强化学习笔记
主要基于b站西湖大学赵世钰老师的【强化学习的数学原理】课程,个人觉得赵老师的课件深入浅出,很适合入门.
第一章 强化学习基本概念
第二章 贝尔曼方程
文章目录
- 强化学习笔记
- 一、状态值函数贝尔曼方程
- 二、贝尔曼方程的向量形式
- 三、动作值函数
- 参考资料
第一章我们介绍了强化学习的基本概念,本章介绍强化学习中一个重要的概念——贝尔曼方程.
一、状态值函数贝尔曼方程
贝尔曼方程(Bellman Equation),也称为贝尔曼期望方程,用于计算给定策略 π \pi π时价值函数在策略指引下所采轨迹上的期望。考虑如下一个随机轨迹:
S t → A t R t + 1 , S t + 1 → A t + 1 R t + 2 , S t + 2 → A t + 2 R t + 3 , … \begin{aligned} &&&&S_t\xrightarrow{A_t}R_{t+1},S_{t+1}\xrightarrow{A_{t+1}}R_{t+2},S_{t+2}\xrightarrow{A_{t+2}}R_{t+3},\ldots \\ \end{aligned} StAtRt+1,St+1At+1Rt+2,St+2At+2Rt+3,…
那么累积回报 G t G_t Gt可以写成如下形式:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + … , = R t + 1 + γ ( R t + 2 + γ R t + 3 + … ) , = R t + 1 + γ G t + 1 . \begin{aligned} G_t &=R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\ldots, \\ &=R_{t+1}+\gamma(R_{t+2}+\gamma R_{t+3}+\ldots), \\ &=R_{t+1}+\gamma G_{t+1}. \end{aligned} Gt=Rt+1+γRt+2+γ2Rt+3+…,=Rt+1+γ(Rt+2+γRt+3+…),=Rt+1+γGt+1.
状态值函数的贝尔曼方程为:
v π ( s ) ≐ E π [ G t ∣ S t = s ] = E π [ R t + 1 + γ G t + 1 ∣ S t = s ] = ∑ a π ( a ∣ s ) ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] , ∀ s ∈ S . \begin{aligned} v_{\pi}(s)& \doteq\mathbb{E}_{\pi}[G_{t}\mid S_{t}=s] \\ &=\mathbb{E}_{\pi}[R_{t+1}+\gamma G_{t+1}\mid S_{t}=s] \\ &=\sum_a\pi(a|s)\sum_{s',r}p(s',r|s,a)\Big[r+\gamma v_\pi(s')\Big],\quad\forall s\in\mathcal{S}. \end{aligned} vπ(s)≐Eπ[Gt∣St=s]=Eπ[Rt+1+γGt+1∣St=s]=a∑π(a∣s)s′,r∑p(s′,r∣s,a)[r+γvπ(s′)],∀s∈S.
- 由值函数的定义出发,得到了一个关于 v v v的递推关系
下面再来详细的推导一下贝尔曼方程,由回报的定义,可以将 G t G_t Gt拆成两部分:
v π ( s ) = E [ G t ∣ S t = s ] = E [ R t + 1 + γ G t + 1 ∣ S t = s ] = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] . \begin{aligned} v_{\pi}\left(s\right)& =\mathbb{E}[G_{t}|S_{t}=s] \\ &=\mathbb{E}[R_{t+1}+\gamma G_{t+1}|S_{t}=s] \\ &=\mathbb{E}[R_{t+1}|S_{t}=s]+\gamma\mathbb{E}[G_{t+1}|S_{t}=s]. \end{aligned} vπ(s)=E[Gt∣St=s]=E[Rt+1+γGt+1∣St=s]=E[Rt+1∣St=s]+γE[Gt+1∣St=s].
首先考虑第一部分 E [ R t + 1 ∣ S t = s ] \mathbb{E}[R_{t+1}|S_t=s] E[Rt+1∣St=s],全概率公式的应用:
E [ R t + 1 ∣ S t = s ] = ∑ a π ( a ∣ s ) E [ R t + 1 ∣ S t = s , A t = a ] = ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r . \begin{aligned}\mathbb{E}[R_{t+1}|S_t=s]&=\sum_a\pi(a|s)\mathbb{E}[R_{t+1}|S_t=s,A_t=a]\\&=\sum_a\pi(a|s)\sum_rp(r|s,a)r. \end{aligned} E[Rt+1∣St=s]=a∑π(a∣s)E[Rt+1∣St=s,At=a]=a∑π(a∣s)r∑p(r∣s,a)r.
