什么是 RAG?其全称为 Retrieval-Augmented Generation,即检索增强生成,它结合了检 索和生成的能力,为文本序列生成任务引入外部知识。RAG 将传统的语言生成模型与大规模 的外部知识库相结合,使模型在生成响应或文本时可以动态地从这些知识库中检索相关信息。
RAG 的工作原理可以概括为几个步骤 :
- 检索:对于给定的输入(问题),模型首先使用检索系统从大型文档集合中查找相关的文档 或段落。这个检索系统通常基于密集向量搜索,例如 ChromaDB、Faiss 这样的向量数据库。
- 上下文编码:找到相关的文档或段落后,模型将它们与原始输入(问题)一起编码。
- 生成:使用编码的上下文信息,模型生成输出(答案)。这通常当然是通过大模型完成的。
RAG 的一个关键特点是,它不仅仅依赖于训练数据中的信息,还可以从大型外部知识库中检 索信息。 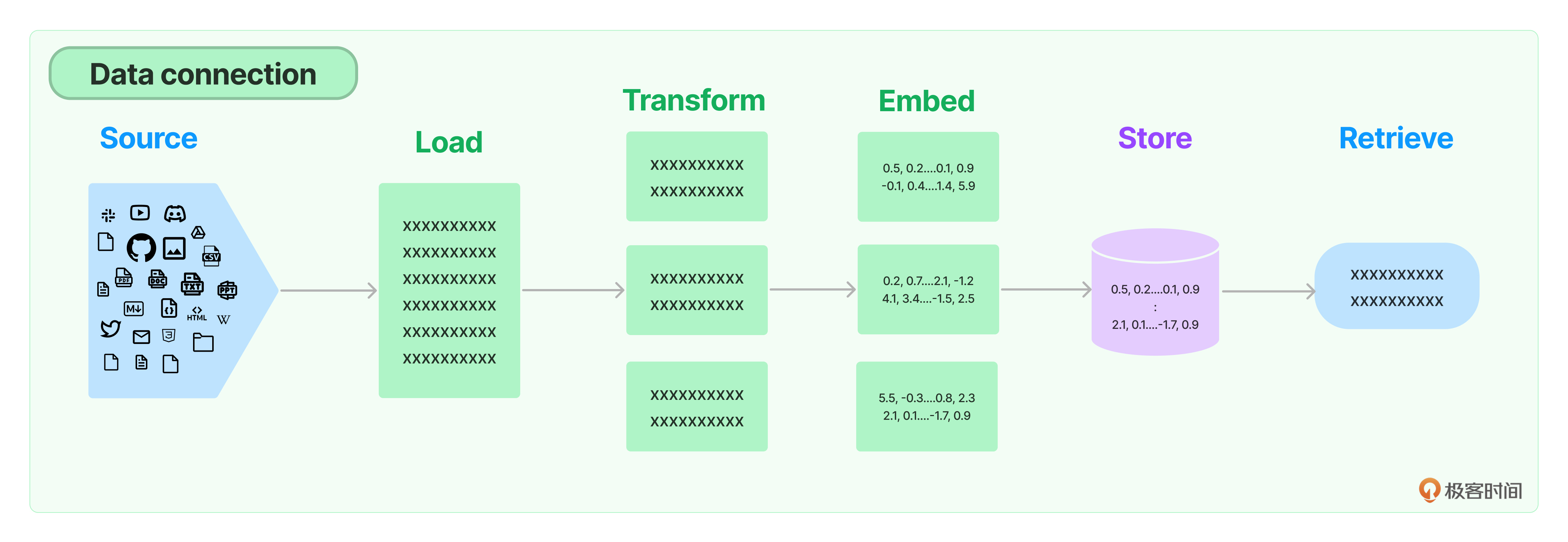
文档加载
RAG 的第一步是文档加载。LangChain 提供了多种类型的文档加载器,以加载各种类型的文 档(HTML、PDF、代码),并与该领域的其他主要提供商如 Airbyte 和 Unstructured.IO 进 行了集成。 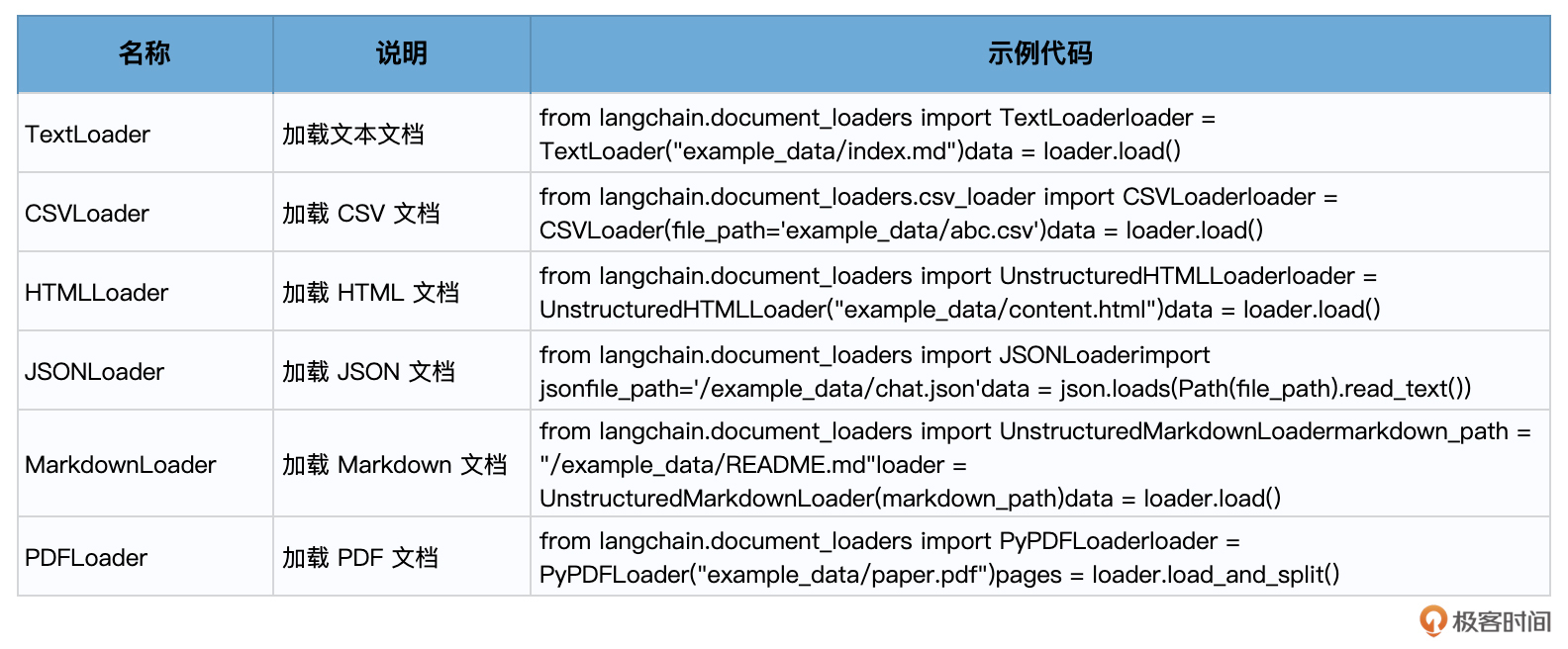
文本转换
加载文档后,下一个步骤是对文本进行转换,而最常见的文本转换就是把长文档分割成更小的 块(或者是片,或者是节点),以适合模型的上下文窗口。LangChain 有许多内置的文档转 换器,可以轻松地拆分、组合、过滤和以其他方式操作文档。
文本分割器
理想情况下,我们希望将语义相关的文本片段保留在一起
LangChain 中,文本分割器的工作原理如下:
- 将文本分成小的、具有语义意义的块(通常是句子)。
- 开始将这些小块组合成一个更大的块,直到达到一定的大小。
- 一旦达到该大小,一个块就形成了,可以开始创建新文本块。这个新文本块和刚刚生成的块
