1、引言
在日常的开发中,无论是主从复制还是哨兵模式,都在高并发的场景中存在致命的缺点:
- 主从复制:当Master Redis机器挂掉之后,Slave依旧可以读取数据,但是由于Master不能写数据了,所以就会导致这个时间段的数据直接存入数据库或者丢失。
- 哨兵模式:当进行Master机器扩展的时候,需要手动的配置哨兵集群,然后重新启动哨兵Redis,当哨兵Redis机器过多时,就会非常复杂且耗时。
Redis集群模式可以解决上述存在的问题,同时集群模式也是市面上推荐的方式。
1.1、Redis集群简介
Redis集群是一个提供在多个Redis节点间共享数据的程序集。它并不支持处理多个keys的命令,因为这需要在不同的节点间移换数据,从而达不到Redis那样的性能,特别是在高负载的情况下,可能会导致不可预料的错误。
Redis集群通过分区来提供一定程度的可用性。在实际环境中,当某个节点宕机或者不可达时,集群仍然能够继续处理命令。集群的主要优势在于它可以自动分隔数据到不同的节点,并在整个集群的部分节点失败或者不可达的情况下,仍然能够继续处理命令。
所有的Redis主节点彼此互联,采用PING-PONG机制进行通信,内部使用二进制协议优化传输速度和带宽。节点的失败是通过集群中超过半数的节点检测确认失效时才生效。客户端与Redis节点直连,不需要中间proxy层,客户端只需要连接集群中任何一个可用的节点即可。
1.2、集群搭建的重要性与优势
(1)重要性:
- 数据可靠性:集群搭建能够确保数据在多个节点间进行备份和同步,从而防止单点故障导致的数据丢失。当某个节点出现故障时,其他节点可以接管其工作,确保系统的连续性和数据的完整性。
- 性能提升:通过集群搭建,可以将数据分布在多个节点上,实现负载均衡。这不仅可以提高系统的吞吐量,降低延迟,还能够应对高并发读写请求,从而提升系统的整体性能。
- 扩展性:随着业务的发展,数据量可能会急剧增长。集群搭建使得Redis能够水平扩展,通过动态添加或删除节点来适应不同的数据量和性能需求。
(2)优势:
- 高可用性与容错性:Redis集群通过数据分片和数据复制来提供高可用性和容错性。即使部分节点发生故障,集群仍然能够继续工作,并通过数据复制从其他节点获取数据,保证服务的连续性。
- 简化管理:集群搭建可以统一管理和监控多个Redis节点,降低了单独管理每个节点的复杂性。此外,通过集群管理工具,可以方便地执行节点添加、删除、扩容等操作,提高了运维效率。
- 资源利用优化:集群可以根据节点的负载情况动态分配数据,实现资源的均衡利用。这不仅可以避免某些节点过载,还可以确保整个集群的性能得到充分发挥。
1.3、集群搭建前的准备工作
- 了解Redis 7的主从复制,可以看我之前的博客:Redis 7.0版本主从复制机制
- 熟悉使用Docker拉去镜像、启动容器。
2、Redis集群基础知识
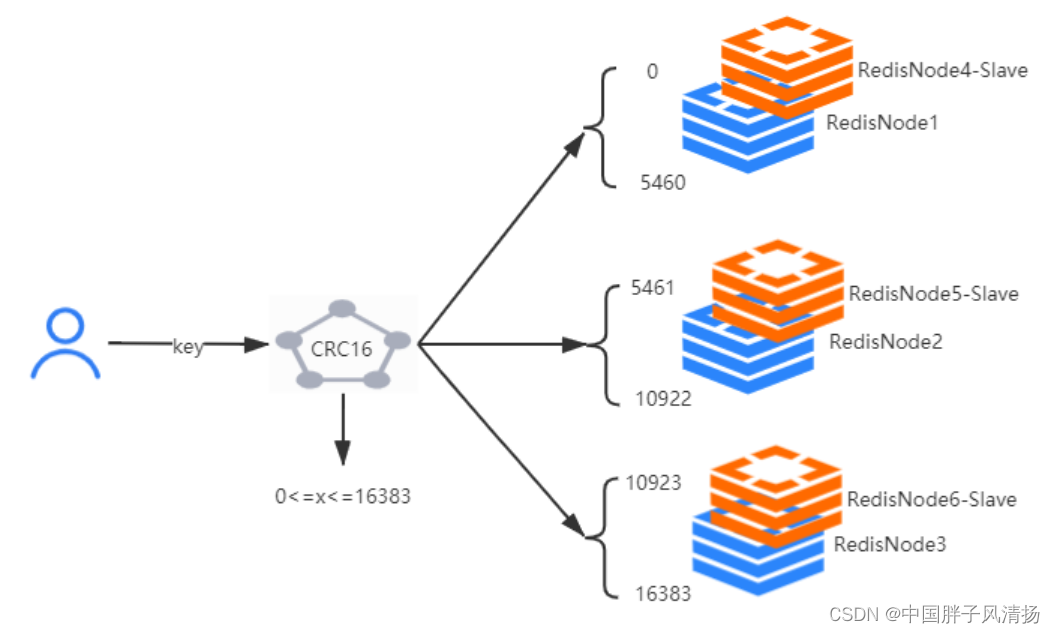
(1)Key的分布式模型
Hash_Slot = CRC16(key) % 16384
集群的密钥空间被分成16384个槽,有效的设置了16384个主节点的集群大小上限,官方建议最大节点大小为1000个节点。
(2)槽位Slot
Redis集群没有使用一致性Hash而是引入了Hash槽的概念,Redis集群有16384个Hash槽,每个Key通过CRC16检验后对16384去模来决定放置在哪个槽中,每个节点负责一部分Hash槽。
可以将集群看作一个小区,每个节点都是一栋楼,而Slot就是每栋楼中的房间,每个Slot会存在一个Slot号,也就是房间号。
Redis集群的原理主要基于数据分片和节点间的通信机制,以实现数据的分布式存储和访问。
2.1、数据分片
