
分布式存储系统的复杂性涉及数据容灾备份、一致性、高并发请求和大容量存储等问题。本文结合CnosDB在分布式环境下的演化历程,分享如何将分布式理论应用于实际生产,以及不同实现方式的优缺点和应用场景。
分布式系统架构模式
分布式存储系统下按照数据复制方式的不同,常分为两种模式:主从模式、无主节点模式。
主从模式
主从模式以Raft分布式算法为代表,Raft 算法是 Diego Ongaro 和 John Ousterhout 于 2013 年发表的《In Search of an Understandable Consensus Algorithm》中提出;从工程案例etcd实现之后,Raft算法开始大放异彩。

Raft分布式算法流程
无主模式
无主模式以亚马逊的Dynamo模型为代表,其理论来源于亚马逊在2007年发表的《Dynamo: Amazon’s Highly Available Key-value Store》,在该论文中论述了一种无主节点的数据库设计方案,像Cassandra、Riak等都是基于此理论实现。
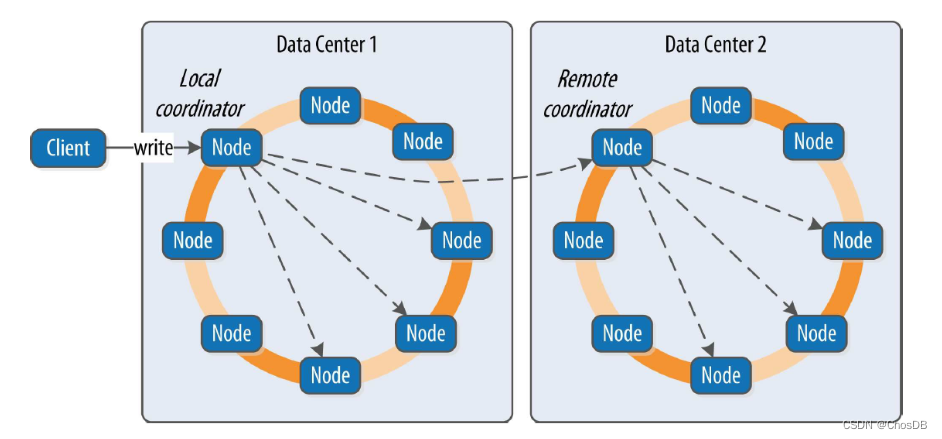
Cassandra数据写入流程
CnosDB整体架构
CnosDB 架构中主要包括了两类进程: cnosdb、cnosdb-meta。cnosdb负责数据的写入、查询、以及存储;cnosdb-meta负责元数据存储,像用户、租户、Database、Table、以及数据分布等相关信息。

Meta服务
CnosDB的Meta服务是有主节点的分布式系统,通过 Raft 一致性协议实现的供CnosDB使用的一套分布式配置中心。作为配置中心要求具有较高的数据一致性,在有主模式下较容易实现这一点,这是我们采用有主模式实现Meta服务的主要原因。
CnosDB对访问频繁的Meta数据在本地有一份Cache,正常情况下直接访问本地Cache,降低用户的请求时延以及对Meta服务的访问压力;通过订阅Meta服务的数据变更日志来更新本地缓存数据。
上面提到Meta数据的本地缓存是通过订阅变更的方式进行同步,这必然会带来本地缓存与Meta服务数据不一致性的问题。对于这个问题我们根据对数据的不同使用场景做了不同处理;在可以容忍这种不一致性的地方直接读取本地缓存,像绝大多数的正常的读写流程都不需要访问Meta服务,这极大降低了用户访问时延;如果需要高度一致性的场景直接访问Meta服务获取最新的数据,像创建数据库、表结构的变更等。
CnosDB服务
CnosDB服务负责数据的写入、读取和存储,是一套类Dynamo的无主节点存储系统。
CnosDB按照两个维度对数据进行分片存储:时间分片与Hash分片。
时间分片:由于时序数据库本身的特征,按照时间维度进行分片有其天然的优势。CnosDB每隔一段时间创建一个Bucket,每个Bucket都有起始、结束时间用于存储对应时间段内的数据。每当系统容量不足时,添加新的存储节点;在创建新的Bucket时也将优先使用空闲容量最多的新节点,已有数据也不需要移动,这完美地解决了集群扩容与数据存储容量的问题。
Hash分片:时间分片完美地解决了存储容量的问题;在一个分布式集群环境下,会有多台机器提供服务,如若每个Bucket只分布在一台机器节点上,则整个系统的写入性能受限于单台机器。时序数据库还有另外一个概念是SeriesKey,按SeriesKey进行Hash分片可以分割成不同的ReplicaSet(复制组),每个ReplicaSet内的一个副本称其为Vnode,每个Vnode分散在不同的存储节点上,一个ReplicaSet内的多个Vnode按照类Dynamo方式进行副本间数据同步;Vnode是CnosDB进行数据分片管理的基本单元,采用Hash分片的方式解决了系统吞吐量的问题。
如下图所示,在时间维度上每隔一段时间创建一个Bucket,每个Bucket有两个复制组(用不同颜色来区分),每个复制组有两个副本(一个Bucket内相同颜色的Vnode有两个)分别落在不同的存储节点上。

