GPT-SoVITS 是一个开源的声音克隆项目,可以训练自己的声音模型。
效果非常好,使用超级简单。
如果你有声音克隆的需求,必须要试试这个项目。
不说废话,直接看怎么训练自己的声音模型。
1. 安装
我的是Windows系统,GPT-SoVITS 为 Windows 提供了整合包。
地址:
https://huggingface.co/lj1995/GPT-SoVITS-windows-package/resolve/main/GPT-SoVITS-beta.7z?download=true
下载解压后直接运行其中的 go-webui.bat 即可。
如果你的Linux或者Mac,请参考项目说明。
2. 训练声音模型
模型训练的流程:
1)人声伴奏分离
如果你提供的音频是干净的人声,就略过此步骤。
2)语音切分
把提供的语音切分成N个几秒的小段儿音频。
3)语音识别 ASR
把每段音频中的文字提取出来。
4)语音文本校对
纠正上一步提取出来的文字不准确的地方,修正。
5)训练集格式化
处理校对过的文本,特征提取,语义token提取。
6)声音模型训练
包括 SoVITS训练、GPT训练。
看着流程挺复杂,实际操作很简单。
先准备好要克隆的音频,一定要保证声音干净、清晰。
我用的是一个5分钟的音频,非常干净,没有伴奏,所以可以直接从第二步开始。
下面开始操作。
语音切分