再来考虑第二部分 E [ G t + 1 ∣ S t = s ] \mathbb{E}[G_{t+1}|S_t=s] E[Gt+1∣St=s],第二个等式用到马尔可夫性质和全概率公式:
E [ G t + 1 ∣ S t = s ] = ∑ s ′ E [ G t + 1 ∣ S t = s , S t + 1 = s ′ ] p ( s ′ ∣ s ) = ∑ s ′ E [ G t + 1 ∣ S t + 1 = s ′ ] p ( s ′ ∣ s ) = ∑ s ′ v π ( s ′ ) p ( s ′ ∣ s ) = ∑ v π ( s ′ ) ∑ p ( s ′ ∣ s , a ) π ( a ∣ s ) . \begin{aligned} \mathbb{E}\left[G_{t+1}|S_{t}=s\right]& =\sum_{s^{\prime}}\mathbb{E}[G_{t+1}|S_{t}=s,S_{t+1}=s^{\prime}]p(s^{\prime}|s) \\ &=\sum_{s'}\mathbb{E}[G_{t+1}|S_{t+1}=s']p(s'|s) \\ &=\sum_{s^{\prime}}v_{\pi}(s^{\prime})p(s^{\prime}|s) \\ &=\sum v_{\pi}(s^{\prime})\sum p(s^{\prime}|s,a)\pi(a|s). \end{aligned} E[Gt+1∣St=s]=s′∑E[Gt+1∣St=s,St+1=s′]p(s′∣s)=s′∑E[Gt+1∣St+1=s′]p(s′∣s)=s′∑vπ(s′)p(s′∣s)=∑vπ(s′)∑p(s′∣s,a)π(a∣s).
以上两部分合起来:
v π ( s ) = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] , = ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r ⏟ mean of immediate rewards + γ ∑ a π ( a ∣ s ) ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) , ⏟ mean of future rewards = ∑ a π ( a ∣ s ) [ ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ] , ∀ s ∈ S = ∑ a π ( a ∣ s ) ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] , ∀ s ∈ S . \begin{aligned} v_{\pi}\left(s\right)& =\mathbb{E}[R_{t+1}|S_{t}=s]+\gamma\mathbb{E}[G_{t+1}|S_{t}=s], \\ &\begin{aligned}=\underbrace{\sum_a\pi(a|s)\sum_rp(r|s,a)r}_{\text{mean of immediate rewards}}+\underbrace{\gamma\sum_a\pi(a|s)\sum_{s'}p(s'|s,a)v_\pi(s'),}_{\text{mean of future rewards}}\end{aligned} \\ &=\sum_a\pi(a|s)\left[\sum_rp(r|s,a)r+\gamma\sum_{s^{\prime}}p(s^{\prime}|s,a)v_\pi(s^{\prime})\right],\forall s\in\mathcal{S}\\ &=\sum_a\pi(a|s)\sum_{s',r}p(s',r|s,a)\Big[r+\gamma v_\pi(s')\Big],\quad \forall s\in\mathcal{S}. \end{aligned} vπ(s)=E[Rt+1∣St=s]+γE[Gt+1∣St=s],=mean of immediate rewards a∑π(a∣s)r∑p(r∣s,a)r+mean of future rewards γa∑π(a∣s)s′∑p(s′∣s,a)vπ(s′),=a∑π(a∣s)[r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)],∀s∈S=a∑π(a∣s)s′,r∑p(s′,r∣s,a)[r+γvπ(s′)],∀s∈S.
