介绍
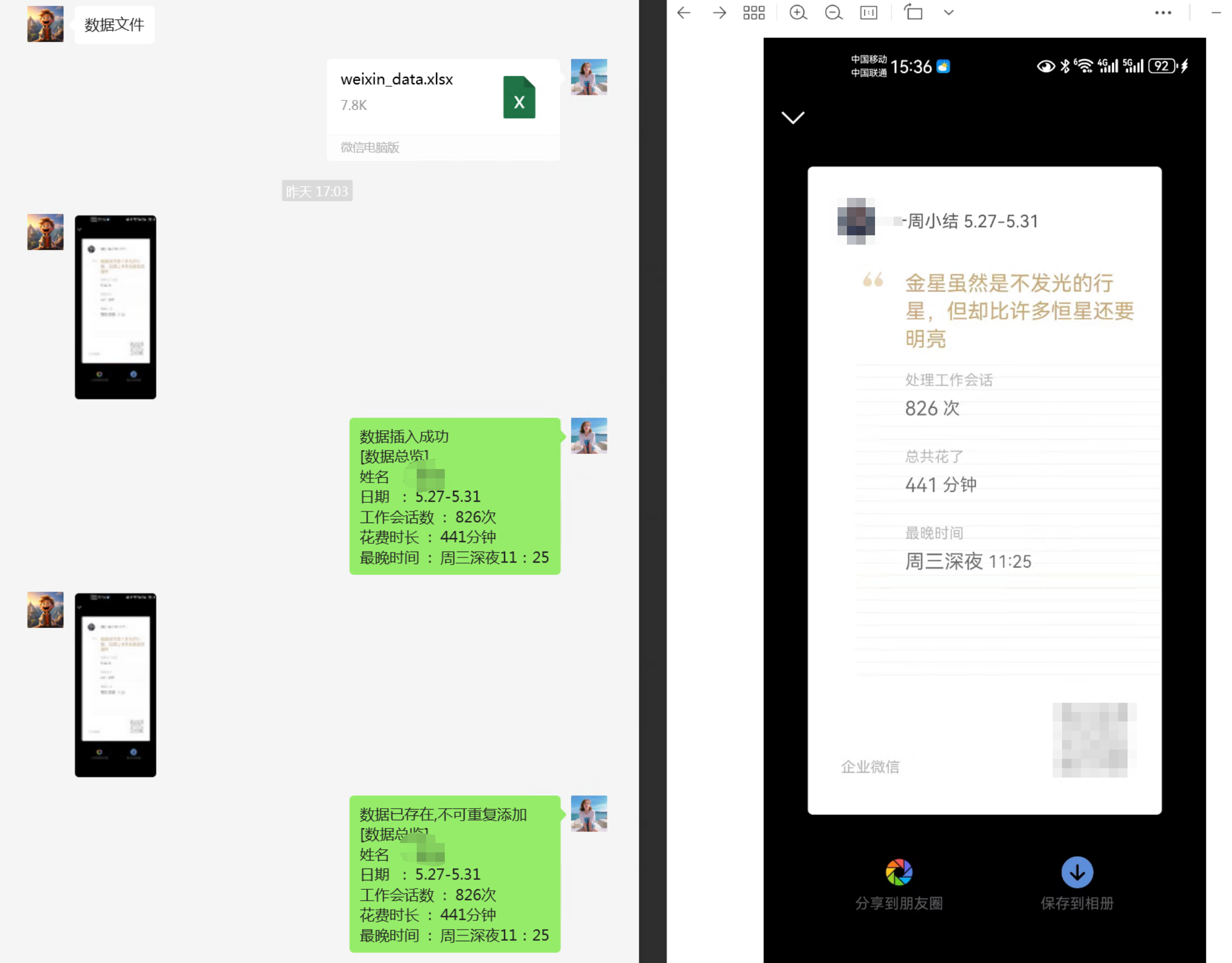
采用微信的hook插件,然后解析微信发来的数据图片,通过ocr识别 然后将数据落入execl表格中。同时有权限的人可以导出数据表格即可。
流程图
代码片
文本消息处理流程_robot.py
elif msg.type == 0x01: # 文本消息# 管理员列表dba_user_list = ['wxid_uev4klri3snh22','zhangzijian0715','yanheng1984','wxid_30173uk0ohjd21']# 8812131740734078818 id字段# 'wxid_uev4klri3snh22' sender字段 我的WXIDself.LOG.info("发送人的ID:" + msg.sender + ",发送内容:" + msg.content)# 管理员的特殊权限if msg.sender in dba_user_list:if msg.content.startswith('数据文件'):# 发送文件self.wcf.send_file(data_execl_path,msg.sender)elif msg.content.startswith('添加人员'):# 保存数据的字典data_dict = {}data_list = msg.content.split()if len(data_list) == 4:data_dict['user_name']= data_list[1]data_dict['user_department']= data_list[2]data_dict['user_wxid']= data_list[3]insert_data_result, insert_cause_str = insert_user_data_info(data_dict)if insert_data_result == False:insert_fail_info = ('数据插入失败,请联系管理员处理,cause: ' + insert_cause_str)self.sendTextMsg(insert_fail_info, msg.sender)returnelse:insert_success_info = ('数据插入成功')self.sendTextMsg(insert_success_info, msg.sender)returnelse:self.sendTextMsg('数据格式错误',msg.sender)returnreturn# 让配置加载更灵活,自己可以更新配置。也可以利用定时任务更新。# if msg.from_self():# if msg.content == "^更新$":# self.config.reload()# self.LOG.info("已更新")# else:# self.toChitchat(msg) # 闲聊
图片消息处理流程_robot.py
elif msg.type == 3: # 图片消息try:##### 判断用户是否属于授权用户user_name = get_user_name_info_by_wxid(msg.sender)if not user_name:self.sendTextMsg('你的账号暂未授权,请联系管理员授权账号\nwxid = ' + msg.sender, msg.sender)return# msg.extra字段为完整图片的dat路径,需要进行图片解密转换,另一个字段属于缩略图# DONE sleep是为了给图片预留落盘的时间,不然会识别不到文件time.sleep(1)###### 下载Image目录的图片并返回图片地址current_datetime = datetime.datetime.now()formatted_datetime = current_datetime.strftime("%Y_%m").strip()# temp_pic目录的路径target_path = os.path.join(os.path.join(os.getcwd(), 'temp_pic'), formatted_datetime)if not os.path.exists(target_path):os.makedirs(target_path)self.wcf.download_image(msg.id, msg.extra, target_path)##### 根据图片地址OCR解析需要的内容## 标准精度识别# data_dict = ocr_wx_pic(os.path.join(target_path, pic_name).replace('.dat', '.jpg'))## 高精度的ORC识别pic_name = os.path.basename(msg.extra)new_pic_path = os.path.join(target_path, pic_name).replace('.dat', '.jpg')if not os.path.exists(new_pic_path):self.sendTextMsg('当前网络繁忙,图片解析失败,请稍后重试', msg.sender)self.LOG.error('当前网络繁忙,图片解析失败,请稍后重试,如有疑问请联系管理员')return### 加一层过滤 防止OCR识别发生错误或者异常图片不符合规范data_dict = ocr_wx_pic_hign(new_pic_path)if data_dict == None:self.sendTextMsg('图片不符合规范,请上传本周小结的内容', msg.sender)self.LOG.error('图片不符合规范,请上传本周小结的内容,如有疑问请联系管理员')return#### 判断数据是否已经录入数据库中,如果未录入则录入data_is_exit = get_user_week_info_is_exit(data_dict['week_date'], user_name)data_dict['user_name'] = user_nameif data_is_exit == False:insert_data_result,insert_cause_str = insert_user_week_data_info(data_dict)if insert_data_result == False:insert_fail_info = ('数据插入失败,请联系管理员处理,cause: '+insert_cause_str+"\n"+ '[数据总览]\n'+ '姓名 : ' + user_name + "\n"+ '日期 : ' + data_dict['week_date'] + "\n"+ '工作会话数 : ' + str(data_dict['week_work_num']) + "次\n"+ '花费时长 : ' + str(data_dict['week_work_total_min']) + "分钟\n"+ '最晚时间 : ' + data_dict['week_final_last_time'])self.sendTextMsg(insert_fail_info, msg.sender)returnelse:send_succ_info = ('数据插入成功\n'+ '[数据总览]\n'+ '姓名 : ' + user_name + "\n"+ '日期 : ' + data_dict['week_date'] + "\n"+ '工作会话数 : ' + str(data_dict['week_work_num']) + "次\n"+ '花费时长 : ' + str(data_dict['week_work_total_min']) + "分钟\n"+ '最晚时间 : ' + data_dict['week_final_last_time'])# 对内容进行转换self.sendTextMsg(send_succ_info, msg.sender)returnelse:# 对内容进行转换repeat_info = ('数据已存在,不可重复添加\n'+ '[数据总览]\n'+ '姓名 : ' + user_name + "\n"+ '日期 : ' + data_dict['week_date'] + "\n"+ '工作会话数 : ' + str(data_dict['week_work_num']) + "次\n"+ '花费时长 : ' + str(data_dict['week_work_total_min']) + "分钟\n"+ '最晚时间 : ' + data_dict['week_final_last_time'])self.sendTextMsg(repeat_info, msg.sender)returnexcept Exception as e:self.sendTextMsg('图片处理失败,请联系管理员处理, cause ' + str(e), msg.sender)self.LOG.exception("图片处理失败,请联系管理员处理: %s", e)execl表格的代码处理_csv_util.py
import pandas as pd
import os
import logging
import datetime# data_path = os.path.join(os.path.dirname(os.path.dirname(os.getcwd())), 'data')data_path = os.path.join(os.getcwd(), 'data')
data_execl_path = os.path.join(data_path, 'weixin_data.xlsx')
user_execl_path = os.path.join(data_path, 'user_info.xlsx')
logs = logging.getLogger("csv_util")def read_excel(file_path):"""读取Excel文件并返回DataFrame"""try:os.chmod(file_path, 0o777)df = pd.read_excel(file_path)return dfexcept Exception as e:logs.error("Error reading Excel file: {} , cause {}",file_path, e)return Nonedef write_to_excel(file_path, new_row):"""将新数据写入Excel文件的最后一行"""try:df = read_excel(file_path)if df is not None:# df = df.append(data, ignore_index=True)df = pd.concat([df, new_row.to_frame().T], ignore_index=True)# 将数据写入with pd.ExcelWriter(file_path, engine='openpyxl', mode='a', if_sheet_exists='overlay') as writer:df.to_excel(writer, index=False, sheet_name='Sheet1')for key, value in new_row.items():logs.error(f"Key: {key}, Value: {value}")logs.info("Data written successfully. ")return True,Noneelse:for key, value in new_row.items():logs.error(f"Key: {key}, Value: {value}")logs.warning("Failed to read Excel file., file info {} ",file_path)return False,Noneexcept Exception as e:for key, value in new_row.items():logs.error(f"Key: {key}, Value: {value}")logs.exception("Error writing to Excel file., file info {} ,cause info {}",file_path, e)return False,str(e)def query_excel(file_path, field, value, return_field=None):"""根据指定字段查询数据"""try:df = read_excel(file_path)if df is not None:result = df[df[field] == value]if return_field:return_values = result[return_field]if not return_values.empty:return_values = ''.join([return_values.iloc[0]])else:return_values = ''.join(return_values)return str(return_values)return resultelse:logs.warning("Failed to read Excel file {} no found , field {} , value {} , return_field {}",file_path, field, value, return_field)return Falseexcept Exception as e:logs.exception("Error querying Excel file {} , field {} , value {} , return_field {}, cause {}",file_path, field, value, return_field, e)return False# 根据wxid获取用户的姓名