当前面临问题
按照时间、Hash两个维度进行分片解决分布式存储下容量与性能问题;但由于每个复制组内的数据复制方式是类Dynamo的无主节点模式,这带来一些新问题:
数据一致性:在无主节点的分布式存储系统中解决数据不一致性问题方式也有很多,像Cassandra中采用以最后写入者为准,Riak中的向量时钟等;再配合读修复、反熵、提示移交(Hinted Handoff)等一整套机制达到数据的最终一致性。这一整套机制实现起来是较为复杂的,也会极大拖累系统的整体性能,CnosDB当前也只是实现了部分机制。
数据订阅与同步:在无主节点的分布式存储系统中由于数据写入无顺序性,这导致做数据订阅也是一个难以解决的问题。在无主节点的模式中数据写入的统一的入口就是计算节点的接口层,但是在计算存储分离的强大背景下,通常计算层都是无状态的,在这一层做数据订阅难以保证订阅服务不丢失数据。
当Raft遇上CnosDB
为解决上述问题,我们转投有主模式寻求解决方案。
半同步方案:最开始我们参考Kafka设计了一个半同步方案。在Kafka中通过下面几个参数来控制服务在不同模式下运行,给用户灵活自由的选择。(不熟悉的读者,具体参数含义可以查阅网络信息)
- acks
- 复制因子(副本数)
- min.insync.replicas
此方案最大优点就是灵活,用户需要什么样的一致性、可靠性等级系统都可以通过参数进行配置;我们考虑到实现的难度、时间关系以及之后的稳定性,暂停了此方案。
其他方案:我们还讨论了主备节点的方案;由于CnosDB系统是多租户的,每个租户甚至每个Database要求的副本数都不一致,导致有些副本节点比较空闲、而像主节点则会压力比较大,造成机器间负载不均衡,资源的浪费等。
最终,我们选择了成熟的Raft方案,确切说是Multi-raft的方式,CnosDB中每个ReplicaSet都是一个Raft复制组。
为什么选择Raft
自采用Raft共识算法实现的etcd发布以后,Raft算法被公认为易于理解、相对易于实现的一套分布式共识算法,在数据的一致性、稳定性、可靠性等方面都得到众多产品的验证。
Raft是有主模式,会很好满足对数据一致性的要求;同时做数据订阅也极其容易(一种方式是作为集群的Learner节点存在,再一种方式是直接读取 Raft Logs)。
再就是CnosDB的Meta服务已经采用Raft。CnosDB主程序再也没有理由不去拥抱Raft。
关于Raft开源社区也有众多开源实现,几乎成为当前分布式系统下的标准算法,我们也并没有必要从头开始造轮子,而是选择了openraft方案。
Raft在CnosDB中应用
