前言
本节内容我们介绍一下hadoop在手动模式下如何实现HDFS的高可用,HDFS的高可用功能是通过配置多个 NameNodes(Active/Standby)实现在集群中对 NameNode 的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将 NameNode很快的切换到另外一台机器,并通过JournalNode实现主备节点的数据同步。
正文
- 集群规划
HDFS高可用集群规划
hadoop101 hadoop02 hadoop03 NameNode NameNode NameNode JournalNode JournalNode JournalNode DataNode DataNode DataNodeNameNode:控制节点
JournalNode:控制节点数据同步
DataNode:数据节点
- 清除hadoop集群下的data和logs目录
-清除hadoop101的data和logs目录,hadoop102和hadoop103同上步骤

- 在/opt/module/hadoop-3.1.3/etc/hadoop目录下修改core-site.xml配置文件
- core-site.xml配置文件
<configuration><!-- 把多个 NameNode 的地址组装成一个集群 mycluster --><property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><!-- 指定 hadoop 运行时产生文件的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property> </configuration>

- 在/opt/module/hadoop-3.1.3/etc/hadoop目录下修改hdfs-site.xml配置文件
- 修改hdfs-site.xml配置文件
<configuration><!-- NameNode 数据存储目录 --><property><name>dfs.namenode.name.dir</name><value>file://${hadoop.tmp.dir}/nn</value></property><!-- DataNode 数据存储目录 --><property><name>dfs.datanode.data.dir</name><value>file://${hadoop.tmp.dir}/dn</value></property><!-- JournalNode 数据存储目录 --><property><name>dfs.journalnode.edits.dir</name><value>${hadoop.tmp.dir}/jn</value></property><!-- 完全分布式集群名称 --><property><name>dfs.nameservices</name><value>mycluster</value></property><!-- 集群中 NameNode 节点都有哪些 --><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2,nn3</value></property><!-- NameNode 的 RPC 通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>hadoop101:8020</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>hadoop102:8020</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn3</name><value>hadoop103:8020</value></property><!-- NameNode 的 http 通信地址 --><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>hadoop101:9870</value></property><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>hadoop102:9870</value></property><property><name>dfs.namenode.http-address.mycluster.nn3</name><value>hadoop103:9870</value></property><!-- 指定 NameNode 元数据在 JournalNode 上的存放位置 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop101:8485;hadoop102:8485;hadoop103:8485/mycluster</value></property><!-- 访问代理类:client 用于确定哪个 NameNode 为 Active --><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 --><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><!-- 使用隔离机制时需要 ssh 秘钥登录--><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hadoop/.ssh/id_rsa</value></property> </configuration>

- 分发配置文件到其它hadoop集群服务器
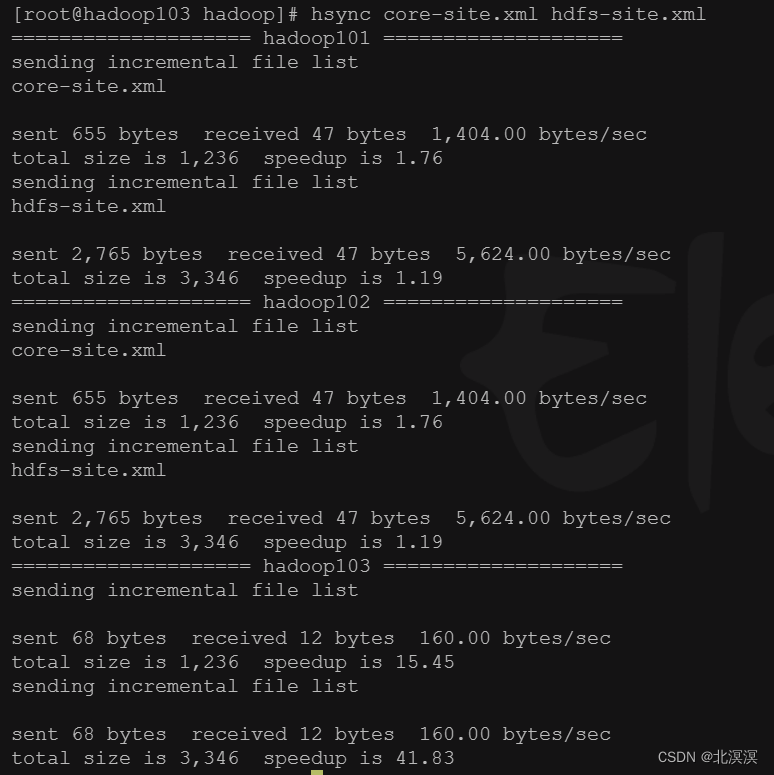
- 启动hadoop集群的journalnode服务,用于同步namenode数据
- 命令:hdfs --daemon start journalnode