def get_user_name_info_by_wxid(wxid):return query_excel(user_execl_path, '微信唯一标识', wxid, '姓名')# 判断周报数据是否存在
def get_user_week_info_is_exit(data_str, user_name):result_df = query_excel(data_execl_path, '日期', data_str)if result_df is None:return Falsefirst_column_values = result_df['姓名'].valuesif user_name in first_column_values:return Trueelse:return False# 将人员数据入库
def insert_user_data_info(data_dict):current_datetime = datetime.datetime.now()formatted_datetime = current_datetime.strftime("%Y-%m-%d %H:%M:%S").strip()new_data = pd.Series({'姓名': data_dict['user_name'],'部门': data_dict['user_department'],'微信唯一标识': data_dict['user_wxid'],'入库时间': formatted_datetime,# 添加更多列数据})# 将数据转换为DataFrame## new_row = pd.Series(# [data_dict['user_name'], data_dict['week_date'], data_dict['week_work_num'], data_dict['week_work_total_min'],# data_dict['week_final_last_time'], data_dict['data_year'], formatted_datetime],# index=['姓名', '日期', '工作会话数', '花费时长', '最晚时间', '年份', '入库时间'])return write_to_excel(user_execl_path, new_data)# 将周报数据入库
def insert_user_week_data_info(data_dict):current_datetime = datetime.datetime.now()formatted_datetime = current_datetime.strftime("%Y-%m-%d %H:%M:%S").strip()new_data = pd.Series({'姓名': data_dict['user_name'],'日期': data_dict['week_date'],'工作会话数': data_dict['week_work_num'],'花费时长': data_dict['week_work_total_min'],'最晚时间': data_dict['week_final_last_time'],'年份': data_dict['data_year'],'入库时间': formatted_datetime,# 添加更多列数据})# 将数据转换为DataFrame## new_row = pd.Series(# [data_dict['user_name'], data_dict['week_date'], data_dict['week_work_num'], data_dict['week_work_total_min'],# data_dict['week_final_last_time'], data_dict['data_year'], formatted_datetime],# index=['姓名', '日期', '工作会话数', '花费时长', '最晚时间', '年份', '入库时间'])return write_to_excel(data_execl_path, new_data)# 示例用法
if __name__ == "__main__":# 通过wxid 判断是否有权限# result = get_user_name_info_by_wxid('wxid_uev4klri3snh22')result = get_user_week_info_is_exit(20240603, '高垣')if result is not None:print(result)# file_path = '/mnt/data/excel_file.xlsx' # 替换为你的Excel文件路径# excel_handler = ExcelHandler(file_path)## # 读取Excel文件# df = excel_handler.read_excel()# if df is not None:# print(df)## # 写入新数据# new_data = {# 'Column1': 'Value1',# 'Column2': 'Value2',# # 添加更多列数据# }# excel_handler.write_to_excel(new_data)## # 根据指定字段查询数据# result = excel_handler.query_excel('Column1', 'Value1')# if result is not None:# print(result)图片ocr的图片处理_baidu_ocr.py
import base64
import urllib
import requests
import json
import re
import datetime
import os
import logging
import datetimeAPI_KEY = "XXXX"
