参考Faiss
索引结构总结:
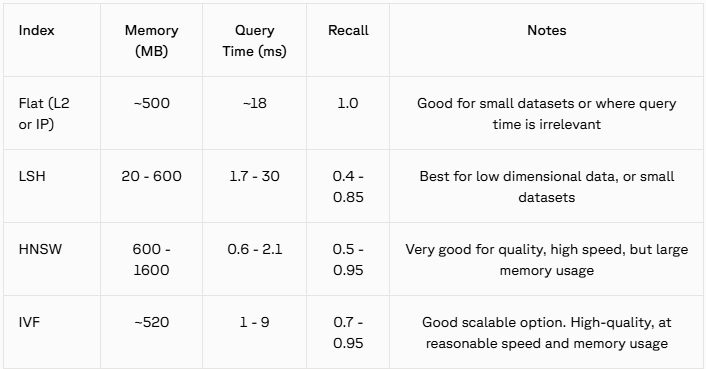
为了加深记忆,介绍一下Inverted File Index(IVF)的名字由来:
IVF索引的名字源自“倒排文件”(Inverted File)的概念。在传统的信息检索中,倒排文件是一种索引结构,用于记录每个词汇和文档之间的关系,从而快速定位包含特定词汇的文档。
“倒排”是相对于文档顺序的“正排”而言的。在传统的信息检索中,文档是按照其自然顺序存储的,称为“正排文件”(Forward File)。在这种结构中,每个文档包含的信息是完整的,比如文档的内容以及可能包含的所有词汇。如果需要搜索某个词汇,系统就需要遍历所有文档,逐个检查是否包含这个词汇,这样效率会非常低。
而“倒排文件”(Inverted File)则是通过将词汇和文档之间的关系“倒转”过来实现的。它先建立一个词汇表(词典),然后为每个词汇记录它所出现的文档编号或位置。这样,当查询某个词汇时,系统可以直接通过倒排文件快速定位到包含该词汇的文档,而不需要逐一扫描所有文档。这种方法显著提高了检索速度。
在向量相似性搜索中,IVF索引借用了这种倒排结构的思想,但将其应用于向量空间。数据集的向量被划分到多个“簇”(clusters)或“细胞”(cells)中。这些簇是通过对向量进行聚类(Clustering)创建的,每个簇有一个中心点(Centroid)。查询向量(Query Vector)通过与中心点的比较确定属于哪个簇,然后搜索范围限制在该簇或多个簇中。这种方法减少了搜索范围,提高了搜索效率。
PQ(Product Quantization)
名字的由来
Product(产品、乘积)一词的核心意义在于:
- 向量的整体量化是多个子空间量化的“乘积”,通过将整体问题分解成多个子问题,从而减少计算复杂性(所以这里product有点类似“分解”的意思)。
- 通过将一个高维向量拆分为多个子向量,并分别对这些子向量进行量化,最终的编码可以看作这些独立量化的“笛卡尔乘积”。
“Quantization”:指的是“量化”过程。量化的目的是用有限的质心(centroids)来近似表示连续向量空间,从而大幅降低存储和计算成本。
“Product Quantization”表达了该技术的核心思想:通过对向量进行分解(product)和量化(quantization)以高效处理大型数据集。这种方法在保持精确性的同时显著减少了存储需求和计算开销。
如何做查询
如何构建参看上述Faiss链接
已知构建好后数据集中的data都可以表示为质心ID。
查询方法一:
- 查询向量量化:查询向量同样被分割为子向量,并映射到其各自子空间的最近质心,这使得查询向量也可以被表示为一组质心ID。
- 计算距离:系统利用这些质心的编码信息来快速计算查询向量与数据库中存储向量之间的距离。由于向量被量化到有限的质心集合,这种计算变得更加高效。
- 最近邻检索:最终,系统基于计算的距离返回最接近查询向量的多个候选向量(通常是 Top-k 结果)。
这里详细解释一下计算距离的操作,既然大家都是查询编号了,我们是可以把查询编号反映射回向量的,所以直接计算对应质心向量之间的(每个子空间的)距离结果求和(而非把重构的结果组合成完整的高维向量再做计算距离)的,但是这样太慢了。
可以发现我们总是在求质心之间的距离,其实非常没必要,我们可以是事先把每个子空间中的质心之间的的距离提前计算出来存着,要计算对应两个质心的距离时直接查表即可(这样也就不用映射回向量了!)。
查询方法二:
- 查询向量量化:查询向量同样被分割为子向量<但不映射为对应的ID,方法一在映射时也需要计算查询向量的子向量到对应质心的向量的距离来判断对应哪个ID>。
- 计算距离:详见下。
- 最近邻检索:最终,系统基于计算的距离返回最接近查询向量的多个候选向量(通常是 Top-k 结果)。
