本章将介绍该系列文章中使用的数据集,并且编写预处理代码,处理成咱们需要的格式。
一、数据集介绍
咱们使用的数据集名称是chinese-poetry,是一个在github上开源的中文诗词数据集,根据仓库中readme.md中的介绍,该数据集是最全的中华古典文集数据库,包含 5.5 万首唐诗、26 万首宋诗、2.1 万首宋词和其他古典文集。诗人包括唐宋两朝近 1.4 万古诗人,和两宋时期 1.5 千古词人。
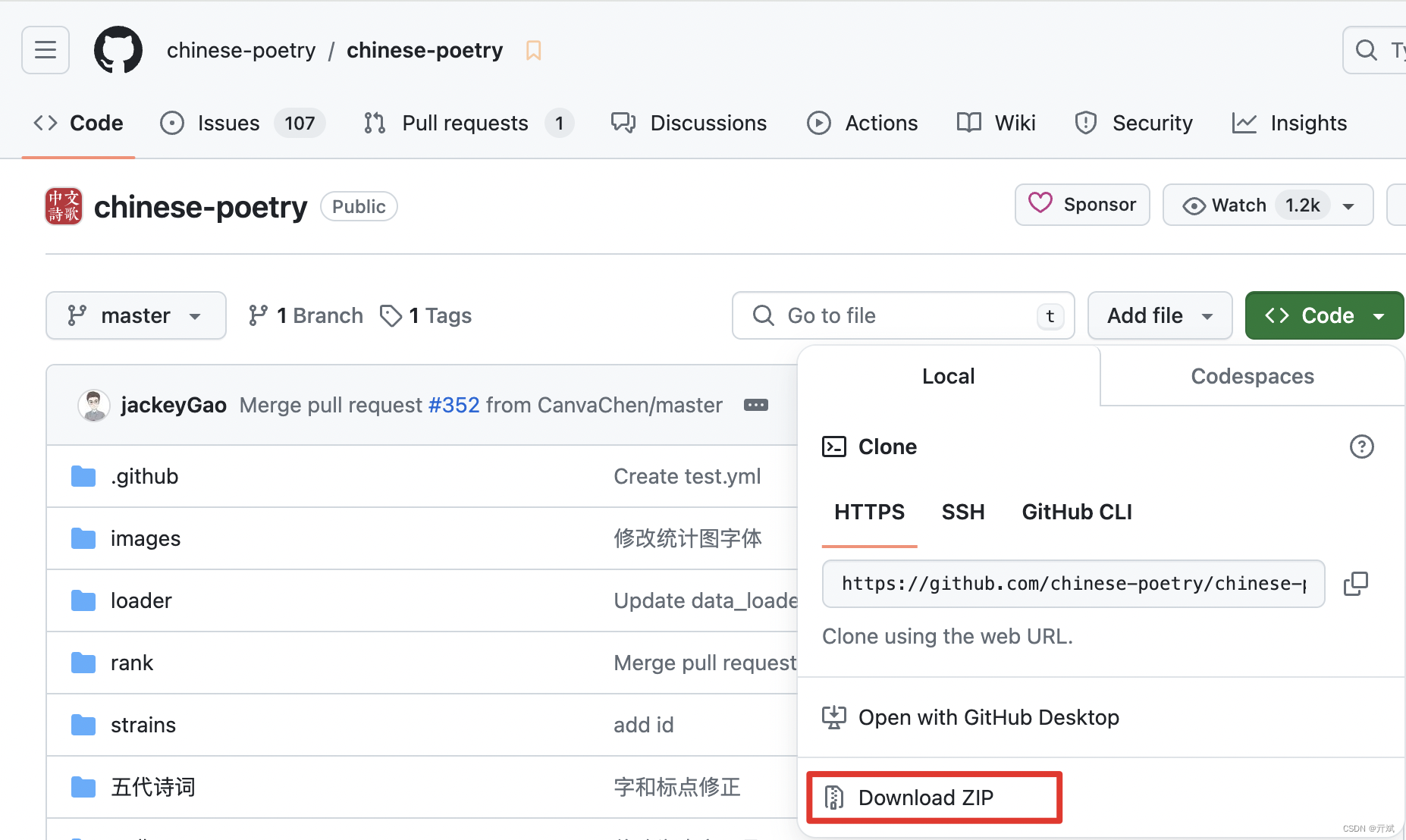
数据集的下载地址:https://github.com/chinese-poetry/chinese-poetry?tab=readme-ov-file,大家可以点击Code按钮,选择Download ZIP将该数据集下载到本地,如下图:
当然,作者收集数据也不易,大家可以顺手点一下star鼓励一下作者,如图:

如果你按照上面的步骤,把数据集下载到你本地了,解压后你可以看到如下图所示的目录结构
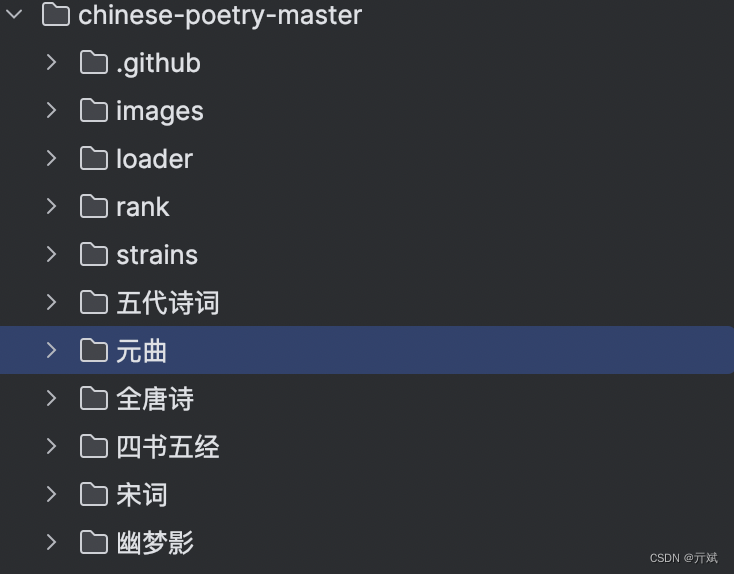
作者按照不同诗词类型进行了分类,并且在每个分类下提供了1个到多个的json文件,json文件里按照结构化数据组织了每一个诗词的信息,如下图

二、数据集预处理
上面咱们详细介绍了chinese-poetry数据集的下载方式和作者组织的结构,下面我们将提取每个诗词的标题和内容作为我们需要的部分,并聚合到一个文件中,以方便我们后续训练模型使用。
首先,我们需要把作者提供的诗词类目整理到一个数组中,方便我们后续进行目录的变量
classes = ['五代诗词', '元曲', '全唐诗', '四书五经', '宋词', '幽梦影', '御定全唐詩', '曹操诗集', '楚辞', '水墨唐诗','纳兰性德', '蒙学', '论语', '诗经']
然后,我们可以遍历该数组,拼接一个目录,遍历目录中中的文件,再进行文件处理
for cls in classes:dir = base_dir + clsfiles = os.listdir(dir)for f in files:f = f'{dir}/{f}'if os.path.isdir(f):if 'error' in f:continuefor ff in os.listdir(f):process_json(f'{f}/{ff}')else:process_json(f)
上面代码中,我们遍历每个类别的目录后,会列出该类别中所有的文件,文件如果是一个目录,则继续遍历这个目录,因为作者提供的目录结构会存在二级目录的情况。
最后,拿到每个json文件后,会调用process_json()函数处理对应的json文件。下面我们开始介绍process_json()函数。
process_json()函数会对上面代码中拿到的每个json文件进行处理,并且从json文件中提取我们需要的信息(诗词的标题和内容),重新组织结构,写入到一个新文件中;该函数还会根据一个简单的策略划分出训练集和测试集(训练集用来训练我们的模型,测试集用来在训练过程中测试模型的性能)。整体代码如下
def process_json(file):if not file.endswith('.json'):returnwith open(file, 'r') as f:json_content = f.read()array = json.loads(json_content)if type(array) != list:returnif len(array) > 100:train_array = array[:-1]test_array = array[-1:]else:train_array = arraytest_array = Nonefor item in train_array:if 'title' not in item.keys() or 'paragraphs' not in item.keys():continuewrite_file(item, dst_train_file)if test_array is not None:for item in test_array:if 'title' not in item.keys() or 'paragraphs' not in item.keys():continuewrite_file(item, dst_test_file)