Redis集群将数据分散存储在多个节点上,通过一种称为“哈希槽”(hash slot)的机制来实现数据分片。在Redis集群中,一共有16384个哈希槽,每个节点负责处理一部分哈希槽。当客户端需要访问某个key时,Redis会根据key的哈希值计算其所属的哈希槽,然后找到负责处理该哈希槽的节点进行访问。这种数据分片的方式使得数据可以均匀地分布在各个节点上,提高了系统的存储能力和并发处理能力。
2.2、节点通信
Redis集群中的节点通过Gossip协议进行彼此通信,以维护集群的元数据和状态信息。Gossip协议是一种去中心化的通信机制,节点之间不断交换信息,最终使得每个节点都拥有集群的完整视图。在Redis集群中,每个节点都会定期向其他节点发送ping消息,以检测节点的存活状态,并交换集群的元数据。当某个节点出现故障时,其他节点可以通过通信机制感知到,并采取相应的措施进行故障转移和数据恢复。
2.3、智能路由
Redis集群提供了智能路由功能,使得客户端可以透明地访问集群中的数据。当客户端发送一个请求到任意一个节点时,该节点会根据请求的key计算其所属的哈希槽,并判断自己是否负责处理该哈希槽。如果负责,则直接处理该请求;如果不负责,则根据集群的元数据将请求转发到正确的节点上。这种智能路由机制使得客户端无需关心数据的具体存储位置,简化了访问过程。
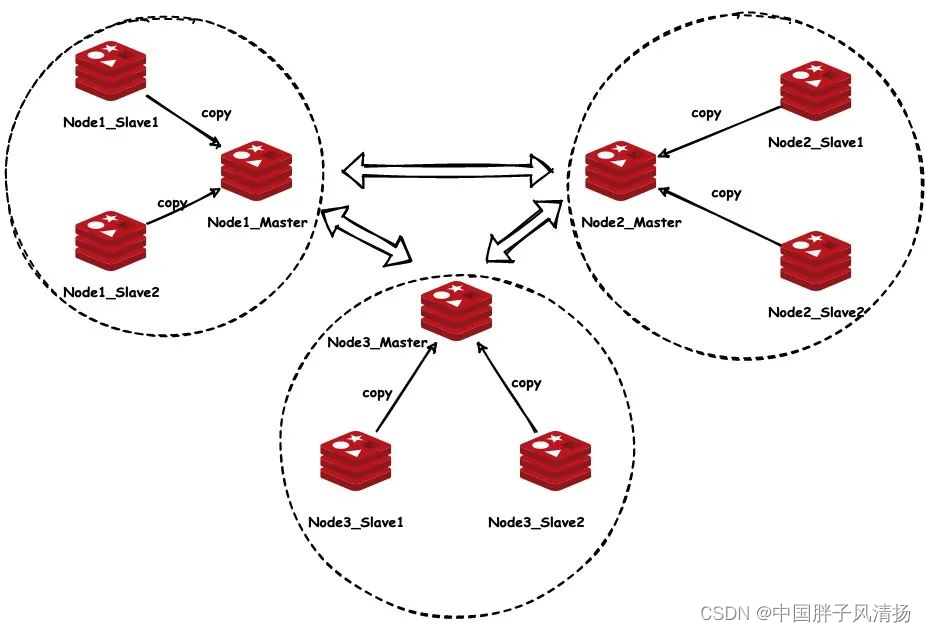
2.4、数据副本与故障转移
为了确保数据的高可用性和可靠性,Redis集群中的每个节点都可以配置一个或多个从节点进行数据复制。主节点负责处理写请求,而从节点则同步主节点的数据,用于处理读请求和提供故障转移的能力。当主节点出现故障时,Redis集群可以通过自动故障转移机制将从节点提升为主节点,以保证服务的连续性。
2.5、重定向
在Redis集群中,重定向是客户端与节点间通信的重要机制。当客户端尝试访问一个key时,如果它连接的节点并不负责处理该key所属的哈希槽,那么该节点会向客户端返回一个重定向错误,并告知客户端正确的节点地址。客户端在接收到重定向错误后,会重新连接到正确的节点,并重新发送请求。
重定向机制使得客户端能够透明地访问集群中的数据,无需关心数据的具体存储位置。同时,它也为Redis集群提供了灵活的数据迁移和故障转移能力,使得集群能够应对节点宕机、数据迁移等场景,保持服务的连续性和可用性。
3、环境准备
3.1、安装Docker
(1)Windows系统
对于Windows系统安装Docker,可以参考我以前的博客:Windows安装Docker运行中间件(详细),这篇博客详细的介绍了Windows 10如何安装Docker到打包、部署容器。
(2)Linux系统或者服务器
对于Linux类型的系统,只需要执行以下命令就可以安装Docker了。
yum install docker
3.2、安装Redis服务器
(1)创建目录
## 以下路径都是根据自己电脑自定义的
## Master节点目录
mkdir /usr/tt/master
mkdir /usr/tt/master/conf
mkdir /usr/tt/master/data## Slave节点目录
mkdir /usr/tt/slave
mkdir /usr/tt/slave/conf
mkdir /usr/tt/slave/data
(2)上传redis.conf文件(可选)
在使用Docker拉取的Redis镜像中,需要绑定一个redis.conf文件,一般拉取下来是没有的,所以需要我们上传一个或者自己写一个,上传的redis.conf文件,可以去Redis官网下载好后上传服务器,而自己编写一个redis.conf只需要简单的写如下属性:
bind 0.0.0.0
port 8900
cluster-enabled yes
appendonly yes
cluster-config-file node_6379.conf
cluster-node-timeout 20000
上传的redis.conf也只需要修改这么几个属性就可以了。
