【ChatGLM2-6B】小白入门及Docker下部署
- 一、简介
- 1、ChatGLM2是什么
- 2、组成部分
- 3、相关地址
- 二、基于Docker安装部署
- 1、前提
- 2、CentOS7安装NVIDIA显卡驱动
- 1)查看服务器版本及显卡信息
- 2)相关依赖安装
- 3)显卡驱动安装
- 2、 CentOS7安装NVIDIA-Docker
- 1)相关环境准备
- 2)开始安装
- 3)验证&使用
- 3、 Docker部署ChatGLM2
- 1)下载对应代码包和模型包
- 2)上传至服务器并进行解压
- 3)下载镜像并启动容器
- 4)等待启动并访问页面
- 5)注意事项
- 三、开发环境搭建
- 1) 代码远程编辑配置
- 2) 一些基本的说明
- 2、接口调用方式
- 好了,开始你的探索吧~
一、简介
1、ChatGLM2是什么
- 一个类似于ChatGPT的智能文本对话模型,支持页面方式进行对话(ChatGLM3已经支持图片分析和生成,这里由于研究仅限于文本,因此选择GLM2)
- 支持训练与微调
- 代码开源
2、组成部分
-
模型:基本的模型矩阵,重量级的参数,大约十几个G,可以理解为是程序的初始化参数配置信息
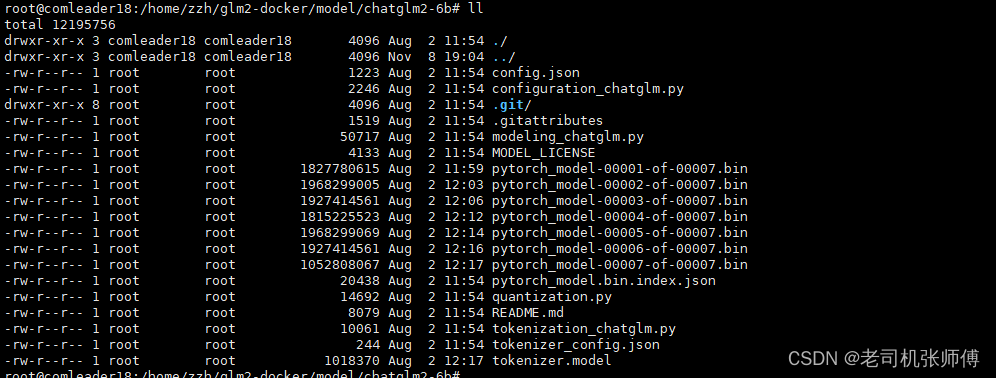
-
代码:加载模型的py代码,ChatGLM2已经封装好了多种加载和对话的方式,支持窗口对话、WEB页面对话、Socket对话、HTTP接口对话等方式。
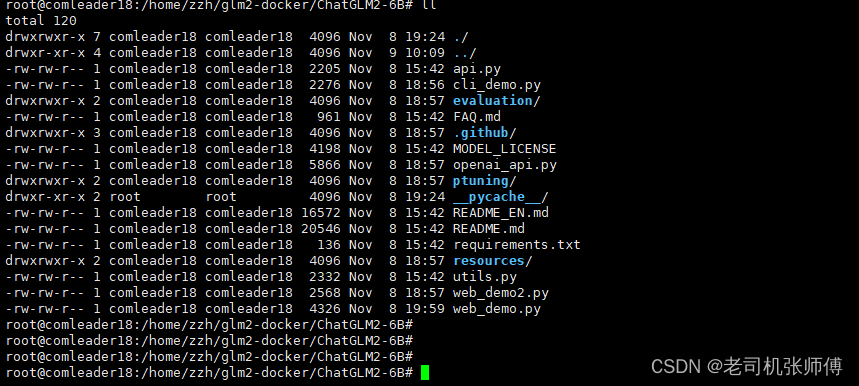