在代码中,首先会打开该json文件,并读取json文件中的内容;读到内容后,通过json.loads()函数将它解码成在python中可以识别的数据结构。
接下来,我们根据该分类下诗词的数据决定是否要划分出测试集,策略很简单,如果个数大于100,我们就把最后一个作为测试集的一部分,当然这个策略可以根据你的需求进行调整。
最后,我们从json中拿到title和paragraphs属性通过一个write_file()函数写到我们的新文件中。
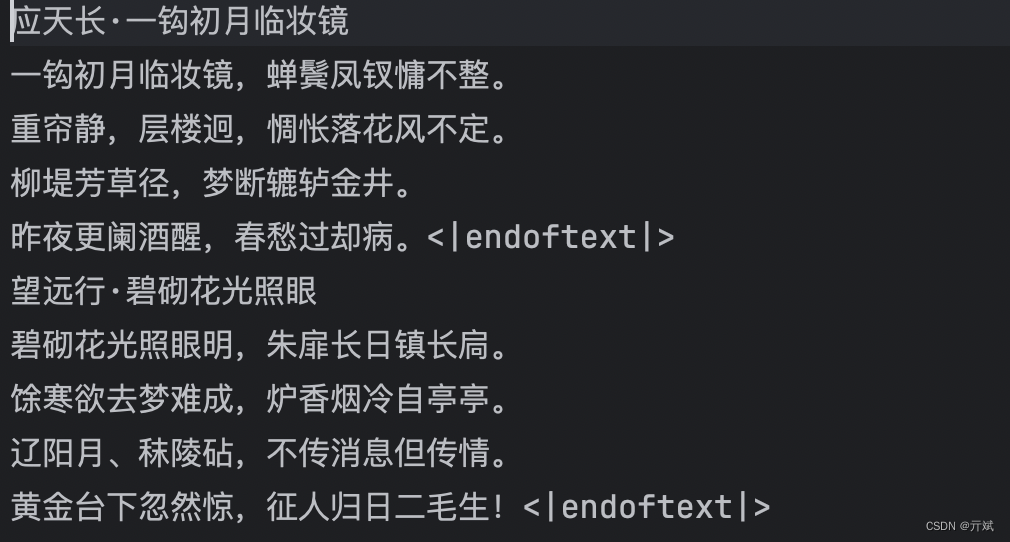
write_file()函数的实现也很简单,作用就是拿到title和paragraphs,组织好结构写入到一个新文件中;我们预处理后的文件不会像原数据集那样提供多个文件,而是全部写到同一个文件中,所以,此时就得考虑一个问题:所有的诗词在一个文件中,怎么标识出一首诗结束了呢?办法很简单,我们在没首诗结束的时候添加一个<|endoftext|>特殊标识,该标识很重要,因为在后面我们训练模型的时候,该标识也会根据此标识学习一首诗到哪结束了(不需要结束,咱们模型就无止境的输出了)。
def write_file(item, dst_file):global error_counttitle = item['title']paragraphs = item['paragraphs']content = f'\n{title}'for p in paragraphs:content = f'{content}\n{p}'content = converter.convert(content)if '𫗋' in content:print(f'{content}----')error_count += 1returncontent = content + '<|endoftext|>'dst_file.write(content)
上面代码中,处理前面我们介绍的部分,存在两个特殊的地方
...
content = converter.convert(content)
...
if '𫗋' in content
第一个的作用是将繁体中文转换成简体字,因为原数据集中存在大量的繁体字,显然,我们不想让咱们的模型生成的诗词是繁体字形式,所以这里我选择将繁体字转换成简体字,这里借助了一个python的转换库opencc实现,大家可以通过pip3 install opencc-python-reimplemented进行安装,该库的使用方法如下
import opencc
# 繁转简
converter = opencc.OpenCC('t2s')
content = converter.convert(content)
第二个特殊的地方就是我们代码中有一个𫗋,这是因为,通过上述代码转换成简体字的时候会有一些字转换错误,所以我们这里直接将存在转换错误情况的诗过滤掉,当然,这种情况不会很多,大概几十首诗词,对于咱们几十万首诗词的数据集来说都是毛毛雨。
好了,上面就是咱们数据预处理的全部过程,最终你会得到一个如下结构的train.txt和test.txt分别代表咱们前面提到过的训练集和测试集。
最后,我把全部代码整理出来,方便大家可以复制到本地直接运行
import os, json
import openccbase_dir = 'chinese-poetry-master/'