开启集群最重要的一个配置就是cluster-enabled yes这个属性。
4、集群搭建步骤
创建从8900~8902端口的三台主机redis.conf文件。
再创建从8903~8905端口的三台从机redis.conf文件。
主机和从机的配置文件除了port和cluster-confi-file两个属性不一样,其他的都可以采用默认的配置。
在上述步骤都成功实现后,就可以开始搭建Redis集群了。
4.1、配置Redis集群模式
无论是Master还是Slave,在Redis集群模式中,至少启动三台(Master、Slave各三台)。
4.1.1、启动容器
这个地方的端口我配置的不是6379,我在redis.conf文件中配置了port属性,所以端口就从6379改为了8900。需要的可以自行修改。
## 使用配置文件
docker run -d --name tt_Master_Redis_1 -p 8900:8900\
-v /usr/tt/master_1/conf/redis.conf:/etc/redis/redis.conf \
-v /usr/tt/master_1/data:/data \
d1397258b209 \
redis-server /etc/redis/redis.conf## 不使用配置文件,直接使用Docker命令启动
docker run -d --name tt_Master_Redis_1 -p 8900:8900 d1397258b209 \
redis-server --port 6379 \
--cluster-enabled yes \
--cluster-config-file nodes.conf \
--appendonly yes
按照以上方式启动三主三从,主机和从机的启动方式都是一样的。
4.1.2、查看容器状态
在容器内部使用docker logs 容器ID查看Redis启动日志。
1:C 09 Mar 2024 11:24:32.023 # WARNING: Changing databases number from 16 to 1 since we are in cluster mode
1:C 09 Mar 2024 11:24:32.023 # WARNING Memory overcommit must be enabled! Without it, a background save or replication may fail under low memory condition. Being disabled, it can also cause failures without low memory condition, see https://github.com/jemalloc/jemalloc/issues/1328. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
1:C 09 Mar 2024 11:24:32.023 * oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1:C 09 Mar 2024 11:24:32.023 * Redis version=7.2.4, bits=64, commit=00000000, modified=0, pid=1, just started
1:C 09 Mar 2024 11:24:32.023 * Configuration loaded
1:M 09 Mar 2024 11:24:32.024 * monotonic clock: POSIX clock_gettime
1:M 09 Mar 2024 11:24:32.024 * Running mode=cluster, port=8900.
