前置知识
什么是一致性算法?
- 安全性保证,绝对不会返回一个错误的结果;
- 可用性,容忍集群部分节点失败;
- 不依赖时序来保证一致性;
- 一条指令可以尽可能快的在集群中大多数节点响应一轮远程过程调用时完成。小部分比较慢的节点不会影响系统整体的性能;
Raft
总结:

服务器状态转移:
跟随者只响应来自其他服务器的请求。如果跟随者接收不到消息,那么他就会变成候选人并发起一次选举。获得集群中大多数选票的候选人将成为领导人。在一个任期内,领导人一直都会是领导人,直到自己宕机了。
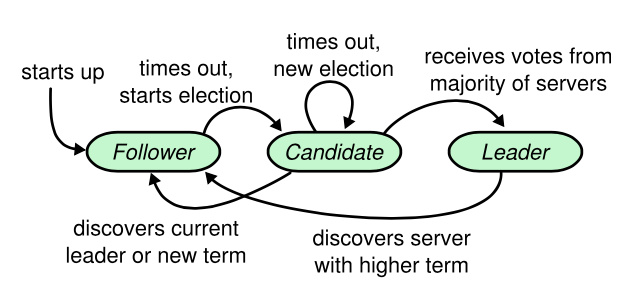
避免脑裂:奇数个服务器,在任何时候为了完成任何操作,必须凑够过半的服务器来批准相应的操作。
例如,当一个Raft Leader竞选成功,那么这个Leader必然凑够了过半服务器的选票,而这组过半服务器中,必然与旧Leader的过半服务器有重叠。所以,新的Leader必然知道旧Leader使用的任期号(term number),因为新Leader的过半服务器必然与旧Leader的过半服务器有重叠,而旧Leader的过半服务器中的每一个必然都知道旧Leader的任期号。类似的,任何旧Leader提交的操作,必然存在于过半的Raft服务器中,而任何新Leader的过半服务器中,必然有至少一个服务器包含了旧Leader的所有操作。这是Raft能正确运行的一个重要因素。
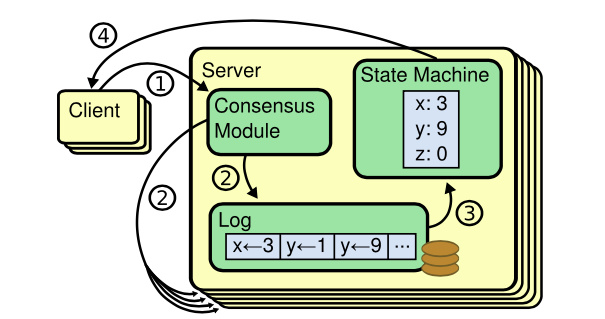
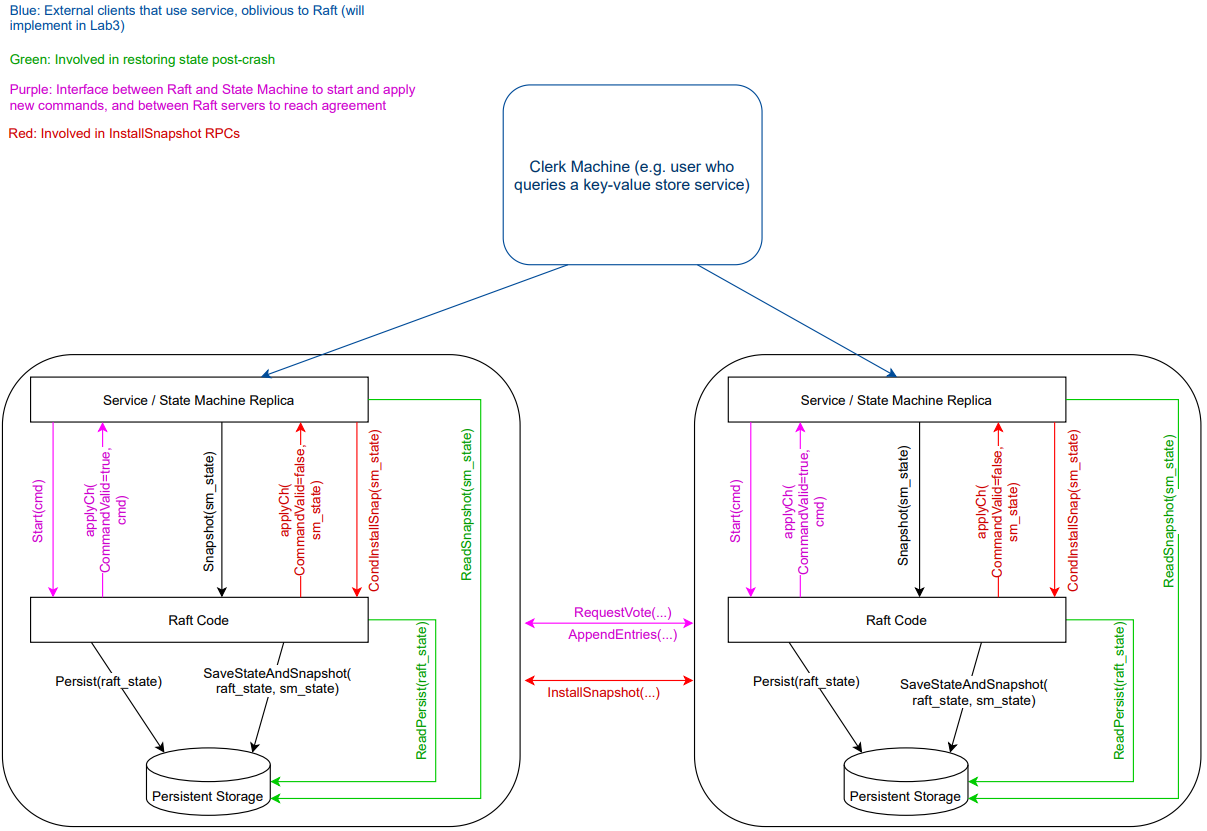
应用程序代码和 Raft 库:应用程序代码接收 RPC 或者其他客户端请求;不同节点的 Raft 库之间相互合作,来维护多副本之间的操作同步。
Log 是 Leader 用来对操作排序的一种手段。Log 与其他很多事物,共同构成了 Leader 对接收到的客户端操作分配顺序的机制。还有就是能够向丢失了相应操作的副本重传,也需要存储在 Leader 的 Log 中。而对于 Follower 来说,Log 是用来存放临时操作的地方。Follower 收到了这些临时的操作,但是还不确定这些操作是否被 commit 了,这些操作可能会被丢弃。对所有节点而言,Log 帮助重启的服务器恢复状态
避免分割选票:为选举定时器随机地选择超时时间。
broadcastTime ≪ electionTimeout ≪ MTBF(mean time between failures)
RAFT 与应用程序交互:
实验内容
实现 RAFT,分为四个 part:leader election、log、persistence、log compaction。
实验环境
OS:WSL-Ubuntu-18.04
golang:go1.17.6 linux/amd64
踩过的坑
- 死锁:if语句提前return,未释放锁;
- 发rpc前后都要check状态是否已经改变;
- 开启进程过多,导致程序运行缓慢,leader election时间延长,从而导致多次选举;这也就是为什么论文要求broadcastTime ≪ electionTimeout ≪ MTBF;这种情况主要每几千次测试发生一次;
- 多次测试!最好测试1w次;
- 代码后续更新在:https://github.com/BeGifted/MIT6.5840-2023
Part 2A: leader election
这部分主要实现选出一位领导人,如果没有失败,该领导人将继续担任领导人;如果旧领导人 fail 或往来于旧领导人的 rpc 丢失,则由新领导人接任。同时实现心跳定时发送。
raft、rpc格式
后续lab会增加内容。
type Raft struct {mu sync.Mutex // Lock to protect shared access to this peer's statepeers []*labrpc.ClientEnd // RPC end points of all peerspersister *Persister // Object to hold this peer's persisted stateme int // this peer's index into peers[]dead int32 // set by Kill()// Your data here (2A, 2B, 2C).// Look at the paper's Figure 2 for a description of what// state a Raft server must maintain.state int // follower\candidate\leadercurrentTerm int // last term server has seenvotedFor int // candidateId that received votelog []Entry // log entriescommitIndex int // index of highest entry committedlastApplied int // index of highest entry applied to state machinenextIndex []intmatchIndex []inttimeout time.DurationexpiryTime time.Time
