单个企业的行为,更是一个相互影响、相互促进的系统性过程。
5.2. 作用机制:资源共享与需求牵引
双边溢出效应并非凭空产生,而是通过具体的机制在供应链伙伴之间传导。研究指出了两种核心机制:资源共享效应和需求牵引效应。
表1:双边溢出效应的核心作用机制对比
| 机制类型 | 资源共享效应 (Resource Sharing Effect) | 需求牵引效应 (Demand-Driven Effect) |
|---|---|---|
| 核心逻辑 | 链主企业将数字资源分享给合作伙伴,降低其转型门槛 | 链主企业对合作伙伴提出数字化要求,促使其提升能力 |
| 传导方向 | 主动推动型(自上而下) | 被动响应型(需求驱动) |
| 具体形式 | • 信息与知识共享 • 技术与平台共享 • 经验与最佳实践共享 | • 数字接口要求 • 数据透明度要求 • 协同效率要求 • 创新机会驱动 |
| 作用对象 | 主要影响供应商数字技术创新、客户数字资产投资 | 同时影响供应商和客户的整体数字化转型投入 |
| 实施难度 | 需要链主企业有意愿分享资源 | 容易实施,但可能引起抵触情绪 |
| 效果持续性 | 中长期,依赖持续的资源投入 | 立竿见影,但需警惕单纯合规而非真正能力提升 |
- 机制一:资源共享效应 (Resource Sharing Effect):
- 核心逻辑: 已经完成或正在进行数字化转型的链主企业,积累了大量的数字资源,包括先进的技术、成熟的平台、宝贵的实践经验和数据洞察。链主企业通过与主要供应商和客户分享这些资源,能够有效降低合作伙伴进行数字化转型的门槛和成本。
- 具体体现:
- 信息与知识共享: 分享市场趋势、消费者洞察、技术路线图等信息,拓宽伙伴视野。
- 技术与平台共享: 开放自身的数据平台接口、提供技术支持或培训,帮助伙伴快速应用新技术。
- 经验与最佳实践共享: 分享自身转型过程中的经验教训,减少伙伴试错成本。
- 作用效果: 这种资源共享直接促进了主要供应商的数字技术创新(如采用新的软件、分析工具)和主要客户的数字资产投资(如升级IT基础设施、建设电商平台),从而提升了它们的整体数字化水平。它还有助于促进伙伴间的协同研发。
- 机制二:需求牵引效应 (Demand-Driven Effect / Demand Traction):
- 核心逻辑: 链主企业自身数字化能力的提升,会对其合作伙伴产生新的、更高的数字化交互需求和标准。为了维持与链主企业的业务关系并满足其要求,合作伙伴被动或主动地进行自身的数字化升级。
- 具体体现:
- 数字接口要求: 链主企业可能要求供应商通过特定的电子平台接收订单、提交发货通知、进行质量追溯等。
- 数据透明度要求: 可能要求物流伙伴提供实时的货物追踪数据,或要求制造商提供更详细的生产过程数据。
- 协同效率要求: 链主企业优化的数字化流程(如快速响应、柔性生产)会向上游和下游传递压力,迫使伙伴提升自身的响应速度和协同能力。
- 创新机会驱动: 链主企业通过数据分析发现供应链中的瓶颈或新的增值机会,并引导合作伙伴进行相应的数字化改造以抓住这些机会。
- 作用效果: 这种需求牵引效应,通过施加渠道压力或提供创新激励,增强了合作伙伴进行数字化转型的决心和投入意愿,促使它们投资于数字技术研发和相关资产,以适应链主企业引领的数字化生态。
- 增强因素: 除了上述核心机制,一些外部因素也能显著增强溢出效应,尤其是在供应商端:
- 地理邻近性: 物理距离越近,信息、知识和资源的交流越便捷,溢出效应越强。
- 共同审计机构: 共享审计机构可能意味着更一致的业务标准和更强的互信基础,有助于数字化实践的传递。
- 基础设施: 良好的交通基础设施(如高铁服务)便于人员交流和资源流动,也能促进溢出效应。
- 关系基础: 长期、互信的合作关系是知识和资源有效共享的前提。
- 最终结果: 通过资源共享和需求牵引的双重作用,链主企业的数字化转型有效地带动了主要供应商和客户的数字化水平提升。虽然链主企业自身也能从转型中直接获益(例如研究发现其库存管理效率得到提升),但双边溢出效应的核心价值在于其对整个供应链生态系统数字化能力的催化和赋能作用。
图2:双边溢出效应的作用机制与增强因素
这两种机制共同解释了链主企业(第1.2节)如何将其内部的数字化成果转化为外部影响力,推动整个供应链生态的共同进化。链主企业既可以主动"推"动资源共享,也可以通过设定标准和需求来"拉"动伙伴转型。这种推拉结合的策略,使得链主企业成为整个供应链数字化转型的关键引擎。同时,地理邻近性等传统因素依然重要,这提示我们,数字化转型虽然由技术驱动,但其效果的发挥仍然深刻地嵌入在现实的商业关系和物理环境中。
6. 案例分析:链主模式实践 (以服装行业为例)