3、相关地址
- GitHub地址: https://github.com/THUDM/ChatGLM2-6B
- 国内模型下载地址:https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2F&mode=list
- 代码下载地址:https://github.com/THUDM/ChatGLM-6B
- docker下部署文档:https://www.luckzym.com/tags/ChatGLM-6B/
- windows下部署文档:https://github.com/ZhangErling/ChatGLM-6B/blob/main/deployment_windows.md
- 官方推荐指导手册:https://www.heywhale.com/mw/project/6436d82948f7da1fee2be59e
二、基于Docker安装部署
1、前提
-
安装了docker
-
16G以上显卡
2、CentOS7安装NVIDIA显卡驱动
-
先查看显卡是否已经安装,没有安装再进行安装,已安装就跳过此步
nvidia-smi # 如下图是已安装
如果没有相关信息,再进行显卡的安装。
1)查看服务器版本及显卡信息
# Linux查看显卡信息:(ps:若找不到lspci命令,可以安装 yum install pciutils)
lspci | grep -i vga# 使用nvidia GPU可以:
lspci | grep -i nvidia# 查看显卡驱动
cat /proc/driver/nvidia/version
- 系统:CentOS7 Linux
- 显卡:iGame GeForce RTX 3070 Ti Advanced OC 8G
2)相关依赖安装
- 安装依赖环境
yum install kernel-devel gcc -y
- 检查内核版本和源码版本,保证一致
ls /boot | grep vmlinu
rpm -aq | grep kernel-devel
- 屏蔽系统自带的
Nouveau
# 查看命令:
lsmod | grep nouveau
# 修改dist-blacklist.conf文件:
vim /lib/modprobe.d/dist-blacklist.conf
# 将nvidiafb注释掉:
blacklist nvidiafb # 然后添加以下语句:
blacklist nouveau
options nouveau modeset=0
可以在屏蔽之后重启系统并在命令行中输入lsmod | grep nouveau查看命令观察是否已经将其屏蔽。
- 重建
Initramfs Image步骤
mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.bak
dracut /boot/initramfs-$(uname -r).img $(uname -r)
- 修改运行级别为文本模式
systemctl set-default multi-user.target
- 重新启动
reboot
3)显卡驱动安装
- 去到NVIDIA官网下载对应的显卡驱动
