场景
Windows中通过bat定时执行命令和mysqldump实现数据库备份:
Windows中通过bat定时执行命令和mysqldump实现数据库备份_mysqldump bat-CSDN博客
Windows上通过bat实现不同数据库之间同步部分表的部分字段数据:
Windows上通过bat实现不同数据库之间同步部分表的部分字段数据_不同数据库不同字段之间的数据同步-CSDN博客
上面讲了在mysql中使用mysqldump备份的记录。
当然如果两个数据中指定表的同步可以直接使用Navicat等软件进行。
但是如果不能同时连接两个库进行数据同步,就需要先把一个库中某个表导出,再到另一个网络环境下执行导入。
但是在postgresql中使用navicat直接导出sql文件并导入会有问题。
PostgreSQL 提供了备份单个数据库的工具 pg_dump
它支持三种文件格式:
• plain,文本格式,输出一个纯文本形式的 SQL 脚本,默认值。还原时直接使用 psql 工具导入。
• custom,自定义格式,输出一个自定义格式的归档文件,还原时使用 pg_restore 工具。
与目录导出格式结合使用时,提供了最灵活的输出格式,它允许在恢复时手动选择和排序已归档的项。
这种格式在默认情况还会进行文件的压缩。
• directory,目录格式,输出一个目录格式的归档,还原时使用 pg_restore 工具。这种格式将会创建一个目录,
为每个导出的表和大对象都创建一个文件,另外再创建一个内容目录文件,该文件使用自定义格式存储关于导出对象的描述。
这种格式在默认情况还会进行文件的压缩,并且支持并行导出。
• tar,打包格式,输出一个 tar 格式的归档,还原时使用 pg_restore 工具。这种格式与目录格式兼容,
解压一个 tar 格式的归档将会产生一个目录格式的归档。但是,tar 格式不支持压缩。
另外,在使用 tar 格式归档进行还原时,表数据项的相对顺序不能进行改动。
下面使用第一种方式进行两个库指定表的导出与导入。
注:
博客:
霸道流氓气质_C#,架构之路,SpringBoot-CSDN博客
实现
1、进入到postgres的安装目录的bin下打开cmd,即包含有pg_dump.exe的目录
执行导出命令
pg_dump –h 127.0.0.1 –U postgres –p 5432 –d postgres_geo -t bus_badao –f "D:/badao.dmp"其中
-h代表数据库ip
-U代表用户名
-p代表端口号
-d代表指定数据库名
-t代表指定表名
-f代表输出的目录和文件名
回车之后会提示输入密码