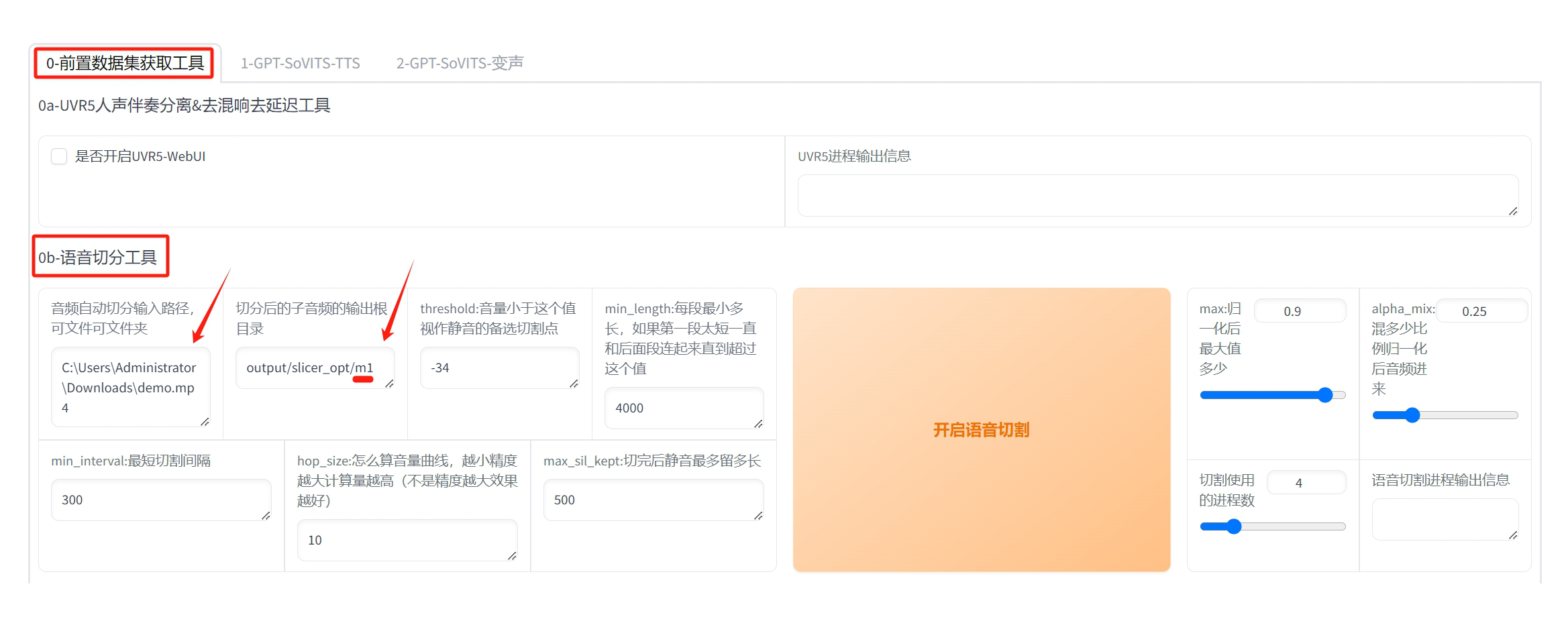
在 “0-前置数据集获取工具” 这个标签中操作。
只需要填写红色箭头指出的两个位置。
“输入路径” 就是你的样本音频文件的位置。
“输出根目录” 是切分后的音频存放位置,其中 “output/slicer_opt/” 是默认值,后面的 "m1" 是我自己填的,目的是让这次切分的音频都放在一个独立的目录中。
然后就点击 “开启语音切割“ 这个大按钮。
非常快,几秒结束,会显示“切割结束”。
语音识别 ASR
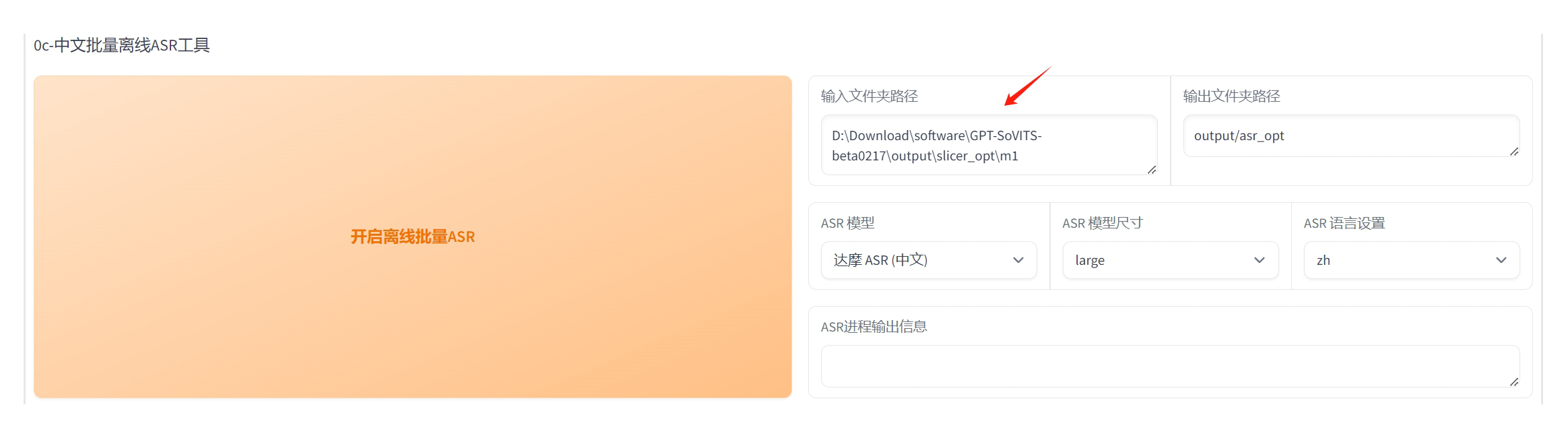
只需要修改 “输入文件夹路径”,就是上一步中填写的 “输出根目录”。