(注:由于提供的研究材料1 未包含关于"曼娜内衣"的具体案例细节,本节将基于前述理论和服装行业的普遍特征,构建一个说明性的案例,阐述链主企业如何通过数据共享驱动上下游伙伴转型,体现资源共享和需求牵引效应。)
6.1. 链主企业通过数据共享驱动伙伴转型
场景设定: 假设"风尚服饰 (ApparelCo)"是一家在中国市场领先的快时尚服装品牌企业,扮演着供应链"链主"的角色。面对市场快速变化、个性化需求增加以及提升供应链效率的压力,ApparelCo决定实施以数据共享为核心的数字化转型战略。
图3:服装行业链主企业数据共享驱动转型流程图
数据共享平台构建: ApparelCo投资建立了一个基于工业互联网理念 的供应链协同平台。该平台整合了来自销售终端 (POS系统、电商平台)、自有仓库、第三方物流以及部分核心供应商和制造商的数据。为了确保数据的安全和可信,对于关键的溯源或交易数据,平台可能引入了区块链技术进行记录。同时,为了处理来自各方的实时数据流并进行快速响应,平台架构中也融入了边缘计算节点,用于在数据源附近进行初步处理。
共享数据的类型与目标: ApparelCo选择性地向其核心合作伙伴(如主要面料供应商、代工厂、核心物流服务商)开放特定数据权限。共享的数据主要包括:
- 实时销售数据与库存水平: 各渠道的实时销售情况、各仓库及门店的库存数据。
- 销售预测与需求趋势: 基于历史数据和AI分析得出的短期销售预测、关键款式的需求趋势。
- 生产计划与订单状态: ApparelCo的生产计划、向代工厂下达的订单状态、物料需求计划。
- 质量反馈与标准: 来自终端消费者和内部质检的质量反馈信息、更新的产品质量标准。
目标: 通过数据共享,打破信息壁垒,提升整个供应链的透明度和协同效率,实现快速响应市场变化、精准匹配供需、优化库存管理、提升产品质量的总体目标。
6.2. 资源共享与需求牵引效应的体现
ApparelCo的数据共享战略,清晰地体现了双边溢出效应中的资源共享和需求牵引机制:
- 资源共享效应的实践:
- 数据即资源: ApparelCo将经过处理的销售数据、库存数据和预测数据作为宝贵的数字资源,分享给上游面料供应商和代工厂。供应商可以据此更准确地预测面料需求,优化原材料采购和库存,减少资金占用和浪费。代工厂可以更合理地安排生产计划,提高产能利用率和订单交付准时率。
- 平台即资源: 提供的协同平台本身就是一种数字基础设施资源。合作伙伴接入平台,可以利用平台提供的分析工具或API接口,提升自身的数据处理和决策能力。
- 知识与经验共享: 在推广平台应用的过程中,ApparelCo可能会提供相关的技术培训和实施指导,分享其在数据分析和数字化管理方面的经验,这本身也是一种知识资源的共享。
- 效果: 这种资源共享,直接推动了合作伙伴在数据分析工具、生产执行系统 (MES) 或企业资源规划 (ERP) 系统方面的投资和应用(数字资产投资),并可能激发它们在数字化排产、智能化仓储等方面的技术创新。
- 需求牵引效应的实践:
- 集成要求: 为了实现端到端的数据贯通,ApparelCo要求核心合作伙伴必须接入其协同平台,按照约定的数据标准和接口规范,实时或准实时地上传生产进度、物料库存、物流状态等信息。这就形成了明确的数字化需求。
- 响应速度要求: 快时尚行业对供应链的响应速度要求极高。ApparelCo通过共享实时销售数据和快速调整的生产计划,向上游传递了快速反应的市场压力,迫使供应商和制造商必须提升自身的数字化能力(如采用自动化设备、优化内部流程)来满足这种需求。
- 质量与追溯要求: 如果ApparelCo利用区块链等技术进行产品溯源或质量追踪,那么相关环节的合作伙伴(如面料厂、印染厂、代工厂)也必须配合采用相应的技术手段(如RFID标签、扫码上传数据)来满足链主的可追溯性要求。
- 效果: 这些来自链主的需求,无论是硬性的集成要求,还是市场传递的效率压力,都强有力地"牵引"着合作伙伴进行数字化升级。合作伙伴为了保住订单、提升竞争力,不得不加大在自动化、信息化、智能化方面的投入。
案例总结: 在这个说明性案例中,ApparelCo作为服装行业的链主企业,成功地利用数据共享这一核心手段,同时发挥了资源共享和需求牵引的作用。通过开放数据资源、提供平台支持,它降低了伙伴转型的门槛(资源共享);通过设定集成标准、传递市场压力,它激发了伙伴转型的动力(需求牵引)。最终,不仅ApparelCo自身的运营效率和市场响应能力得到提升,整个供应链生态系统的数字化水平和协同能力也得到了显著增强,实现了双边溢出效应,共同构筑了更具韧性和竞争力的数字化供应链体系。