Note:
- 贝尔曼公式给出了值函数的一个递推关系式
- 当前状态的值函数,可以由下一状态的值函数完全确定
下面的树状图形象的刻画了贝尔曼方程中几个求和符合,各变量之间的关系:
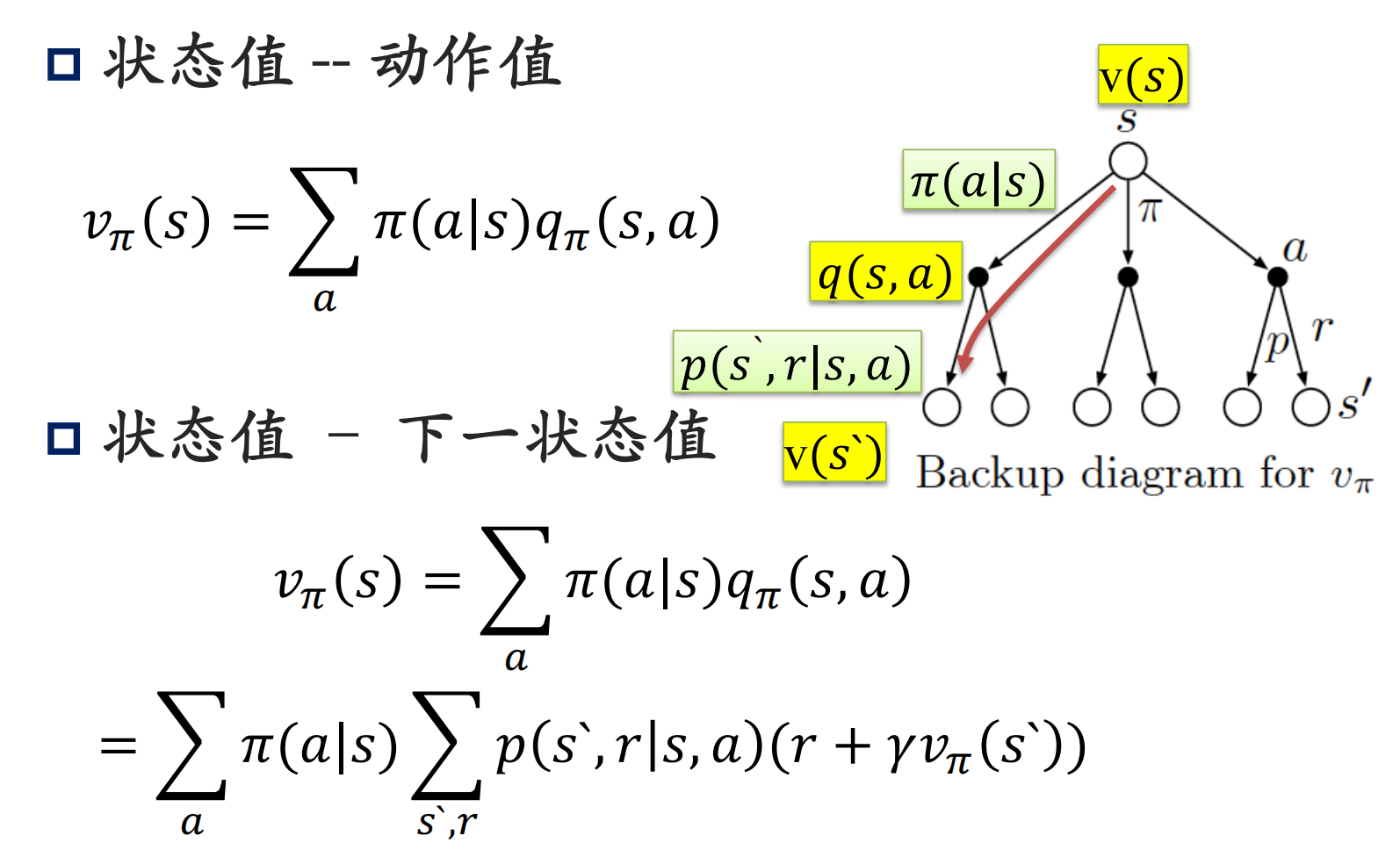
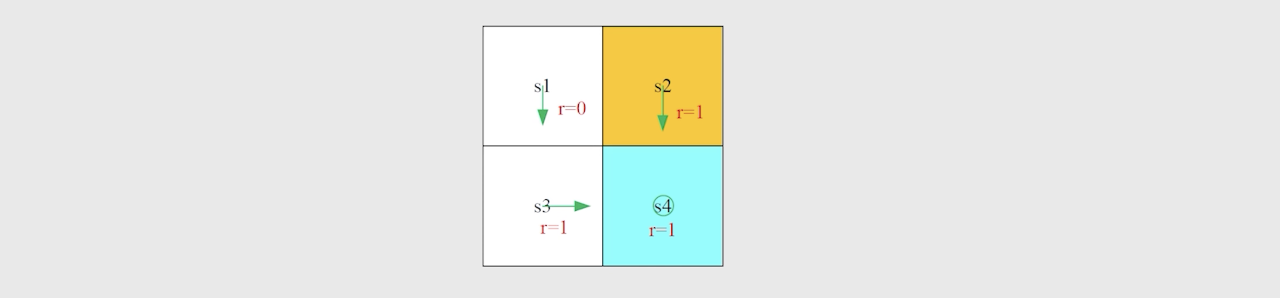
实例:
仍然是agent-网格问题,绿色箭头表示当前策略:

二、贝尔曼方程的向量形式
我们将贝尔曼公式拆成两项之和的形式:
v π ( s ) = r π ( s ) + γ ∑ s ′ p π ( s ′ ∣ s ) v π ( s ′ ) , v_\pi(s)=r_\pi(s)+\gamma\sum_{s^{\prime}}p_\pi(s^{\prime}|s)v_\pi(s^{\prime}), vπ(s)=rπ(s)+γs′∑pπ(s′∣s)vπ(s′),其中:
r π ( s ) ≜ ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r , p π ( s ′ ∣ s ) ≜ ∑ a π ( a ∣ s ) p ( s ′ ∣ s , a ) . \begin{aligned}r_\pi(s)\triangleq\sum_a\pi(a|s)\sum_rp(r|s,a)r,\quad p_\pi(s'|s)\triangleq\sum_a\pi(a|s)p(s'|s,a)\end{aligned}. rπ(s)≜a∑π(a∣s)r∑p(r∣s,a)r,pπ(s′∣s)≜a∑π(a∣s)p(s′∣s,a).
假设状态为 s i ( i = 1 , … , n ) s_i(i=1, \ldots, n) si(i=1,…,n),对于状态 s i s_i si, Bellman方程为:
