RSGPT: A Remote Sensing Vision Language Model and Benchmark
贡献:构建了一个高质量的遥感图像描述数据集(RSICap)和一个名为RSIEval的基准评估数据集,并在新创建的RSICap数据集上开发了基于微调InstructBLIP的遥感生成预训练模型(RSGPT)。通过仅微调Q-Former网络和InstructBLIP的线性层,模型可以快速学习以数据高效的方式将遥感图像的视觉特征与LLM对齐。
引言:
VLM是指集成计算机视觉和自然语言处理技术以实现对视觉和文本数据的整体理解的一类人工智能模型。通过同时分析视觉和语义模式,VLM 具有辨别视觉元素和语言信息之间复杂关系的能力,并提供更全面、更接近人类的视觉内容理解能力。
VLM 在遥感领域发展的一个具有挑战性的问题是缺乏大规模对齐的图像文本数据集。现有的RSI数据集大多专注于视觉识别任务,不提供语言注释。只有少数尝试构建图像文本RSI数据集,但数据规模和质量远未达到预期。
构建了一个高质量的遥感图像描述数据集(RSICap),以促进遥感领域大型 VLM 的开发。与之前采用模型生成的说明文字或简短描述的遥感数据集不同,RSICap 包含 2,585 个人工注释的说明文字,具有丰富且高质量的信息。该数据集提供每张图像的详细描述,包括场景描述(例如住宅区、机场或农田)以及物体信息(例如颜色、形状、数量、绝对位置等)。为了方便遥感领域VLM的评估,我们还提供了一个名为RSIEval的基准评估数据集。该数据集由人工注释的标题和视觉问答对组成,允许在遥感背景下对 VLM 进行全面评估。RSIEval由100个人工注释的标题和936个视觉问答对组成,包含丰富的信息和开放式的问题和答案。我们的目标是建立一个标准基准,涵盖各种遥感图像理解任务,包括图像字幕,视觉问题回答,视觉接地等。
在新创建的RSICap数据集上开发了基于微调InstructBLIP的遥感生成预训练模型(RSGPT)。通过仅微调Q-Former网络和InstructBLIP的线性层,模型可以快速学习以数据高效的方式将遥感图像的视觉特征与LLM对齐。
数据集介绍:
UCM-Captions 和Sydney-Captions:是最早的遥感图像字幕数据集,分别基于UCM数据集和Sydney数据集构建。
UCM-Captions:包含2100个图像和10500个字幕
Sydney-Captions:包含613个图像和3065个字幕
RSICD:包括10921张图像和54605个字幕,其中只有24333个不同的字幕
NWPUCaptions:包含31500张图片和157500个字幕。
这些数据集中的每幅图像都用五个简短的字幕进行了注释,但它们之间的差异相对较小,细节程度仅限于对主要场景的粗略描述。
RS5M:包含500万个对齐的图像文本对,平均标题长度为40个词汇。RS5M数据集是通过从公开可用的数据集(包括LAION400M和CC3 中仔细过滤RS相关图像,并利用BLIP2模型自动生成图像标题来创建的。
DOTA:来自不同卫星和航空传感器的图像,如GF-2,JL-1和Google Earth卫星图像,以及不同分辨率的航空图像。DOTA包括彩色和全色图像; DOTA数据集包含不同的场景。本文使用的DOTA-v1.5覆盖了16个对象类别; DOTA提供了类别和边界框标签,方便了感兴趣对象的统计计数。DOTA中图像的原始尺寸从800×800到4,000 × 4,000不等。
RSICaps:本文提出的数据集,是基于DOTA目标检测数据集构建RSICap。标题细节方面超过了RS5M数据集,平均长度为60个词汇。构建过程:将训练集中的图像分成大小为512×512的块,然后随机选择总共2,585块。五位遥感专家对图像作了注释。说明注记过程遵循以下原则:(1)描述图像属性,包括卫星/航空图像、彩色/全色图像和高/低分辨率;(2)描述对象属性,包括对象数量、颜色、形状、大小和空间位置(包括图像中的绝对位置和对象之间的相对位置);(3)一般而言,注释过程涉及首先描述图像的整体场景,然后描述特定对象。根据这些原则,我们生成了2,585个高质量的RS图像-文本对。
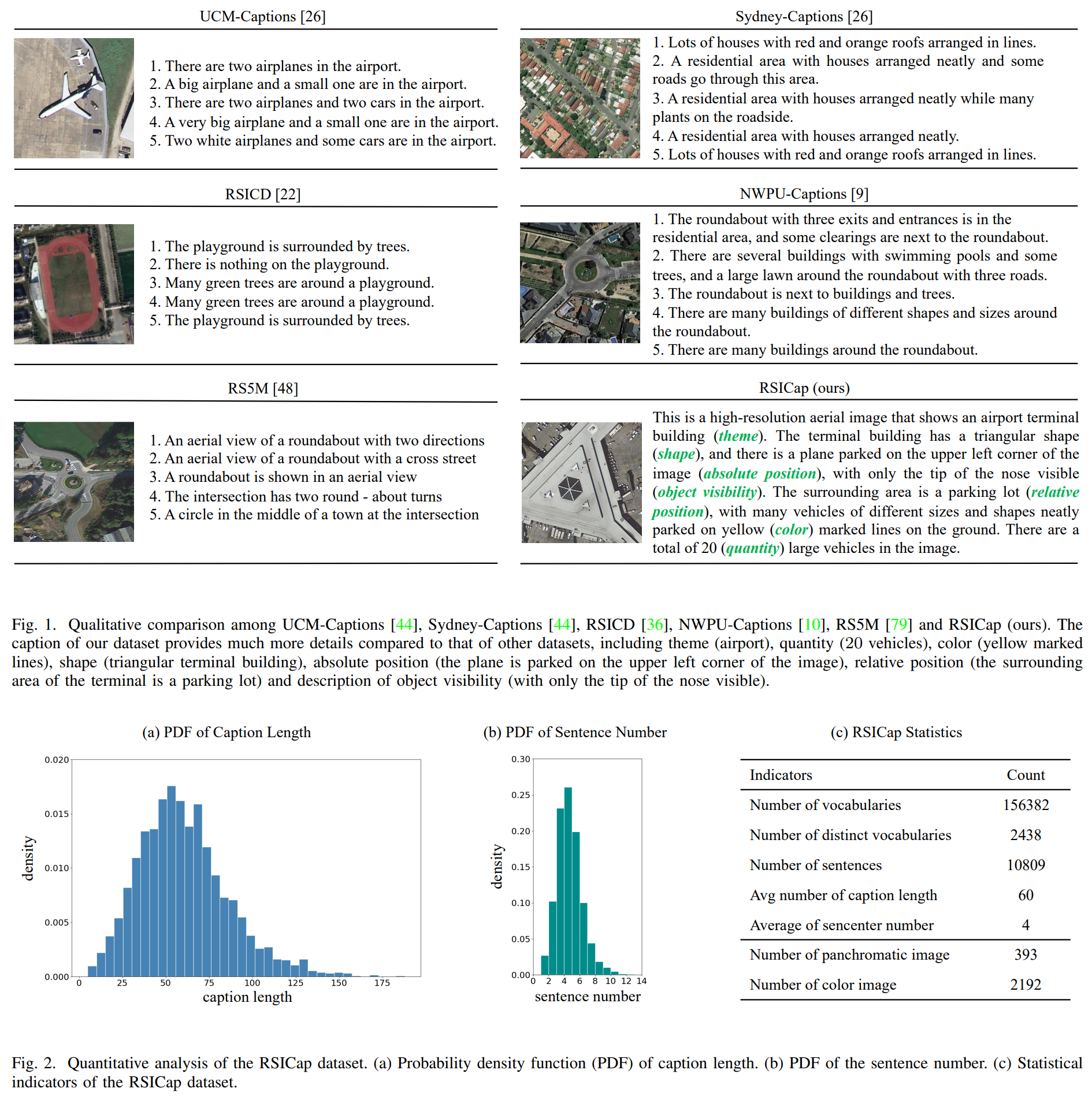
RSIEval:将DOTA-v1.5验证集中的图像分成大小为512×512的块,然后从这些块中选择100幅图像进行进一步的人工标注。5名遥感专家参加了注释。RSIEval由100个高质量的图像-标题对(每个图像一个标题)和936个不同的图像-问题-答案三元组(每个图像平均9个问题)组成。