- 对hadoop101节点数据格式化并启动namenode服务
- 数据格式化命令:hdfs namenode -format
- 启动namenode服务命令:hdfs --daemon start namenode


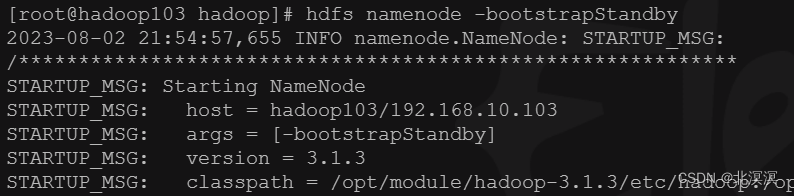
- 在hadoop102与hadoop103上面执行以下命令同步hadoop101的元数据信息
命令:hdfs namenode -bootstrapStandby

- 启动hadoop102与hadoop103的namenode服务
命令:hdfs --daemon start namenode


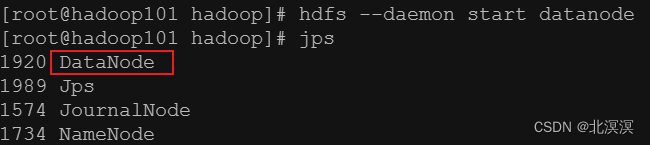
- 在所有节点开启datanode服务
命令:hdfs --daemon start datanode


- 将hadoop101激活为主节点
命令:hdfs haadmin -transitionToActive nn1
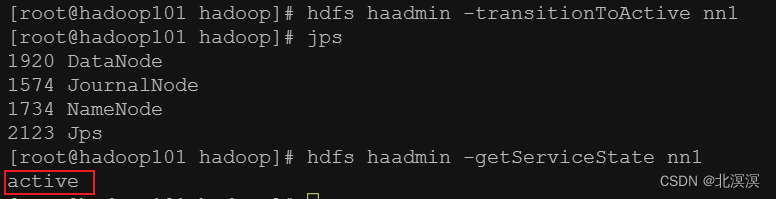
- 查看节点状态


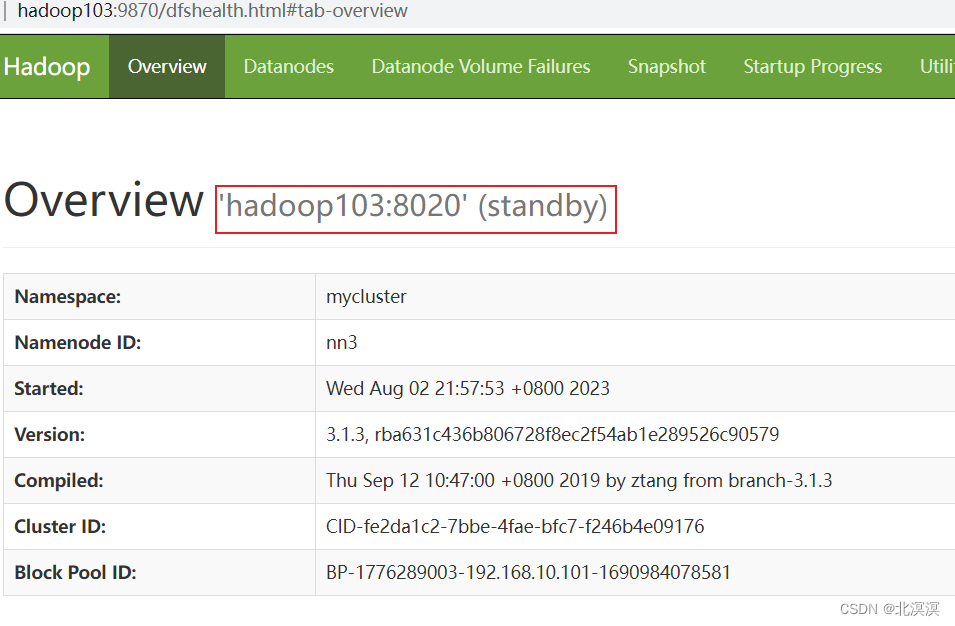
- 自动模式存在的问题
- 如果namenode挂机之后,想直接故障转移,把其它节点升级为namenode主节点是不行的,必须先将挂机的namenode重新启动才行,手动模式必须保证所有namenode节点必须是存活状态
- 在有active状态下的namenode节点,是无法切换其它节点为active节点
- 集群中只有一个节点是active
结语
hadoop高可用之HDFS手动模式高可用内容到这里就结束了,我们下期见。。。。。。









)
)






)

从入门到精通系列之十四:安装工具)