网址:https://www.nvidia.cn/Download/index.aspx?lang=cn

在这里点击搜索即可弹出对应的下载软件包

- 开始安装其软件包
chmod +x NVIDIA-Linux-x86_64-525.105.17.run
./NVIDIA-Linux-x86_64-525.105.17.run
- 验证是否安装成功
nvidia-smi
到此CentOS7已完成NVIDIA显卡驱动的安装
2、 CentOS7安装NVIDIA-Docker
1)相关环境准备
在开始之前我们需要确保已经安装好了Docker的环境,并且也安装了Docker Compose。
需要注意的是,因为
NVIDIA-Docker软件的存在,我们不需要在宿主机上安装CUDA工具包,这样我们可以根据不同的需要选择合适的版本。
NVIDIA容器工具包对应的Github代码仓库地址:https://github.com/NVIDIA/nvidia-docker
2)开始安装
# 获得当前操作系统的发行版和版本,以便下载适用于NVIDIA Docker Toolkit的正确仓库
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)# 下载NVIDIA Docker Toolkit仓库,并将其保存为文件到/etc/yum.repos.d/目录中,使得包管理器够定位并安装工具包
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo# 使用yum安装nvidia-container-toolkit软件包
sudo yum install -y nvidia-container-toolkit# 重新启动Docker守护程序,以便它识别通过安装NVIDIA Docker Toolkit进行的新配置更改
sudo systemctl restart docker
3)验证&使用
# 在现有的GPU上启动启用GPU的容器,并运行nvidia-smi命令
docker run --gpus all nvidia/cuda:10.0-base nvidia-smi# 在两个GPU上启动启用GPU的容器,并运行nvidia-smi命令
docker run --gpus 2 nvidia/cuda:10.0-base nvidia-smi# 在特定的GPU上启动启用GPU的容器,并运行nvidia-smi命令
docker run --gpus '"device=1,2"' nvidia/cuda:10.0-base nvidia-smidocker run --gpus '"device=UUID-ABCDEF,1"' nvidia/cuda:10.0-base nvidia-smi# 这个命令演示了如何为容器指定能力(图形、计算等)
# 请注意,这种方式很少使用
docker run --gpus all,capabilities=utility nvidia/cuda:10.0-base nvidia-smi
3、 Docker部署ChatGLM2
1)下载对应代码包和模型包