这个案例也揭示了链主企业成功推动数据共享的关键前提:首先,链主自身需要具备强大的数字化能力和清晰的战略意图;其次,需要精心设计共享数据的范围、粒度和权限,确保数据对伙伴而言是真正有价值且可操作的;最后,也是至关重要的,必须建立起合作伙伴之间的信任基础以及明确的数据治理规则(详见第7.1节),以保障数据共享的安全、合规和可持续性。
7. 风险管控与商业化考量
数字化转型,特别是涉及跨企业数据共享和复杂技术应用的场景,必然伴随着风险,同时也对技术的商业化落地提出了更高要求。
7.1. 共享环境下的数据所有权与治理
在制造业与供应链的数字化转型中,数据共享是实现协同效应、发挥链主引领作用和激发双边溢出效应的关键。然而,数据的流动和共享也带来了关于数据所有权、使用权、隐私保护和安全性的严峻挑战3。缺乏明确的规则和有效的治理,数据共享可能引发纠纷、抑制参与意愿,甚至导致法律风险。
表2:数据共享协议 (DSA) 的关键要素与示例条款
| 协议要素 | 内容说明 | 示例条款 |
|---|---|---|
| 共享目的与范围 | 明确界定数据共享的具体用途和允许访问的数据范围 | “本协议中共享的销售数据仅用于供应商优化生产计划和库存管理,不得用于其他商业目的” |
| 数据所有权界定 | 明确原始数据和衍生数据的所有权归属 | “原始销售数据的所有权归属于数据提供方,基于该数据生成的分析报告所有权归属于数据接收方” |
| 数据使用权限 | 规定各方对数据的使用权限和限制 | “接收方可对数据进行内部分析,但不得转售、再许可或向第三方披露” |
| 保密与安全义务 | 规定数据接收方必须采取的安全措施 | “接收方须采用至少AES-256加密标准存储数据,并限制访问权限仅授予必要人员” |
| 合规性承诺 | 确保数据处理活动符合法律法规 | “双方承诺遵守《个人信息保护法》及相关数据保护法规,及时更新隐私政策” |
| 协议期限与终止 | 明确有效期限及终止后数据处理方式 | “协议有效期为一年,自动续期;终止后30天内,接收方须返还或销毁所有共享数据” |
| 责任与审计 | 界定违约责任及审计条款 | “提供方有权每季度对接收方数据处理措施进行一次审计;违反协议导致数据泄露,违约方承担全部责任” |
| 争议解决机制 | 规定如何处理协议执行中的分歧 | “因本协议引起的争议,双方应先通过友好协商解决;协商不成,提交XX仲裁委员会仲裁” |
| 不可抗力条款 | 对不可控因素导致的协议履行障碍的处理 | “因自然灾害、政府行为等不可抗力导致无法履行协议义务的,免除相应责任” |
| 通知与联系方式 | 明确正式沟通渠道和联系人 | “协议相关的所有通知应通过电子邮件发送至指定的数据保护官邮箱” |
- 核心挑战:
- 所有权界定模糊: 数据在产生、传输、处理、聚合的过程中,其所有权归属可能变得复杂。谁拥有原始数据?谁拥有经过处理或分析后产生的新数据或洞察?。
- 数据安全风险: 数据在共享过程中可能面临未经授权的访问、泄露、篡改或滥用。
- 隐私合规压力: 特别是涉及个人信息(如消费者数据、员工数据)时,必须遵守严格的隐私法规(如欧盟的GDPR、加州的CCPA以及中国的《个人信息保护法》等),包括获取明确同意、限制数据用途、保障数据主体权利等3。
- 信任缺失: 合作伙伴可能因担心数据被滥用或核心商业信息泄露而对共享数据持保留态度。
- 治理框架与协议的重要性: 建立清晰的数据治理框架和具有法律约束力的数据共享协议是应对挑战的关键。
- 数据治理 (Data Governance): 指的是一套管理数据资产生命周期的规则、流程、标准和控制措施。它明确了数据相关的角色和职责(如数据所有者、数据管理员、数据使用者)、数据质量标准(准确性、完整性、一致性、及时性等)、数据分类(根据敏感度定义访问和处理要求,如公开、受限、机密)以及数据安全策略。
- 数据共享协议 (Data Sharing Agreements / Data Use Agreements - DUAs): 这是规范数据共享行为的法律合同3。一份完善的协议应至少明确以下内容:
- 共享目的与范围: 清晰界定共享数据的具体用途和允许访问的数据范围。
- 数据所有权与使用权: 明确原始数据和衍生数据的所有权归属,以及各方对数据的使用权限和限制。
- 保密与安全义务: 规定数据接收方必须采取的安全措施(如加密、访问控制),以及对数据的保密责任。
- 合规性承诺: 确保数据处理活动符合所有适用的法律法规。
- 协议期限与终止: 明确协议的有效期限以及终止后数据的处理方式(如返还或销毁)。
- 责任与审计: 界定违约责任,并可能包含审计条款以核查协议遵守情况。
- 新兴解决方案:数据空间 (Data Spaces): 为了在保障数据主权的前提下促进更广泛、更安全的数据共享,数据空间的概念应运而生。数据空间旨在构建一个基于共同规则、标准和信任机制的分布式数据生态系统。
