Model I/O
可以把对模型的使用过程拆解成三块,分别是输入提示(对应图中的Format)、调用模型(对应图中的Predict)和输出解析(对应图中的Parse)。这三块形成了一个整体,因此在LangChain中这个过程被统称为 Model I/O。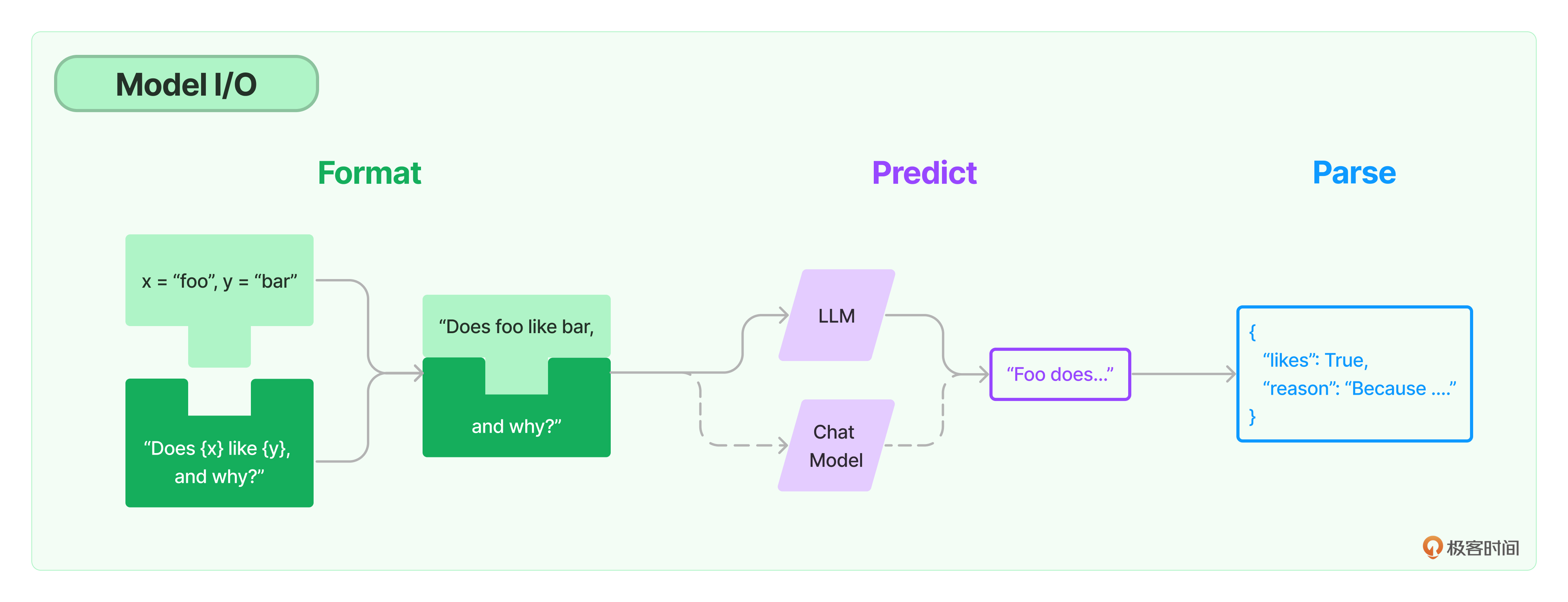
提示模板
提示工程:Prompt Engineering
吴恩达老师在他的提示工程课程中所说的:
- 给予模型清晰明确的指示
- 让模型慢慢地思考
# 导入LangChain中的提示模板
from langchain import PromptTemplate
# 创建原始模板
template = """
您是一位专业的鲜花店文案撰写员。\n
对于售价为 {price} 元的 {flower_name} ,您能提供一个吸引人的简短描述吗?
"""
# 根据原始模板创建LangChain提示模板
prompt = PromptTemplate.from_template(template)
# 打印LangChain提示模板的内容
print(prompt)
提示模板的具体内容如下:
input_variables=['flower_name', 'price']
output_parser=None partial_variables={}
template='/\n您是一位专业的鲜花店文案撰写员。
\n对于售价为 {price} 元的 {flower_name} ,您能提供一个吸引人的简短描述吗?\n'
template_format='f-string'
validate_template=True
LangChain 提供了多个类和函数,也为各种应用场景设计了很多内置模板,使构建和使用提示变得容易。
语言模型
LangChain中支持的模型有三大类。
- 大语言模型(LLM) ,也叫Text Model,这些模型将文本字符串作为输入,并返回文本字符串作为输出。Open AI的text-davinci-003、Facebook的LLaMA、ANTHROPIC的Claude,都是典型的LLM。
- 聊天模型(Chat Model),主要代表Open AI的ChatGPT系列模型。这些模型通常由语言模型支持,但它们的 API 更加结构化。具体来说,这些模型将聊天消息列表作为输入,并返回聊天消息。
- 文本嵌入模型(Embedding Model),这些模型将文本作为输入并返回浮点数列表,也就是Embedding。
接上面的代码:
# 导入LangChain中的OpenAI模型接口
from langchain import OpenAI
# 创建模型实例
model = OpenAI(model_name='text-davinci-003')
# 输入提示
input = prompt.format(flower_name=["玫瑰"], price='50')
# 得到模型的输出
output = model(input)
# 打印输出内容
print(output)
具体的提示:“您是一位专业的鲜花店文案撰写员。对于售价为 50 元的玫瑰,您能提供一个吸引人的简短描述吗?”
模型可以自由选择、自主训练,而调用模型的框架往往是有章法、而且可复用的。
输出解析
在开发具体应用的过程中,很明显我们不仅仅需要文字,更多情况下我们需要的是程序能够直接处理的、结构化的数据。
在这个文案中,如果你希望模型返回两个字段:
- description:鲜花的说明文本
- reason:解释一下为何要这样写上面的文案
A:“文案是:让你心动!50元就可以拥有这支充满浪漫气息的玫瑰花束,让TA感受你的真心爱意。为什么这样说呢?因为爱情是无价的,50元对应热恋中的情侣也会觉得值得。”
B:{description: “让你心动!50元就可以拥有这支充满浪漫气息的玫瑰花束,让TA感受你的真心爱意。” ; reason: “因为爱情是无价的,50元对应热恋中的情侣也会觉得值得。”}
像b这种数据结构,langchain中的输出解析器可以帮助我们实现
# 通过LangChain调用模型
from langchain import PromptTemplate, OpenAI# 导入OpenAI Key
import os
os.environ["OPENAI_API_KEY"] = '你的OpenAI API Key'# 创建原始提示模板
prompt_template = """您是一位专业的鲜花店文案撰写员。
对于售价为 {price} 元的 {flower_name} ,您能提供一个吸引人的简短描述吗?
{format_instructions}"""# 创建模型实例
