机器学习中的特征筛选
- 一、特征筛选的重要性与基本概念
- 二、特征筛选的方法与实践
- 1. 基于统计的特征筛选
- 2. 基于模型的特征筛选
- 3. 嵌入式特征筛选
- 三、总结与展望
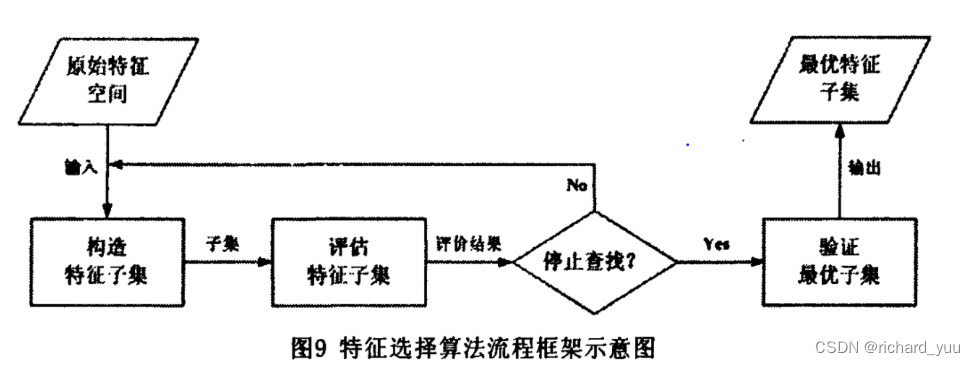
在机器学习领域,特征筛选作为预处理步骤,对于提高模型性能、简化模型结构以及增强模型解释性具有举足轻重的作用。本文将通过实例与代码,深入探讨特征筛选的基本概念、方法以及实践步骤,帮助读者更好地理解和应用特征筛选技术。
一、特征筛选的重要性与基本概念
特征筛选是机器学习工作流程中不可或缺的一环。随着数据集的日益庞大和复杂,特征的数量往往也随之激增。然而,并非所有的特征都对模型的性能提升有所贡献,有些特征甚至可能是冗余的、噪声较大的或者与目标变量无关的。因此,通过特征筛选,我们可以识别并保留与目标变量最相关的特征,同时剔除那些对模型性能贡献不大或者没有贡献的特征。
特征筛选的核心在于评估每个特征与目标变量之间的相关性或重要性。基于这些评估结果,我们可以选择出最为关键的特征子集,从而降低模型的复杂度,提高模型的泛化能力,并加速模型的训练过程。
二、特征筛选的方法与实践
特征筛选的方法多种多样,包括基于统计的方法、基于模型的方法和嵌入式方法等。下面我们将通过实例与代码,介绍几种常用的特征筛选方法,并展示如何在实践中应用这些方法。
1. 基于统计的特征筛选
基于统计的特征筛选方法通常利用统计学中的相关性分析或假设检验来评估特征与目标变量之间的关系。例如,我们可以使用皮尔逊相关系数或斯皮尔曼秩相关系数来衡量特征与目标变量之间的线性关系或单调关系。
pythonimport pandas as pd
from scipy.stats import pearsonr, spearmanr# 加载数据集
data = pd.read_csv('dataset.csv')# 计算特征与目标变量的皮尔逊相关系数
correlation_matrix = data.corr()
target_column = 'target'
feature_correlations = correlation_matrix[target_column].drop(target_column)# 筛选出相关性较高的特征
important_features = feature_correlations[abs(feature_correlations) > 0.5].index
print("Important features based on Pearson correlation:", important_features)# 计算特征与目标变量的斯皮尔曼秩相关系数
spearman_correlations = {}
for feature in data.columns:if feature != target_column:corr, _ = spearmanr(data[feature], data[target_column])spearman_correlations[feature] = corr# 筛选出相关性较高的特征
important_features_spearman = [feature for feature, corr in spearman_correlations.items() if abs(corr) > 0.5]
print("Important features based on Spearman correlation:", important_features_spearman)
2. 基于模型的特征筛选
基于模型的特征筛选方法利用机器学习模型来评估特征的重要性。这种方法通常通过训练模型并观察特征对模型性能的贡献来进行特征选择。例如,我们可以使用决策树或随机森林模型,通过查看特征的重要性排序来选择关键特征。
pythonfrom sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
import numpy as np# 划分数据集
X = data.drop(target_column, axis=1)
y = data[target_column]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 使用决策树模型进行特征筛选
tree_model = DecisionTreeClassifier(random_state=42)
tree_model.fit(X_train, y_train)
importances = tree_model.feature_importances_
indices = np.argsort(importances)[::-1]
print("Feature ranking by Decision Tree:", X.columns[indices])# 使用随机森林模型进行特征筛选
forest_model = RandomForestClassifier(n_estimators=100, random_state=42)
forest_model.fit(X_train, y_train)
importances = forest_model.feature_importances_
indices = np.argsort(importances)[::-1]
print("Feature ranking by Random Forest:", X.columns[indices])
3. 嵌入式特征筛选
嵌入式特征筛选方法将特征选择过程嵌入到模型训练过程中。例如,梯度提升决策树(GBDT)和XGBoost等模型在训练过程中会自然地对特征进行重要性评估。这些模型提供了特征重要性分数,我们可以基于这些分数进行特征选择。
pythonimport xgboost as xgb# 使用XGBoost进行特征筛选
xgb_model = xgb.XGBClassifier(use_label_encoder=False, objective='binary:logistic', random_state=42)
xgb_model.fit(X_train, y_train)
importances = xgb_model.feature_importances_
indices = np.argsort(importances)[::-1]
print("Feature ranking by XGBoost:", X.columns[indices])
三、总结与展望
特征筛选在机器学习中的重要性不言而喻。通过选择与目标变量相关性较高的特征,我们可以简化模型结构、提高模型性能,并增强模型的解释性。随着机器学习技术的不断发展,特征筛选方法也在不断演进和完善。未来,我们可以期待更多高效、准确的特征筛选方法的出现,为机器学习领域的发展注入新的活力。
通过本文的实例与代码详解,相信读者对特征筛选的基本概念、方法以及实践步骤有了更深入的了解。希望这些内容能够帮助读者更好地应用特征筛选技术,提升机器学习模型的性能。

ProxyFactory源码分析)


安装Gnome看CCTV)

)








![[LitCTF 2023]PHP是世界上最好的语言!!、 [LitCTF 2023]Vim yyds、 [羊城杯 2020]easycon](http://pic.xiahunao.cn/[LitCTF 2023]PHP是世界上最好的语言!!、 [LitCTF 2023]Vim yyds、 [羊城杯 2020]easycon)

)

