接上次博客:JavaEE进阶(14)Linux基本使用和程序部署(博客系统部署)-CSDN博客
目录
关于Bean的作用域
概念
Bean的作用域
Bean的生命周期
源码阅读
Spring Boot自动配置
Spring 加载Bean
问题描述
原因分析
解决方案
@ComponentScan:
@Import
导入类
导入ImportSelector接口实现类
SpringBoot原理分析
源码阅读
1、元注解
2. @SpringBootConfiguration
3.@EnableAutoConfiguration (开启自动配置)
4.@ComponentScan (包扫描)
@EnableAutoConfiguration 详解
关于Bean的作用域
概念
在Spring的IoC(控制反转)和DI(依赖注入)阶段,我们深入学习了Spring框架如何帮助我们管理对象,从而实现松耦合和模块化的设计:JavaEE进阶(5)Spring IoC&DI:入门、IoC介绍、IoC详解(两种主要IoC容器实现、IoC和DI对对象的管理、Bean存储、方法注解 @Bean)、DI详解:注入方式、总结_java的ioc-CSDN博客
- 通过注解声明Bean对象: Spring提供了多种注解来声明Bean对象,如@Controller、@Service、@Repository、@Component、@Configuration和@Bean。这些注解可以告诉Spring容器哪些类需要被管理,并在需要时创建相应的对象。
- 通过ApplicationContext或者BeanFactory获取对象: Spring提供了两种主要的容器来管理对象,分别是ApplicationContext和BeanFactory。这些容器负责创建、配置和管理应用中的Bean对象,我们可以通过它们来获取需要的对象实例。
- 通过注入方式注入依赖: 在Spring中,我们可以通过多种方式来进行依赖注入。常用的方式包括使用@Autowired注解、Setter方法注入和构造方法注入。这些方式可以帮助我们在需要时将依赖的Bean对象注入到目标对象中,从而实现对象之间的解耦和灵活配置。
现在我们来简单回顾一下:
我们新建一个项目:
通过 @Bean 声明bean,把bean存在Spring容器中 :
package com.example.springtest.Bean;import lombok.Data;public class Dog {private String name;public String getName() {return name;}public void setName(String name) {this.name = name;}}
package com.example.springtest.Bean;import org.springframework.beans.factory.config.ConfigurableBeanFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
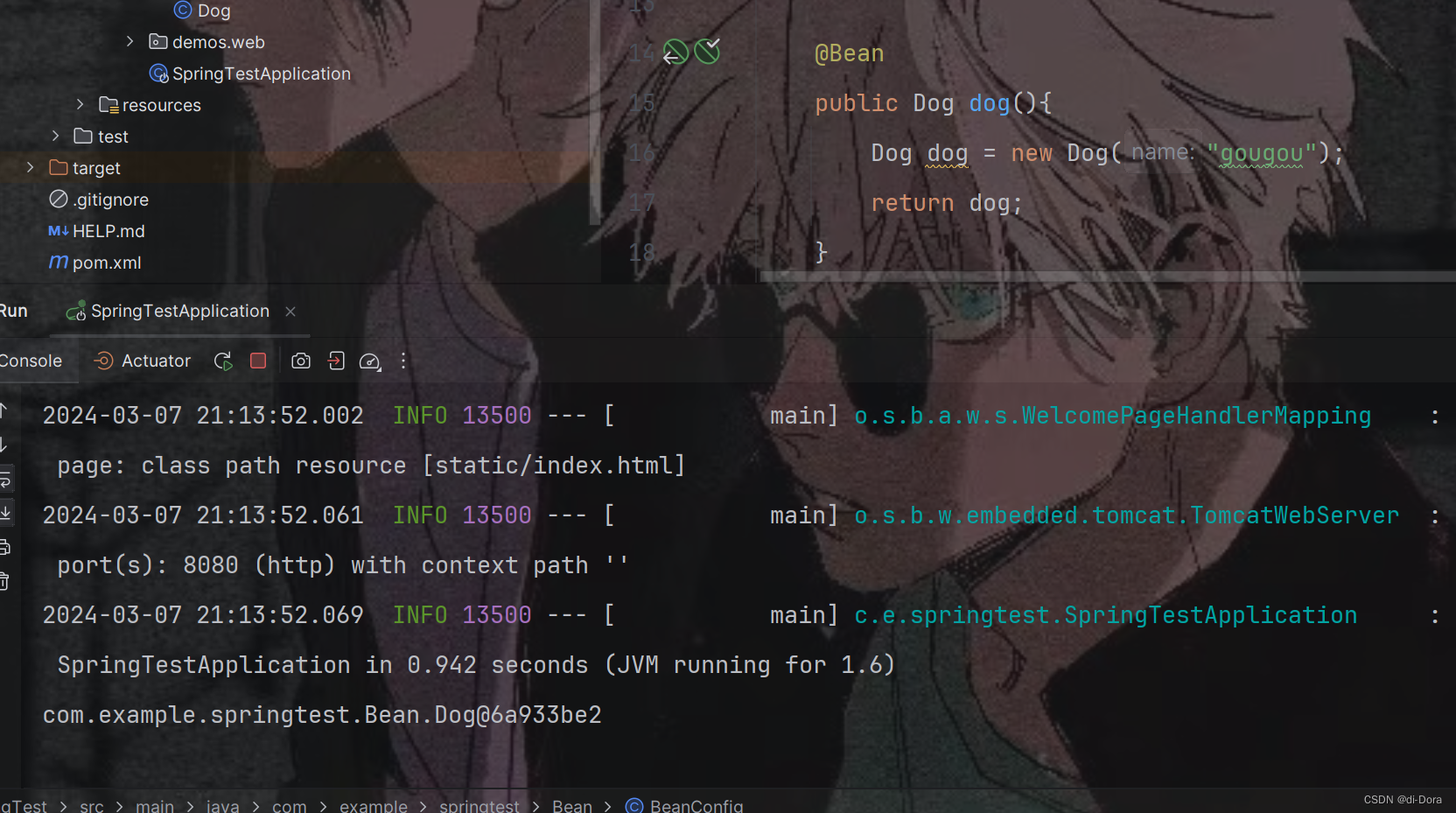
public class BeanConfig {@Beanpublic Dog dog(){Dog dog = new Dog("gougou");return dog;}}
从Spring容器中获取Bean:
package com.example.springtest;import com.example.springtest.Bean.Dog;
import com.sun.glass.ui.Application;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.ApplicationContext;@SpringBootApplication
public class SpringTestApplication {public static void main(String[] args) {ApplicationContext context = SpringApplication.run(SpringTestApplication.class, args);Dog bean = context.getBean(Dog.class);System.out.println(bean);}}