链接:https://pan.baidu.com/s/1RhoYQ6wL5eJM8Qd0K4BYAg?pwd=zws4
提取码:zws4
2)上传至服务器并进行解压
解压完成后的目录如下
3)下载镜像并启动容器
注意:在线环境直接使用以下代码启动即可,离线环境需要先手动下载和加载woshikid/chatglm2-6b镜像,然后在使用docker进行启动
docker run --gpus all --runtime=nvidia \
-p 7860:7860 \
-p 8000:8000 \
-p 8501:8501 \
-p 80:80 \
-v ./ChatGLM2-6B:/ChatGLM2-6B \
-v ./model/chatglm2-6b:/chatglm2-6b \
--name chatglm2-webdemo \
-dit woshikid/chatglm2-6b \
python web_demo.py
其中,-p表示端口映射,物理机的7860端口会映射容器的7860端口,这个端口是web页面的端口
-v后跟的参数表示将物理机上的对应目录映射进入docker容器中
以下是启动的不同的访问方式和端口信息:
woshikid/chatglm2-6b python cli_demo.py # 小黑窗口对话
-p 8000:8000 woshikid/chatglm2-6b python api.py # HTTP接口对话
-p 8000:8000 woshikid/chatglm2-6b python openai_api.py # HTTP接口对话
