如何构建你自己的商务聊天机器人?注意哦,是你自己的聊天机器人。一起来看看Redis Enterprise的向量检索是怎么帮你实现这个愿望的吧。
鉴于最近人工智能支持的API和网络开发工具的激增,似乎每个人都在将聊天机器人集成到他们的应用程序中。
LangChain是一种备受欢迎的新框架,近期引起了广泛关注。该框架旨在简化开发人员与语言模型、外部数据和计算资源进行交互的应用程序开发过程。它通过清晰且模块化的抽象,关注构建所需的所有构建模块,并构建了常用的"链条",即构建模块的组合。例如,对话检索链条可以让用户与外部存储中的数据进行交互,实现真实的对话体验。
LangChain是如何实现这一目标的呢?OpenAI的语言模型并没有针对特定企业的具体数据进行训练或优化。如果您的聊天机器人依赖于该框架,您需要在运行时向OpenAI提供数据。在检索步骤中,我们使用向量相似性搜索(VSS)从Redis中获取与用户查询相关的数据,并将这些数据与原始问题一起输入到语言模型中。这要求模型仅使用提供的信息(在人工智能领域中称为"上下文")来回答问题。
这个链条中的大部分复杂性都归结于检索步骤。因此,我们选择将LangChain与Redis Enterprise集成为一个向量数据库。这种组合为复杂的人工智能和产品开发之间搭建了桥梁。
在这个简短的教程中,我们将展示如何构建一个会话式的零售购物助手,帮助顾客在产品目录中发现那些被埋藏的令人感兴趣的商品。读者可以按照提供的完整代码进行操作。
一、构建你的聊天机器人
首先,安装项目所需的所有组件。
(一)安装 Python 依赖项
这个项目需要一些Python库。这些库存储在github仓库的requirements.txt文件中。(Github:https://github.com/RedisVentures/redis-langchain-chatbot)