要有一些重叠,以保持块之间的上下文。
但是存在几个问题:
- 文本如何分割
- 块的大小
- 块之间重叠文本的长度
- 需要细致查看文本的任务,最好使用较小的分块。例如,拼写检查、语法检查和文本分析可 能需要识别文本中的单个单词或字符。垃圾邮件识别、查找剽窃和情感分析类任务,以及搜 索引擎优化、主题建模中常用的关键字提取任务也属于这类细致任务。
- 需要全面了解文本的任务,则使用较大的分块。例如,机器翻译、文本摘要和问答任务需要 理解文本的整体含义。而自然语言推理、问答和机器翻译需要识别文本中不同部分之间的关 系。还有创意写作,都属于这种粗放型的任务。
最后,你也要考虑所分割的文本的性质。例如,如果文本结构很强,如代码或 HTML,你可能 想使用较大的块,如果文本结构较弱,如小说或新闻文章,你可能想使用较小的块。
其他形式的文本转换
除拆分文本之外,LangChain 中还集成了各种工具对文档执行的其他类型的转换。
- 过滤冗余的文档:使用 EmbeddingsRedundantFilter 工具可以识别相似的文档并过滤掉冗余信息。
- 翻译文档:通过与工具 doctran 进行集成,可以将文档从一种语言翻译成另一种语言。
- 提取元数据:通过与工具 doctran 进行集成,可以从文档内容中提取关键信息(如日期、 作者、关键字等),并将其存储为元数据。
- 转换对话格式:通过与工具 doctran 进行集成,可以将对话式的文档内容转化为问答 (Q/A)格式,从而更容易地提取和查询特定的信息或回答。
文本嵌入
文本块形成之后,我们就通过 LLM 来做嵌入(Embeddings),将文本转换为数值表示,使 得计算机可以更容易地处理和比较文本。
Embeddings 会创建一段文本的向量表示,让我们可以在向量空间中思考文本,并执行语义 搜索之类的操作,在向量空间中查找最相似的文本片段。 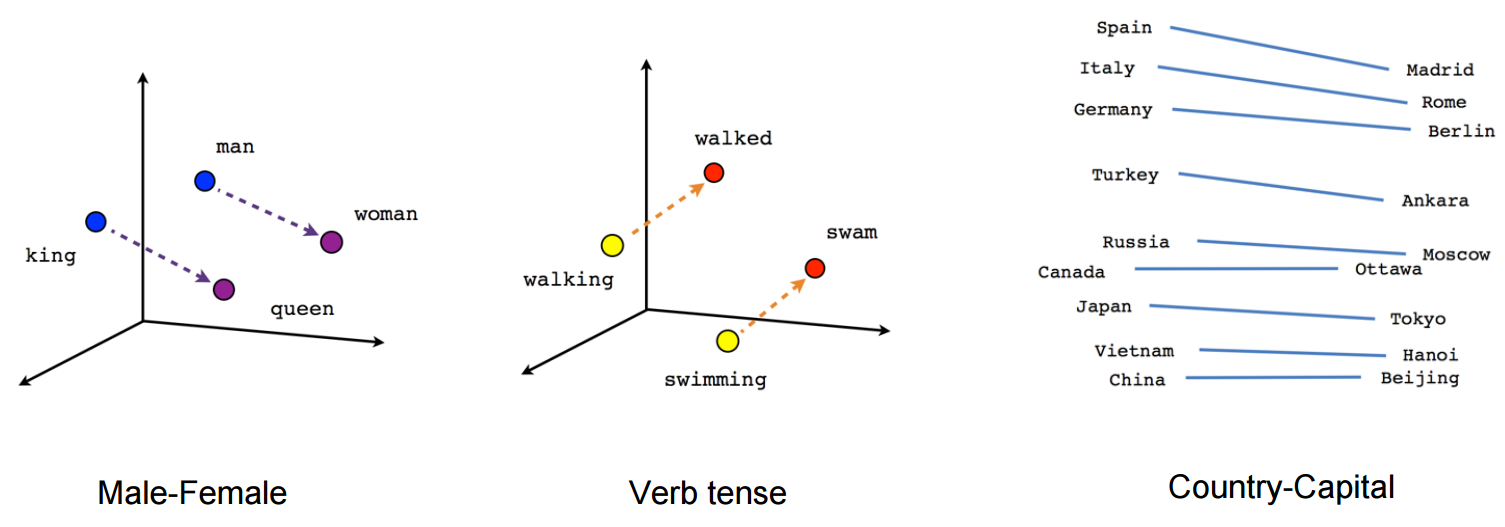
