2021 年 9 月 8 日,StarRocks 开源社区诞生。从第一天开始,我们怀揣着“打造世界一流的数据分析产品”的梦想,踏上了星辰大海的征途。 两年间,StarRocks 在 GitHub 上收获了 5.4K Stars,产品共迭代发布了 90 余个版本,288 家市值超过 10 亿美元的头部用户在生产环境中上线运行。“不止步于极速”,StarRocks 更是在短短一年内完成了从全场景 OLAP 分析进化到云原生湖仓分析的进化。
StarRocks 突飞猛进的发展都要得力于社区用户的使用反馈和开发者们不断地帮 StarRocks 添砖加瓦,使其生态体系更加完善。在过去一年内,StarRocks 发布了 v2.5、v3.0、v3.1 三个重大的里程碑版本,其中存算分离、湖仓分析、物化视图等重量级特性, 为极速统一湖仓分析新范式的落地奠定了坚实基础。 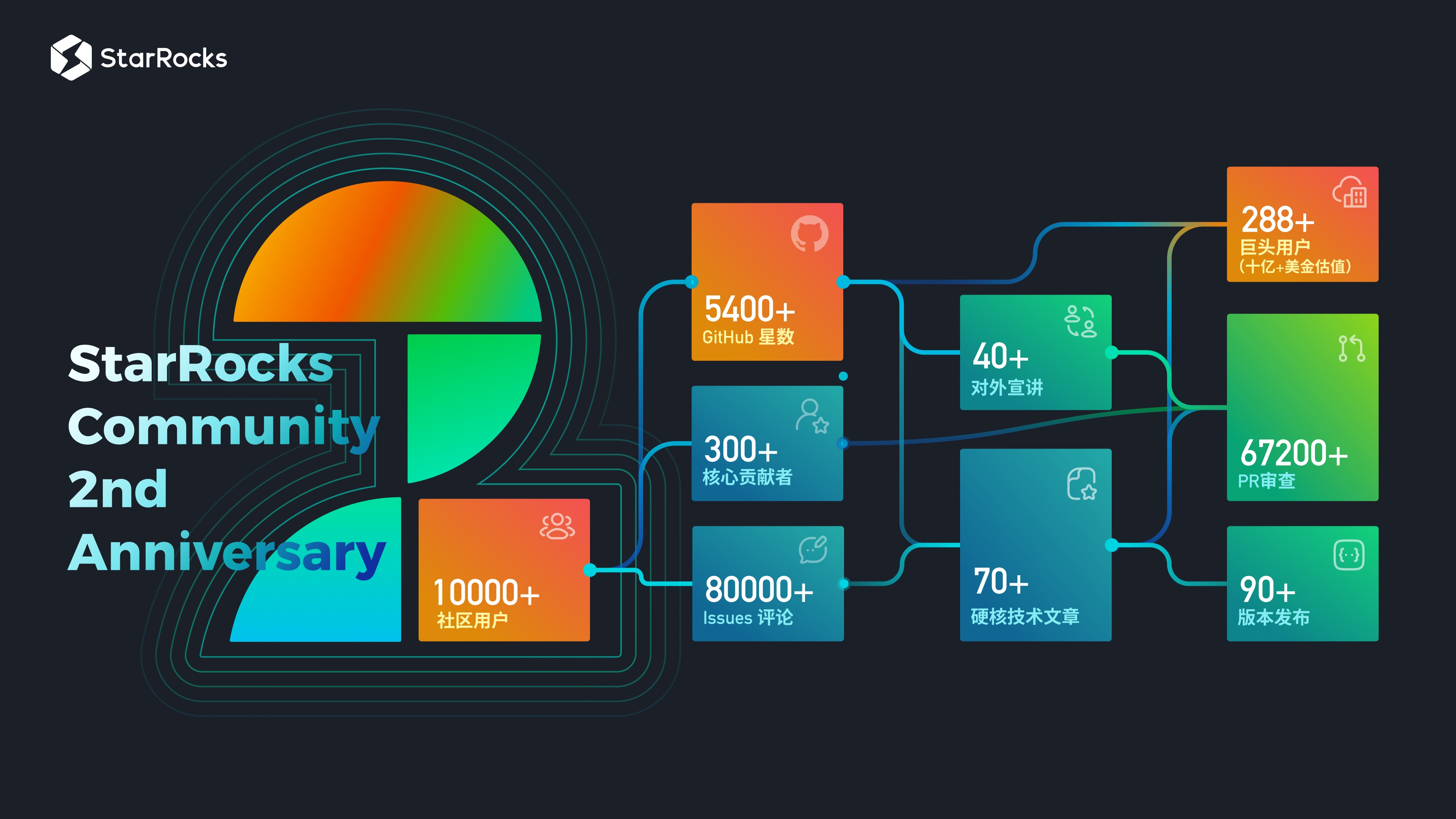
进化,永不止步
从诞生之初,StarRocks 就不断在探索关于“极速统一”之道。全面向量化引擎、CBO 查询优化器、实时更新数据模型、Pipeline 执行引擎相继发布,将 OLAP 分析性能提升到了新的高度,也引领了当前大数据分析的发展趋势。 随着各项重要功能历经 2 年、近 300 家各行业头部用户在生产环境中的打磨与完善,StarRocks 完成从 OLAP 到云原生湖仓的快速进化,通过湖仓一体让企业能基于一份数据,满足 BI 报表、多维分析、Ad-hoc 查询、实时分析等不同场景的数据分析需求, StarRocks 往 "One data,all analytics" 的目标不断前行。
湖仓一体化极速查询引擎
