中文医学数据集 ChineseBLUE 分析
- 基本介绍
- 数据集分类
- 构造成本
论文:https://arxiv.org/pdf/2106.08087v5.pdf
链接:https://github.com/alibaba-research/ChineseBLUE
基本介绍
需要注意的是,中文生物医学文本在语言上与英文不同,具有其领域特性,这需要专门为中文设计的评估BioNLP基准测试。
在本研究中,我们专注于中文,旨在填补这一空白并开发第一个中文生物医学语言理解基准测试。
我们收集了真实世界的生物医学数据,并提出了第一个中文生物医学语言理解评估(CBLUE)基准:包括命名实体识别、信息抽取、临床诊断标准化、单句/句对分类等自然语言理解任务的集合,以及一个用于模型评估、比较和分析的在线平台。
为了在这些任务上建立评估标准,我们报告了当前11个预训练中文模型的实验结果,实验结果显示,最先进的神经模型的性能远远低于人类的上限。
使用当前最先进的人工智能(AI)技术开发的神经网络模型的性能,比人类的最佳表现要差很多。
数据集分类

NER(命名实体识别):
- 命名实体识别旨在识别各种实体,包括疾病,药物,综合症等。
- 选择从中国电子健康记录中标记的cEHRNER数据集和从中国社区问答中标记的cMedQANER数据集。
PI(释义识别):
- 复述识别旨在识别两个句子是否表达相同的含义。
- 我们使用cMedQQ,它由搜索查询对组成。
QNLI(问题自然语言推论):
- 问题自然语言推论旨在识别答案是否对应于问题答案对中的问题
- 我们使用cMedQNLI,它由问答对组成。
QA(问题解答):
- 可以将问题回答近似为根据其相似性对候选答案句子进行排名。
- 我们为质量检查对分配0,1标签,这将转换为二进制分类问题。
- 我们使用论文“中医问题答案选择的多尺度注意力交互网络”中发布的
cMedQA,其中包括问题及其答案。
IR(Information Retrieval):
- 信息检索旨在根据搜索查询来检索大多数相关文档。
- IR可以视为一项排名任务。
- 我们使用cMedIR数据集,该数据集由具有多个文档及其相对得分的查询组成。
IC(意图分类):
- 意图分类旨在为查询分配意图标签,可以将其视为多个标签分类任务。
- 我们使用cMedIC数据集,该数据集由带有三个意图标签(例如,无意图,弱意图和坚定意图)的查询组成。
TC(文本分类):
- 文本分类旨在为句子分配多个标签。
- 我们使用cMedTC数据集,该数据集由带有多个标签的生物医学文本组成。
Symptom Diagnosis症状诊断:
- 在自然语言处理中,症状诊断是一个具有挑战性但意义深远的问题。
- 我们使用论文“通过全局注意力和症状图增强对话症状诊断”发布的CMDD数据集。
比如:
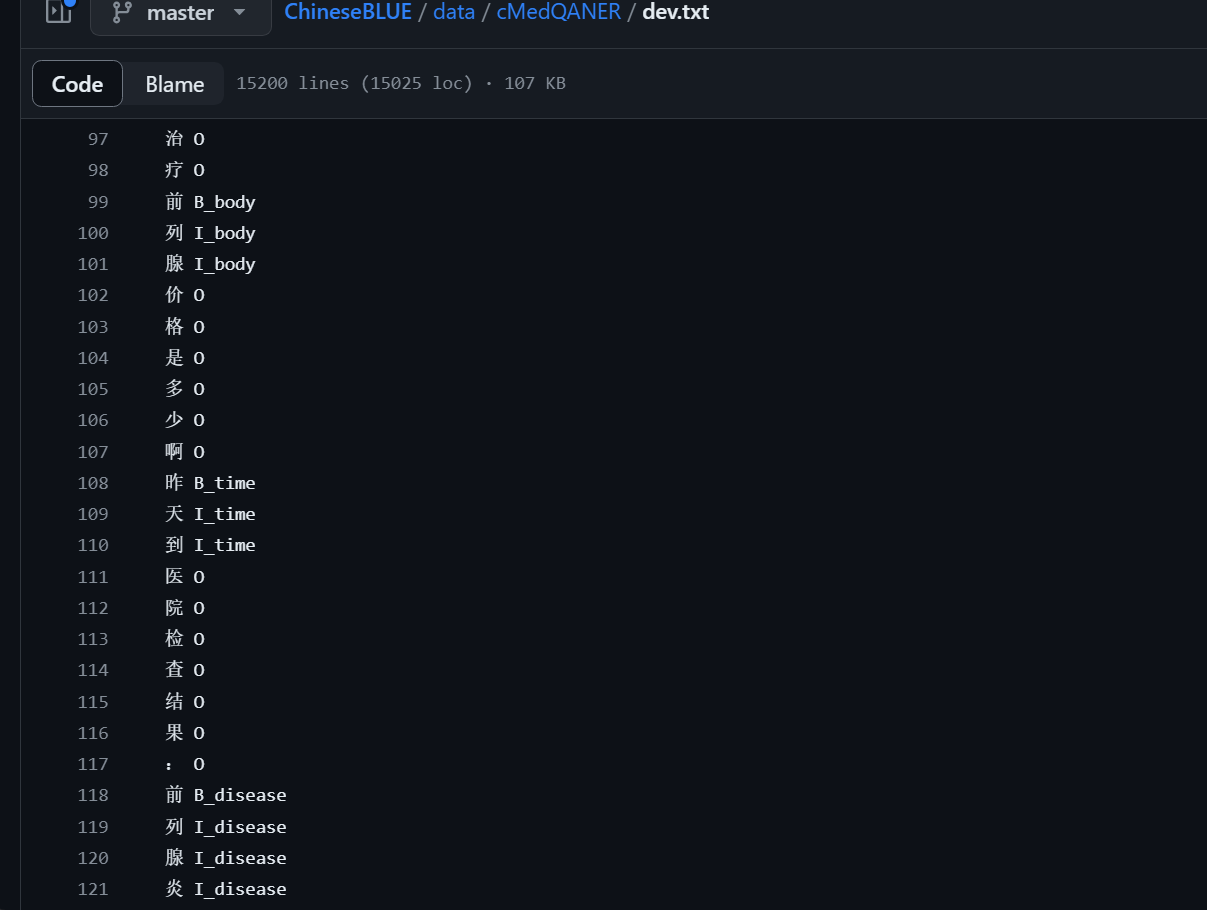
dev.json 是原始数据,dev.txt 是清洗后的数据。
disease(疾病):口腔溃疡、感冒、癫痫、鼻炎、三叉神经痛