方法:
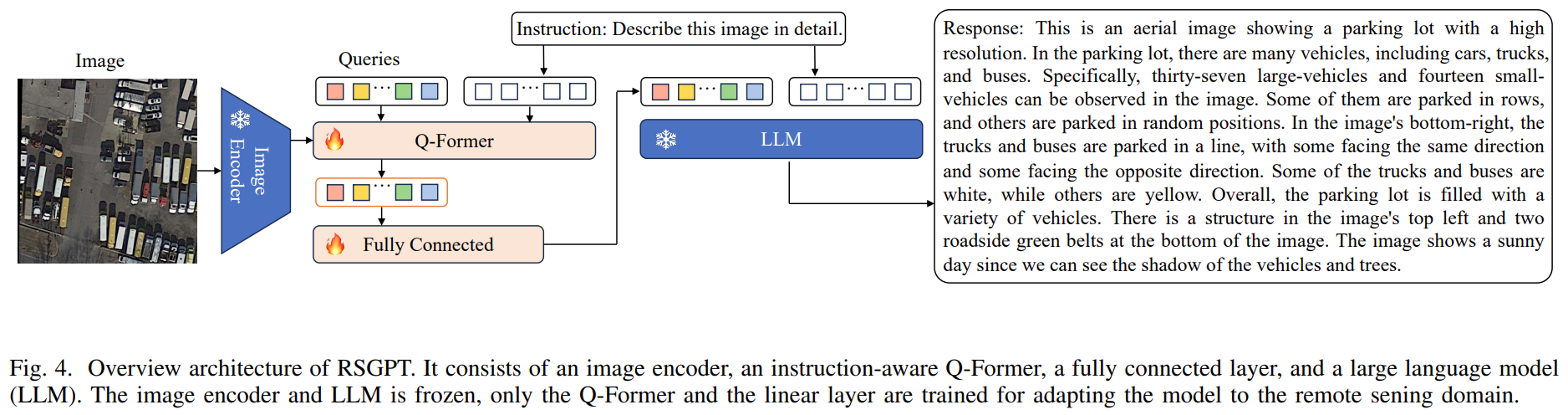
Image Encoder:EVA-G; LLM:vicuna7b, vicuna13b
线性层:把Q-Former输出映射到LLM输入特征空间
训练:将InstructBLIP的预训练权重集成到RSGPT中,用RSICap数据集微调RSGPT中的Q-Former和线性层。
实验:

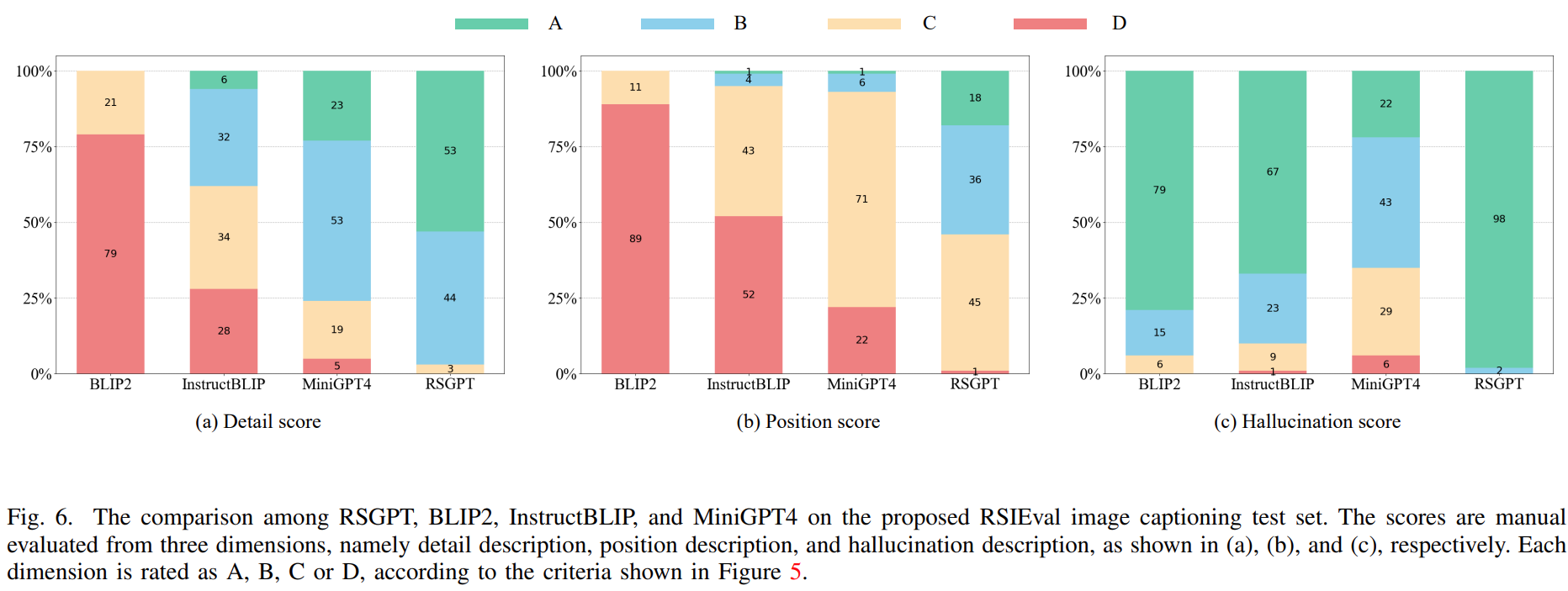
从细节描述、位置描述和幻觉描述三个维度对生成的遥感图像字幕质量进行四级评分。

RSICap数据集的分辨率多样性,场景多样性和合理推测的可视化。(a)RSICap涵盖不同分辨率的航空图像、全色卫星图像和彩色卫星图像。(b)RSICap覆盖机场、港口、网球场、居民区等多种场景。(c)注释器可以在标题生成期间添加合理推测的描述。

BLIP2、InstructBLIP、MiniGPT4和RSGPT在提出的RSIEval图像字幕测试集上的定性比较。详细描述、位置描述和幻觉描述的分数在括号中用粗体字表示。预测字幕中的幻觉描述以蓝色突出显示。

BLIP2、InstructBLIP、MiniGPT4和RSGPT在提出的RSIEval RSVQA测试集上的定性比较。问题类型在括号内以粗体显示。评分结果用对勾和叉号表示。

)

)


)


)


)
 TS-466C NAS 开箱评测,4盘位NAS,N6005,存储服务器)

——串的定义和基本操作)




)