也可以通过在代码中直接注入ApplicationContext的方式来获取Spring容器:
package com.example.springtest.scope;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.context.annotation.RequestScope;@RestController
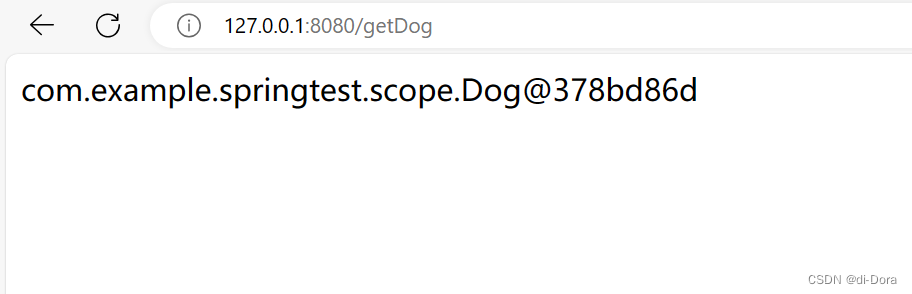
public class ScopeController {@Autowiredprivate ApplicationContext context;@RequestMapping("/getDog")public String getDog(){return context.getBean(Dog.class).toString(); }}
从Spring容器中多次获取Bean:
package com.example.springtest.scope;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.context.annotation.RequestScope;@RestController
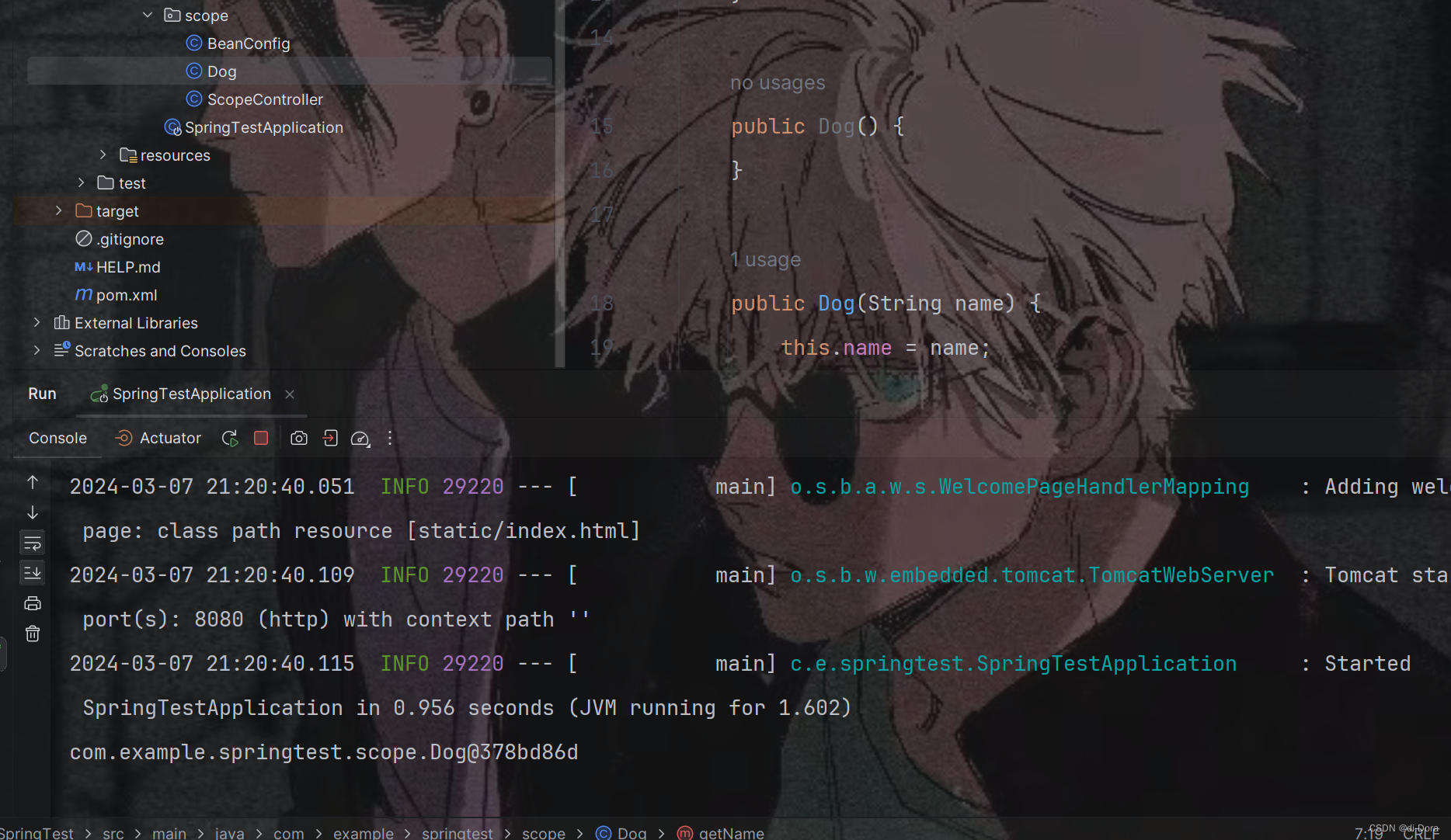
public class ScopeController {@Autowiredprivate ApplicationContext context;@Autowiredprivate Dog dog;@RequestMapping("/getDog")public String getDog(){Dog contextDog = context.getBean(Dog.class);Dog contextDog2 = context.getBean(Dog.class);Dog contextDog3 = context.getBean(Dog.class);System.out.println(contextDog);System.out.println(contextDog2);System.out.println(contextDog3);return "dog:"+dog.toString()+",context:"+contextDog.toString();}}

发现不管我们拿了几次,拿到的都是同一个对象,甚至包括我们注入进来的那个。
当输出的bean对象地址值相同时,表明每次从Spring容器中取出的对象都是同一个实例。这种现象符合单例模式的特征。单例模式确保一个类只有一个实例,无论多次创建都不会产生多个实例。在默认情况下,Spring容器中的bean都是单例的,这种行为模式我们称之为Bean的作用域。
单例模式在Spring中非常常见,因为它可以有效地节省系统资源,并且避免不必要的对象创建和销毁开销。在大多数情况下,如果一个bean的作用域是单例的,那么Spring容器只会创建该bean的一个实例,并在需要时重复使用这个实例。这样可以确保整个应用程序中的组件都共享同一个实例,从而实现资源的共享和减少内存消耗。
需要注意的是,虽然Spring默认情况下的bean作用域是单例的,但也可以通过配置来修改bean的作用域,如设置为原型(prototype)作用域,这样每次请求时Spring容器都会创建一个新的实例。选择合适的bean作用域可以根据具体需求来决定,以达到最佳的性能和资源利用效率。
Bean 的作用域指的是在Spring框架中定义Bean时指定的一种行为模式。
常见的作用域包括单例(singleton)、原型(prototype)、请求(request)、会话(session)、全局会话(global session)等。
其中,单例作用域是最常见的一种。它表示在整个Spring容器中只存在一个Bean实例,这个实例是全局共享的。换句话说,当一个Bean对象被创建后,Spring容器会在整个应用程序生命周期内保持这个实例的唯一性。因此,如果一个人修改了这个单例Bean的值,那么另一个人读取到的就是被修改后的值。