# 初始化Embedding类
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
它提供两种方法:
- embed_documents 方法,为文档创建嵌入。这个方法接收多个文本作为输入,
意味着你可以一次性将多个文档转换为它们的向量表示。 - embed_query 方法,为查询创建嵌入。这个方法只接收一个文本作为输入,通
常是用户的搜索查询。
embed_documents 方法的示例代码如下:
embeddings = embeddings_model.embed_documents(
[
"您好,有什么需要帮忙的吗?",
"哦,你好!昨天我订的花几天送达",
"请您提供一些订单号?",
"12345678",
]
)
len(embeddings), len(embeddings[0])
# 输出
(4, 1536)embedded_query = embeddings_model.embed_query("刚才对话中的订单号是多少?")
embedded_query[:3]
# 输出
[-0.0029746221837547455, -0.007710168602107487, 0.00923260021751183]
存储嵌入
计算嵌入可能是一个时间消耗大的过程。为了加速这一过程,我们可以将计算出的嵌入存储或 临时缓存,这样在下次需要它们时,就可以直接读取,无需重新计算。
缓存存储
CacheBackedEmbeddings 是一个支持缓存的嵌入式包装器,它可以将嵌入缓存在键值存储中。具体操作是:对文本进行哈希处理,并将此哈希值用作缓存的键。
**主要的方式是使用 from_bytes_store **
- underlying_embedder:实际计算嵌入的嵌入器。
- document_embedding_cache:用于存储文档嵌入的缓存。