- 核心理念:数据主权: 数据所有者能够完全自主地决定其数据如何被访问和使用。
- 关键技术与标准:
- 参考架构: 如国际数据空间协会 (IDSA) 的IDS-RAM3 和Gaia-X架构,定义了数据空间的组件和交互方式。
- 核心组件: IDS连接器 (IDS Connectors) 作为参与者接入数据空间的标准化接口,负责执行数据策略和安全通信。
- 通信协议: 数据空间协议 (Dataspace Protocol) 定义了数据发布、策略协商和数据交换的标准流程。
- 信任与身份管理: 利用去中心化标识符 (Decentralized Identifiers, DIDs) 和可验证凭证 (Verifiable Credentials, VCs)来实现参与者身份认证和授权,通常与eIDAS等现有信任框架兼容。
- 策略执行: 使用如ODRL (Open Digital Rights Language) 等策略语言来定义和执行数据使用控制策略。
- 互操作性: 强调采用W3C (如DCAT, VCs)、OGC等国际标准,确保不同数据空间和平台间的互操作性。
- 治理组织: IDSA、Gaia-X、FIWARE基金会等组织通过数据空间商业联盟 (DSBA)等合作,共同推动技术融合和标准制定。
图4:数据空间架构与数据主权保障机制
数据空间提供了一种更系统化、更安全、更能保障数据主权的方法来应对数据共享的挑战,被认为是未来数据经济的重要基础设施。对于希望在供应链中建立深度数据协作的企业,尤其是链主企业,了解和参与数据空间的建设将是重要的战略方向。
7.2. 预测性维护商业化:精度阈值与投资回报 (ROI)
将预测性维护 (PDM) 从技术探索推向商业化应用,需要跨越技术和经济两方面的门槛。其中,如何设定合理的预测精度阈值,以及如何清晰地评估和证明其投资回报 (ROI),是商业化成功的关键考量因素。
图5:预测性维护决策流程与阈值设定考量
-
商业化的前提:证明ROI: PDM系统的实施涉及显著的前期投资,包括购买传感器、软件平台、进行系统集成以及人员培训等。因此,在决策投入之前,必须进行严谨的商业论证,量化PDM可能带来的经济效益,即计算其ROI。准确计算ROI本身也存在挑战,需要全面的成本和收益数据。
-
ROI计算的关键要素: ROI的计算逻辑是比较实施PDM后的净收益(收益增加+成本节约)与实施PDM的总成本(初始投资+持续运营成本)。
- 主要收益/成本节约项 (价值驱动因素):
- 减少非计划停机时间: 这是最直接的效益,可通过 (停机时间减少量 × 每小时停机成本) 来量化。研究表明PDM可将非计划停机减少高达50%或35-45%。
- 降低维护成本: 通过优化维护时机,避免不必要的预防性维护和昂贵的紧急维修,可降低总维护成本10-40%7 或25-30%。
- 延长设备寿命: 通过早期干预避免严重损坏,可将设备寿命延长20-40%,从而推迟资本支出。
- 提高生产效率/OEE: 设备可用性提高带来产量增加。
- 提升产品质量: 避免因设备问题导致的生产缺陷。
- 提高安全性与合规性: 减少灾难性故障和安全事故。
- 降低备件库存: 更精准的维护计划可减少备件库存持有成本,约10%。
- 提升能源效率: 维护良好的设备运行更高效。
- 主要成本项:
- 初始投资: 传感器、硬件、软件平台购买成本;安装、集成、校准、测试成本;员工培训成本。
- 持续成本: 系统维护与支持费用(年度);数据存储与计算资源费用;数据分析人力成本;传感器等硬件的更换成本。
- 主要收益/成本节约项 (价值驱动因素):
-
精度阈值与模型性能的影响: PDM模型的预测精度直接关系到其商业价值。模型的性能通常通过以下指标衡量,这些指标之间存在权衡关系:
- 敏感性 (Sensitivity) / 召回率 (Recall): 模型正确识别出实际将要发生故障的能力 (TP / (TP + FN))。高敏感性意味着能捕捉到更多真实故障,减少假阴性 (False Negatives, FN),即漏报。漏报会导致非计划停机,通常成本高昂1。
- 特异性 (Specificity): 模型正确识别出设备正常运行状态的能力 (TN / (TN + FP))。高特异性意味着能准确判断设备无故障,减少假阳性 (False Positives, FP),即误报。误报会导致不必要的维护检查或停机,增加成本并可能降低对系统的信任。
- 精确率 (Precision): 在模型预测为故障的案例中,实际确实是故障的比例 (TP / (TP + FP))。高精确率意味着预测的故障信号更可靠,采取维护行动的决策依据更充分。