SECRET_KEY = "XXXX"logs = logging.getLogger("baidu_ocr")
def main():url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general?access_token=" + get_access_token()# image 可以通过 get_file_content_as_base64("C:\fakepath\15866dbd4118eb7638c9a13b430dadf1.jpg",True) 方法获取# payload = 'image=%2F9j%2F4AAQSkZJRgABAQAAAQABAAD%2F2wBDAAEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQ...&detect_direction=false&detect_language=false¶graph=false&probability=false'payload = 'image='+get_file_content_as_base64(r"E:\PythonCode\WeChatRobot\temp_pic\15866dbd4118eb7638c9a13b430dadf1.jpg",True)+"&detect_direction=false&detect_language=false&vertexes_location=false¶graph=false&probability=false"headers = {'Content-Type': 'application/x-www-form-urlencoded','Accept': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload)if(response.status_code==200):pic_str = json.loads(response.text)else:logs.error('接口请求失败。status_code {} , reason {}',response.status_code,response.reason)def get_file_content_as_base64(path, urlencoded=False):"""获取文件base64编码:param path: 文件路径:param urlencoded: 是否对结果进行urlencoded:return: base64编码信息"""with open(path, "rb") as f:content = base64.b64encode(f.read()).decode("utf8")if urlencoded:content = urllib.parse.quote_plus(content)# print(content)return contentdef get_access_token():"""使用 AK,SK 生成鉴权签名(Access Token):return: access_token,或是None(如果错误)"""url = "https://aip.baidubce.com/oauth/2.0/token"params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}return str(requests.post(url, params=params).json().get("access_token"))def ocr_wx_pic(pic_full_path):url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general?access_token=" + get_access_token()payload = 'image=' + get_file_content_as_base64(pic_full_path,True) + "&detect_direction=false&detect_language=false&vertexes_location=false¶graph=false&probability=false"headers = {'Content-Type': 'application/x-www-form-urlencoded','Accept': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload)if response.status_code == 200:#解析图片return parse_pic_data(response.text)else:print("接口请求失败。原因:" + response.reason)return None# 高精度版本
def ocr_wx_pic_hign(pic_full_path):url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic?access_token=" + get_access_token()payload = 'image=' + get_file_content_as_base64(pic_full_path,True) + "&detect_direction=false¶graph=false&probability=false"headers = {'Content-Type': 'application/x-www-form-urlencoded','Accept': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload)if response.status_code == 200:#解析图片return parse_pic_data(response.text)else:logs.error('接口请求失败。