其他的不需要改,点击 “开启离线批量ASR” 大按钮。
第一次执行时,时间会有点长,因为需要下载语音识别模型。
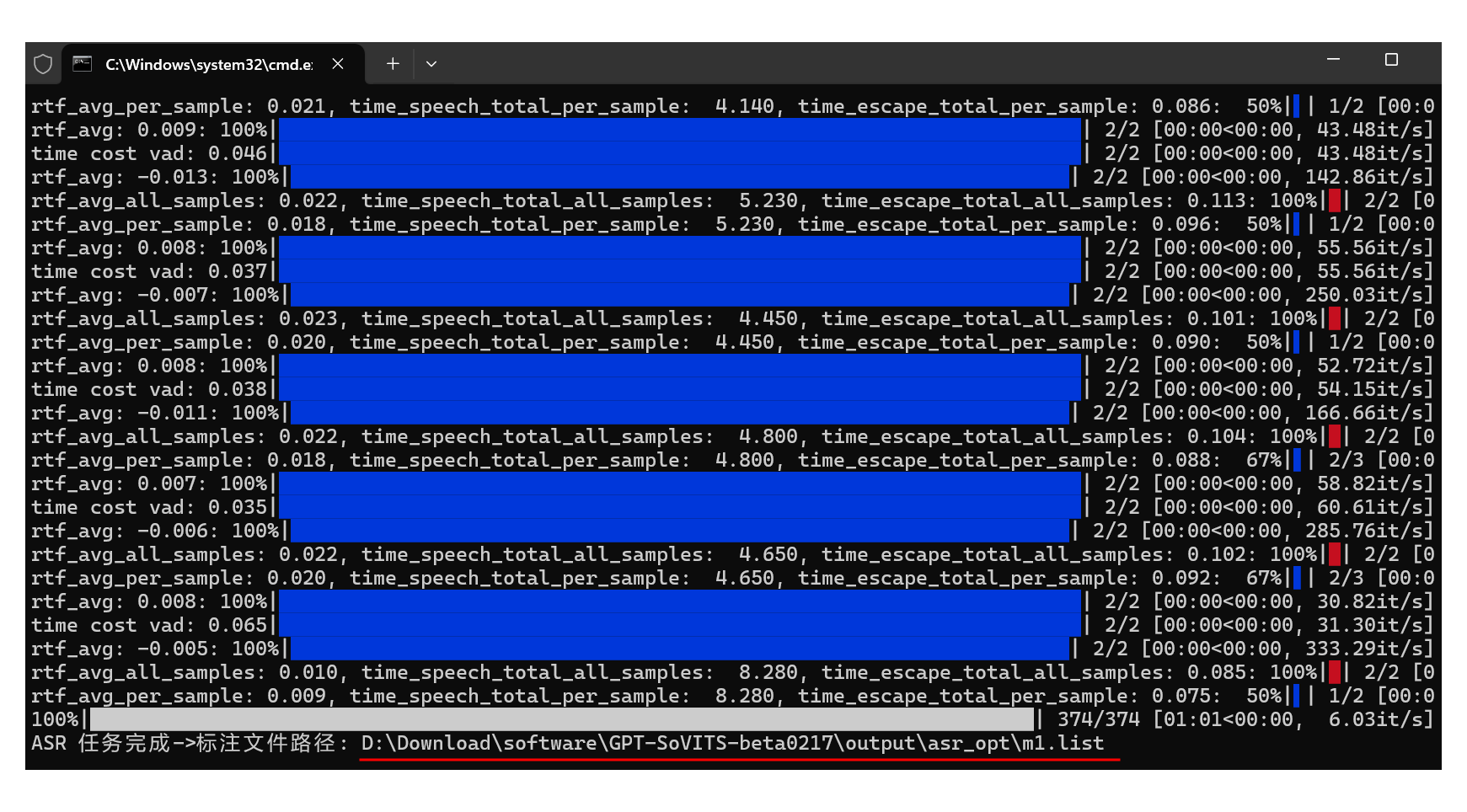
执行过程就是分析每一段之前切割的小音频,全部识别完成后,显示了结果文件路径。
语音文本校对

先填写 “.list标注文件的路径”,就是上一步输出的文件路径。
然后,勾选 “是否开启打标WebUI”。
注意,一定要先填写好路径,再勾选
勾选后,等待几秒,会打开一个新的页面。
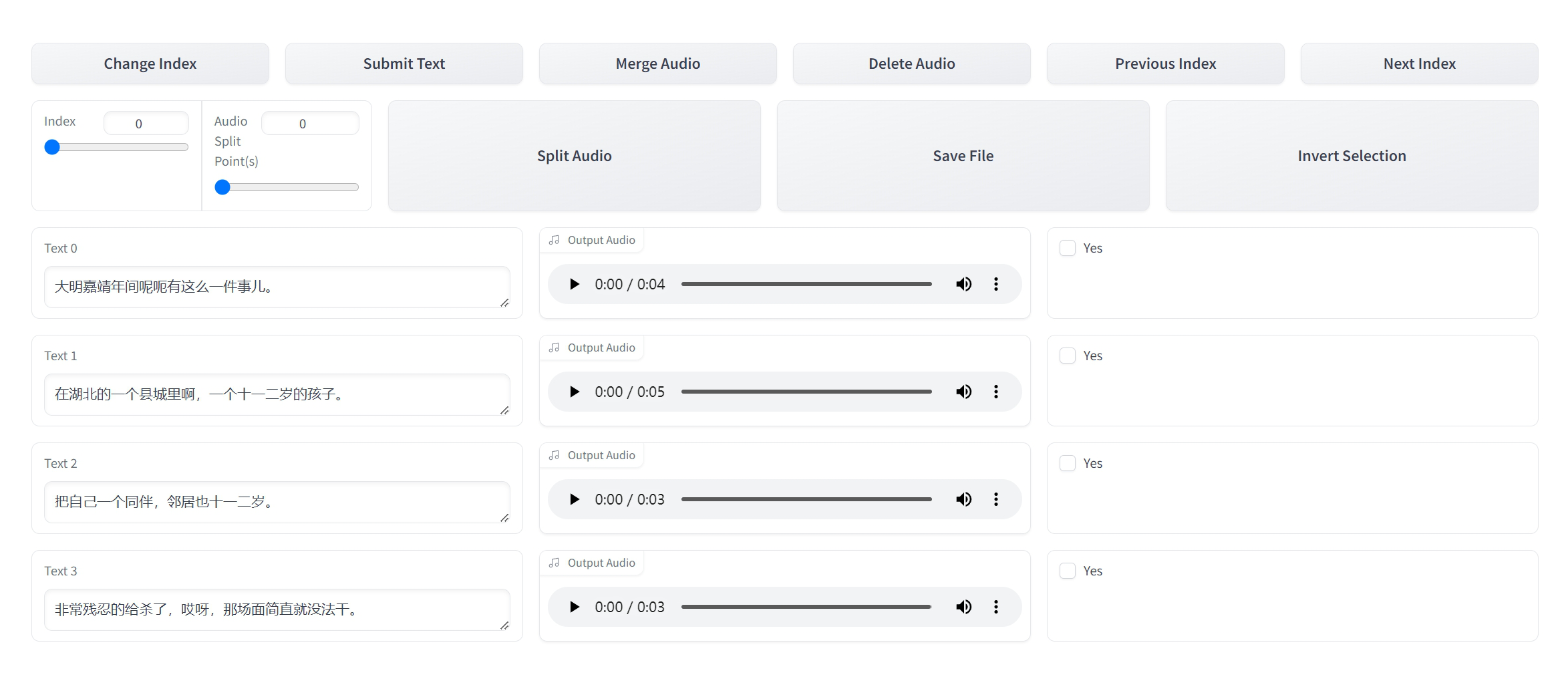