- namespace(可选):用于文档缓存的命名空间,避免与其他缓存发生冲突。
不同的缓存策略如下:
- InMemoryStore:在内存中缓存嵌入。主要用于单元测试或原型设计。如果需要长期存储嵌入,请勿使用此缓存。
- LocalFileStore:在本地文件系统中存储嵌入。适用于那些不想依赖外部数据库或存储解决 方案的情况。
- RedisStore:在 Redis 数据库中缓存嵌入。当需要一个高速且可扩展的缓存解决方案时, 这是一个很好的选择。
在内存中缓存嵌入的示例代码如下
# 导入内存存储库,该库允许我们在RAM中临时存储数据
from langchain.storage import InMemoryStore# 创建一个InMemoryStore的实例
store = InMemoryStore()# 导入与嵌入相关的库。OpenAIEmbeddings是用于生成嵌入的工具,而CacheBackedEmbeddings允许我们缓存这些嵌入
from langchain.embeddings import OpenAIEmbeddings, CacheBackedEmbeddings# 创建一个OpenAIEmbeddings的实例,这将用于实际计算文档的嵌入
underlying_embeddings = OpenAIEmbeddings()# 创建一个CacheBackedEmbeddings的实例。
# 这将为underlying_embeddings提供缓存功能,嵌入会被存储在上面创建的InMemoryStore中。
# 我们还为缓存指定了一个命名空间,以确保不同的嵌入模型之间不会出现冲突。
embedder = CacheBackedEmbeddings.from_bytes_store(underlying_embeddings, # 实际生成嵌入的工具store, # 嵌入的缓存位置namespace=underlying_embeddings.model # 嵌入缓存的命名空间