model = OpenAI(model_name='text-davinci-003')# 导入结构化输出解析器和ResponseSchema
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
# 定义我们想要接收的响应模式
response_schemas = [ResponseSchema(name="description", description="鲜花的描述文案"),ResponseSchema(name="reason", description="问什么要这样写这个文案")
]
# 创建输出解析器
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)# 获取格式指示
format_instructions = output_parser.get_format_instructions()
# 根据原始模板创建提示,同时在提示中加入输出解析器的说明
prompt = PromptTemplate.from_template(prompt_template, partial_variables={"format_instructions": format_instructions}) # 数据准备
flowers = ["玫瑰", "百合", "康乃馨"]
prices = ["50", "30", "20"]# 创建一个空的DataFrame用于存储结果
import pandas as pd
df = pd.DataFrame(columns=["flower", "price", "description", "reason"]) # 先声明列名for flower, price in zip(flowers, prices):# 根据提示准备模型的输入input = prompt.format(flower_name=flower, price=price)# 获取模型的输出output = model(input)# 解析模型的输出(这是一个字典结构)parsed_output = output_parser.parse(output)# 在解析后的输出中添加“flower”和“price”parsed_output['flower'] = flowerparsed_output['price'] = price# 将解析后的输出添加到DataFrame中df.loc[len(df)] = parsed_output # 打印字典
print(df.to_dict(orient='records'))# 保存DataFrame到CSV文件
df.to_csv("flowers_with_descriptions.csv", index=False)输出
[{'flower': '玫瑰', 'price': '50', 'description': 'Luxuriate in the beauty of this 50 yuan rose, with its deep red petals and delicate aroma.', 'reason': 'This description emphasizes the elegance and beauty of the rose, which will be sure to draw attention.'},
{'flower': '百合', 'price': '30', 'description': '30元的百合,象征着坚定的爱情,带给你的是温暖而持久的情感!', 'reason': '百合是象征爱情的花,写出这样的描述能让顾客更容易感受到百合所带来的爱意。'},
{'flower': '康乃馨', 'price': '20', 'description': 'This beautiful carnation is the perfect way to show your love and appreciation. Its vibrant pink color is sure to brighten up any room!', 'reason': 'The description is short, clear and appealing, emphasizing the beauty and color of the carnation while also invoking a sense of love and appreciation.'}]
LangChain框架的好处:
模板管理、变量提取和检查、模型切换、输出解析
)



)


(二))


(关系模型))


之远程命令)




 快速入门)