这种全局共享的特性使得单例Bean在应用程序中非常有用,可以用来保存应用程序的全局状态或共享资源。但同时也需要小心并发访问和状态修改的问题,确保线程安全性。
其他作用域如原型作用域表示每次请求Bean时都会创建一个新的实例,请求作用域表示每个HTTP请求都会创建一个新的实例,会话作用域表示每个会话(session)都会创建一个新的实例,全局会话作用域表示全局会话(例如集群环境下的分布式会话)都会创建一个新的实例。这些作用域可以根据具体的需求来选择,以满足不同场景下的需求。
那么能不能将bean对象设置为非单例的(也就是每次获取的bean都是⼀个新对象)呢?
当然可以,这些就是Bean的不同作用域了。
Bean的作用域
在Spring框架中,提供了丰富的Bean作用域来满足不同场景下的需求。这些作用域可以通过在Bean的声明中使用@Scope注解来指定,从而控制Bean的生命周期和实例化方式。
-
Singleton(单例作用域):在Spring IoC容器中,默认的作用域就是单例作用域。这意味着每个容器内同名称的Bean只有一个实例,它是全局共享的。在整个应用程序中只有一个实例存在,所有对该Bean的引用都将指向同一个实例。
-
Prototype(原型作用域):原型作用域是一种多例作用域,每次获取该Bean时都会创建一个新的实例。这意味着每次使用该Bean时都会获得一个新的对象实例,而不是共享同一个实例。
以下四种作用域在Spring MVC环境中才生效:
-
Request(请求作用域):请求作用域表示每个HTTP请求的生命周期内都会创建一个新的实例。这意味着每个HTTP请求都会使用一个新的Bean实例,适用于需要在请求级别上维护状态的Bean。
-
Session(会话作用域):会话作用域表示每个HTTP Session的生命周期内都会创建一个新的实例。这意味着每个会话都会使用一个新的Bean实例,适用于需要在会话级别上维护状态的Bean,而同一个会话中是相同的Bean。
-
Application(全局作用域):全局作用域表示每个ServletContext的生命周期内都会创建一个新的实例。这意味着每个ServletContext都会使用一个新的Bean实例,适用于需要在应用程序级别上共享资源的Bean。
-
WebSocket(WebSocket作用域):WebSocket作用域表示每个WebSocket的生命周期内都会创建一个新的实例。这意味着每个WebSocket连接都会使用一个新的Bean实例,适用于需要在WebSocket会话级别上维护状态的Bean。
了解和合理使用不同作用域的Bean是Spring应用程序设计中的重要一环,学习后我们就可以根据具体的业务需求和性能考虑来选择合适的作用域。
参考官方文档:Bean Scopes :: Spring Framework
在Spring中,通过注解我们可以方便地指定Bean的作用域,而不必在配置文件中进行显式的配置。
我们来简单看下代码实现,定义几个不同作用域的Bean:
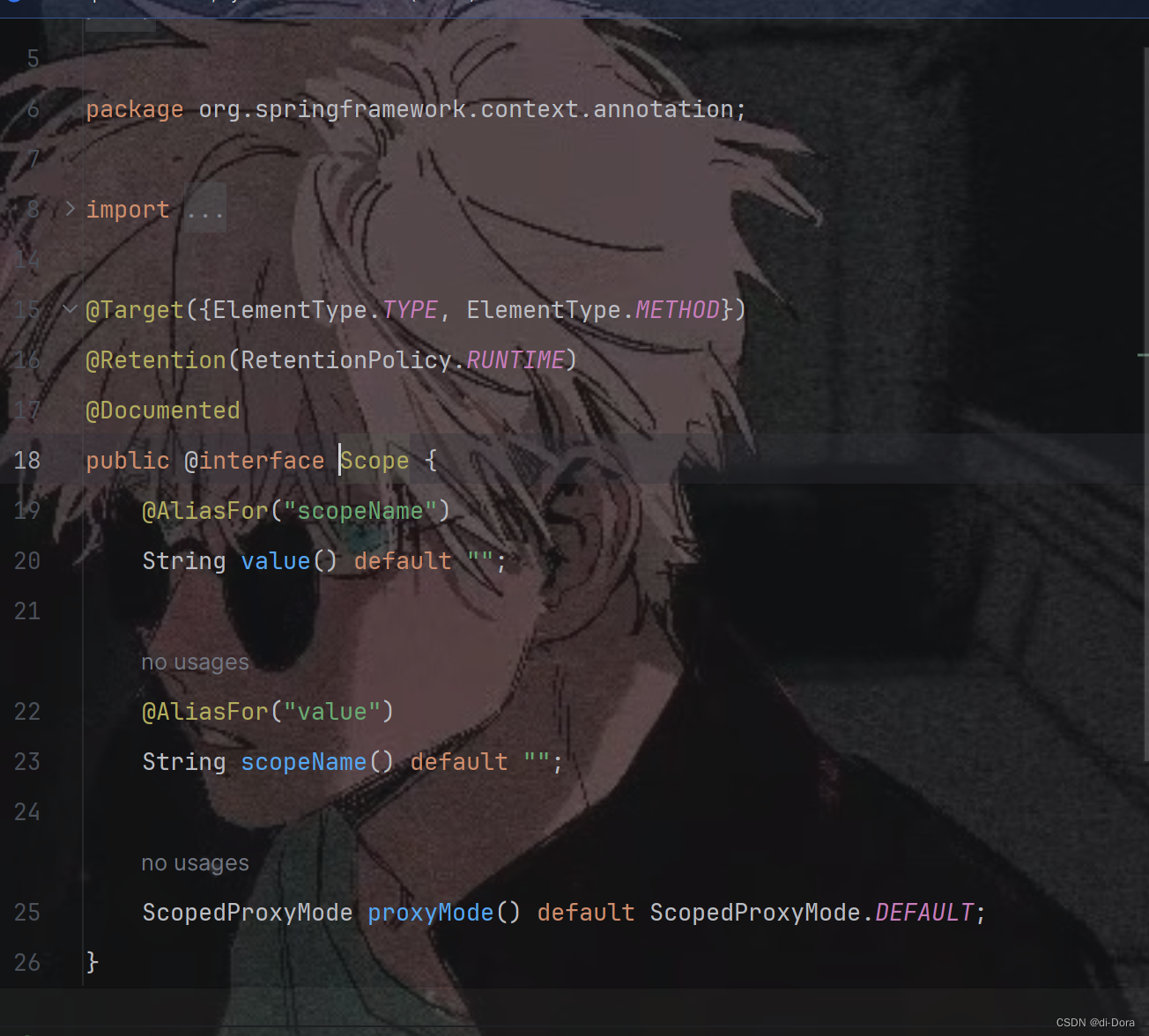
Scope用于在Spring框架中指定Bean的作用域。该注解用于类或者方法上,并且标记为运行时保留。
@Target({ElementType.TYPE, ElementType.METHOD}):指定了该注解可以被应用在类或者方法上。
@Retention(RetentionPolicy.RUNTIME):指定了该注解在运行时保留,这样Spring容器可以在运行时读取并处理这个注解。
@Documented:指定了该注解会被包含在JavaDoc文档中。
@AliasFor("scopeName"):表示value和scopeName是互相别名的属性,它们可以互相替代使用。
String value() default "":用于指定Bean的作用域名称。这个属性与scopeName()是互相别名的。
ScopedProxyMode proxyMode() default ScopedProxyMode.DEFAULT:用于指定Bean的代理模式。默认值为ScopedProxyMode.DEFAULT,表示Spring将根据需要自动选择代理模式。
也就是说,该注解可以通过@Scope注解来声明一个Bean的作用域,并且可以指定作用域的名称和代理模式。通过在类或者方法上添加这个注解,我们可以告诉Spring容器如何处理这个Bean的作用域。