)# 使用embedder为两段文本生成嵌入。
# 结果,即嵌入向量,将被存储在上面定义的内存存储中。
embeddings = embedder.embed_documents(["你好", "智能鲜花客服"])
首先我们在内存中设置了一个存储空间,然后初始化了一个嵌入工具,该工 具将实际生成嵌入。之后,这个嵌入工具被包装在一个缓存工具中,用于为两段文本生成嵌 入
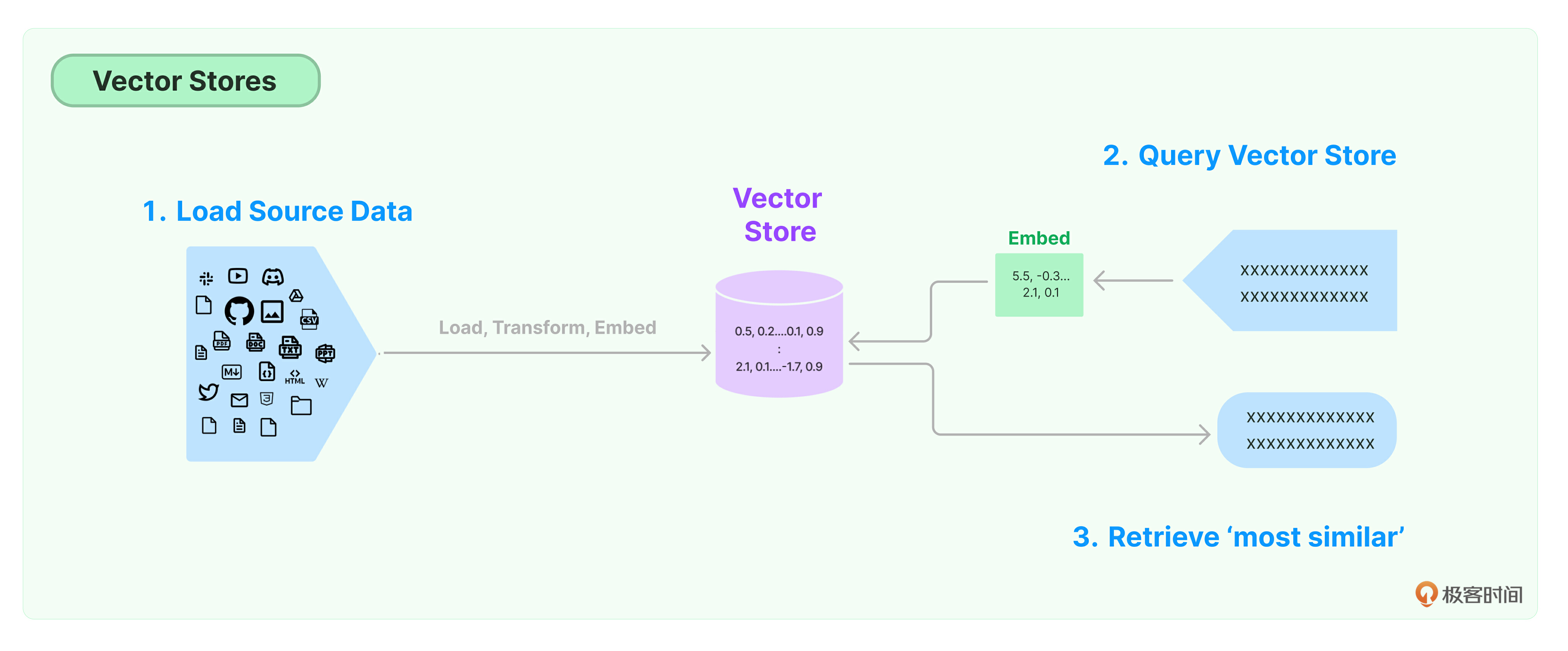
向量数据库(向量存储)
数据检索
向量存储检索器
下面实现一个端到端的数据检索功能,我们通过 VectorstoreIndexCreator 来创建索引,并在索引的 query 方法中,通过 vectorstore 类的 as_retriever 方法,把向量数据库(VectorStore)直接作为检索器,来完成检索任务。
# 设置OpenAI的API密钥
import os
os.environ["OPENAI_API_KEY"] = 'Your OpenAI Key'# 导入文档加载器模块,并使用TextLoader来加载文本文件
from langchain.document_loaders import TextLoader
loader = TextLoader('LangChainSamples/OneFlower/易速鲜花花语大全.txt', encoding='utf8')# 使用VectorstoreIndexCreator来从加载器创建索引
from langchain.indexes import VectorstoreIndexCreator
index = VectorstoreIndexCreator().from_loaders([loader])# 定义查询字符串, 使用创建的索引执行查询
query = "玫瑰花的花语是什么?"