(二)准备产品数据集
1、对于零售聊天机器人,我们选择使用Amazon Berkeley Objects数据集。该数据集包含了大量适用于生成零售助手的亚马逊产品。
2、使用Python的pandas库来加载和预处理数据集。在加载过程中,我们可以截断较长的文本字段。这样一来,我们的数据集会更加精简,从而节省内存和计算时间。
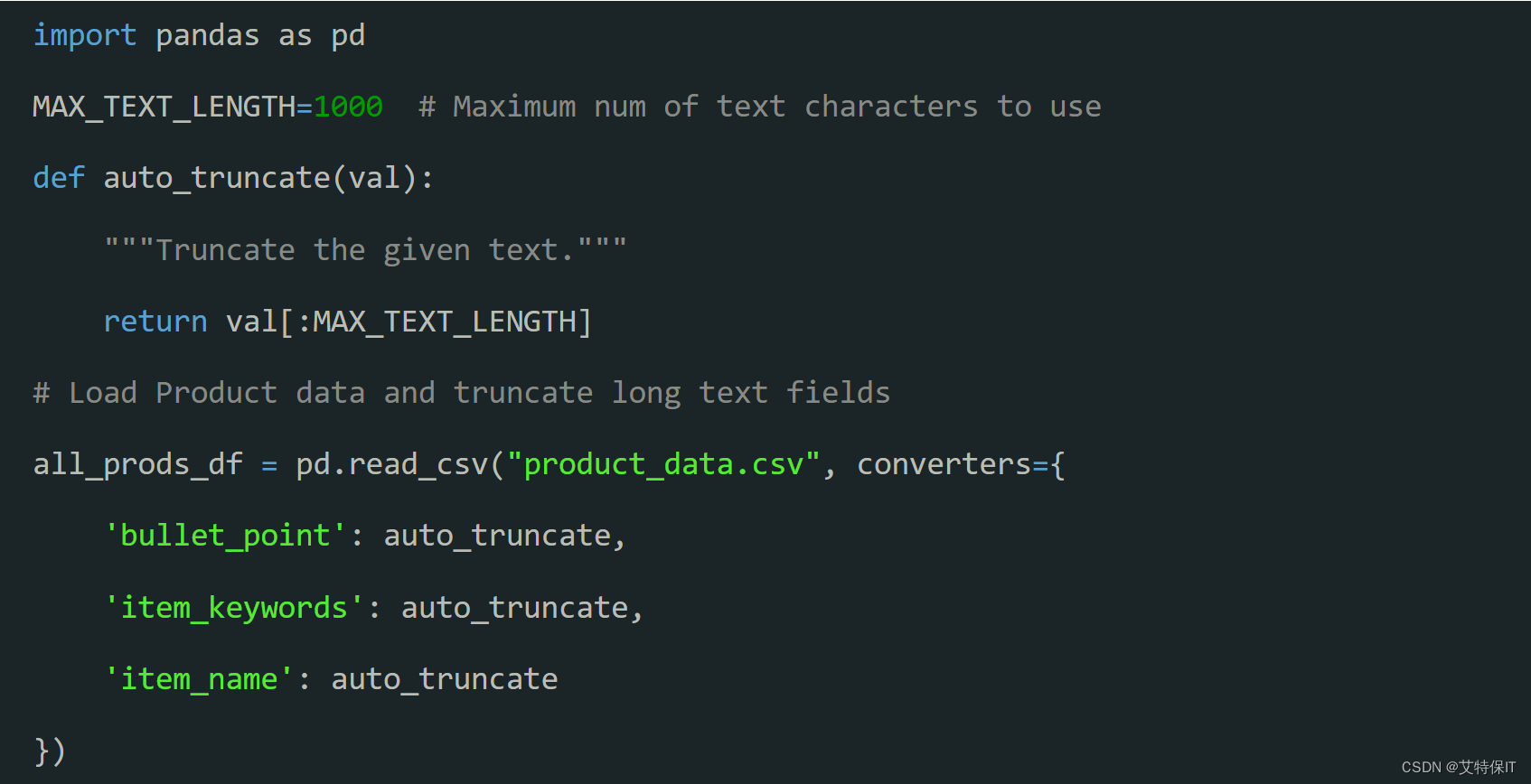
4、如果你持续在跟进GitHub上的代码步骤,可以使用all_prods_df.head()来查看数据框的前几行。