status_code {} , reason {}', response.status_code, response.reason)return Nonedef parse_pic_data(orcStr):# 解析json字符串pic_str = json.loads(orcStr)# 保存数据的字典data_dict = {}# TODO 50表示该图片不是需要识别图片if pic_str['words_result_num'] > 50 or pic_str['words_result_num'] < 5:return None# 循环List去除掉无关项,例如 手机图片头部信息 以及 尾部二维码等pic_list = pic_str['words_result']# 循环pic_listfor idx,pic in enumerate(pic_list):# print(f"pic: {pic}")if pic['words'].find('一周小结') != -1:data_dict['week_date'] = pic['words'].replace('一周小结', "")elif pic['words'].find('处理工作会话') != -1:data_dict['week_work_num'] = extract_integer(pic_list[idx+1]['words'])elif pic['words'].find('总共花了') != -1:data_dict['week_work_total_min'] = extract_integer(pic_list[idx+1]['words'])elif pic['words'].find('最晚时间') != -1:data_dict['week_final_last_time'] = pic_list[idx+1]['words']# 手动添加年份data_dict['data_year'] = datetime.datetime.today().yearif len(data_dict) != 5:return Nonereturn data_dictdef extract_integer(text):# 匹配字符串中的第一个整数部分match = re.search(r'\d+', text)if match:# 找到整数则返回整数值return int(match.group())else:# 如果未找到整数,则返回 None 或者其他你想要的默认值return Noneif __name__ == '__main__':pic_orc_str = '{"words_result":[{"words":"中国移动15:36●","location":{"top":23,"left":200,"width":257,"height":81}},{"words":"中国联通","location":{"top":70,"left":213,"width":96,"height":24}},{"words":"@86令959l92乡","location":{"top":46,"left":667,"width":370,"height":44}},{"words":"一周小结5.27-5.31","location":{"top":424,"left":309,"width":358,"height":44}},{"words":"66","location":{"top":573,"left":242,"width":49,"height":37}},{"words":"金星虽然是不发光的行","location":{"top":570,"left":343,"width":502,"height":51}},{"words":"星,但却比许多恒星还要","location":{"top":640,"left":343,"width":555,"height":51}},{"words":"明亮","location":{"top":710,"left":341,"width":100,"height":51}},{"words":"处理工作会话","location":{"top":813,"left":341,"width":218,"height":44}},{"words":"826次","location":{"top":880,"left":341,"width":136,"height":46}},{"words":"总共花了","location":{"top":998,"left":341,"width":143,"height":44}},{"words":"441分钟","location":{"top":1066,"left":341,"width":177,"height":46}},{"words":"最晚时间","location":{"top":1190,"left":343,"width":141,"height":37}},{"words":"周三深夜11:25","location":{"top":1251,"left":345,"width":307,"height":51}},{"words":"回叠回","location":{"top":1620,"left":718,"width":172,"height":54}},{"words":"企业微信","location":{"top":1756,"left":184,"width":146,"height":44}},{"words":"分享到朋友圈","location":{"top":2095,"left":218,"width":213,"height":33}},{"words":"保存到相册","location":{"top":2092,"left":674,"width":177,"height":37}}],"words_result_num":18,"log_id":1797510538274524905}'# pic_str = json.loads(json_str)parse_pic_data(pic_orc_str)# main()
部署流程
安装python_3.9
安装包有略过此过程
安装微信
- 先下载一个 3.9.10.19版本, 32位的。
- 登陆以后,设置里面点击 更新
- 升级到最新版,然后拿23版本 覆盖一下 就ok了
安装python依赖
4. 安装依赖
```sh
# 升级 pip
python -m pip install -U pip
# 安装必要依赖
pip install -r requirements_v1.txt
pip install baidu-aip
pip install pandas openpyxl
pip install xlrd
pip install pymem运行微信
```sh
python main.py# 需要停止按 Ctrl+C
已支持功能
- 图片ocr识别
- 添加人员
命令: 添加人员 xxx xxx服务部 wxid_huwcf7p637mxxx
- 查看execl文件
命令:数据文件 (仅管理员权限的人支持)


)
)


———附带BootCamp6驱动下载链接)
)




制造业数字化能力中心,赋能企业向数字化转型)

)
)
)


)