result = index.query(query)
print(result) # 打印查询结果
这个实现看起来简单,是因为langchain把 vectorstore、embedding 以及 text_splitter,甚至 document loader 都封装了。
index.query(query),又是如何完成具体的检索及文本生成任务的呢?
在 VectorStoreIndexWrapper 类的 query 方法中,可以看到,在 调用方法的同时,RetrievalQA 链被启动,以完成检索功能。
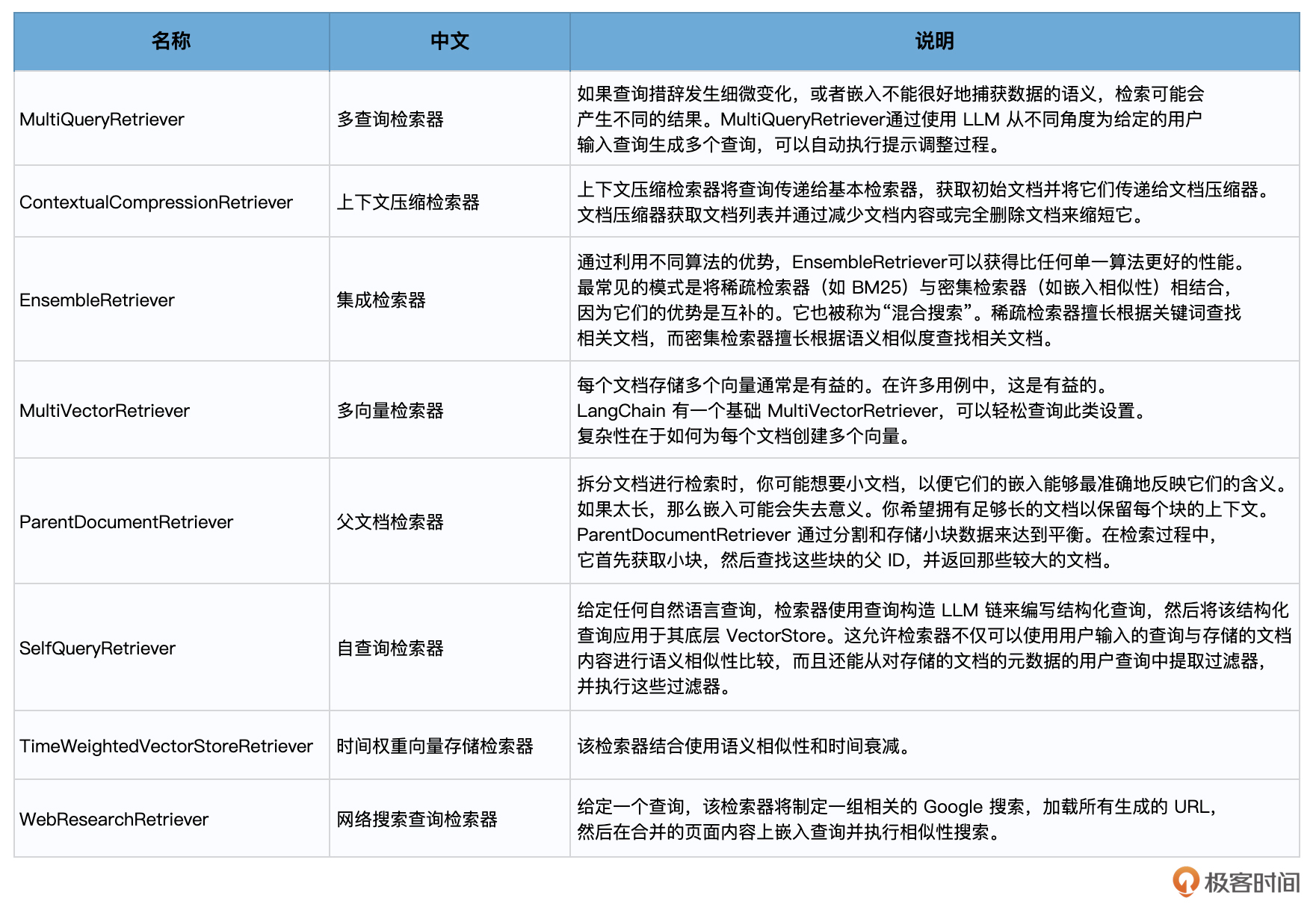
各种类型的检索器
索引
LangChain 提供的索引 API 为开 发者带来了一个高效且直观的解决方案。具体来说,它的优势包括:
- 避免重复内容:确保你的向量存储中不会有冗余数据。
- 只更新更改的内容:能检测哪些内容已更新,避免不必要的重写。
- 省时省钱:不对未更改的内容重新计算嵌入,从而减少了计算资源的消耗。
- 优化搜索结果:减少重复和不相关的数据,从而提高搜索的准确性。
在进行索引时,API 会对每个文档进行哈希处理,确保每个文档都有一个唯一的标识。这个哈 希值不仅仅基于文档的内容,还考虑了文档的元数据
一旦哈希完成,以下信息会被保存在记录管理器中:
- 文档哈希:基于文档内容和元数据计算出的唯一标识。
- 写入时间:记录文档何时被添加到向量存储中。
- 源 ID:这是一个元数据字段,表示文档的原始来源。
总结