完整的数据集包含超过100,000个产品,但是对于这个聊天机器人,我们将其限制在2500个的子集中。

5、下面是我们要处理的产品JSON对象的一个示例。
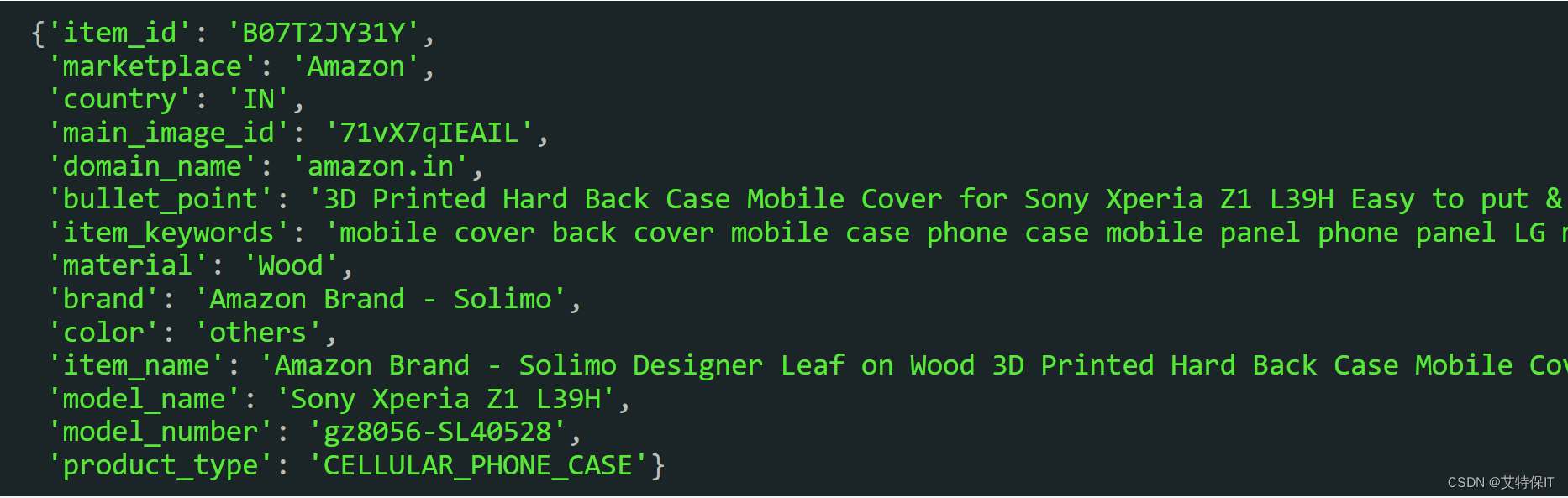
二、使用Redis作为向量数据库的设置
1、LangChain为Redis提供了一个简单的包装器,可用于加载文本数据并创建捕捉“含义”的嵌入向量。在以下代码中,我们准备产品文本和元数据,准备文本嵌入的提供程序(OpenAI),为搜索索引分配一个名称,并提供一个用于连接的Redis URL。