Presto/Trino/Impala 一直以来都是行业最好的数据湖(Hive/Hudi/Iceberg/Deltalake 等)查询引擎。但是其性能无法和将数据导入到 ClickHouse 或是 StarRocks 此类极速 OLAP 数据库/数仓相媲美,用户通常会组合使用,运维和使用都会比较复杂,StarRocks 期望彻底改变这种“组合”模式,推出更一体化的方案。StarRocks 的湖仓一体化极速查询引擎的理念是可以同时极速查询数据湖数据和 StarRocks 本地数据。从 StarRocks 2.0 到 StarRocks 3.0 版本, 经过一年半的时间和 7 个大版本的持续打磨,StarRocks 终于发布了业内第一个成熟完善的湖仓一体化极速查询引擎,让数据湖查询和本地数据查询基本持平,并且数据湖查询达到了 Presto/Trino/Impala 等系统的 3-6 倍以上的性能水平。
基于物化视图(MV)的轻量化数据建模
当前数据工程师进行数据建模时,需要通过预先构建大量 ETL 任务来生成 ODS/DWD/DWS/ADS 数据表。这种数据建模方法比较重,周期长,而且会存在很多无用 ETL。StarRocks 基于 MV 的轻量化数据建模方法提供了全新模式,将逻辑建模与物理建模分离:
-
无需预先大量 ETL,只需要用 view 来建立各层数据模型,快速交付 view 给业务查询使用 -
在业务查询使用中,随需创建多表/单表 MV 实现透明查询加速
业内 Clickhouse、Doris、Snowflake 等打造了比较好的单表 MV,缺乏完善的多表 MV 支持,不足以支持轻量级数据建模方法的落地。StarRocks 在 2.4 版本发布了多表 MV,之后经过 12 个月的时间和三个版本—— StarRocks 2.5、 StarRocks 3.0 和 StarRocks 3.1 版本的打磨,已经成为业内第一个可以同时支持复杂查询、数据湖外表和异步构建的多表 MV,可以很好的支持轻量化建模方法落地,成为用户针对数据建模和 ETL 进行降本增效的大杀器。
此外,物化视图也成为 StarRocks 3.0 的核心功能,物化视图通过声明式的方式降低了传统 ETL 中 Transform 的复杂度,通过外表物化视图可以无缝连接湖仓,通过查询改写可以透明加速,通过 spill 和分区增量刷新可以进行稳定的物化视图构建和细粒度的物化视图刷新策略。帮助用户的湖仓建模更容易。