下面的它们三个其实也继承与@scope:

具体来说:
- @RequestScope等同于@Scope(value = WebApplicationContext.SCOPE_REQUEST, proxyMode = ScopedProxyMode.TARGET_CLASS):这个注解表示将Bean的作用域设置为请求作用域。在Web应用程序中,每个HTTP请求都会创建一个新的实例。同时,需要设置proxyMode属性为ScopedProxyMode.TARGET_CLASS,这样才能基于CGLIB实现动态代理。
- @SessionScope等同于@Scope(value = WebApplicationContext.SCOPE_SESSION, proxyMode = ScopedProxyMode.TARGET_CLASS):这个注解表示将Bean的作用域设置为会话作用域。在Web应用程序中,每个HTTP Session的生命周期内都会创建一个新的实例。同样,需要设置proxyMode属性为ScopedProxyMode.TARGET_CLASS。
- @ApplicationScope等同于@Scope(value = WebApplicationContext.SCOPE_APPLICATION, proxyMode = ScopedProxyMode.TARGET_CLASS):这个注解表示将Bean的作用域设置为全局作用域。在Web应用程序中,每个ServletContext的生命周期内都会创建一个新的实例。同样,需要设置proxyMode属性为ScopedProxyMode.TARGET_CLASS。
proxyMode属性用于为Spring Bean设置代理,这在某些情况下是必需的,尤其是在Web环境中。设置proxyMode为ScopedProxyMode.TARGET_CLASS表示使用CGLIB动态代理来实现对Bean的代理,以确保在运行时能够正确地创建和管理作用域内的Bean实例。
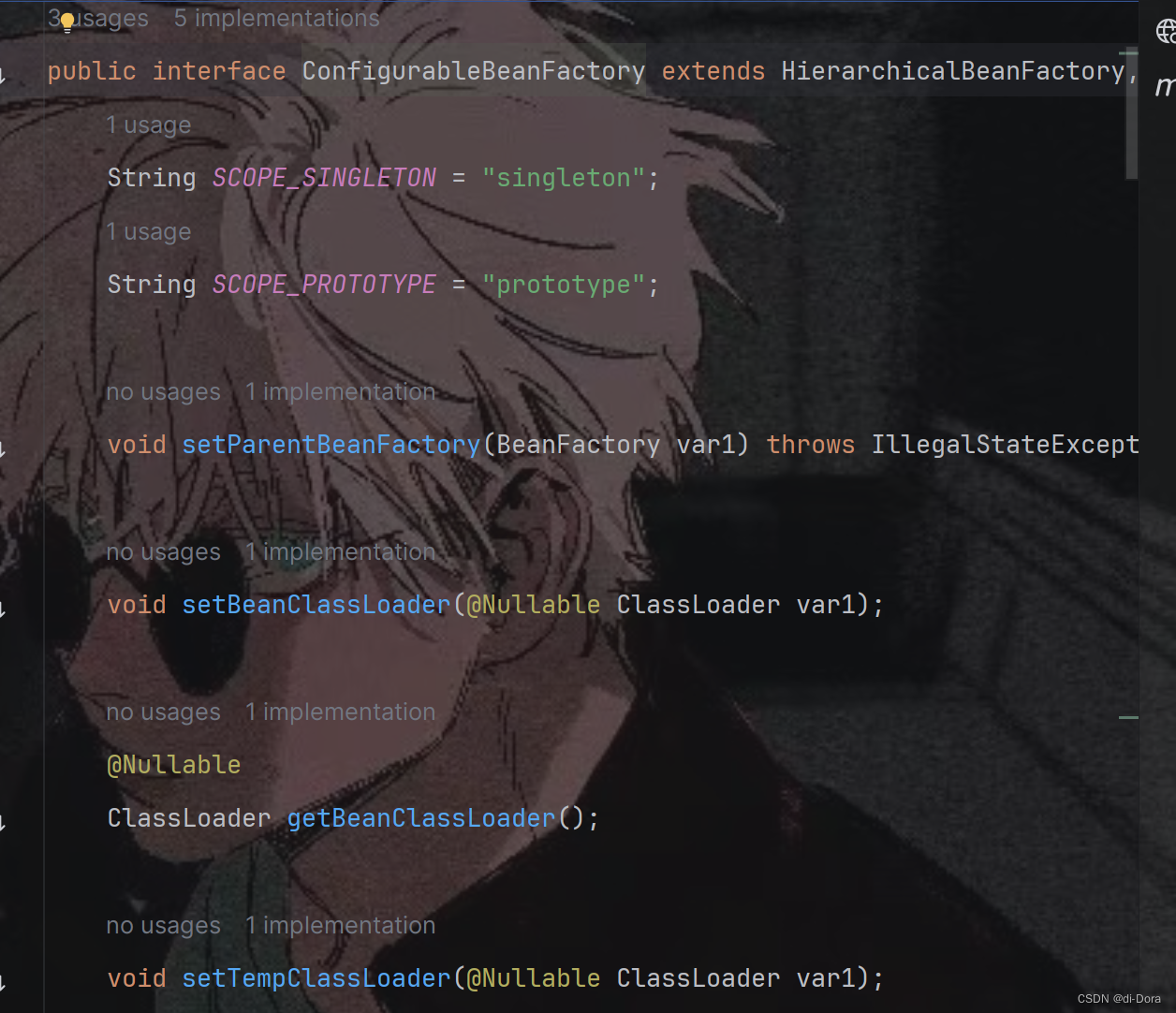
ConfigurableBeanFactory:该接口定义了一些方法,用于配置可配置的Bean工厂。这个接口扩展了HierarchicalBeanFactory和SingletonBeanRegistry接口,从而继承了它们的功能。
在Spring框架中,BeanFactory是负责创建、管理和解析Bean对象的核心接口。ConfigurableBeanFactory接口提供了一些额外的配置功能,使得BeanFactory更加灵活和可配置。
该接口中的方法包括设置父级Bean工厂、设置类加载器、设置Bean表达式解析器、设置转换服务、注册作用域、注册别名、销毁Bean等。这些方法可以用于配置Bean工厂的各种属性和行为,以满足特定的应用需求。
综上,ConfigurableBeanFactory接口提供了一种可扩展和可配置的方式来管理Bean对象,并且提供了一些灵活的方法来对Bean工厂进行配置和定制。
我们开始写我们的代码:
package com.example.springtest.scope;import org.springframework.beans.factory.config.ConfigurableBeanFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Scope;
import org.springframework.web.context.annotation.ApplicationScope;
import org.springframework.web.context.annotation.RequestScope;
import org.springframework.web.context.annotation.SessionScope;
//import org.springframework.context.annotation.Scope;
//import org.springframework.web.context.annotation.ApplicationScope;