到这里,我们已经成功处理了Amazon产品数据集,并将其加载到了具有向量嵌入的Redis数据库中。
2、然后,我们将它们整合在一起,创建Redis向量存储。

三、创建 LangChain 对话链
现在我们准备好创建一个聊天机器人,使用存储在Redis中的产品数据来进行对话。聊天机器人因其极大的实用性而非常受欢迎。在我们下面构建的场景中,我们假设用户需要穿搭建议。
1、为了引入更多LangChain功能,我们需要导入几个LangChain工具。

2、正如在介绍中提到的,这个项目使用了一个ConversationalRetrievalChain来简化聊天机器人的开发。
Redis作为我们的存储介质,保存了完整的产品目录,包括元数据和由OpenAI生成的捕捉产品内容语义属性的嵌入向量。通过使用底层的Redis Vector Similarity Search(VSS),我们的聊天机器人可以直接查询目录,以找到与用户购物需求最相似或相关的产品。这意味着您无需进行繁琐的关键字搜索或手动过滤,VSS会自动处理这些问题。
构成聊天机器人的ConversationalRetrievalChain分为三个阶段:
- 问题创建:在这个阶段,聊天机器人评估输入的问题,并利用OpenAI GPT模型将其与之前的对话交互知识(如果有)结合起来。通过这个过程,机器人可以更好地理解购物者的问题,并为后续的检索提供准确的上下文。