1:M 09 Mar 2024 11:24:32.024 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
1:M 09 Mar 2024 11:24:32.025 * No cluster configuration found, I'm c4d671d53518db7d41c1d3db15f9a56f480f2845
1:M 09 Mar 2024 11:24:32.028 * Server initialized
1:M 09 Mar 2024 11:24:32.028 * Reading RDB base file on AOF loading...
1:M 09 Mar 2024 11:24:32.028 * Loading RDB produced by version 7.2.4
1:M 09 Mar 2024 11:24:32.028 * RDB age 68 seconds
1:M 09 Mar 2024 11:24:32.028 * RDB memory usage when created 1.51 Mb
1:M 09 Mar 2024 11:24:32.028 * RDB is base AOF
1:M 09 Mar 2024 11:24:32.028 * Done loading RDB, keys loaded: 0, keys expired: 0.
1:M 09 Mar 2024 11:24:32.028 * DB loaded from base file appendonly.aof.1.base.rdb: 0.000 seconds
1:M 09 Mar 2024 11:24:32.028 * DB loaded from append only file: 0.000 seconds
1:M 09 Mar 2024 11:24:32.028 * Opening AOF incr file appendonly.aof.1.incr.aof on server start
1:M 09 Mar 2024 11:24:32.028 * Ready to accept connections tcp
只要出现Running mode=cluster, port=8900.这段命令,并且使用Client能够访问到Redis,则表示Redis以集群模式启动成功。
4.1.3、为什么最小是三主三从?
如果在Redis中搭建集群最小的规模不是三主三从,在使用Redis Cluster命令初始化集群的时候就会报错:
*** ERROR: Invalid configuration for cluster creation.
*** Redis Cluster requires at least 3 master nodes.
*** This is not possible with 2 nodes and 1 replicas per node.
*** At least 6 nodes are required.
上面的错误就会告诉我们,集群的最小规模是三主三从。
4.2、使用Redis Cluster命令行工具搭建集群
在完成上述操作后,还有很重要的一步:查看Redis容器IP地址,查看Redis容器IP地址,查看Redis容器IP地址。
因为我们使用的是Docker虚拟化部署的Redis服务器,所以Redis内部集群之间的访问不是云服务器(我的Docker部署在云服务器上)的地址,而是Docker为Redis服务器分配了IP地址。在现实的开发中,这个地址就是远程Redis主机的IP地址。
说实话,这是我踩到的一个坑,我硬是解决了两天,我一直认为是自己的配置文件配错了或者是云服务器的端口和IP地址没有映射成功,就一直在改配置文件,也同时在网上找了很多博主写的博客,几乎没找到有说过这一步的。
4.2.1、查看容器的IP地址(重要)
查看容器的IP地址,我们可以在Redis容器成功启动后,使用docker inspect 容器ID/容器名称 | grep IPAddress命令来查看Docker为容器分配的IP地址。
docker inspect tt_Master_Redis_1 | grep IPAddress
查看结果可以得到:
"SecondaryIPAddresses": null,
"IPAddress": "172.17.0.7",
"IPAddress": "172.17.0.7",
172.17.0.7这个IP地址就是Docker为tt_Master_Redis_1这个容器分配的IP地址。
4.2.2、搭建集群
在搭建好三主三从的六台Redis服务后,我们可以随便进入一个Redis服务的内部:
docker exec -it 容器ID /bin/bash
进入后直接执行以下指令:
redis-cli --cluster create \
Master_1地址:端口 Slave_1地址:端口 \
Master_2地址:端口 Slave_2地址:端口 \
Master_3地址:端口 Slave_3地址:端口 \
--cluster-replicas 1
在回车后等待一段时间让Redis自动初始化集群信息。初始化完成后就会看到下列内容:
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 172.17.0.7:8902 to 172.17.0.5:8900
Adding replica 172.17.0.10:8905 to 172.17.0.8:8903
Adding replica 172.17.0.9:8904 to 172.17.0.6:8901
M: a799a8c4e709eea899b186163d068eb8637bf1ab 172.17.0.5:8900slots:[0-5460] (5461 slots) master
M: 90bf16a87c85a4f11e54c128896be90be083ff25 172.17.0.8:8903slots:[5461-10922] (5462 slots) master
M: bdacb0a18f092f814c92e87444f2c363c48486a1 172.17.0.6:8901slots:[10923-16383] (5461 slots) master
S: 184a44ad4883cb7a4bf1852340a413f24931400a 172.17.0.9:8904replicates bdacb0a18f092f814c92e87444f2c363c48486a1
S: 61212f108d61cd69a9e7725b326f92be27949340 172.17.0.7:8902replicates a799a8c4e709eea899b186163d068eb8637bf1ab
S: c4d671d53518db7d41c1d3db15f9a56f480f2845 172.17.0.10:8905replicates 90bf16a87c85a4f11e54c128896be90be083ff25
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
....
>>> Performing Cluster Check (using node 172.17.0.5:8900)
M: a799a8c4e709eea899b186163d068eb8637bf1ab 172.17.0.5:8900slots:[0-5460] (5461 slots) master1 additional replica(s)
S: 184a44ad4883cb7a4bf1852340a413f24931400a 172.17.0.9:8904slots: (0 slots) slavereplicates bdacb0a18f092f814c92e87444f2c363c48486a1
S: 61212f108d61cd69a9e7725b326f92be27949340 172.17.0.7:8902slots: (0 slots) slavereplicates a799a8c4e709eea899b186163d068eb8637bf1ab
M: 90bf16a87c85a4f11e54c128896be90be083ff25 172.17.0.8:8903slots:[5461-10922] (5462 slots) master1 additional replica(s)
M: bdacb0a18f092f814c92e87444f2c363c48486a1 172.17.0.6:8901slots:[10923-16383] (5461 slots) master1 additional replica(s)
S: c4d671d53518db7d41c1d3db15f9a56f480f2845 172.17.0.10:8905slots: (0 slots) slavereplicates 90bf16a87c85a4f11e54c128896be90be083ff25
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
在Can I set the above configuration?询问的时候,一定要回答yes,回答其他的都是no。
看到以上信息则表示Redis集群初始化成功。
如果回答了yes之后,一直处于等待的状态,可能是存在三个问题:
- Redis服务器的IP地址和端口不正确,我之前就是不知道Docker内部还会分配IP,导致一直是等待状态。
- 防火墙是否对当前IP和端口进行了拦截。
- 当前机器的网络是否能和Redis服务器连通,同时Redis服务器也能与本机连通。
4.3、验证集群状态
我们可以在客户端使用cluster nodes和cluster info命令来查看集群的信息:
(1)cluster info
当在客户端执行了这个命令后,就会出现下列的配置信息,如果出现cluster_state:ok这个信息,就代表集群配置成功。
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:10
cluster_my_epoch:1
cluster_stats_messages_ping_sent:3162
cluster_stats_messages_pong_sent:3225
cluster_stats_messages_fail_sent:32
cluster_stats_messages_auth-ack_sent:4
cluster_stats_messages_sent:6423
cluster_stats_messages_ping_received:3220