v π ( s i ) = r π ( s i ) + γ ∑ s j p π ( s j ∣ s i ) v π ( s j ) ∀ i = 1 , … , n v_\pi\left(s_i\right)=r_\pi\left(s_i\right)+\gamma \sum_{s_j} p_\pi\left(s_j \mid s_i\right) v_\pi\left(s_j\right) \quad\forall i=1,\ldots ,n vπ(si)=rπ(si)+γsj∑pπ(sj∣si)vπ(sj)∀i=1,…,n
把所有状态的方程放在一起重写成矩阵-向量的形式
v π = r π + γ P π v π v_\pi=r_\pi+\gamma P_\pi v_\pi vπ=rπ+γPπvπ
其中
- v π = [ v π ( s 1 ) , … , v π ( s n ) ] T ∈ R n v_\pi=\left[v_\pi\left(s_1\right), \ldots, v_\pi\left(s_n\right)\right]^T \in \mathbb{R}^n vπ=[vπ(s1),…,vπ(sn)]T∈Rn
- r π = [ r π ( s 1 ) , … , r π ( s n ) ] T ∈ R n r_\pi=\left[r_\pi\left(s_1\right), \ldots, r_\pi\left(s_n\right)\right]^T \in \mathbb{R}^n rπ=[rπ(s1),…,rπ(sn)]T∈Rn
- P π ∈ R n × n P_\pi \in \mathbb{R}^{n \times n} Pπ∈Rn×n,其中 [ P π ] i j = p π ( s j ∣ s i ) \left[P_\pi\right]_{i j}=p_\pi\left(s_j \mid s_i\right) [Pπ]ij=pπ(sj∣si)为状态转移矩阵
实例:
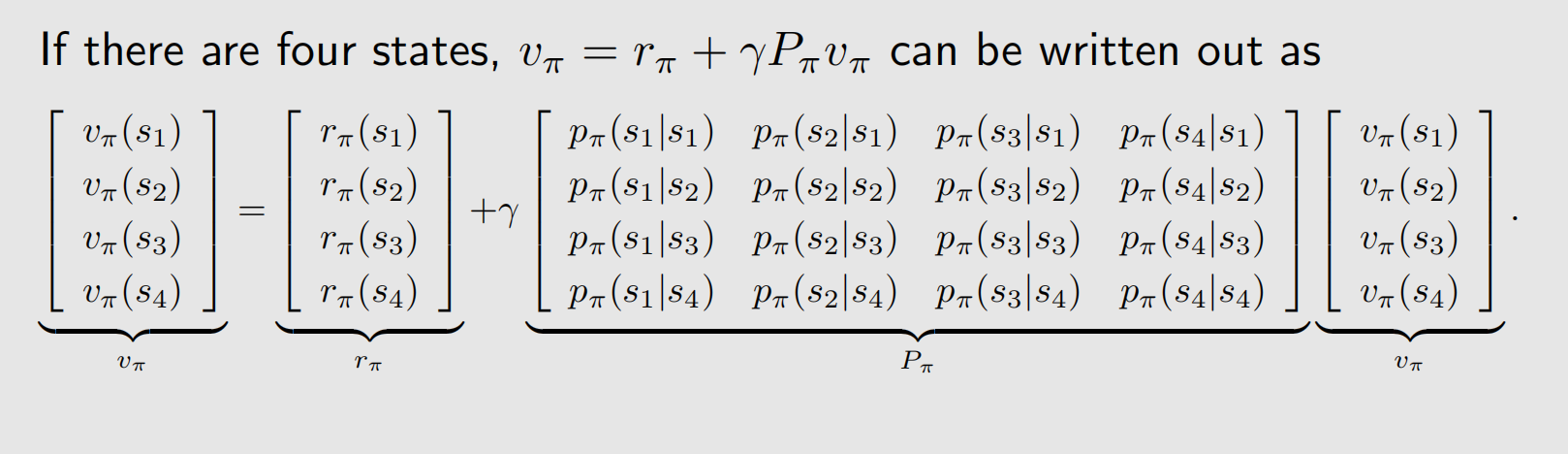
给定一个策略,算出出相应的状态值被称为策略评估,这是强化学习的一个基本问题。而通过上面的介绍我们知道要得到state value,可以求解贝尔曼方程。由刚刚介绍的贝尔曼方程矩阵形式:
v π = r π + γ P π v π v_\pi=r_\pi+\gamma P_\pi v_\pi vπ=rπ+γPπvπ易得:
v π = ( I − γ P π ) − 1 r π v_\pi=(I-\gamma P_\pi)^{-1}r_\pi vπ=(I−γPπ)−1rπ
但矩阵的求逆是 O ( n 3 ) O(n^3) O(n3)的复杂度,当矩阵很大时,求解效率很低。所以我们通常不用这个方法来解贝尔曼方程,而是采用迭代法(下一章详细介绍).迭代法格式如下:
v k + 1 = r π + γ P π v k \begin{aligned}v_{k+1}=r_\pi+\gamma P_\pi v_k\end{aligned} vk+1=rπ+γPπvk给定一个初始值 v 0 v_0 v0,可以得到迭代序列 { v 0 , v 1 , v 2 , … } . \{v_0,v_1,v_2,\ldots\}. {v0,v1,v2,…}. 并且可以证明
v k → v π = ( I − γ P π ) − 1 r π , k → ∞ v_k\to v_\pi=(I-\gamma P_\pi)^{-1}r_\pi,\quad k\to\infty vk→vπ=(I−γPπ)−1rπ,k→∞
也就是可以用迭代法,通过有限次迭代得到一个近似值.
三、动作值函数
由状态值函数与动作值函数的关系,我们有:
v π ( s ) = ∑ a π ( a ∣ s ) q π ( s , a ) . v_\pi(s)=\sum_a\pi(a|s)q_\pi(s,a). vπ(s)=a∑π(a∣s)qπ(s,a).