- 检索:在检索阶段,聊天机器人根据购物者表达的兴趣项,搜索Redis数据库,以获取最佳的可用产品。通过使用Redis Vector Similarity Search(VSS)等技术,机器人能够快速而准确地检索与购物者需求相匹配的产品。
- 问题回答:在这个阶段,聊天机器人从向量搜索的查询结果中获取产品信息,并利用OpenAI GPT模型帮助购物者浏览选项。机器人可以生成适当的回答,提供有关产品特征、价格、评价等方面的信息,以帮助购物者做出决策。
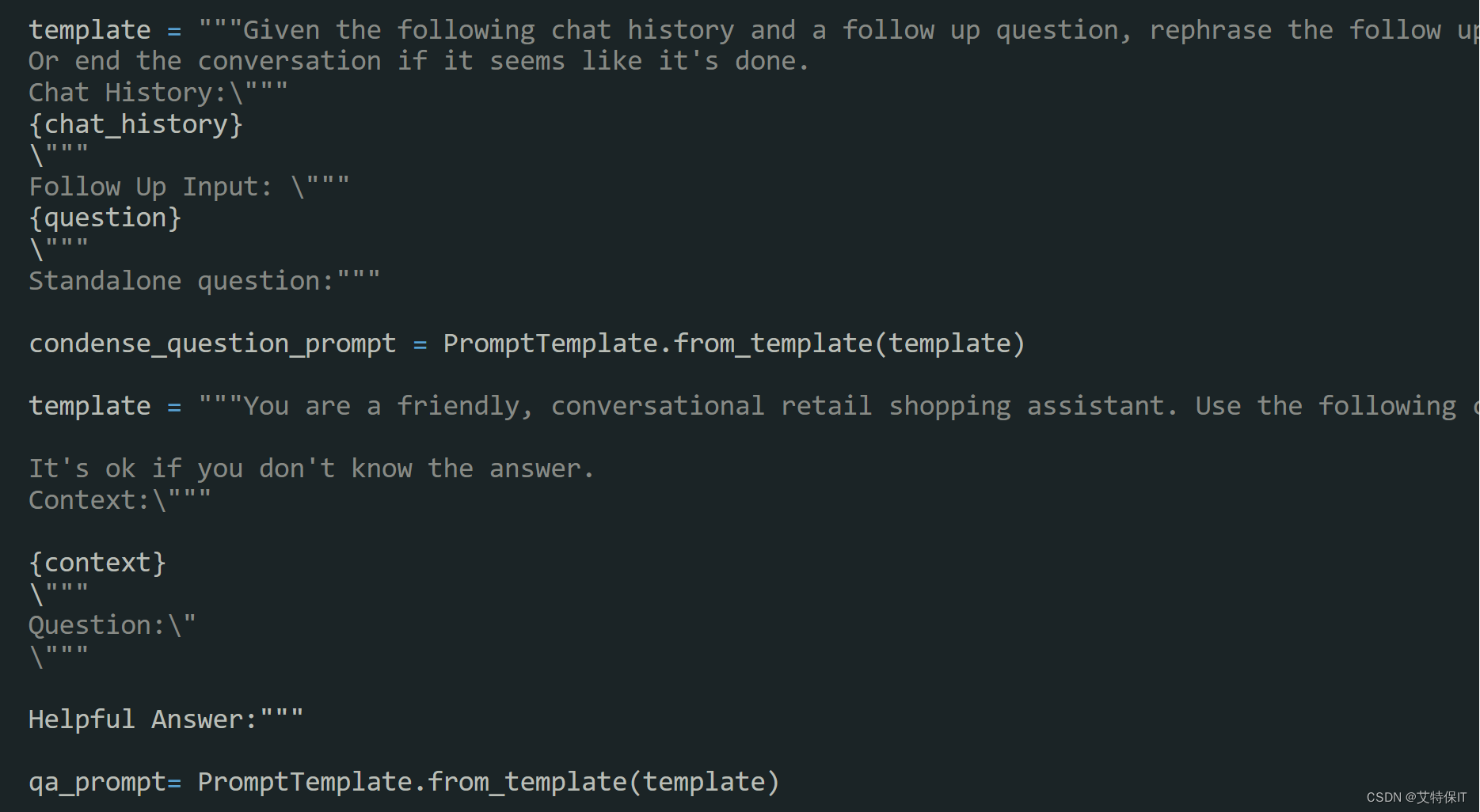
3、虽然LangChain和Redis极大地提升了工作流程的效率,但与大型语言模型(如GPT)进行交互时需要使用"提示(prompt)"来进行沟通。我们创造出一组指令作为提示,以引导模型的行为朝着期望的结果发展。为了获得聊天机器人的最佳效果,需要进一步完善提示的设置。
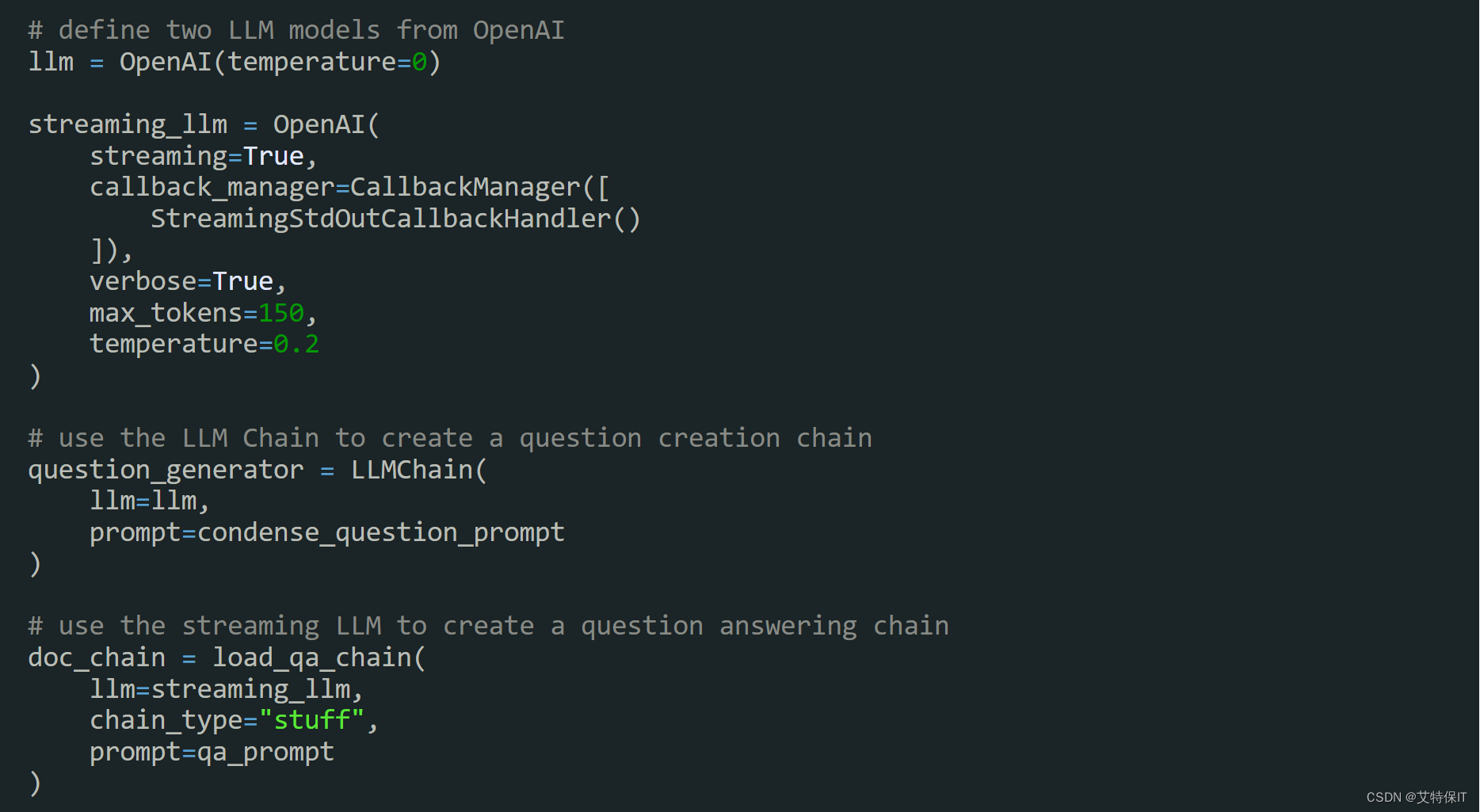
4、接下来,我们定义两个OpenAI LLM,并分别使用链条对其进行封装,用于问题生成和问题回答。streaming_llm允许我们逐个标记地将聊天机器人的响应传输到stdout,从而为用户提供类似于聊天机器人的用户体验。
5、最后,我们使用ConversationalRetrievalChain将所有三个步骤封装起来。