校对每一段语音对应的文本,修改识别错误的文字。
都修改完成后,点击顶部的 “Submit Text” 按钮,保存修改结果。
“.list” 后缀的标注文件其实就是文本文件,可以用记事本打开。
例如:

校对完成后,可以打开这个文件看看自己的修改是否保存成功了。
训练集格式化

点击 “1-GPT-SoVITS-TTS” 标签,默认打开 “1A-训练集格式化工具” 标签。
“实验/模型名” 自由填写,我还是使用 “m1”。
“文本标注文件” 填入“.list” 后缀的标注文件路径。
其他的不用改,点击 “开启一键三连” 大按钮,等待进程结束。
声音模型训练

点击 “1B-微调训练” 标签。
其中的参数都不需要动。
点击 “开启SoVITS训练”,耐心等待一会儿,等待进程结束。
再点击 “开启GPT训练”,耐心等待一会儿,等待进程结束。
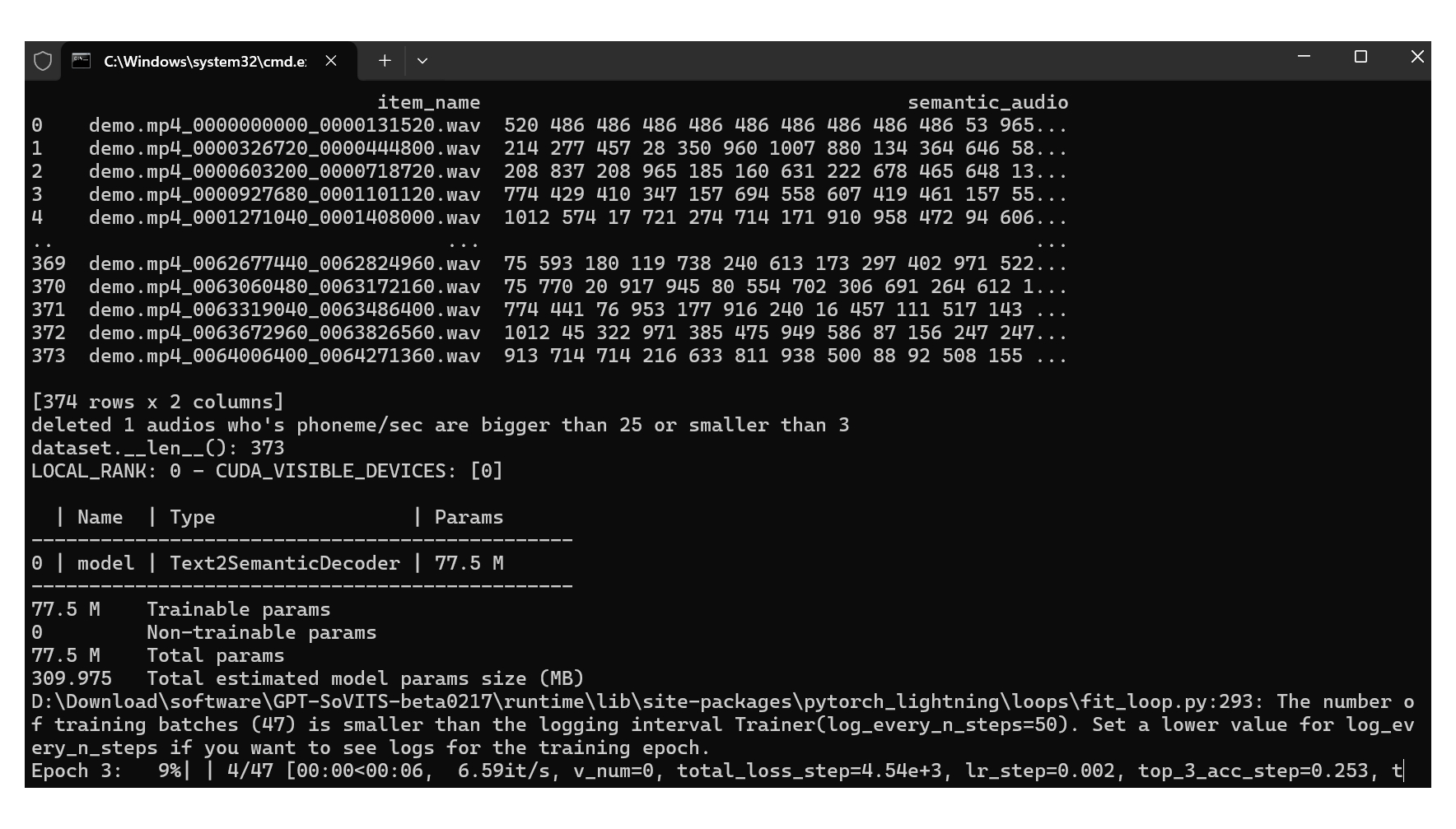
每个训练都包含多轮,所以会比较慢。
至此,声音模型的训练接完成了,可以使用我们的模型了。
3. 使用模型
点击 “1C-推理” 标签。
点击 “刷新模型路径” 大按钮。
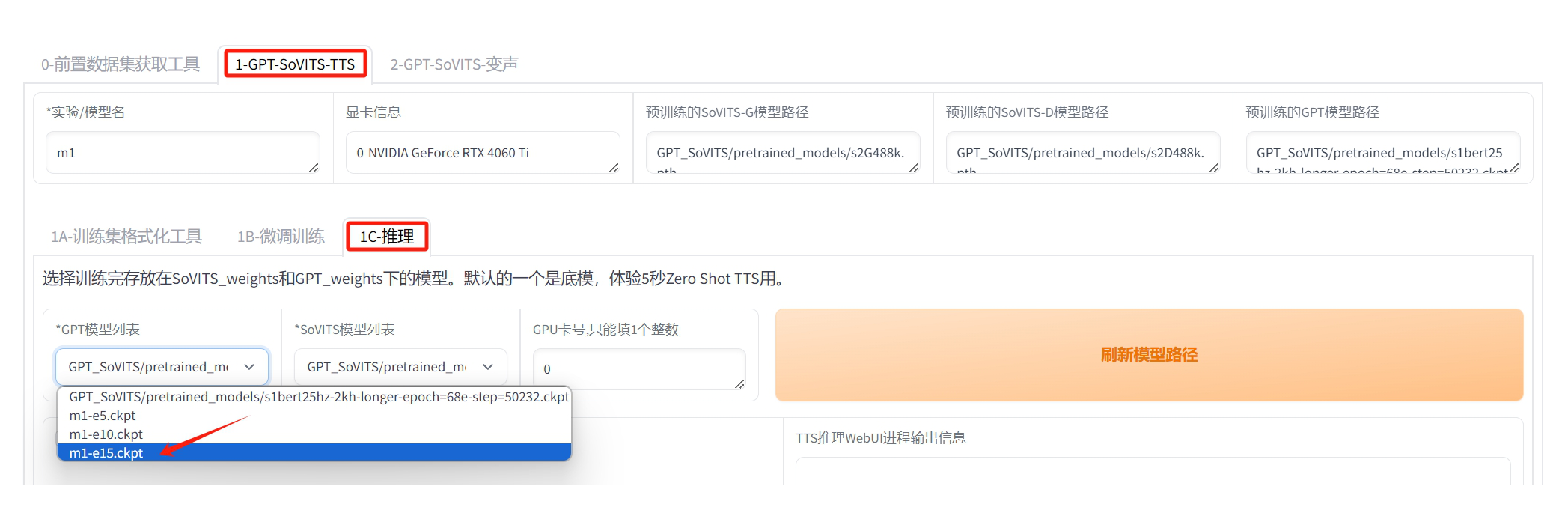

刷新后,模型列表中会列出我们训练的模型,选择 “e” 后面数字最大的。
然后,勾选 “是否开启TTS推理WebUI”。