- 准确率 (Accuracy): 模型正确预测(包括正确预测故障和正确预测正常)的总体比例 ((TP + TN) / (TP + TN + FP + FN))1。虽然常用,但对于故障通常是小概率事件的PDM场景,单纯看准确率可能具有误导性。
-
设定阈值的考量因素——基于失败成本的分析: 商业化应用所需的"足够好"的精度阈值并非绝对,而是需要根据具体场景下的风险和成本进行权衡。
- 失败成本分析 (Cost of Failure Analysis): 这是设定阈值的核心依据。需要评估不同类型错误的经济后果:
- 假阴性成本 (Cost of FN / Undetected Failure): 通常包括紧急维修成本、生产损失、可能的安全或环境影响、声誉损失等。对于关键设备,此成本可能极高。
- 假阳性成本 (Cost of FP / False Alarm): 通常包括检查成本、不必要的维护人工和备件成本、以及因误报导致的短暂停机损失。
- 权衡与决策: 阈值的设定实质上是在假阴性成本和假阳性成本之间寻找平衡点。
- 如果假阴性(漏报)的后果极其严重(如安全事故、核心设备停机),则倾向于设置更敏感的阈值(允许更高的误报率FP,以捕捉尽可能多的真实故障TP,即提高敏感性/召回率)。
- 如果假阳性(误报)的成本很高(如维护操作复杂昂贵、停机检查影响大),则倾向于设置更保守的阈值(要求更高的证据才报警,以减少误报FP,即提高精确率/特异性)。
- 辅助工具与方法:
- 成本函数模型: 将模型性能指标(精确率、召回率)与失败成本(Cd, k)结合,量化不同阈值下的总成本,辅助找到成本最优的阈值点。
- FMECA分析: 通过评估不同故障模式的发生概率 (Occurrence) 和严重性 (Severity/Cost Impact),可以为不同故障模式设定差异化的监控优先级和报警阈值。
- 剩余使用寿命 (RUL) 估计: 阈值也可以基于RUL的预测值来设定,例如当预测RUL低于某个安全裕度时触发维护。
- 失败成本分析 (Cost of Failure Analysis): 这是设定阈值的核心依据。需要评估不同类型错误的经济后果:
-
商业化成功的其他因素: 除了ROI和精度,PDM的成功商业化还需要考虑:数据的持续可用性和质量、与现有维护流程和系统(如CMMS)的集成、维护团队的技能提升和对新技术的接纳程度(组织变革管理)、以及选择合适的技术供应商。
表5:预测性维护ROI场景分析 - 不同类型设备示例
| 设备类型 | 初始投资 (万元) | 年度运营 成本(万元) | 非计划停机 减少 | 维护成本 节约 | 设备寿命 延长 | 投资回报周期 | 关键阈值设置考量 |
|---|---|---|---|---|---|---|---|
| 核心生产设备 (高价值生产线) | 80-120 | 15-25 | 40-50% | 25-30% | 20-30% | 9-12个月 | 重点避免漏报(FN), 可接受适度误报(FP), 敏感性优先 |
| 辅助设备 (动力/空调系统) | 40-60 | 8-12 | 30-35% | 20-25% | 15-20% | 12-18个月 | 平衡漏报与误报, 成本效益最优化 |
| 周边设备 (物流传送设备) | 20-30 | 5-8 | 20-30% | 15-20% | 10-15% | 18-24个月 | 避免过多误报(FP), 精确率优先, 减少不必要干预 |
| 通用设备 (电机/泵/阀门) | 10-15 | 3-5 | 25-35% | 15-25% | 15-25% | 12-18个月 | 按批次设置差异化阈值, 依据设备重要性和 失效影响程度 |
总之,预测性维护的商业化并非简单的技术部署,而是一个涉及经济效益评估、风险权衡、模型性能优化和组织适应的复杂过程。通过严谨的ROI分析明确其价值,并基于对失败成本的深刻理解来科学设定精度阈值,是确保PDM投资能够带来预期回报并成功融入企业运营的关键。同时,必须认识到模型预测本身存在不确定性,因此建立包含警报验证、持续学习和人机结合的闭环反馈机制1,对于提升PDM系统的鲁棒性和用户的长期信任至关重要。
表3:预测性维护 (PDM) ROI 计算关键因素
| 类别 | 因素 | 指标/衡量方法 | 相关文献 Snippets |
|---|---|---|---|
| 成本节约/收益 | 减少非计划停机 | 停机小时减少量 × 每小时停机成本 | |
| 降低维护成本 | 预防性/反应性维护工时减少量 × 人工费率;备件成本降低百分比 | ||
| 延长设备寿命 | 增加的寿命年限 × (年折旧避免额 或 延期购置成本的现值) | ||
| 提高生产效率/OEE | 产量增加百分比 或 OEE提升百分比 | ||