symptom(症状):红肿、腰酸、神经痛、疼痛、出血
body(部位):嘴、胃肠道、关节、神经、血管
treatment(治疗方法):手术、中医、平肝泻火、降压药物、活血化瘀、消炎药
drug(药物):感冒灵颗粒、络活喜、洛汀新、阿莫西林
test(检查项):胃镜、超声、CT、抽血化验、血压
crowd(人群):小孩、儿童、女性、中老年、宝宝、婴儿
time(时间):昨天、三个月、上周三、今年5月份、三个月
physiology(生理机能):怀孕、血压、血糖、脂肪、消化
feature(特征):严重、局部、轻度、剧烈、部分
department(科室):消化科、神经外科、儿科、五官科、骨科
再比如:
比如 CMDD 意图识别:
- 病症:定义,病因,临床表现,相关病症,治疗方法,推荐医院,预防,所属科室,禁忌,传染性,治愈率,严重性
- 药物:作用,适用症,价钱,药物禁忌,用法,副作用,成分
- 治疗方案:方法,费用,有效时间,临床意义/检查目的,治疗时间,疗效,恢复时间,正常指标,化验/体检方案,恢复
- 其他:设备用法,多问,养生,整容,两性,对比,无法确定
构造成本
中文医学命名实体识别数据集(CMeEE):
注释人员:
- 32名注释者参与
- 2名医学专家
- 4名生物医学信息领域专家
- 6名医学博士
- 22名计算机科学硕士生
时间与费用:
- 注释过程持续了大约3个月(2018年10月至12月)
- 附加1个月时间进行数据整理
- 总费用约为50,000人民币
中文医学信息提取数据集(CMeIE):
注释人员:
- 20名注释者参与
- 2名医学专家
- 2名生物医学信息领域专家
- 4名医学博士
- 14名计算机科学硕士生
时间与费用:
- 注释过程持续了大约4个月(2018年10月至12月)
- 总费用约为40,000人民币
临床诊断标准化数据集(CHIP-CDN):
注释人员:
- 医疗团队由益度云组成
- 所有成员都有医学背景和临床资格证书
时间与费用:
- 工作持续了大约2个月
- 由内部员工完成,估计总成本约为100,000人民币
临床试验标准数据集(CHIP-CTC):
注释人员:
- 3名注释者
- 1名生物医学研究员
- 2名生物医学信息领域的博士候选人
时间:
- 注释工作开始于2019年7月并持续了大约1个月
- 该工作与注释者的研究项目相关,无需支付费用
语义文本相似性数据集(CHIP-STS)
- 5名本科生
- 2周
- 2.5万
KUAKE-查询意图分类数据集(KUAKE-QIC)
- 6名全职员工
- 2周
- 6600元
KUAKE-查询标题相关性数据集(KUAKE-QTR)
- 9名(7名众包大学生和2名阿里巴巴全职医疗背景员工)
- 2周
- 2.8万
KUAKE-查询查询相关性数据集(KUAKE-QQR)
- 注释费用为2.2万
- 其他信息未详细说明


)


-------单节点安装启动)

)


23-364)



)

运行时数据区域介绍)

)