【第二种是 embed_query 方法,为查询创建嵌入】一直有个疑问,如果query是需要“复杂理 解”的,那么是怎么通过“相似度”去match到文档内容的呢。比如文档是一片小说,而query 是:请解读文中描写主人翁心理活动的部分?这里面 LangChain 是否做了特殊处理?
问题特别好。这边LangChain并没有做特别的处理,而目前的LLM还无法处理超长的 文本。那么,首先:你的问题要非常细。解读心理活动,解读那部分?哪年哪月?哪个环境?你泛 泛,回答肯定不准。你问题细,就有可能检索出来相关的嵌入块。另外,工程上需要设计Metadata给 每个块,需要做Summary,需要考虑递归式的检索策略,分层的检索策略。这是另一个大课题了。
如果对文件切片时候,文件中的的问题和回答被切成2个不同的chunck那么经常会无法检 索到答案,这种场景有什么优化方法吗?
1. 一般来说,都可以在切片时设置上下文的重叠区域,也就是重叠窗口。可以设大一点。 2. 有一些包支持把上一个片,和下一个片,都作为Metadata来保存在索引中,这样,检索出一个片, 也就同时检索了上下文。 3. 如果你的文档都是一问,一答的形式。你可以自己修改切片逻辑,刻意的把问答捆绑在一起。







![[CF0526C] Om Nom and Candies 解题记录](http://pic.xiahunao.cn/[CF0526C] Om Nom and Candies 解题记录)






)
—— docker三大概念(镜像、容器、仓库))