-p 7860:7860 woshikid/chatglm2-6b python web_demo.py # WEB页面对话
-p 8501:8501 woshikid/chatglm2-6b streamlit run web_demo2.py # streamlit框架的WEB页面对话
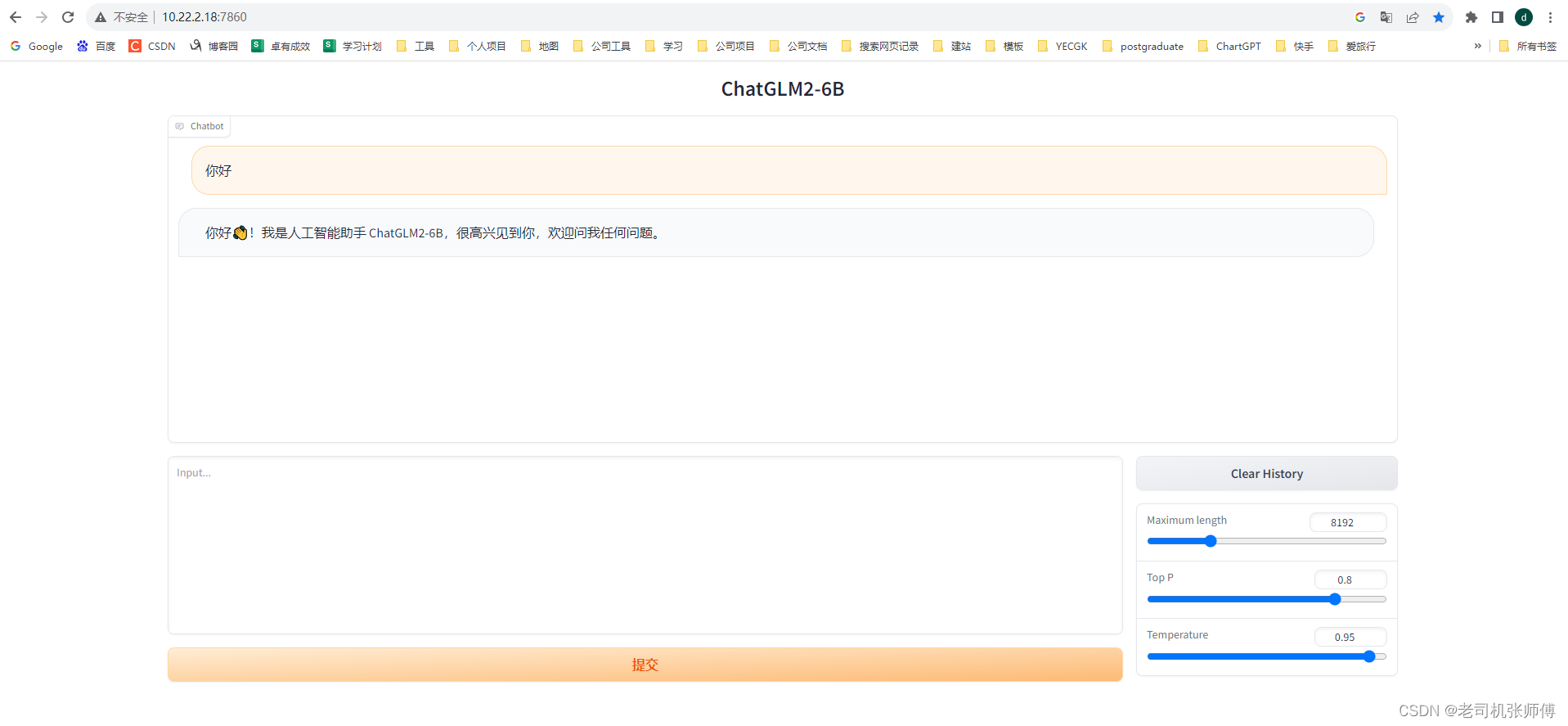
4)等待启动并访问页面
http://ip:7860即可进入对话页面
5)注意事项
通过nvidia-smi命令可以查看显卡使用情况
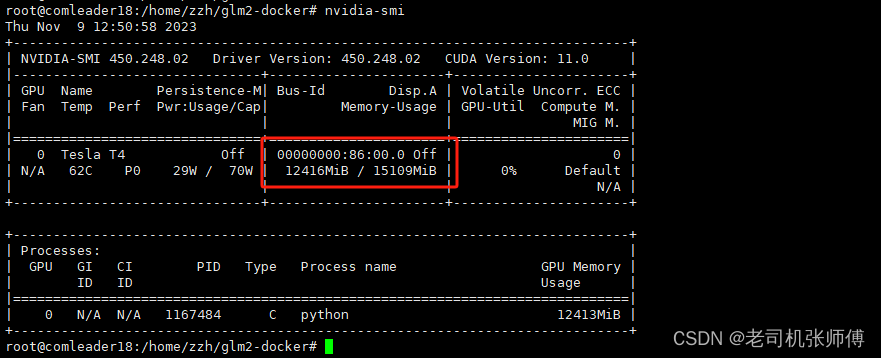
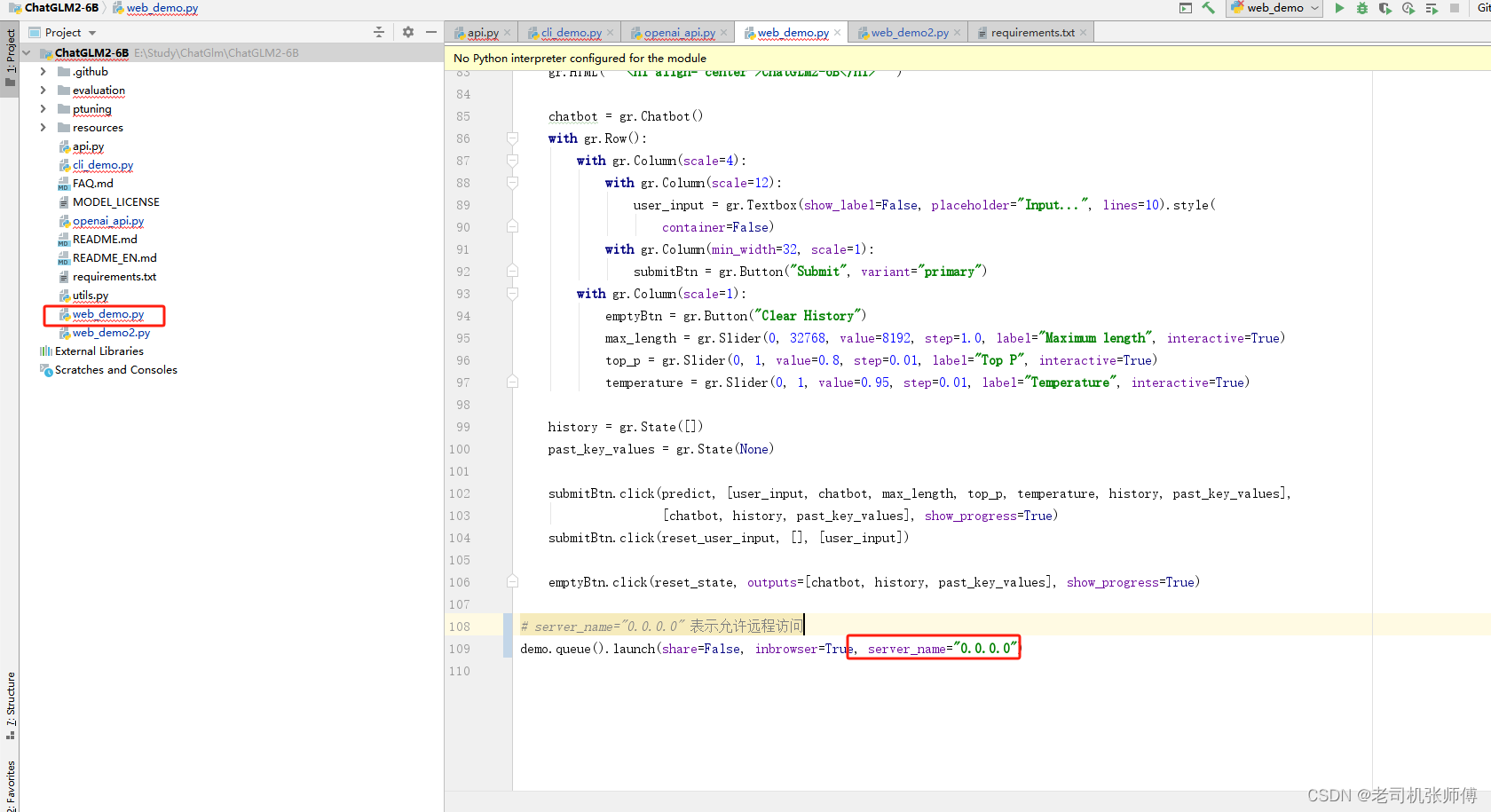
另外,如果是自己从github上下载的官方代码,需要修改下web_demo.py代码允许远程访问,否则默认会只允许本机访问。
三、开发环境搭建
1) 代码远程编辑配置
通常,本地的代码开发机器性能不足以支持ChatGLM2-6B的运行,但是在服务器上去编辑代码又十分的不方便,因此使用一种可以远程开发的方法来进行开发。下面是对这种方法的步骤介绍:
各种开发工具基本上都有这种功能,这里以Idea或者PyCharm开发工具来说明,其原理是本地开发后,利用SFTP将代码推送到远程服务器来进行对应的调试。
1)首先打开IDEA或PyCharm开发工具,打开我们的代码。
2)打开开发环境配置。
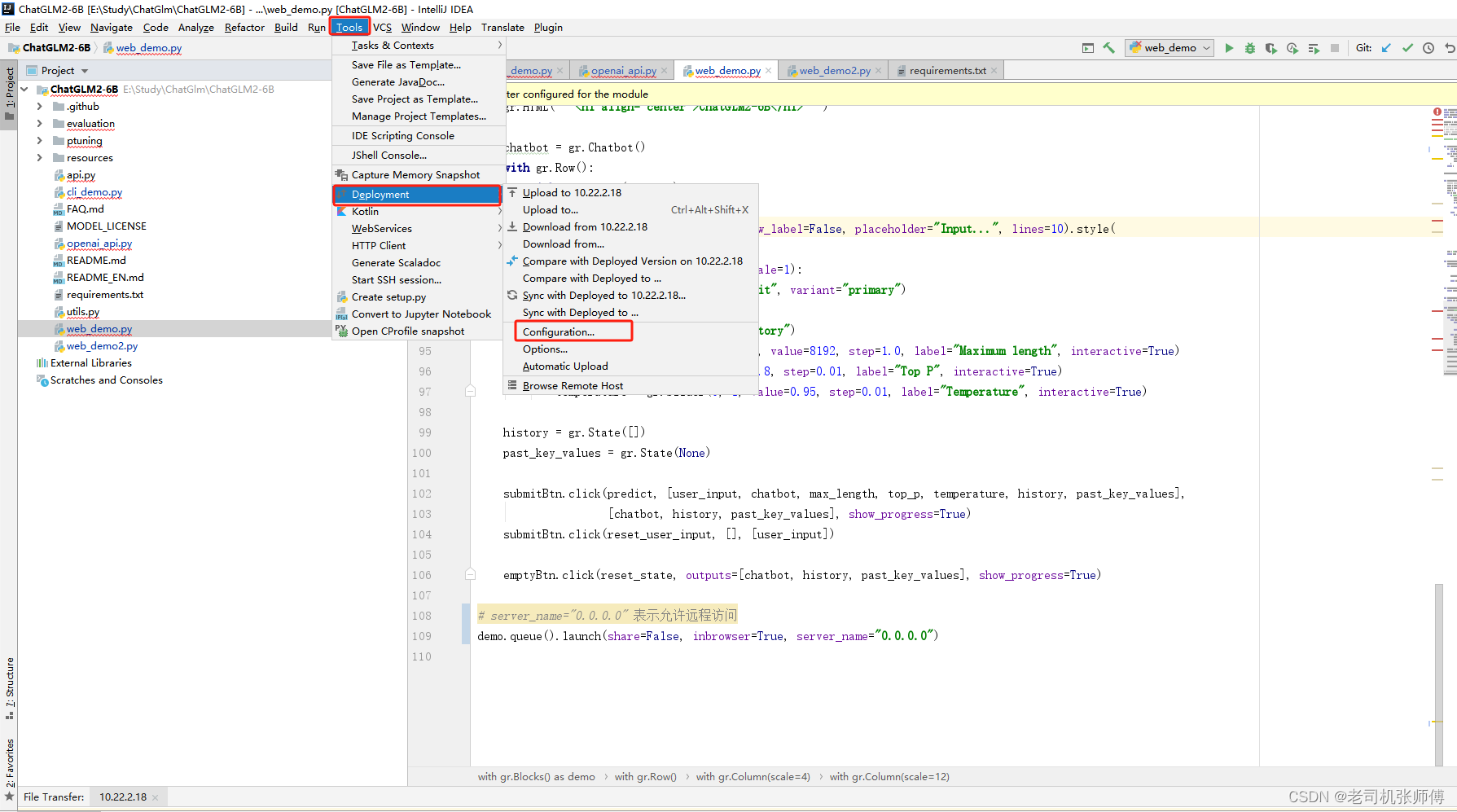
3)新建一个SFTP配置,并在Connection中填写服务器连接配置信息。