cluster_stats_messages_pong_received:3132
cluster_stats_messages_meet_received:5
cluster_stats_messages_fail_received:28
cluster_stats_messages_auth-req_received:6
cluster_stats_messages_received:6391
total_cluster_links_buffer_limit_exceeded:0
(2)cluster nods
这个命令是查看集群节点信息的命令,在客户端执行了这个命令后,就可以看到整个集群的节点信息。
184a44ad4883cb7a4bf1852340a413f24931400a 172.17.0.9:8904@18904 master - 0 1709986378959 8 connected 10923-16383
61212f108d61cd69a9e7725b326f92be27949340 172.17.0.7:8902@18902 slave a799a8c4e709eea899b186163d068eb8637bf1ab 0 1709986377454 1 connected
90bf16a87c85a4f11e54c128896be90be083ff25 172.17.0.8:8903@18903 slave c4d671d53518db7d41c1d3db15f9a56f480f2845 0 1709986378457 10 connected
a799a8c4e709eea899b186163d068eb8637bf1ab 172.17.0.5:8900@18900 myself,master - 0 1709986378000 1 connected 0-5460
bdacb0a18f092f814c92e87444f2c363c48486a1 172.17.0.6:8901@18901 slave 184a44ad4883cb7a4bf1852340a413f24931400a 0 1709986377554 8 connected
c4d671d53518db7d41c1d3db15f9a56f480f2845 172.17.0.10:8905@18905 master - 0 1709986377053 10 connected 5461-10922
(3)docker logs
也可以通过查看容器的日志来查看集群配置信息,只是看起来有点杂乱。
1:C 09 Mar 2024 11:08:28.465 # WARNING: Changing databases number from 16 to 1 since we are in cluster mode
1:C 09 Mar 2024 11:08:28.465 # WARNING Memory overcommit must be enabled! Without it, a background save or replication may fail under low memory condition. Being disabled, it can also cause failures without low memory condition, see https://github.com/jemalloc/jemalloc/issues/1328. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
1:C 09 Mar 2024 11:08:28.465 * oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1:C 09 Mar 2024 11:08:28.465 * Redis version=7.2.4, bits=64, commit=00000000, modified=0, pid=1, just started
1:C 09 Mar 2024 11:08:28.465 * Configuration loaded
1:M 09 Mar 2024 11:08:28.465 * monotonic clock: POSIX clock_gettime
1:M 09 Mar 2024 11:08:28.466 * Running mode=cluster, port=8900.
1:M 09 Mar 2024 11:08:28.466 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
1:M 09 Mar 2024 11:08:28.466 * No cluster configuration found, I'm a799a8c4e709eea899b186163d068eb8637bf1ab
1:M 09 Mar 2024 11:08:28.483 * Server initialized
1:M 09 Mar 2024 11:08:28.493 * Creating AOF base file appendonly.aof.1.base.rdb on server start
1:M 09 Mar 2024 11:08:28.583 * Creating AOF incr file appendonly.aof.1.incr.aof on server start
1:M 09 Mar 2024 11:08:28.583 * Ready to accept connections tcp
1:M 09 Mar 2024 11:39:59.432 * configEpoch set to 1 via CLUSTER SET-CONFIG-EPOCH
1:M 09 Mar 2024 11:39:59.489 * IP address for this node updated to 172.17.0.5
1:M 09 Mar 2024 11:40:04.411 * Cluster state changed: ok
1:M 09 Mar 2024 11:40:04.550 * Replica 172.17.0.7:8902 asks for synchronization
1:M 09 Mar 2024 11:40:04.550 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for 'd49c5f6d07f4e8d3758b047ef307c00eaf889057', my replication IDs are 'bf40ebc4b012894cc0574dabd6dc0d69ab8520ca' and '0000000000000000000000000000000000000000')
1:M 09 Mar 2024 11:40:04.550 * Replication backlog created, my new replication IDs are '2f71b44f909b7c9f29c0014135168d9111b3a3b3' and '0000000000000000000000000000000000000000'
1:M 09 Mar 2024 11:40:04.550 * Delay next BGSAVE for diskless SYNC
1:M 09 Mar 2024 11:40:09.740 * Starting BGSAVE for SYNC with target: replicas sockets
1:M 09 Mar 2024 11:40:09.740 * Background RDB transfer started by pid 26
26:C 09 Mar 2024 11:40:09.741 * Fork CoW for RDB: current 0 MB, peak 0 MB, average 0 MB
1:M 09 Mar 2024 11:40:09.741 * Diskless rdb transfer, done reading from pipe, 1 replicas still up.