勾选后,等待几面,会打开推理页面。
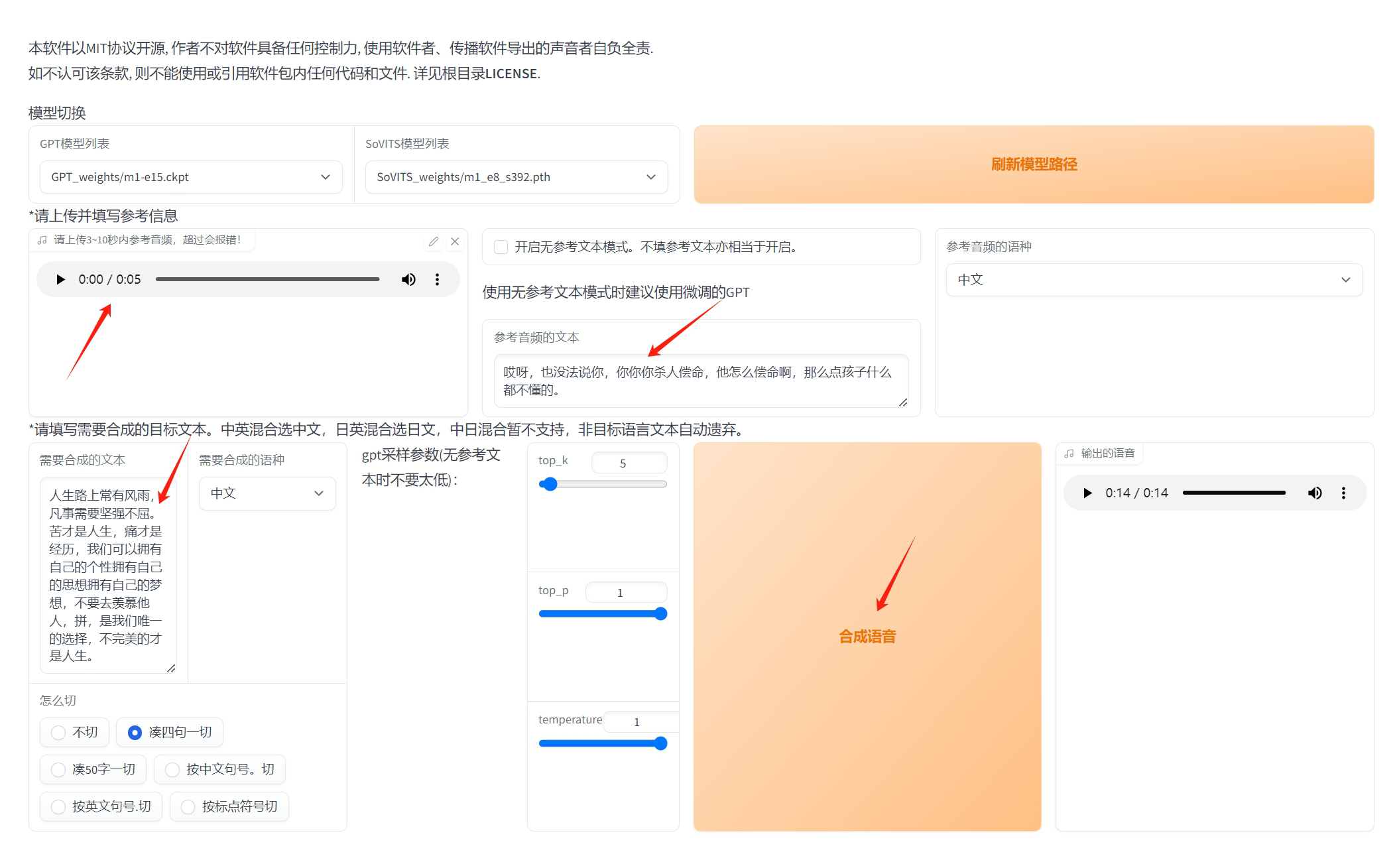
需要修改的有3处:
1)上传参考音频
从之前分割好的小音频中选择一个。
2)参考音频的文本
选择的音频所对应的文本
3)需要合成的文本
就是想要AI朗读的内容
然后,点击 “合成语音” 大按钮,等待输出结果。
搞定 !!!
不错吧,赶快试试吧。
地址:
github.com/RVC-Boss/GPT-SoVITS
#AI 人工智能,#AI 声音克隆,#TTS,#GPT-SoVITS,#gpt890
信息来源 gpt890.com/article/37


)




)




)