在CnosDB 中一个ReplicaSet就是一个Raft复制组,一个ReplicaSet由分布在不同机器上的多个Vnode副本组成,这些Vnode便构成了该Raft复制组的成员节点。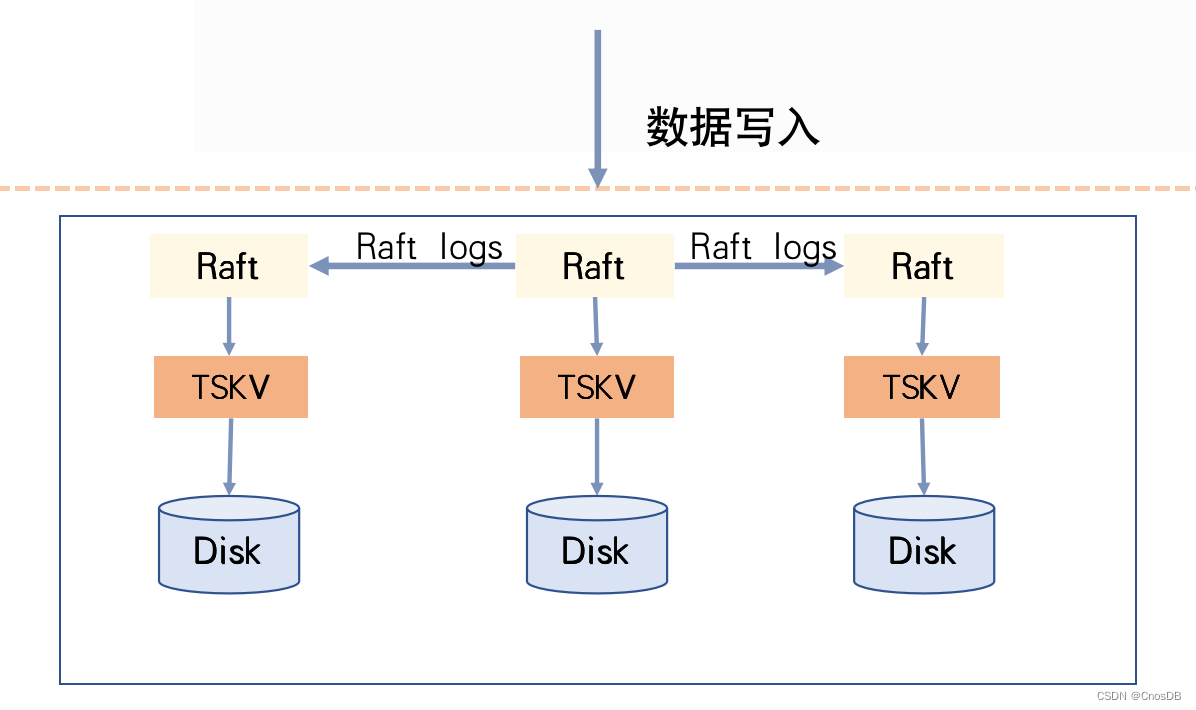
Raft在CnosDB中使用
数据写入过程:在CnosDB中每次写入都对应Raft复制组中的一次提交。服务接收到请求后判断本节点是否是此次写入对应Raft复制组的主节点,不是则进行请求转发;如果是则通过Raft协议进行写入,按照Raft协议在每个Vnode节点下产生一条Raft Log Entry,CnosDB会以WAL的形式记录到此Vnode目录下。
有超过半数Vnode节点记录WAL成功后,由Raft协议驱动进入下一个阶段——Apply阶段;在CnosDB中Apply阶段较为简单,只是写Memcache,主节点Apply成功后就响应客户端成功。
服务重启后Memcache中的数据通过WAL进行恢复。Memcache是由上层的Raft协议驱动刷盘,每次Memcache的刷盘都是作为一个Snapshot而存在。
更详细的过程可以参考Raft协议相关文档。
数据读取过程:根据查询条件,数据读取最终会落到每个Vnode上。在CnosDB的计划中是优先读取主节点的Vnode,这会带来较高的数据一致性;由于CnosDB是一个Multi-raft实现方式,主节点是分散在各个节点并不会造成主从节点负载不均匀的问题。
新的问题
Raft共识算法在如下场景下并没有说明如何处理:
- 读写Raft log发生错误
- Apply时发生错误
上述两项错误通常为IO错误,发生上述错误时系统将陷入一种未知的状态,当前CnosDB的做法是尽量提前预检查规避错误的发生,也参考了etcd的处理方式如果遇到不可处理的未知场景,将由人工介入处理。
启用Raft算法
在配置文件中只需要把配置项using_raft_replication设置为true即可。
using_raft_replication = true总结
CnosDB在2.4版本中引入Raft共识算法,在保住了CnosDB高性能、高可用性、易维护性的提前下,将会使得CnosDB 查询具有更高的数据一致性,同时为后面待实现的数据订阅、同步、数据异构处理做足了前期准备。
随着CnosDB各项功能的完善,未来将会在更广泛的使用场景中发挥更大的作用。后期我们会推出更多的测试报告、以及使用场景供大家参考,欢迎各位关注我们,我们共同成长。
CnosDB简介
CnosDB是一款高性能、高易用性的开源分布式时序数据库,现已正式发布及全部开源。
欢迎关注我们的社区网站:https://cn.cnosdb.com
)

覆盖优化 - 附代码)












)