极简存算分离架构
Snowflake 打造出了全球最好的存算分离架构,让很多云服务用户受益匪浅。但是其架构组件复杂,无法简单部署到用户的各类私有化环境。StarRocks 在存算分离上的创新初心是打破这种限制,让任何社区用户都可以将存算分离架构轻松部署到各类私有环境,获取更多降本增效的收益。StarRocks 3.0 版本发布的全新极简存算分离架构,基于原创的云原生操作系统 StarOS,整个新架构只有 FE 和 CN 两个模块,无需任何外部组件依赖,部署运维和非存算分离版本一样简单,性能一样出色。用户可以随时随地部署使用 StarRocks 存算分离架构,实现降本增效。
更加引人注目的是,3.0 版本的存算分离架构不仅学习了 Snowflake 的优点,通过内置的 StarOS,StarRocks 实现了完全无需外部组件的部署,大大简化了用户的操作。让用户在各种云上云下的环境都可以通过存算分离架构来接口存储介质,提升更好的弹性能力,实现多 AZ 甚至多云的高可用能力。大量用户的实践也证明了 StarRocks 存算分离架构已经走向成熟,将逐渐变成 StarRocks 的默认架构。
产品能力进化时间线
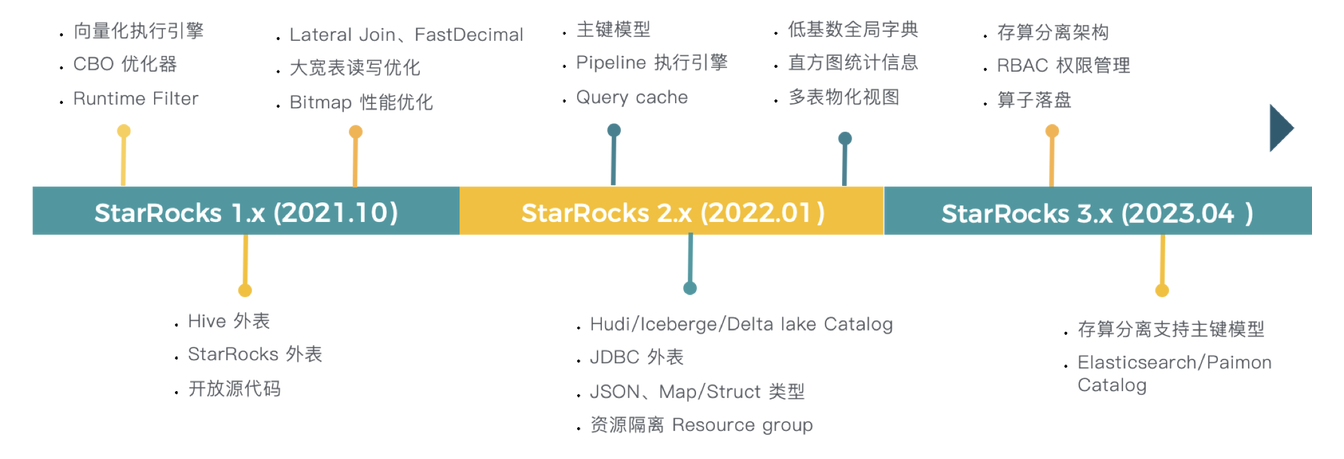
一文了解 StarRocks 物化视图、湖仓分析和存算分离: 重新定义物化视图,你必须拥有的极速湖仓神器! 当打造一款极速湖分析产品时,我们在想些什么 兼顾降本与增效,我们对存算分离的设计与思考
进化,不止代码
创建一个健康的开源项目需要整个社区的共同协作,在开源生态系统中,每个参与者都有机会塑造和改进软件,用户可以识别所需功能并贡献代码或用户案例。只有当整个社区和相关社区积极参与时,一个开源项目才能成功发展为一个繁荣的生态系统,这包括代码贡献者、用户、文档编写者、软件和平台供应商以及集成者等各方。
StarRocks 社区始终相信开放协作的力量,信奉 “Code is power. Community is strength. And Openness is everything. ”。代码是改变世界的力量,社区给了我们无限的可能,而这一切都只有通过开放才能实现。StarRocks 社区的价值观具体体现在:
-
对极速统一的云原生湖仓一体技术的持续探索:用户能更快、更低成本且更简单地在海量数据中挖掘数据的价值,助力业务成功。
-
与用户共同成长,彼此成就:建立产品文档、新手教程、产品特性解析、FAQ 、最佳实践和丰富的用户案例知识库,并且通过 StarRocks 城市行、开源集市、线上线下会议和微信/Slack/GitHub 等渠道与用户零距离交流。

-
开放生态,无缝衔接上下游组件:2022 年底,StarRocks 项目正式捐献给 Linux 基金会,更加中立、开放;并与开放的数据生态产品,如 Apache Flink、Apache SeaTunnel、Apache Paimon、Apache Hudi、Apache Icerberg 等社区共建现代数据栈。

蓬勃发展的用户社区
StarRocks 发展至今已有超过 288 家估值超过 10 亿美元的行业头部用户。这些用户遍布各行业,许多用户也在使用 StarRocks 后积极向社区分享了使用场景和实践经验。以下是一些具有代表性的用户案例:
互联网:芒果 TV、 滴滴、万物新生、 贝壳、同程旅行、得物、小红书、携程、美团餐饮 SaaS、360、微信 物流:顺丰、跨越速运、京东物流、达达 金融:中信建投、中欧财富 、众安保险、中原银行、信也科技 游戏:波克城市、37 手游、腾讯游戏、游族网络 汽车: 理想汽车、 蔚来汽车、、吉利汽车、首汽约车、汽车之家 制造/零售:大润发、华润万家、TCL、华米科技、百草味
完整的用户案例合集请见 StarRocks 公众号“StarRocks 用户案例合集” 和 StarRocks B 站!
深度参与社区共建的伙伴