//import org.springframework.web.context.annotation.RequestScope;
//import org.springframework.web.context.annotation.SessionScope;@Configuration
public class BeanConfig {@Beanpublic Dog dog(){Dog dog = new Dog("gougou");return dog;}@Scope(ConfigurableBeanFactory.SCOPE_SINGLETON)@Beanpublic Dog singleDog(){return new Dog();}@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)@Beanpublic Dog prototypeDog(){return new Dog();}@RequestScope@Beanpublic Dog requestDog(){return new Dog();}@SessionScope@Beanpublic Dog sessionDog(){return new Dog();}@ApplicationScope@Beanpublic Dog applicationDog(){return new Dog();}}
package com.example.springtest.scope;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.context.annotation.RequestScope;@RestController
public class ScopeController {@Autowiredprivate ApplicationContext context;
// public String getDog(){
// return context.getBean(Dog.class).toString();
// }@Autowiredprivate Dog dog;@Autowiredprivate Dog singleDog;@Autowiredprivate Dog prototypeDog;@Autowiredprivate Dog requestDog;@Autowiredprivate Dog sessionDog;@Autowiredprivate Dog applicationDog;@RequestMapping("/getDog")public String getDog(){Dog contextDog = context.getBean(Dog.class);Dog contextDog2 = context.getBean(Dog.class);Dog contextDog3 = context.getBean(Dog.class);System.out.println(contextDog);System.out.println(contextDog2);System.out.println(contextDog3);return "dog:"+dog.toString()+",context:"+contextDog.toString();}@RequestMapping("/single")public String single(){Dog contextDog = (Dog)context.getBean("singleDog");return "singleDog:"+singleDog.toString()+",context:"+contextDog.toString();}@RequestMapping("/prototype")public String prototype(){Dog contextDog = (Dog)context.getBean("prototypeDog");return "prototypeDog:"+prototypeDog.toString()+",context:"+contextDog.toString();}@RequestMapping("/request")public String request(){Dog contextDog = (Dog)context.getBean("requestDog");return "requestDog:"+requestDog.toString()+",context:"+contextDog.toString();}@RequestMapping("/session")public String session(){Dog contextDog = (Dog)context.getBean("sessionDog");return "sessionDog:"+sessionDog.toString()+",context:"+contextDog.toString();}@RequestMapping("/application")public String application(){Dog contextDog = (Dog)context.getBean("applicationDog");return "applicationDog:"+applicationDog.toString()+",context:"+contextDog.toString();}}
测试不同作用域的Bean取到的对象是否一样:
单例作用域,多次请求拿到的是同一个对象:

多例作用域,每次拿到的不是同一个对象:

请求作用域,在一个请求中是同一个对象,不同请求中是不同对象。在一次请求中, @Autowired 和 applicationContext.getBean() 是同⼀个对象:


session作用域,同一个会话中是同一个对象:

我们直接更换一个浏览器访问,发现会重新创建对象:

application作用域:在一个应用中,多次访问都是同⼀个对象

换一个浏览器:

Application作用域和Singleton作用域的相似之处在于它们都是在应用程序的整个生命周期内只创建一个实例,确保了全局唯一性。但是,它们的区别在于作用域的范围不同:
-
Application作用域:Bean的作用域是ServletContext级别的,也就是说,在整个Web容器中,只有一个实例存在。这意味着,无论有多少个Web应用部署在同一个容器中,它们共享同一个Application作用域中的Bean实例。换句话说,Application作用域是ServletContext的单例。
-
Singleton作用域:Bean的作用域是ApplicationContext级别的,也就是说,在每个ApplicationContext中只有一个实例存在。在一个Web容器中可以存在多个ApplicationContext,每个Web应用都有自己的ApplicationContext实例。因此,Singleton作用域是在ApplicationContext级别的单例。
这样的区别使得在特定的场景下能够选择合适的作用域,以满足不同的需求。特别是在多个Web应用部署在同一个容器中的情况下,使用Application作用域可以确保Bean的实例在所有应用之间的共享,而不会受到其他应用的影响。
我们来说得更明白些,在单个Web应用程序内部,无论是使用Application作用域还是Singleton作用域,都会导致在整个应用程序中只存在一个实例。因此,从单个Web应用程序的角度来看,它们的行为确实类似,都可以被视为单例。
但是,它们的区别在于跨多个Web应用程序的情况下:
-
Application作用域:在整个Web容器中,无论有多少个Web应用程序部署在其中,它们共享同一个Application作用域中的Bean实例。这意味着,如果在一个Web应用程序中修改了Application作用域中的Bean实例,那么其他所有Web应用程序都会看到这个修改。
-
Singleton作用域:在单个Web应用程序内部,Singleton作用域确实表现为单例,但是如果有多个Web应用程序部署在同一个容器中,每个Web应用程序都有自己的ApplicationContext实例,因此它们各自拥有自己的Singleton作用域。这意味着,即使在同一个容器中部署了多个Web应用程序,它们的Singleton作用域中的Bean实例是相互独立的,一个应用程序对其进行的修改不会影响其他应用程序。
再补充说明几点:
-
对于Spring框架中的Singleton作用域来说,它是在每个ApplicationContext级别上的单例。在典型的Web应用程序中,每个Web应用程序通常都有自己的ApplicationContext实例。所以,无论是同一个浏览器还是不同的浏览器,只要它们都属于同一个Web应用程序,它们共享的是同一个ApplicationContext,因此对于Singleton作用域的Bean来说,它们确实是同一个对象实例。
-
在Web开发中,一个Web应用程序通常指的是一个独立的、功能完整的网络应用,它包含了一组相关的Web资源(例如HTML、CSS、JavaScript文件)、服务器端代码(例如Java、Python等)、以及一些配置文件。这个应用程序通过HTTP协议与用户交互,提供特定的功能和服务,比如电子商务网站、社交网络、博客系统等。
在一个Web应用程序中,可能有多个不同的模块或组件,每个模块都承担不同的功能。例如,在Java的Web开发中,一个Web应用程序通常会包含多个Servlet、Filter、Listener等组件,它们协同工作来处理用户请求、实现业务逻辑等。
关于浏览器的配置问题,通常情况下,一个Web应用程序对应一个独立的部署单元,例如一个WAR文件或者一个独立的目录。在一个Web应用程序中,无论用户使用什么样的浏览器,都是访问同一个Web应用程序,即使用同一个ApplicationContext实例。这意味着,无论用户使用何种浏览器访问同一个Web应用程序,它们都会共享同一个ApplicationContext,因此对于Singleton作用域的Bean来说,它们确实是同一个对象实例。
Bean的生命周期
生命周期指的是一个对象从诞生到销毁的整个生命过程,我们把这个过程就叫做一个对象的生命周期。
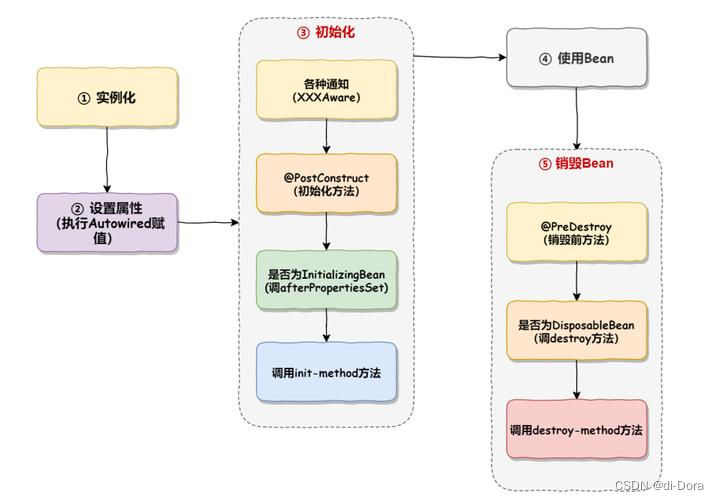
Bean 的生命周期分为以下5个部分:
-
实例化:为Bean分配内存空间。
这个阶段是指在内存中为对象分配空间,并创建对象的实例。通常情况下,实例化是通过Java的new关键字来完成的。 -
属性赋值:Bean注入与装配。
这一阶段涉及到将Bean所需的属性值设置到相应的属性中。属性值可以通过各种方式注入,比如使用@Autowired注解自动装配,或者通过XML配置文件或Java代码手动设置。 -
初始化:
在初始化阶段,Bean的状态会被准备好以供使用。这一阶段主要包括两个部分:
a. 执行各种通知:在这一步中,Bean会执行一些特定的方法来获取关于自身的信息,比如BeanNameAware、BeanFactoryAware、ApplicationContextAware等接口方法,通过这些方法可以获取关于Bean的一些元数据信息或者对Spring容器的引用。
b. 执行初始化方法:在这一步中,Bean的初始化方法会被调用,初始化方法可以通过以下方式定义:
① 在XML中使用init-method属性来指定初始化方法。
② 使用@PostConstruct注解来标记初始化方法。
③ 执行初始化后置方法,即调用实现了BeanPostProcessor接口的类中的postProcessBeforeInitialization和postProcessAfterInitialization方法。 -
使用Bean:
一旦Bean完成了初始化阶段,它就可以被其他对象或组件使用了。在这个阶段,Bean会被注入到其他对象中,或者在容器中被获取并调用其方法。 -
销毁Bean:
当Bean不再需要时,Spring容器会在适当的时候销毁它。这个阶段包括执行一些清理工作以释放资源,通常包括:
a. 调用销毁回调方法:可以通过以下方式定义销毁回调方法:
① 在XML中使用destroy-method属性来指定销毁方法。
② 使用@PreDestroy注解来标记销毁方法。
b. 执行DisposableBean接口方法:
如果Bean实现了DisposableBean接口,Spring容器会在销毁Bean时调用其destroy()方法。
上述这些是Bean的完整生命周期的详细阶段,每个阶段都是Spring框架管理Bean的重要组成部分。
执行流程如图:
举个例子来说明:当考虑到购买一栋房子的生命周期时:
-
房子建造: 就像是购买一栋房子的第一步一样,房子的建造是从无到有的过程。在这个阶段,房子的各个构件被建造并组装在一起,创造出了一个新的物理空间。