1:M 09 Mar 2024 11:40:09.790 * Background RDB transfer terminated with success
1:M 09 Mar 2024 11:40:09.790 * Streamed RDB transfer with replica 172.17.0.7:8902 succeeded (socket). Waiting for REPLCONF ACK from replica to enable streaming
1:M 09 Mar 2024 11:40:09.790 * Synchronization with replica 172.17.0.7:8902 succeeded
1:M 09 Mar 2024 11:43:11.568 # Cluster state changed: fail
1:M 09 Mar 2024 11:43:16.053 * Marking node c4d671d53518db7d41c1d3db15f9a56f480f2845 () as failing (quorum reached).
1:M 09 Mar 2024 11:43:16.053 * Marking node 61212f108d61cd69a9e7725b326f92be27949340 () as failing (quorum reached).
1:M 09 Mar 2024 11:43:16.053 * Marking node 184a44ad4883cb7a4bf1852340a413f24931400a () as failing (quorum reached).
1:M 09 Mar 2024 11:43:16.053 * Marking node 90bf16a87c85a4f11e54c128896be90be083ff25 () as failing (quorum reached).
1:M 09 Mar 2024 11:43:16.363 * Clear FAIL state for node c4d671d53518db7d41c1d3db15f9a56f480f2845 ():replica is reachable again.
1:M 09 Mar 2024 11:43:16.494 * Marking node bdacb0a18f092f814c92e87444f2c363c48486a1 () as failing (quorum reached).
1:M 09 Mar 2024 11:43:17.115 * FAIL message received from 90bf16a87c85a4f11e54c128896be90be083ff25 () about c4d671d53518db7d41c1d3db15f9a56f480f2845 ()
1:M 09 Mar 2024 11:43:17.522 * Clear FAIL state for node 184a44ad4883cb7a4bf1852340a413f24931400a ():replica is reachable again.
1:M 09 Mar 2024 11:43:17.962 # Failover auth denied to 61212f108d61cd69a9e7725b326f92be27949340 (): its master is up
1:M 09 Mar 2024 11:43:17.962 * Failover auth granted to c4d671d53518db7d41c1d3db15f9a56f480f2845 () for epoch 7
1:M 09 Mar 2024 11:43:17.962 * Clear FAIL state for node 61212f108d61cd69a9e7725b326f92be27949340 ():replica is reachable again.
1:M 09 Mar 2024 11:43:18.582 * Failover auth granted to 184a44ad4883cb7a4bf1852340a413f24931400a () for epoch 8
1:M 09 Mar 2024 11:43:25.320 * FAIL message received from c4d671d53518db7d41c1d3db15f9a56f480f2845 () about 184a44ad4883cb7a4bf1852340a413f24931400a ()
1:M 09 Mar 2024 11:43:25.649 * Clear FAIL state for node bdacb0a18f092f814c92e87444f2c363c48486a1 ():replica is reachable again.
1:M 09 Mar 2024 11:43:26.053 * Clear FAIL state for node 90bf16a87c85a4f11e54c128896be90be083ff25 ():replica is reachable again.
1:M 09 Mar 2024 11:43:26.621 * Failover auth granted to 90bf16a87c85a4f11e54c128896be90be083ff25 () for epoch 9
1:M 09 Mar 2024 11:43:26.652 # Failover auth denied to bdacb0a18f092f814c92e87444f2c363c48486a1 (): already voted for epoch 9
1:M 09 Mar 2024 11:43:28.290 * Clear FAIL state for node c4d671d53518db7d41c1d3db15f9a56f480f2845 ():replica is reachable again.
1:M 09 Mar 2024 11:43:35.721 * Clear FAIL state for node 184a44ad4883cb7a4bf1852340a413f24931400a (): is reachable again and nobody is serving its slots after some time.
1:M 09 Mar 2024 11:43:35.722 * Cluster state changed: ok
1:M 09 Mar 2024 11:45:34.514 * FAIL message received from 184a44ad4883cb7a4bf1852340a413f24931400a () about c4d671d53518db7d41c1d3db15f9a56f480f2845 ()
1:M 09 Mar 2024 11:45:38.692 * Clear FAIL state for node c4d671d53518db7d41c1d3db15f9a56f480f2845 ():replica is reachable again.