| 提升产品质量 | 次品/返工减少量 × 单位成本 | ||
| 提高安全性/合规性 | 事故/罚款减少带来的成本避免 (较难量化) | ||
| 降低MRO备件库存 | 库存持有成本降低百分比 | ||
| 提升能源效率 | 能耗降低百分比 × 单位能源成本 | ||
| 投资成本 | 硬件成本 (传感器等) | 设备采购成本 | |
| 软件成本 (平台/算法) | 许可证费用 (一次性或订阅) | ||
| 安装/集成/校准/测试成本 | 实施服务费用或内部人工成本 | ||
| 员工培训成本 | 培训课程费用 + 参训人员时间成本 | ||
| 系统维护与支持 (持续) | 年度维护合同费用 或 内部运维人工成本 | ||
| 数据存储与计算 (持续) | 云服务费用 或 本地服务器运维成本 | ||
| 数据分析人力成本 (持续) | 数据科学家/分析师工资福利 |
数据来源: 综合
表4:预测性维护 (PDM) 警报阈值设定框架
| 输入因素 | 阈值设定考量 | 相关文献 Snippets |
|---|---|---|
| 假阳性成本 (Cost of False Positive, FP) | 误报成本高时 (如维护操作复杂、停机检查影响大),倾向于提高阈值,要求更强的故障信号才报警,以牺牲部分敏感性来提高精确率/特异性,减少误报。 | |
| 假阴性成本 (Cost of False Negative, FN) | 漏报成本高时 (如关键设备故障、安全风险大),倾向于降低阈值,对较弱的异常信号也报警,以牺牲部分精确率/特异性来提高敏感性/召回率,减少漏报。需要区分可检测与不可检测故障成本。 | |
| 模型敏感性 (Sensitivity / Recall) | 模型本身的敏感性能力决定了在特定阈值下能捕捉到多少真实故障。阈值调整直接影响敏感性。 | |
| 模型特异性 (Specificity) | 模型本身的特异性能力决定了在特定阈值下能排除多少正常状态。阈值调整直接影响特异性。 | |
| 模型精确率 (Precision) | 阈值设定影响精确率,即报警的可靠性。精确率低意味着误报多。 | |
| 资产重要性 (Asset Criticality) | 通过FMECA等方法评估。高重要性资产通常无法容忍漏报 (FN),倾向于更敏感的阈值。低重要性资产可能允许更高的漏报风险以避免误报成本。 | |
| 故障发展速度 | 故障发展快的模式需要更低的阈值和更频繁的监测,以确保有足够的响应时间。 | |
| 监测间隔与响应时间 | 阈值设定需考虑监测频率和从报警到采取行动所需的最短响应时间,确保预警足够提前。 | |
| 数据质量与噪声水平 | 数据噪声大或质量不稳定时,过于敏感的阈值可能导致大量误报,需要更鲁棒的算法或更保守的阈值。 | |
| 成本函数优化 | 利用量化成本函数,模拟不同阈值下的总成本(FP成本+FN成本+维护成本),寻找使总成本最小化的阈值点。 |
数据来源: 综合
8. 综合路径:迈向智能制造与智慧供应链
8.1. 技术与商业模式的融合
制造业与供应链的数字化转型并非孤立技术的简单堆砌,而是需要将先进技术与创新的商业模式深度融合,形成协同效应,才能最终实现价值创造。
核心技术对比与协同
| 技术类别 | 主要功能 | 核心价值 | 应用场景 |
|---|---|---|---|
| IIoT/边缘计算 | 数据采集、实时处理 | 连接物理与数字世界 | 设备监控、实时控制、远程运维 |
| AI/ML | 数据分析、预测决策 | 智能化升级、优化决策 | PDM、规范性维护、质量预测 |
| 区块链 | 数据共享、信任建立 | 透明度、可追溯性 | 供应链协作、产品溯源、合规记录 |
| 集成工具(如Node-RED) | 系统连接、流程编排 | 技术整合、快速部署 | 跨系统数据流、业务流程自动化 |
- 技术协同发挥价值: 本报告深入探讨的几项关键技术——工业物联网预测性维护 (PDM)、区块链和边缘计算/物联网集成——并非相互排斥,而是可以相互补充、协同工作。
- IIoT/边缘计算 [第4节] 构成了数据获取的基础设施,负责连接物理世界和数字世界,并在靠近数据源的地方进行实时处理,为上层应用提供及时、有效的数据输入。
- AI/ML [第2.3节] 是智能化的核心引擎,利用IIoT/边缘计算采集的数据进行深度分析,实现精准的预测(如PDM)和优化的决策(如规范性维护)。
- 区块链 [第3节] 则为跨组织的数据共享和协作提供了可信的基础设施,确保数据的透明度、不可篡改性和可追溯性,解决了多方协作中的信任难题。例如,可以将经过边缘计算处理的关键设备状态数据或经过AI预测的维护建议,记录在区块链上,供供应链伙伴(如设备供应商、维护服务商)可信地访问。Node-RED [第4.3节] 等集成工具则扮演着"粘合剂"的角色,将这些不同的技术模块和数据流连接起来。