}type RequestVoteArgs struct {// Your data here (2A, 2B).Term int //candidate termCandidateId intLastLogIndex intLastLogTerm int
}type RequestVoteReply struct {// Your data here (2A).Term int // currentTermVoteGranted bool
}type AppendEntriesArgs struct {Term int //leader termLeaderId intPrevLogIndex intPrevLogTerm intEntries []EntryLeaderCommit int // leader commitIndex
}type AppendEntriesReply struct {Term int // currentTermSuccess bool
}
RequestVote
- follower 一段时间未收到心跳发送 RequestVote,转为 candidate;
- candidate 一段时间未收到赞成票发送 RequestVote,维持 candidate;
- 接收 RequestVote 的 server:
- T < currentTerm:reply false;
- T >= currentTerm && votedFor is nil or candidateId && 日志较旧:reply true;转为 follower;
- else:reply false;
- RequestVoteReply:看返回的 term 如果比 currentTerm 大,转为 follower;否则计算投票数。
AppendEntries
- 心跳,不带 entries,维持 leader;
- 日志复制,在 last log index ≥ nextIndex[i] 时触发;
- 接收 AppendEntries 的server:
- term < currentTerm || prevLogIndex 上 entry 的 term 与 prevLogTerm 不匹配:reply false;
- 删除冲突的 entries,添加 new entries;
- leaderCommit > commitIndex:commitIndex = min(leaderCommit, index of last new entry);
- AppendEntries 返回:
- 成功:更新 nextIndex[i]、matchIndex[i];
- 失败:减少 nextIndex[i],retry;
ticker
用于当某个 follower 一段时间未收到 AppendEntries 时,开启竞选 leader。
func (rf *Raft) ticker() {for rf.killed() == false {// Your code here (2A)// Check if a leader election should be started.if rf.state != Leader && time.Now().After(rf.expiryTime) {go func() { // leader selectionrf.mu.Lock()rf.state = Candidaterf.votedFor = rf.merf.currentTerm++timeout := time.Duration(250+rand.Intn(300)) * time.Millisecondrf.expiryTime = time.Now().Add(timeout)rf.persist()numGrantVote := 1 // self grantargs := RequestVoteArgs{Term: rf.currentTerm,CandidateId: rf.me,LastLogIndex: len(rf.log) - 1,LastLogTerm: rf.log[len(rf.log)-1].Term,}rf.mu.Unlock()for i := 0; i < len(rf.peers); i++ {if i == rf.me {continue}go func(i int) {reply := RequestVoteReply{}if ok := rf.sendRequestVote(i, &args, &reply); ok {rf.mu.Lock()if rf.state != Candidate || args.Term != reply.Term || args.Term != rf.currentTerm || reply.Term < rf.currentTerm {rf.mu.Unlock()return}if reply.Term > rf.currentTerm {rf.state = Followerrf.currentTerm = reply.Termrf.votedFor = -1rf.persist()} else if reply.VoteGranted {numGrantVote++if numGrantVote > len(rf.peers)/2 {rf.mu.Unlock()rf.toLeader()return}}rf.mu.Unlock()}}(i)}}()}// pause for a random amount of time between 50 and 350// milliseconds.ms := 50 + (rand.Int63() % 30)time.Sleep(time.Duration(ms) * time.Millisecond)}
}
heart beat
func (rf *Raft) heartBeat() {for rf.killed() == false {rf.mu.Lock()if rf.state != Leader {rf.mu.Unlock()return}rf.mu.Unlock()for i := 0; i < len(rf.peers); i++ {if i == rf.me {continue}go func(i int) {rf.mu.Lock()if rf.state != Leader {rf.mu.Unlock()return}log.Println(i, "rf.nextIndex[i]", rf.nextIndex[i], "len", len(rf.log))args := AppendEntriesArgs{Term: rf.currentTerm,LeaderId: rf.me,PrevLogIndex: rf.nextIndex[i] - 1,PrevLogTerm: rf.log[rf.nextIndex[i]-1].Term,Entries: []Entry{},LeaderCommit: rf.commitIndex,}reply := AppendEntriesReply{}rf.mu.Unlock()var o boolif ok := rf.sendAppendEntries(i, &args, &reply); ok {rf.mu.Lock()o = okif rf.state != Leader || args.Term != reply.Term || args.Term != rf.currentTerm || reply.Term < rf.currentTerm {rf.mu.Unlock()return}if reply.Term > rf.currentTerm {rf.state = Followerrf.currentTerm = reply.Termrf.votedFor = -1rf.persist()rf.mu.Unlock()return}if reply.Success {rf.nextIndex[i] = args.PrevLogIndex + len(args.Entries) + 1rf.matchIndex[i] = args.PrevLogIndex + len(args.Entries)} else {rf.nextIndex[i] = args.PrevLogIndex}rf.mu.Unlock()}log.Println(rf.me, "send AppendEntries to", i, o, ": currentTerm=", rf.currentTerm, "reply.Term=", reply.Term, "reply.Success", reply.Success)}(i)}time.Sleep(time.Duration(50) * time.Millisecond)}
}
实验结果
测试10000次: