基本介绍
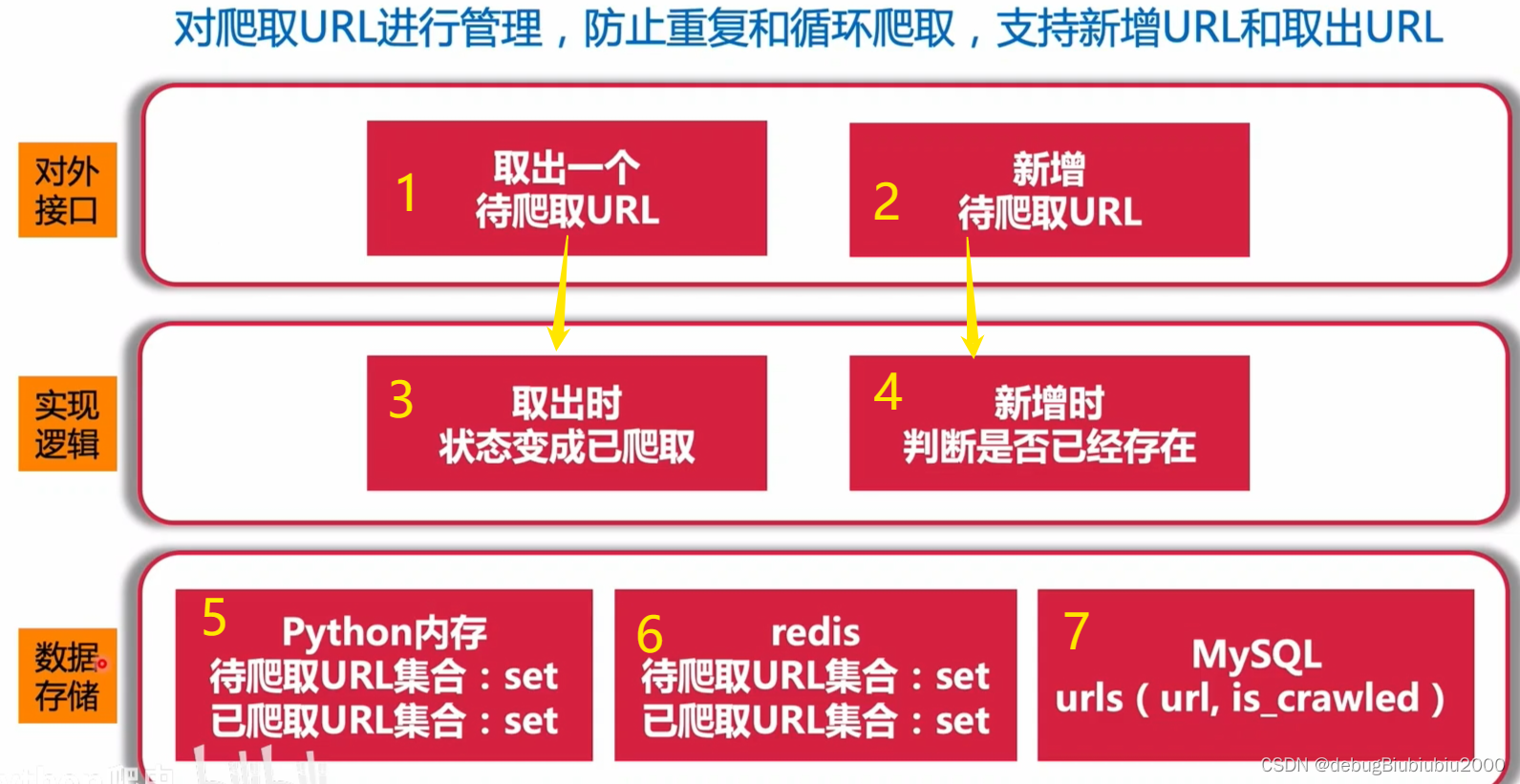
对外接口
对外提供两个接口:一个可以提取URL,一个可以增加URL,分别对应图上的1和2。
当要爬取某个网页时,则可以从1接口提取出该网页的URL进行爬取。
有时候爬取的网页内容中会包含别的网页链接,即包含有URL,此时可以把包含的URL提取出来,放入URL管理器,以便后续进行爬取,则可以利用2接口向URL管理器新增URL
实现逻辑
图中的3:从URL管理器取出一个URL时,将该URL的状态进行更改,如已爬取、爬取成功、爬取失败等(有多少种状态根据具体需求定义),以防止重复对同一URL进行爬取。
图中的4:把从爬取的网页内容中解析出来的URL放入到URL管理器中前,需要判断URL管理器中是否已存在该URL,已存在就不需要再添加,还是防止对同一URL进行重复爬取。
数据存储
实现URL管理器有5、6、7三种,
图中的5:利用python内存实现。
用python中的set集合实现URL管理器,set集合可以实现自动去重,而且可以快速的判断集合中是否已存在某个元素。
已爬取的URL可以用一个set来表示,未爬取的URL用另一个set集合表示。从未爬取的URL集合中取出一个URL进行爬取,并将该URL标记为已爬取URL,放入到已爬取URL的set集合中。当要新增一个URL时,即把新增URL放入未爬取URL集合中,如果未爬取URL集合已存在该URL,则不会重复添加,实现了图中4的逻辑。
如果一个URL有多种状态,如正在爬取中,爬取失败、爬取成功等,可以为每种状态设置一个set集合进行存储。当状态发生转变时,从相应的集合中取出放入到转变后的集合中。
图中的6:利用Redis实现
实现逻辑和python内存类似,区别在于Python内存一旦断电就要从头开始执行,但是Redis可以保存中间状态,断电后数据不会消失
图中的7:利用MySQL数据库表
可以利用一张urls表进行存储,该表中有两个字段:url 和 url 对应的状态(已爬取、未爬取等)
URL 管理器的代码实现(python内存实现)
class UrlManage:"""URL 管理器"""def __init__(self):# 待爬取 URL 集合self.new_urls = set()# 已爬取 URL 集合self.old_urls = set()def get_url(self):"""从URL管理器中获取URL进行爬取"""if self.has_new_url():url = self.new_urls.pop()self.old_urls.add(url)return urlreturn Nonedef add_new_url(self, url):"""新增一个 URL"""if url is None or len(url) == 0:returnif url in self.old_urls or url in self.new_urls:returnself.new_urls.add(url)def add_new_urls(self, *urls):"""批量新增 URL"""if urls is None or len(urls) == 0:returnfor url in urls:self.add_new_url(url)def has_new_url(self):"""判断是否还有待爬取 URL"""return len(self.new_urls) > 0# 测试代码
if __name__ == '__main__':url_manage = UrlManage()url_manage.add_new_url('url1')url_manage.add_new_urls('url1', 'url2', 'url3')print('已爬取set:', url_manage.old_urls, '未爬取set:', url_manage.new_urls)print('-' * 20)url = url_manage.get_url()print(url)print('已爬取set:', url_manage.old_urls, '未爬取set:', url_manage.new_urls)print('-' * 20)url = url_manage.get_url()print(url)print('已爬取set:', url_manage.old_urls, '未爬取set:', url_manage.new_urls)print('-' * 20)url = url_manage.get_url()print(url)print('已爬取set:', url_manage.old_urls, '未爬取set:', url_manage.new_urls)print('-' * 20)print(url_manage.has_new_url())print('已爬取set:', url_manage.old_urls, '未爬取set:', url_manage.new_urls)







)


)

ngx.balance和balance_by_lua终结篇)
)

)
)