StarRocks 各个代码仓库下已有超过 300 名贡献者,其中有许多人贡献了文档、函数、connector、周边生态等功能。我们由衷感谢每一位为 StarRocks 贡献力量的朋友们。特别要感谢以下深度参与社区的伙伴们,他们为 StarRocks 提供了备受用户欢迎的重要特性。 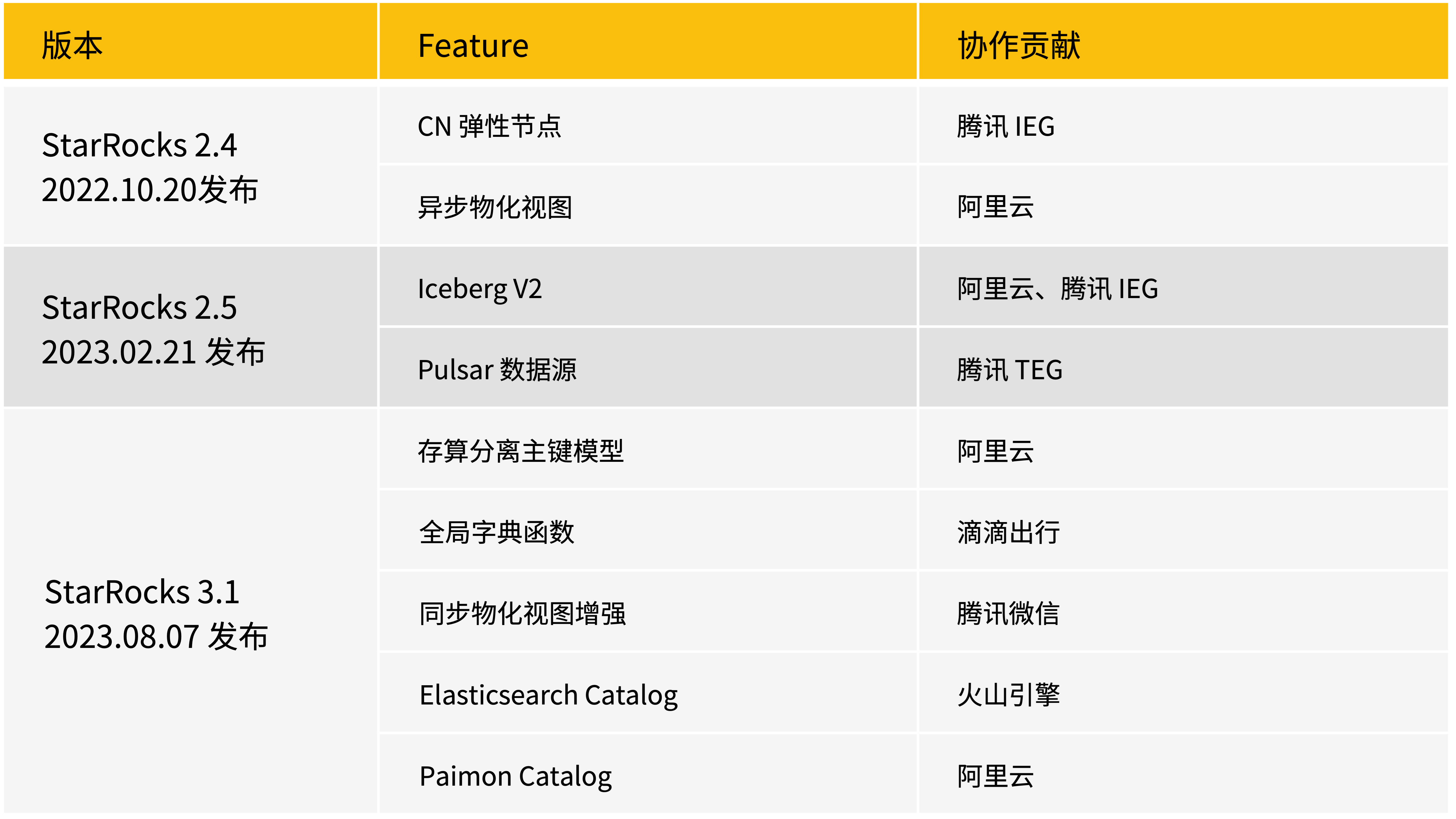
最后,感谢每一位为 StarRocks 添砖加瓦的小伙伴们:https://github.com/StarRocks/starrocks/graphs/contributors
总结与展望
过去的一年对于 StarRocks 来说是至关重要的一年,我们在产品、用户规模和社区治理模式方面不断进化,取得了飞跃式的成长。
-
产品:从原本的 OLAP 分析引擎到现在的湖仓一体,再从存算一体到存算分离,StarRocks 已发展成为极速统一云原生湖仓分析的新范式 -
用户规模:经过短短一年的时间,我们从千人规模的社区成长为超过万人的社区,拥有来自世界各地的众多知名用户积极参与并支持 StarRocks -
社区治理:StarRocks 的社区治理也越来越开放,更多开发者能通过不同的兴趣小组(SIG)参与研发工作 ,专家们能加入技术指导委员会(TSC, Technical Steering Committee)参与 StarRocks Roadmap 的制定和培养社区优秀人才
未来, StarRocks 社区也将保持着合作、开放、共赢的信念,与用户们一同探索新一代的云原生湖仓,共同打造极速统一湖仓分析的新范式!让我们期待更加精彩的下一周年!
本文由 mdnice 多平台发布







hbase映射表插入hive)









![[2023.09.21]:源码已上传,供大家了解Rust Yew的前后端开发](http://pic.xiahunao.cn/[2023.09.21]:源码已上传,供大家了解Rust Yew的前后端开发)