可以直接计算查询向量的子向量到对应子空间的所有质心的距离,做成一个表<查询向量与质心的表,注意与查询一是构建质心之间的距离表>(不需要映射到最近的质心了,但其实也遍历了与质心计算,少了对q的编码那一步)。因为数据集中的数据已经表示为对应的质心ID了,所以到查询向量到数据集中的data只需要查表然后累加。
相对简洁些。
IVFPQ(Inverted File Index + Product Quantization)
相较于IndexPQ直接对向量 x x x 进行 PQ 量化,IVFPQ 先用 IVF 聚类,再对残差进行PQ,相对量化误差小,精度高,当然速度上会逊于单纯的IndexPQ。
1. 预处理阶段(构建索引)
在执行查询之前,系统已经执行了以下步骤:
1.1 构建 IVF(倒排文件索引)
- 对所有数据库向量运行 K-Means 聚类,得到 K 个簇中心(centroids)
- 每个数据库向量x被分配到距离它最近的簇中心 C i C_i Ci,并存储在该簇的倒排列表中
1.2 对簇内的向量进行 PQ(产品量化)
- 对每个数据库向量的偏移量 x − C i x-C_i x−Ci进行PQ
- 只存储PQ编码不存储原始向量
2.查询阶段
给定查询向量 q q q,IVFPQ 执行以下步骤来查找最近邻:
Step 1:使用 IVF 找候选集
用 IVF 簇中心索引快速筛选候选集,避免遍历整个数据库。
- 计算 q q q 到所有K 个聚类中心的距离: d ( q , C i ) d(q,C_i) d(q,Ci)
- 选取最近的前n个簇(通常 n < < K n<<K n<<K),只在这些簇的数据库向量中进行搜索,而不扫描整个数据库。
Step 2:计算查询向量到候选向量的距离(使用 PQ)
对候选向量使用 PQ 查表计算近似距离,加速计算。
对于每个候选簇中的数据库向量:
- 计算查询向量相对簇中心的偏移量: q ′ = q − C i q'=q-C_i q′=q−Ci
- 利用 PQ 查找表计算近似距离:(1)预计算查询向量到PQ质心的距离表<方式二>;(2)读取数据库向量的 PQ 编码,从查找表中快速查找距离;(3)每个向量的距离计算变成了查表 + 加法操作,而不需要逐维计算欧几里得距离
Step 3:返回最近邻
在候选集中排序,选取最近的 k k k个向量作为最终查询结果。
为什么是对残差进行PQ
- 减少量化误差
- 直接对整个数据库向量 x x x进行 PQ 时,可能会出现较大的量化误差。
- 但如果先用 IVF 找到最接近的簇中心,然后对其 残差进行 PQ 量化,则编码更加精细,可以减少误差。
- 提高检索精度
- 由于每个簇内的向量与簇中心的偏移较小(即残差较小),因此残差的值域更小,产品量化的效果更好。
- 这样,查询时可以用更少的 PQ 码字(即更低的存储成本)来获得更高的搜索精度。
问题:nprobe 的选择(找候选集的个数)
较低的nprobe会进一步加快速度,但是同时也大概率降低recall,可以适当提高nprobe
这里放上手册中的对比图:
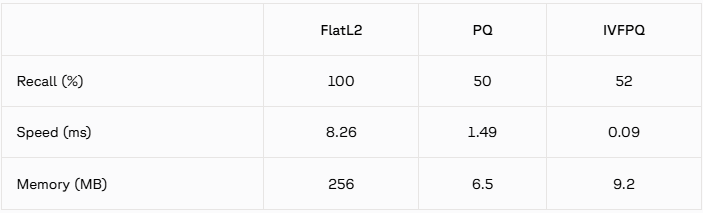
总结:PQ很快但是召回率较低,注意使用场景
这里给上GPT的回答:
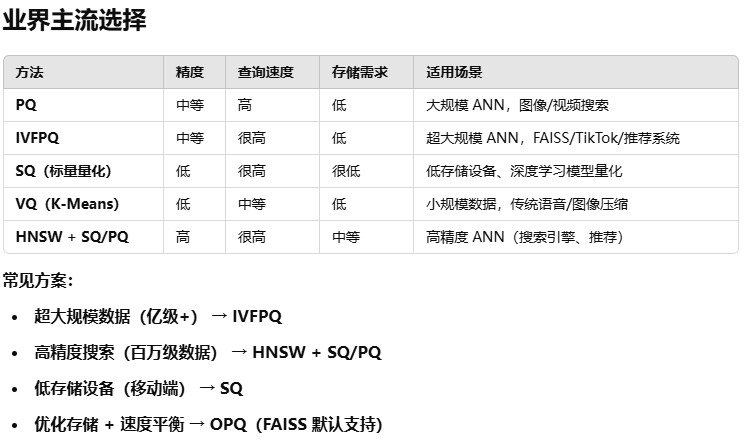
补充一下里面未涉及的有关量化的方法:






![【网络流 图论建模 最大权闭合子图】 [六省联考 2017] 寿司餐厅](http://pic.xiahunao.cn/【网络流 图论建模 最大权闭合子图】 [六省联考 2017] 寿司餐厅)
:axios有哪些常用的方法)



Hive聚合函数深度解析:从基础统计到多维聚合的12个生产级技巧)








用于执行两个矩阵(或图像)逐元素乘法操作的函数mul())