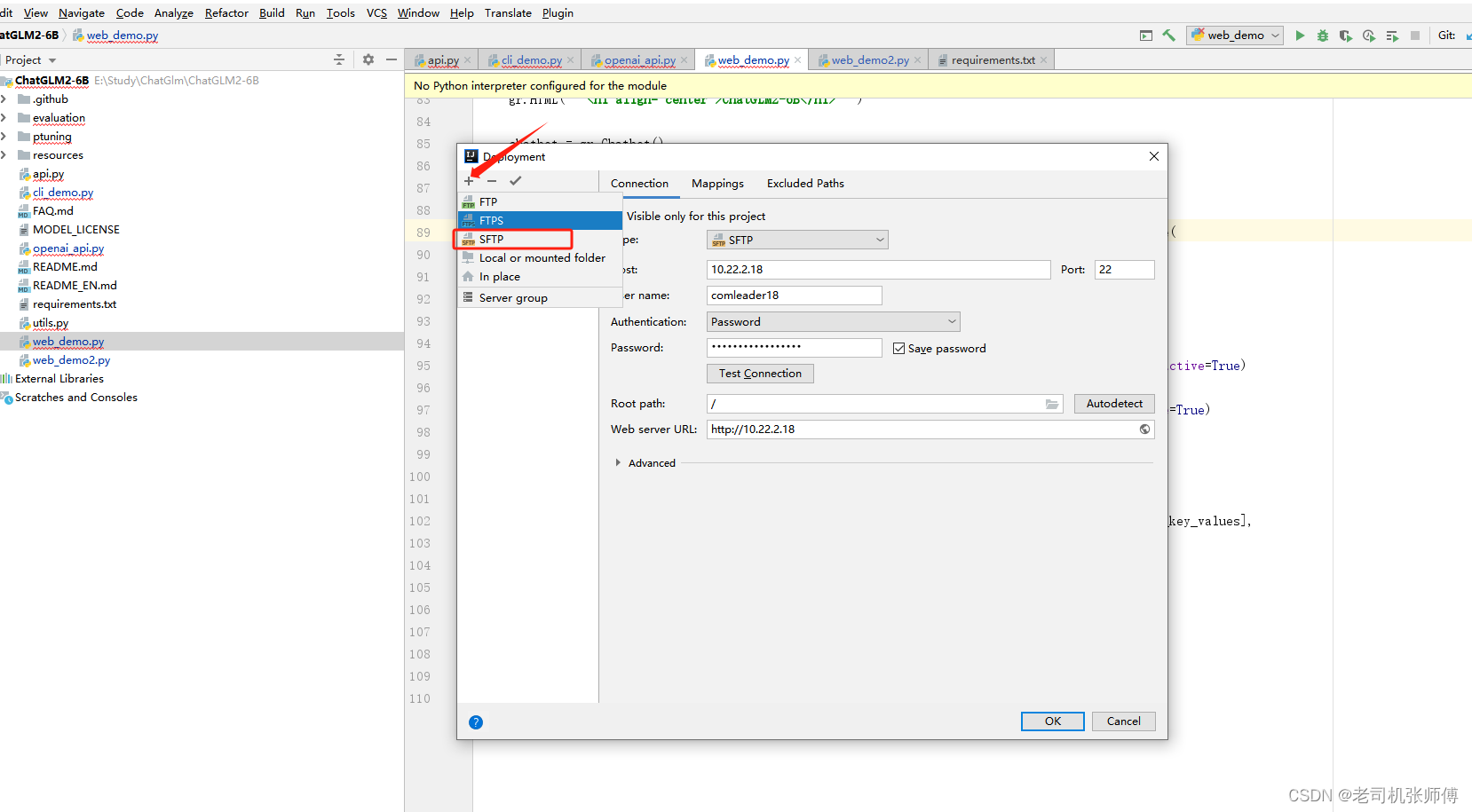
4)点击Mappings,将本地的代码地址和服务器上的代码地址做映射,这里服务器上的代码地址是我们ChatGLM-6B的地址,用于映射到容器内部,然后点击确认。
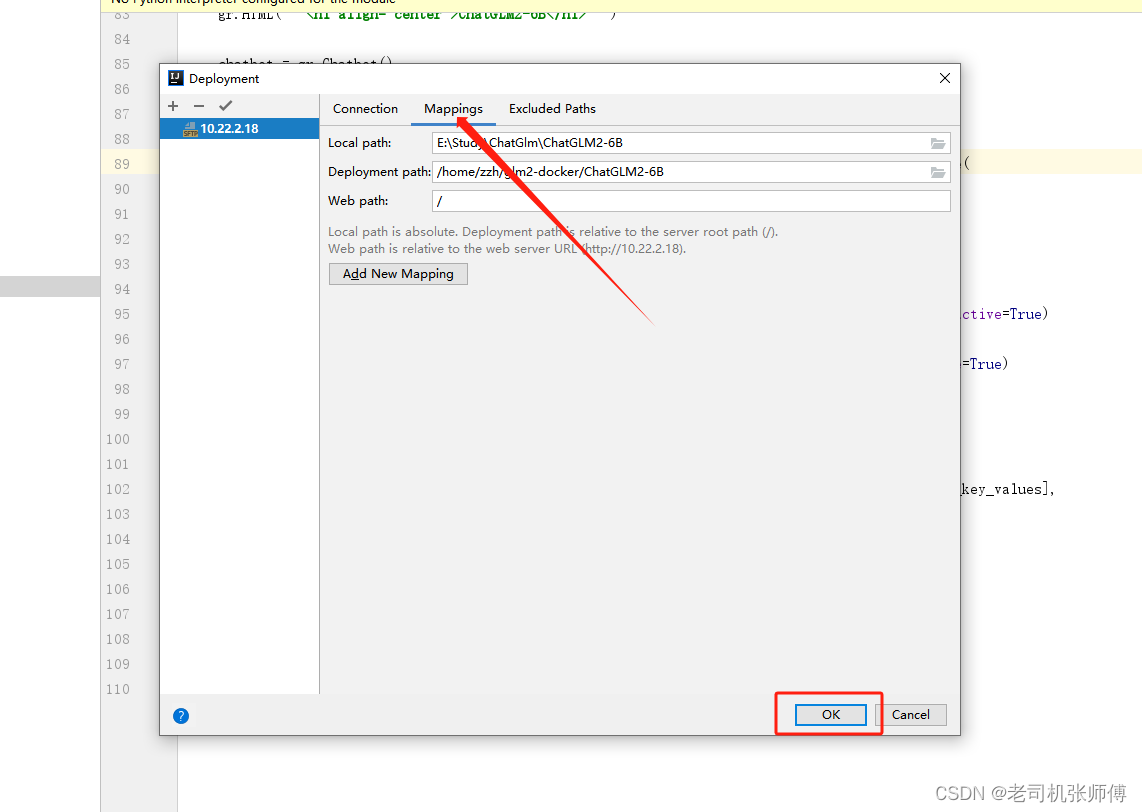
5)代码推送。
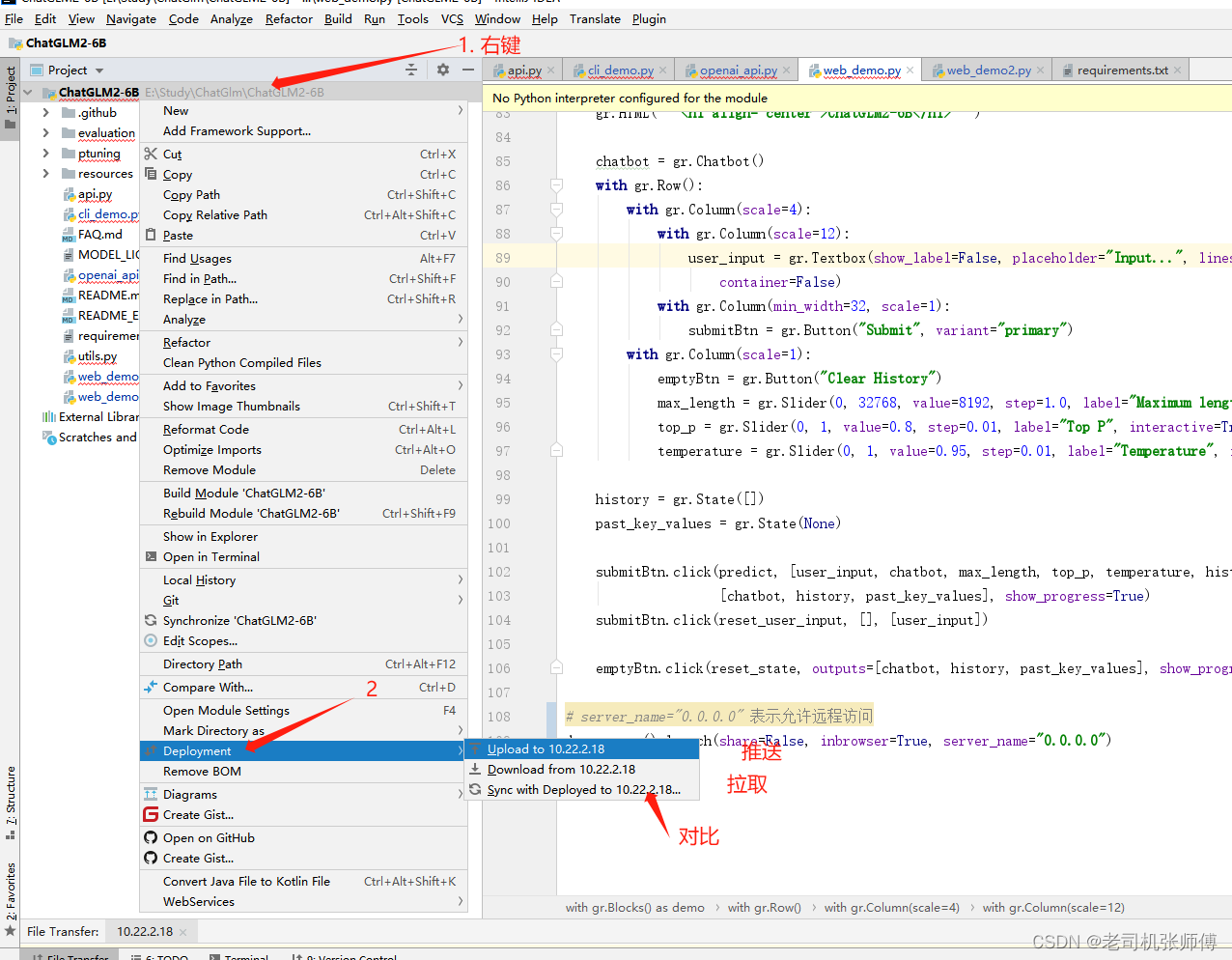
6)这样,就可以实现本地编写代码,推送到远程进行调试了,十分的便捷。
报错的信息不用管,因为本地没有环境,所以只能当编辑器使用。
2) 一些基本的说明
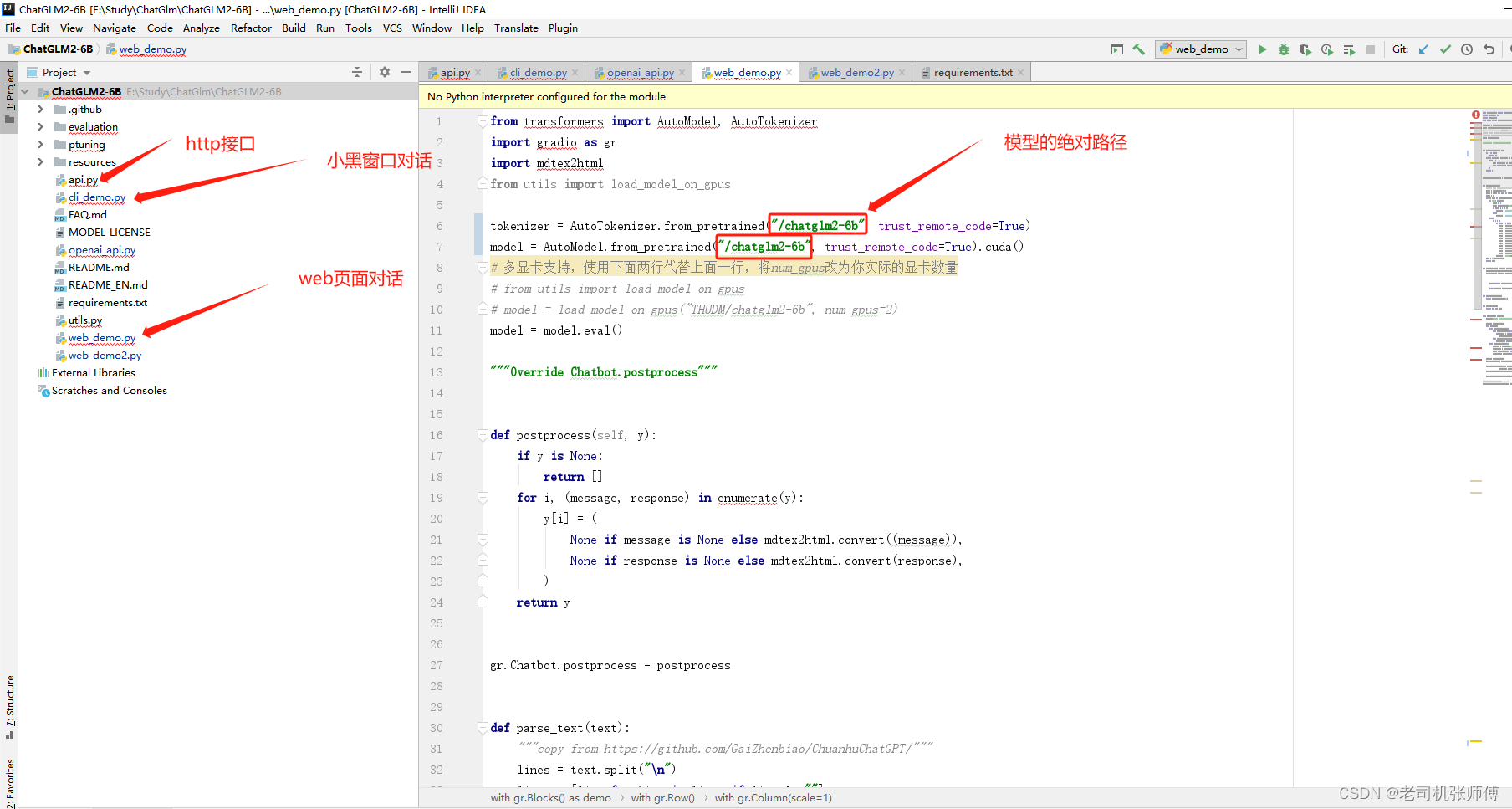
2、接口调用方式
curl -X POST "http://127.0.0.1:8000" \-H 'Content-Type: application/json' \-d '{"prompt": "你好", "history": []}'
回复的内容:
{"response":"你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。","history":[["你好","你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。"]],"status":200,"time":"2023-03-23 21:38:40"
}

)


-卷积神经网络)







111. 二叉树的最小深度)
)





)