无任何报错提示则导出成功,可去导出目录下进行验证

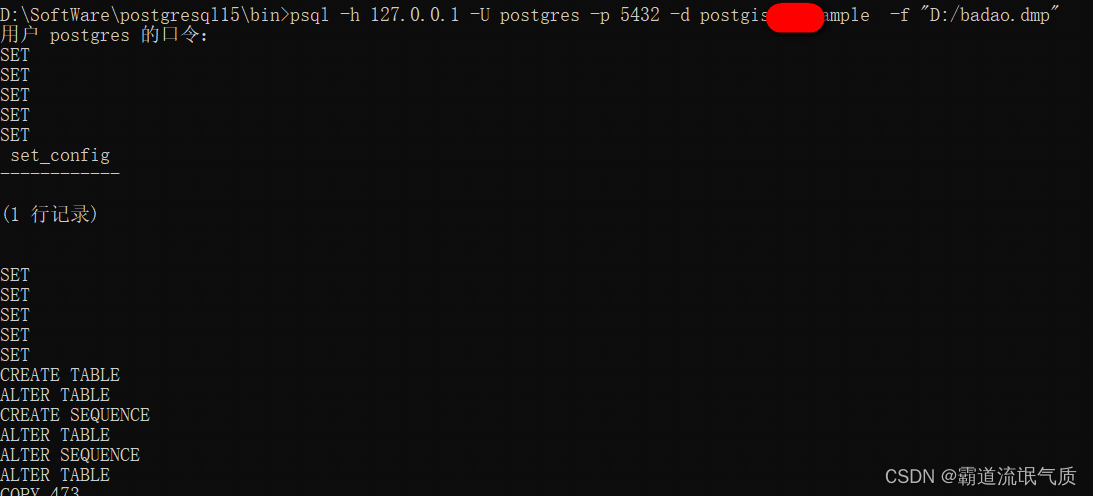
2、导入
同样在bin目录下打开cmd,执行导入命令
psql –h 127.0.0.1 –U postgres –p 5432 –d postgis_33_sample –f "D:/badao.dmp"其中postgis_33_sample代表数据库名
同样会提示输入密码。
导入成功
3、导出导出其他参数明细
Usage:
pg_dump [OPTION]... [DBNAME] 数据库名放最后,不指定默认是系统变量PGDATABASE指定的数据库。
常用选项:
-f, --file=FILENAME 导出后保存的文件名
-F, --format=c|d|t|p 导出文件的格式(custom, directory, tar, plain, text(default))
-a, --data-only 只导出数据,不包括模式
-b, --blobs 在转储中包括大对象
-c, --clean 在重新创建之前,先清除(删除)数据库对象
-C, --create 在转储中包括命令,以便创建数据库(包括建库语句,无需在导入之前先建数据库)
-t, --table=TABLE 只转储指定名称的表
--column-inserts 以带有列名的insert命令形式转储数据
-t, --table=TABLE 只转储指定名称的表(多张表 -t tb_1 -t tb_1)
-T, --exclude-table=TABLE 不转储指定名称的表(多张表 -t tb_1 -t tb_2)
General options:(一般选项)
-f, --file=FILENAME 导出后保存的文件名
-F, --format=c|d|t|p 导出文件的格式(custom, directory, tar, plain, text(default))
-j, --jobs=NUM 并行任务数
-v, --verbose 详细信息
-V, --version 版本信息
-Z, --compress=0-9 压缩格式的压缩级别
--lock-wait-timeout=TIMEOUT 在等待表锁超时后操作失败
-?, --help 帮助信息
Options controlling the output content:(控制输出的选项)
-a, --data-only 只导出数据,不包括模式
-b, --blobs 在转储中包括大对象
-c, --clean 在重新创建之前,先清除(删除)数据库对象
-C, --create 在转储中包括命令,以便创建数据库(包括建库语句,无需在导入之前先建数据库)
-E, --encoding=ENCODING 转储以ENCODING形式编码的数据
-n, --schema=SCHEMA 只转储指定名称的模式
-N, --exclude-schema=SCHEMA 不转储已命名的模式
-o, --oids 在转储中包括 OID
-O, --no-owner 在明文格式中, 忽略恢复对象所属者
-s, --schema-only 只转储模式, 不包括数据(不导出数据)
-S, --superuser=NAME 在转储中, 指定的超级用户名
-t, --table=TABLE 只转储指定名称的表
-T, --exclude-table=TABLE 不转储指定名称的表
-x, --no-privileges 不转储权限 (grant/revoke)
--binary-upgrade 只能由升级工具使用
--column-inserts 以带有列名的insert命令形式转储数据
--disable-dollar-quoting 取消美元 (符号) 引号, 使用 SQL 标准引号
--disable-triggers 在恢复数据的过程中禁用触发器
--exclude-table-data=TABLE 不转储指定表的数据
--inserts 将数据转储为insert命令,而不是copy命令
--no-security-labels 不分配安全标签进行转储
--no-synchronized-snapshots 不在并行任务中使用同步快照
--no-tablespaces 不转储表空间分配信息
--no-unlogged-table-data 不转储未标记的表数据
--quote-all-identifiers 引用所有标识符( 不是关键字 )
--section=SECTION 转储命名部分(pre-data, data, or post-data)
--serializable-deferrable 等待没有异常的情况下进行转储
--use-set-session-authorization 使用SET SESSION AUTHORIZATION命令而不是ALTER OWNER命令来设置所有权
Connection options:(控制连接的选项)
-d, --dbname=DBNAME 转储的数据库名
-h, --host=HOSTNAME 数据库服务器的主机名或IP
-p, --port=PORT 数据库服务器的端口号
-U, --username=NAME 指定数据库的用户联接
-w, --no-password 不显示密码提示输入口令
-W, --password 强制口令提示 (自动)
--role=ROLENAME 转储前设置角色
如果没有提供数据库名字, 那么使用 PGDATABASE 环境变量的数值.
)




![neuq-acm预备队训练week 10 P1525 [NOIP2010 提高组] 关押罪犯](http://pic.xiahunao.cn/neuq-acm预备队训练week 10 P1525 [NOIP2010 提高组] 关押罪犯)






)






)