技术驱动的商业模式创新
- 技术驱动商业模式创新: 技术的应用最终要服务于商业目标,并可能催生新的商业模式。
- 链主引领的生态协同模式: “链主"企业 [第1.2节] 利用其技术和市场优势,通过数据共享和平台建设,发挥"双边溢出效应” [第5节],带动整个供应链生态系统的数字化升级。这本身就是一种基于平台和生态的商业模式创新。
- 基于数据的增值服务: PDM技术的成熟使得设备制造商或服务商可以从传统的销售产品模式,转向提供基于设备运行状态和性能的增值服务,例如按需维护、设备健康管理、甚至"设备即服务"(按正常运行时间或产出收费)的模式。边缘计算使得这种服务的实时性成为可能。
- 可信追溯驱动的品牌价值提升: 区块链技术提供的端到端可追溯性,尤其在食品、医药、奢侈品等领域 [第3.2节],可以显著提升产品的透明度和消费者信任度,从而增强品牌价值和市场竞争力。
- 柔性制造与个性化定制: 边缘计算、物联网和AI的结合,使得工厂能够更灵活地响应个性化订单,实现小批量、多品种的柔性生产,甚至向"制造即服务"(MaaS) 的模式演进。
整合路径建议与实施阶段
- 整合路径建议: 企业在推进转型时,应考虑一个整合的技术与商业演进路径,而非单点突破。一个可能的阶段性路径是:
. 奠定基础: 建设稳健的IIoT基础设施,实现关键设备和流程的数据采集与连接,完善数据治理 [第7.1节]。
. 提升效率: 应用CBM和基础的PDM技术 [第2.1节],结合边缘计算进行实时监控和早期预警,提升内部运营效率。
. 深化智能: 引入更高级的AI/ML算法,实现更精准的PDM和初步的规范性维护,优化资产管理和维护策略 [第2.3节]。
. 增强信任与透明: 在需要高可信度和可追溯性的环节(如关键零部件、质量控制、合规记录)引入区块链技术 [第3节]。
. 拓展协同: 链主企业构建数据共享平台,利用数据空间理念 [第7.1节] 和技术,发挥双边溢出效应,推动供应链伙伴协同转型,探索新的生态商业模式。
8.2. 转型的关键挑战与成功要素
尽管数字化转型前景广阔,但在实践中企业仍面临诸多挑战。识别这些挑战并掌握关键成功要素,对于确保转型顺利推进至关重要。
数字化转型主要挑战与应对策略
| 挑战类别 | 主要表现 | 应对策略 | 关键成功要素 |
|---|---|---|---|
| 数据相关 | 数据就绪度低、数据孤岛、集成复杂 | 数据治理体系建设、标准化接口开发 | 坚实的数据基础、统一数据标准 |
| 技术集成 | 新旧系统融合难、缺乏标准化 | 采用开放标准、构建中间层 | 互操作性设计、渐进式架构 |
| 成本与ROI | 高投入、回报不确定 | 分阶段实施、价值快速验证 | 以业务价值为导向、小步快跑 |
| 安全与治理 | 网络安全风险、数据隐私 | 安全架构设计、合规框架建立 | 风险管控机制、合规优先策略 |
| 人才与技能 | 复合人才缺乏、技能更新慢 | 培训计划、专家引进 | 人才培养、组织变革 |
| 组织与文化 | 部门壁垒、抵触情绪 | 组织重构、文化引导 | 强有力领导、文化塑造 |
| 标准化 | 行业标准缺失、互通难度大 | 参与标准制定、采用开放技术 | 开放合作、生态思维 |
- 主要挑战:
- 数据相关挑战: 数据就绪度低(可用性、质量、完整性差)是首要障碍6;数据孤岛普遍存在;数据采集和集成的成本与复杂性高;数据过载难以处理。
- 技术集成挑战: 将新技术(IIoT, AI, Blockchain, Edge)与现有老旧系统(OT/IT)集成难度大,缺乏标准化接口和协议。
- 成本与ROI挑战: 数字化转型需要高昂的前期投资,而投资回报(ROI)的量化和证明存在不确定性,使得决策困难。
- 安全与治理挑战: 数据共享和互联互通带来了新的网络安全风险和数据隐私合规压力,需要健全的治理框架。
- 人才与技能挑战: 缺乏既懂业务又懂数字化技术的复合型人才,现有员工技能更新速度跟不上技术发展。
- 组织与文化挑战: 转型需要跨部门协作,但组织壁垒和"筒仓效应"普遍存在;员工可能对变革产生抵触情绪;缺乏数据驱动的决策文化。
- 标准化与互操作性挑战: 缺乏统一的行业标准和技术规范,导致不同厂商的设备和平台难以互联互通,增加了集成成本和生态构建难度。
数字化转型成功要素框架
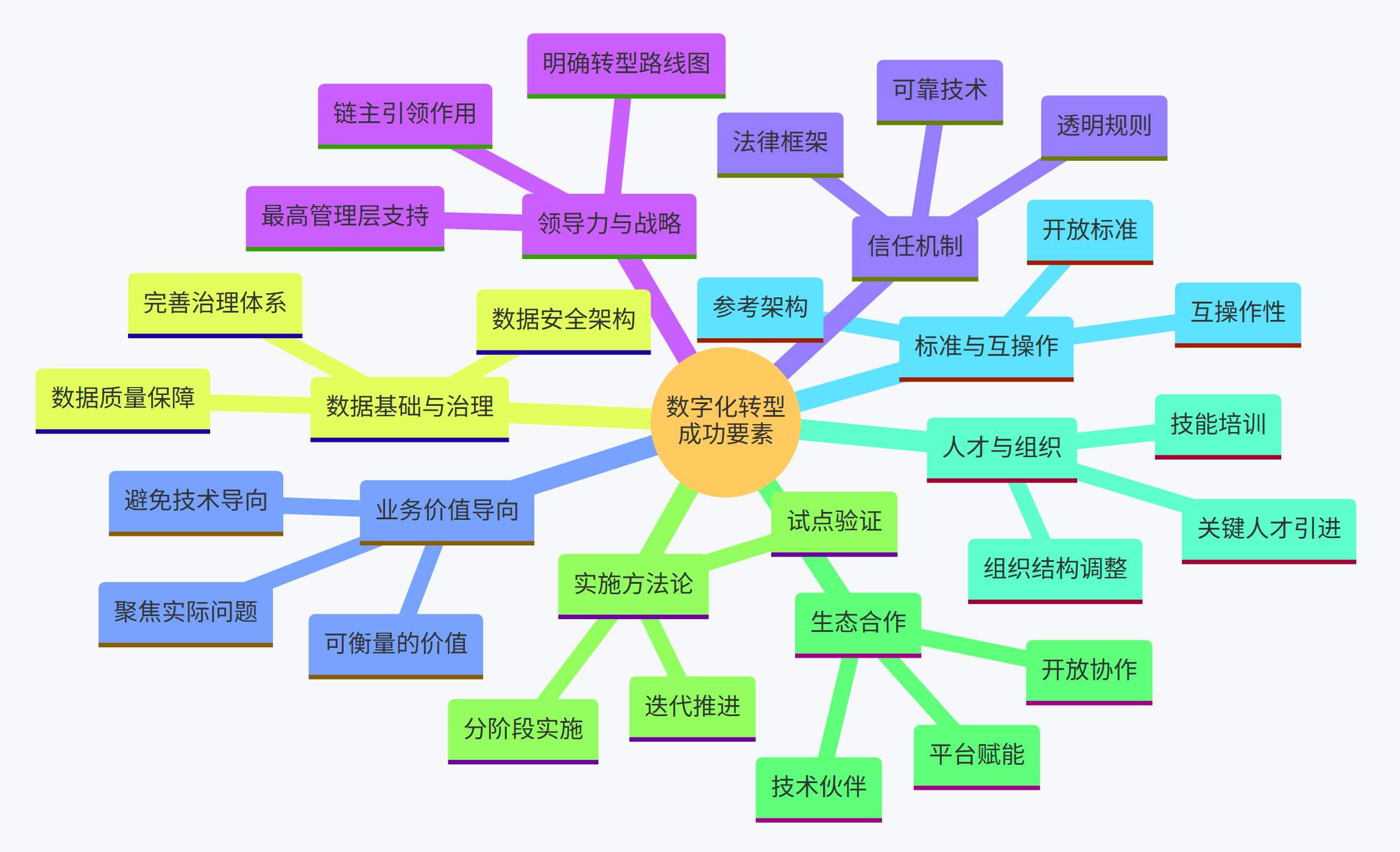
- 关键成功要素:
- 强有力的领导力与清晰战略: 最高管理层的决心和支持是转型的根本保障;需要制定清晰的、与业务目标紧密结合的数字化转型战略和路线图。链主企业的引领作用尤为关键。