上小节关于状态值函数的贝尔曼方程为:
v π ( s ) = ∑ a π ( a ∣ s ) ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] v_{\pi}(s)=\sum_a\pi(a|s)\sum_{s',r}p(s',r|s,a)\Big[r+\gamma v_\pi(s')\Big] vπ(s)=a∑π(a∣s)s′,r∑p(s′,r∣s,a)[r+γvπ(s′)]
两式对比我们可以得到动作值函数的贝尔曼方程:
q π ( s , a ) = ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] q_\pi(s,a)=\sum_{s',r}p(s',r|s,a)\Big[r+\gamma v_\pi(s')\Big] qπ(s,a)=s′,r∑p(s′,r∣s,a)[r+γvπ(s′)]
总结一下:
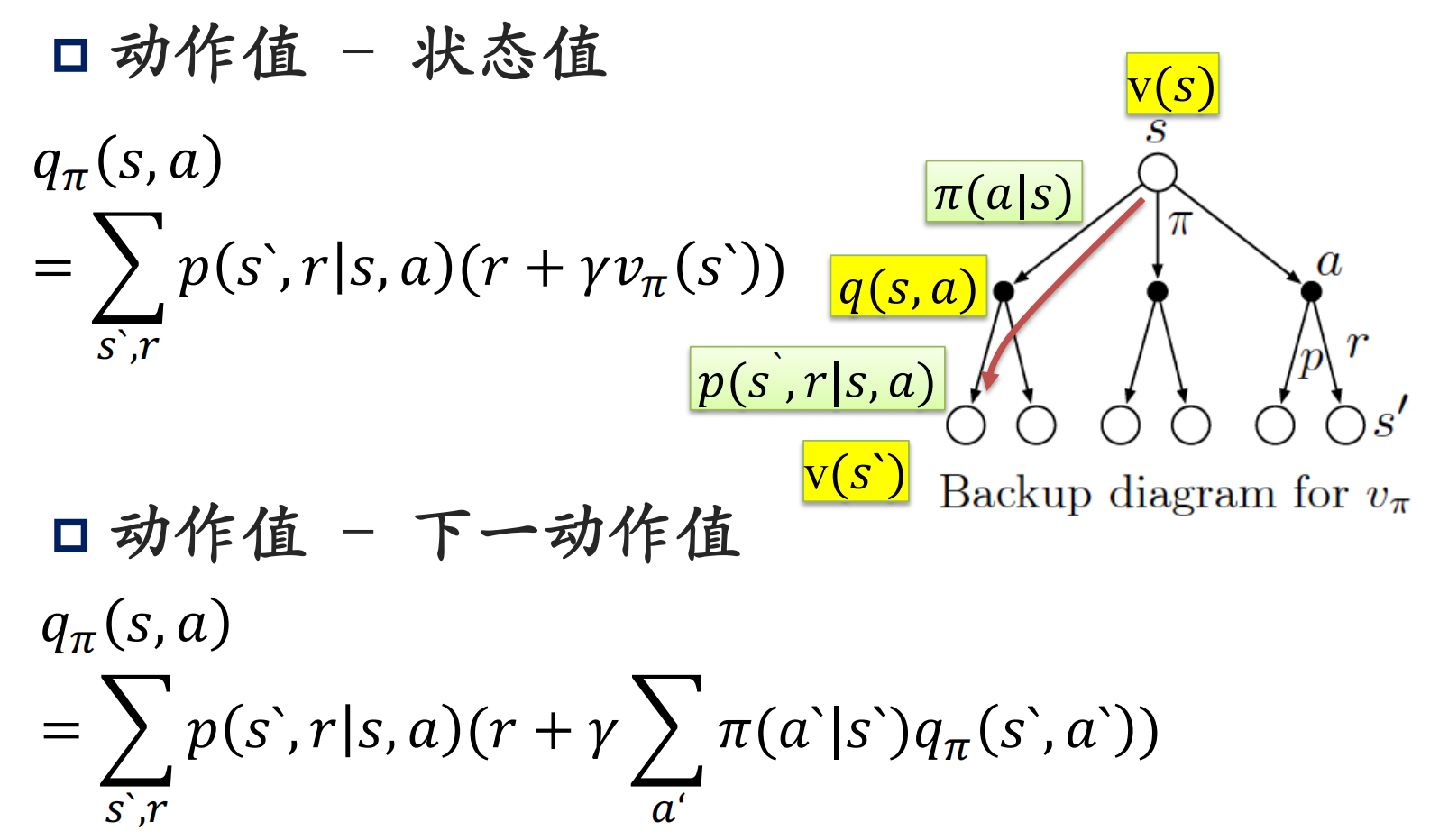
参考资料
- Zhao, S… Mathematical Foundations of Reinforcement Learning. Springer Nature Press and Tsinghua University Press.
- Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. MIT press, 2018.
)



架构设计类)









的介绍和python实现)

)