四、虚拟购物助手已就绪
1、请注意,这并不是一个全能的聊天AI。然而,通过Redis的帮助,它存储了完整的产品库知识,我们能够打造出一个相当出色的体验。
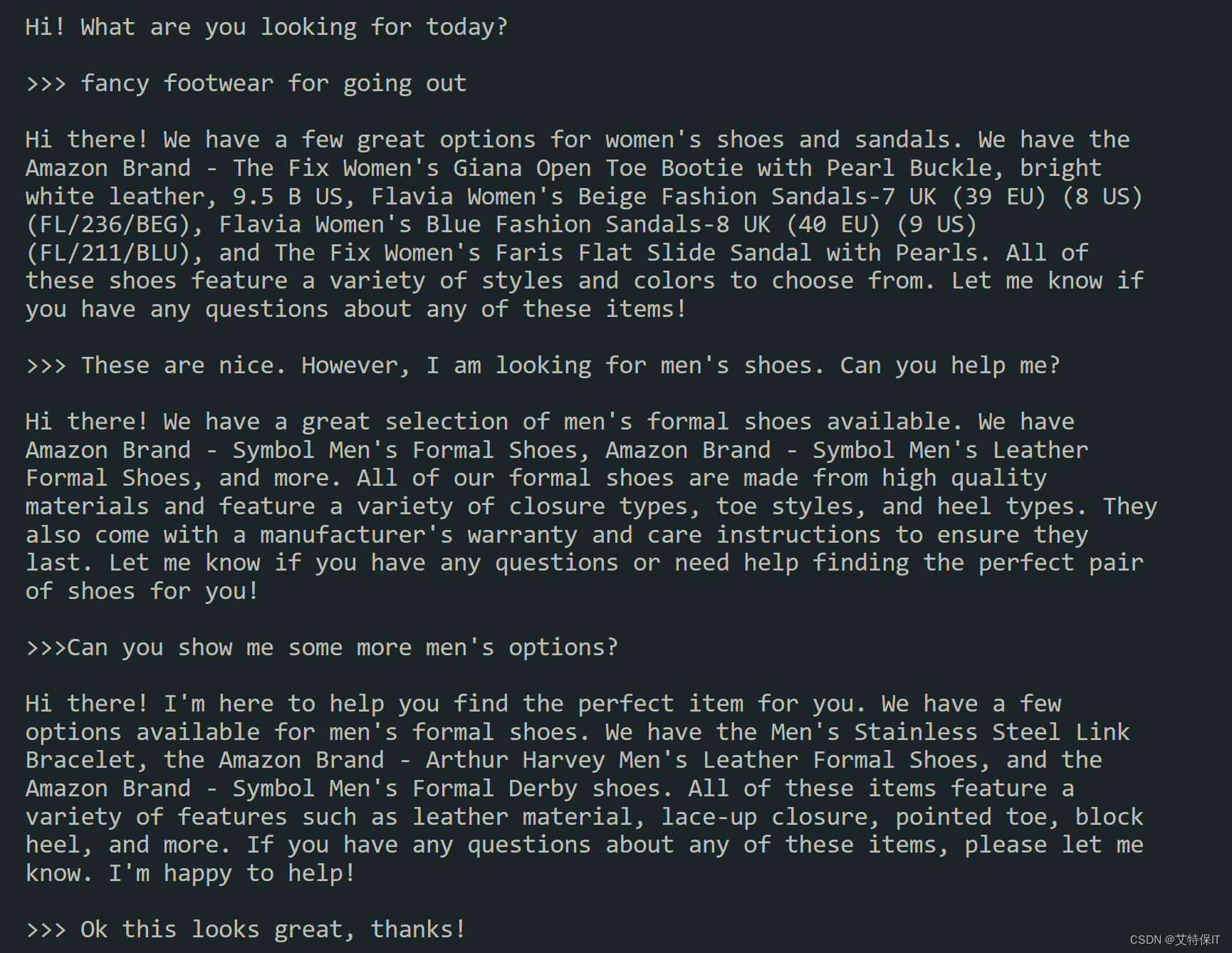
2、该机器人将实时与您交互,并根据目录中的商品帮助您缩小选择范围。以下是一个简单的示例:

3、在聊天机器人用发出“你好!今天你在找什么?”此类的招呼后,尝试一些示例提示,或者自己创建一个。
五、定制您的链条以提高性能
1、LangChain最好的部分之一是每个类抽象都可以扩展或创建自己的预设。我们自定义BaseRetriever类,在返回结果之前执行一些文档预处理。

2、我们需要更新检索类和聊天机器人,以使用上述的自定义实现。

3、大功告成!现在你的聊天机器人可以在对话中注入更多的产品信息。以下是另一个短对话的示例:



)




)





)