- 以业务价值为导向: 技术应用应聚焦于解决实际业务问题,创造可衡量的价值(如提升效率、降低成本、改善客户体验),而非为技术而技术。
- 坚实的数据基础与治理: 将数据视为核心资产,优先投入资源建设可靠的数据采集、存储、管理基础设施,并建立完善的数据治理体系,确保数据质量和安全6。
- 循序渐进、迭代推进: 采取分阶段实施的方法,从试点项目或高价值场景入手,验证效果、积累经验、逐步推广,避免"大爆炸"式变革带来的风险。
- 开放合作与生态构建: 认识到转型非一家企业能独立完成,积极与技术伙伴、供应链伙伴开展合作,共同构建开放、互利的数字生态系统。链主企业应主动承担生态构建者的角色。
- 人才培养与组织变革: 持续投资于员工技能培训,引进关键人才;推动组织结构调整,打破部门壁垒;培育拥抱变革、数据驱动的企业文化。
- 重视标准化与互操作性: 在技术选型和系统建设中,优先考虑采用开放标准和具备良好互操作性的解决方案(如遵循IDS、IIRA等参考架构),为未来的集成和扩展奠定基础。
- 建立信任机制: 在涉及多方数据共享的场景下,通过透明的规则、可靠的技术(如区块链、数据空间)和具有法律效力的协议,建立合作伙伴间的信任关系。
8.3. 对各类企业的战略建议
基于上述分析,针对不同类型的企业,提出以下战略建议:
企业数字化转型战略矩阵
| 企业类型 | 战略重点 | 实施要点 | 预期成果 |
|---|---|---|---|
| 所有企业 | 战略先行、数据为基 | 明确目标、夯实基础、小步快跑 | 效率提升、成本降低、决策优化 |
| 链主企业 | 平台化思维、生态构建 | 引领行业、标准制定、伙伴赋能 | 生态价值、供应链韧性、创新加速 |
| 中小企业 | 紧跟链主、聚焦核心 | 差异化定位、平台利用、资源整合 | 协同提升、降低成本、专业增值 |
- 对所有寻求转型的企业:
. 战略先行: 明确数字化转型的业务目标和战略优先级,切忌盲目跟风。
. 数据为基: 将数据治理和数据质量提升作为基础工程来抓,没有高质量的数据,后续的AI、大数据应用都将是空中楼阁。
. 基建投入: 投资建设灵活、可扩展的IIoT基础设施,为未来的数据采集和应用奠定基础。
. 小步快跑: 从能够快速产生价值的试点项目开始,验证技术可行性和商业模式,然后逐步推广。
. 人才赋能: 制定人才培养计划,提升现有员工的数字技能,同时引进外部专业人才。
. 文化塑造: 培育鼓励创新、容忍试错、基于数据进行决策的企业文化。 - 对链主企业:
. 担当引领者: 充分认识并主动发挥自身在供应链中的引领作用和"双边溢出效应"。
. 平台化思维: 考虑构建开放的数据共享平台或参与/主导行业数据空间的建设 [第7.1节],为生态伙伴赋能。
. 善用影响力: 结合运营要求和金融工具(如供应链金融),引导和激励合作伙伴共同进行数字化升级。
. 标准倡导者: 在自身实践的基础上,积极参与或推动行业数据标准和技术规范的制定,降低整个生态的协同成本。 - 对中小企业/合作伙伴:
. 紧跟链主: 积极响应链主企业的数字化要求,将其视为自身转型升级的契机。
. 聚焦核心能力: 结合自身业务特点和资源限制,优先在能够直接提升与链主协同效率或满足其核心需求的环节进行数字化投入。
. 借力平台: 充分利用链主企业提供的共享平台、数据资源和技术支持,降低转型成本。
. 寻求差异化: 在满足基本协同要求的基础上,探索在特定领域(如柔性制造、专业化服务)利用数字化技术建立自身的差异化竞争优势。
制造业与供应链数字化转型综合价值模型
结论
制造业与供应链的数字化转型是一场深刻而复杂的系统性变革,技术是驱动力,而商业模式创新和生态协同是实现价值的关键。本文深入剖析了预测性维护、区块链、边缘计算等核心使能技术,并结合链主企业模式、双边溢出效应等商业洞察,揭示了转型的内在逻辑和实践路径。
成功转型并非易事,企业需要克服数据、技术、成本、安全、人才和组织等多重挑战。然而,通过制定清晰的战略、夯实数据基础、采取分阶段实施、重视生态合作、并建立有效的风险管控和治理机制,企业完全有能力驾驭这场变革。特别是链主企业,应勇于担当,利用其资源和影响力,通过数据共享和平台赋能,激发双边溢出效应,引领整个供应链生态迈向更智能、更高效、更具韧性的未来。对于所有参与者而言,拥抱数字化、持续学习、开放合作,将是在这场转型浪潮中保持竞争力的不二法门。

与 Go 协程的运行原理不同 为何Go 能在低配机器上承接10万 Websocket 协议连接)

:学会控件的使用(自定义弹窗))
——考试介绍【新】)



)
——DDS信号发生器设计)

)




 (传输协议层:UDP、TCP))