classes = ['五代诗词', '元曲', '全唐诗', '四书五经', '宋词', '幽梦影', '御定全唐詩', '曹操诗集', '楚辞', '水墨唐诗','纳兰性德', '蒙学', '论语', '诗经']dst_train_file = open('./train.txt', 'w')
dst_test_file = open('./test.txt', 'w')converter = opencc.OpenCC('t2s')
error_count = 0def write_file(item, dst_file):global error_counttitle = item['title']paragraphs = item['paragraphs']content = f'\n{title}'for p in paragraphs:content = f'{content}\n{p}'content = converter.convert(content)if '𫗋' in content:print(f'{content}----')error_count += 1returncontent = content + '<|endoftext|>'dst_file.write(content)def process_json(file):if not file.endswith('.json'):returnwith open(file, 'r') as f:json_content = f.read()array = json.loads(json_content)if type(array) != list:returnif len(array) > 100:train_array = array[:-1]test_array = array[-1:]else:train_array = arraytest_array = Nonefor item in train_array:if 'title' not in item.keys() or 'paragraphs' not in item.keys():continuewrite_file(item, dst_train_file)if test_array is not None:for item in test_array:if 'title' not in item.keys() or 'paragraphs' not in item.keys():continuewrite_file(item, dst_test_file)for cls in classes:dir = base_dir + clsfiles = os.listdir(dir)for f in files:f = f'{dir}/{f}'if os.path.isdir(f):if 'error' in f:continuefor ff in os.listdir(f):process_json(f'{f}/{ff}')else:process_json(f)dst_train_file.close()
dst_test_file.close()dst_train_file = open('./train.txt', 'r')
dst_test_file = open('./test.txt', 'r')train_count = 0
test_count = 0for line in dst_train_file:if '<|endoftext|>' in line:train_count += 1for line in dst_test_file:if '<|endoftext|>' in line:test_count += 1print(f'train_count: {train_count}, test_count: {test_count}, error_count: {error_count}')
















)