1:M 09 Mar 2024 11:54:53.487 * Marking node 61212f108d61cd69a9e7725b326f92be27949340 () as failing (quorum reached).
1:M 09 Mar 2024 11:54:53.997 * Clear FAIL state for node 61212f108d61cd69a9e7725b326f92be27949340 ():replica is reachable again.
1:M 09 Mar 2024 11:54:54.037 * FAIL message received from c4d671d53518db7d41c1d3db15f9a56f480f2845 () about 61212f108d61cd69a9e7725b326f92be27949340 ()
1:M 09 Mar 2024 11:54:59.813 * Clear FAIL state for node 61212f108d61cd69a9e7725b326f92be27949340 ():replica is reachable again.
1:M 09 Mar 2024 11:58:24.592 # Cluster state changed: fail
1:M 09 Mar 2024 11:58:34.477 * Marking node 90bf16a87c85a4f11e54c128896be90be083ff25 () as failing (quorum reached).
1:M 09 Mar 2024 11:58:34.546 * FAIL message received from 184a44ad4883cb7a4bf1852340a413f24931400a () about 61212f108d61cd69a9e7725b326f92be27949340 ()
1:M 09 Mar 2024 11:58:34.546 * FAIL message received from 184a44ad4883cb7a4bf1852340a413f24931400a () about bdacb0a18f092f814c92e87444f2c363c48486a1 ()
1:M 09 Mar 2024 11:58:34.546 * FAIL message received from 184a44ad4883cb7a4bf1852340a413f24931400a () about c4d671d53518db7d41c1d3db15f9a56f480f2845 ()
1:M 09 Mar 2024 11:58:35.097 * Clear FAIL state for node c4d671d53518db7d41c1d3db15f9a56f480f2845 ():replica is reachable again.
1:M 09 Mar 2024 11:58:35.796 * Failover auth granted to c4d671d53518db7d41c1d3db15f9a56f480f2845 () for epoch 10
1:M 09 Mar 2024 11:58:36.497 * Clear FAIL state for node 61212f108d61cd69a9e7725b326f92be27949340 ():replica is reachable again.
1:M 09 Mar 2024 11:58:36.796 * Clear FAIL state for node bdacb0a18f092f814c92e87444f2c363c48486a1 ():replica is reachable again.
1:M 09 Mar 2024 11:58:37.097 * Clear FAIL state for node 90bf16a87c85a4f11e54c128896be90be083ff25 ():replica is reachable again.
1:M 09 Mar 2024 11:58:39.505 * Cluster state changed: ok
这个命令就可以看到从机接入的时刻和容器启动的时刻。
4.4、写入数据
在写入数据时,我们需要回忆起一个东西,就是上面提到的Key的分布式模型。
当Redis集群创建好之后,我们可以再查看集群信息的时候看到Slot的分区情况:
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
三个主节点将16384个Slot平均分配。
当我们写入数据的时候,Redis会根据Hash_Slot = CRC16(key) % 16384这个方式将keyName分配到对应的主节点上,如果数据没有分配到当前节点上,则会进行重定向到集群中对应的机器上。
4.4.1、写入时报错
当我们通过redis-cli命令连接Redis服务器,在插入数据时,可能会出现以下错误:
127.0.0.1:8900> set name zhangsan
(error) MOVED 5798 172.17.0.10:8905
这是因为我们使用redis-cli命令连接Redis服务器的时候使用的是以下语句:
redis-cli 192.168.240.3 -p 8900
使用这种方式是不会进行重定向的,需要使用以下的命令进行连接Redis服务器:
redis-cli 192.168.240.3 -p 8900 -c
4.4.2、正常写入
(1)通过Redis分布式Key的计算分配在本机上:
redis> set name zhangsan
OK
(2)没有分配到本机上需要进行重定向:
redis> set name lisi
-MOVED 5930 192.168.240.3:8901
5930表示是192.168.240.3:8901这台主机上的Slot槽,所以这就被重定向到了192.168.240.3:8901这台主机上。

![[Vue]中数组的操作用法](http://pic.xiahunao.cn/[Vue]中数组的操作用法)


介绍(横切关注点、通知(增强)、连接切入点、切面))


Spring原理:Bean的作用域、Bean的生命周期、Spring Boot自动配置(加载Bean、SpringBoot原理分析))


MVC)








)