-
装修与装饰: 在房子建造完成之后,接下来就是装修和装饰的阶段。这包括选择合适的家具、粉刷墙壁、铺设地板等等,以及根据个人喜好进行装饰,让房子变得温馨舒适。
-
购买家电和家居用品: 在房子装修完毕后,接下来就是购买各种家电和家居用品的阶段。这包括购买洗衣机、冰箱、电视、空调等设备,以及购买床上用品、厨房用具等日常生活所需的物品。
-
入住: 一切准备就绪后,就可以搬入新房子开始新的生活了。这个阶段代表了房子被实际使用的过程,人们可以在这里生活、工作、休息,享受新的家庭生活。
-
卖房或迁出: 当房子不再符合需求,或者因为其他原因需要离开时,就需要考虑卖房或者搬迁的问题。这个阶段类似于Bean销毁的过程,房子可能会被重新出售给其他买家,或者被拆除重建,或者被改建成其他用途。
实例化和属性赋值对应构造方法和setter方法的注入,初始化和销毁是用户能自定义扩展的两个阶段,可以在实例化之后,类加载完成之前进行自定义“事件”处理。
- 实例化阶段通常涉及到类的构造方法,这是对象在内存中被创建的时刻。在Spring中,通过构造方法实例化Bean对象,并且在此时Spring会为Bean的属性赋予默认值(如果有的话)。
- 属性赋值阶段是在实例化之后,通过setter方法或者字段注入等方式将Bean的属性值设置好。这是为了满足依赖注入和装配的需要,确保Bean在使用之前具备了必要的数据。
- 初始化阶段是用户能够自定义扩展的阶段,允许在Bean实例化并且属性设置完毕后进行一些定制化操作。这些操作可能包括执行特定的初始化方法、注册监听器或者事件处理器等等。Spring提供了多种自定义扩展的机制,比如使用@PostConstruct注解标记初始化方法,实现InitializingBean接口的afterPropertiesSet()方法等。
- 销毁阶段也是用户能够自定义扩展的阶段,允许在Bean被销毁之前进行一些清理工作,释放资源等操作。在这个阶段,可以执行一些定制化的销毁方法,也可以注册一些监听器来捕获Bean被销毁的事件。Spring提供了多种自定义扩展的机制,比如使用@PreDestroy注解标记销毁方法,实现DisposableBean接口的destroy()方法等。
总的来说,Spring框架为Bean的生命周期提供了丰富的扩展点,允许开发者在不同阶段插入自定义的逻辑,以满足各种需求,确保应用程序的正常运行和资源的有效管理。
我们来用代码演示:
package com.example.springtest.beanlife;import com.example.springtest.scope.Dog;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;@Slf4j
@Component
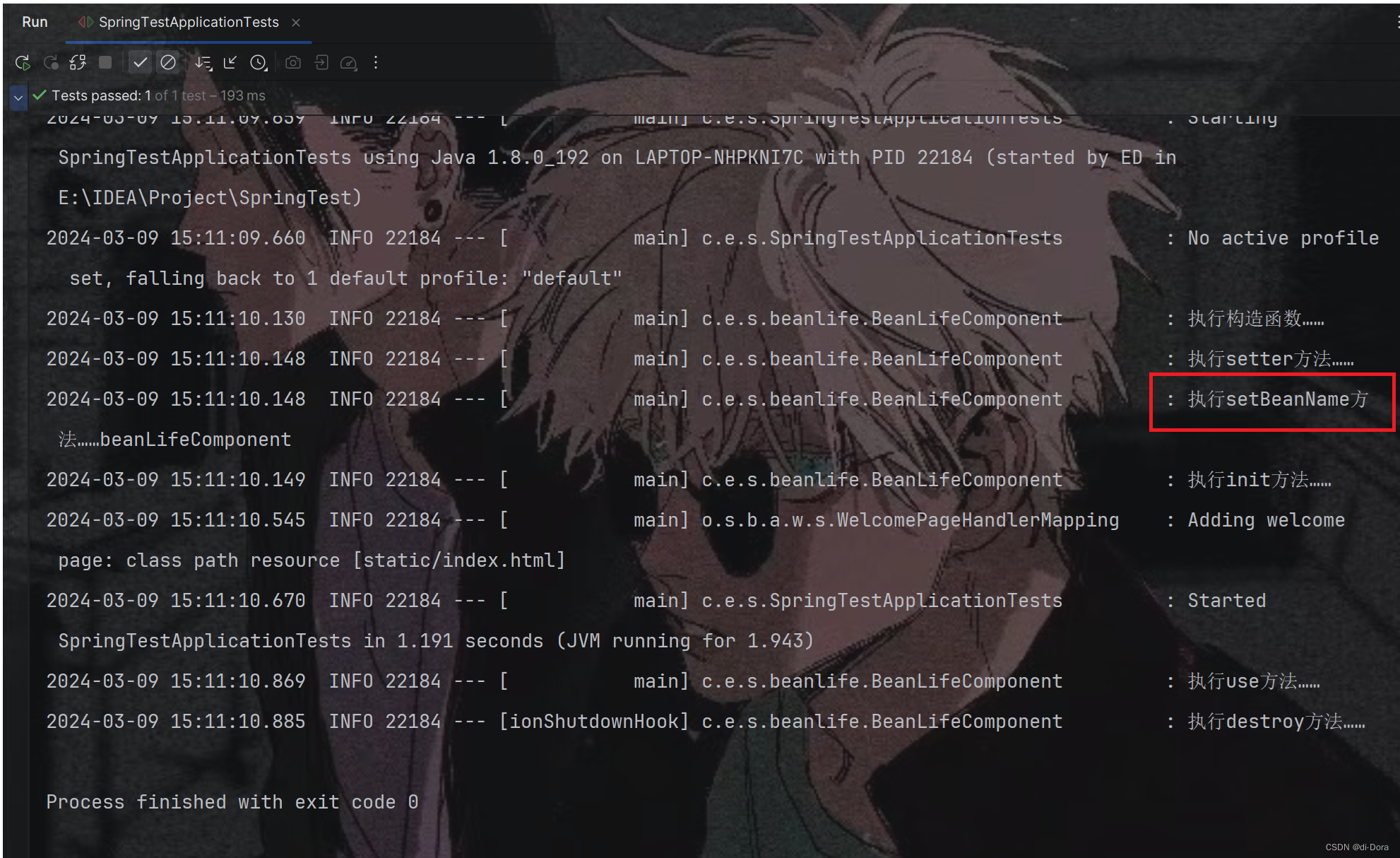
public class BeanLifeComponent {private Dog dog;public BeanLifeComponent() {log.info("执行构造函数……");}@Autowiredpublic void setDog(Dog dog) {this.dog = dog;log.info("执行setter方法……");}@PostConstructpublic void init(){log.info("执行init方法……");}public void use(){log.info("执行use方法……");}@PreDestroypublic void destroy(){log.info("执行destroy方法……");}
}
package com.example.springtest;import com.example.springtest.beanlife.BeanLifeComponent;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest
class SpringTestApplicationTests {@Autowiredprivate BeanLifeComponent beanLifeComponent;@Testvoid contextLoads() {beanLifeComponent.use();}
}
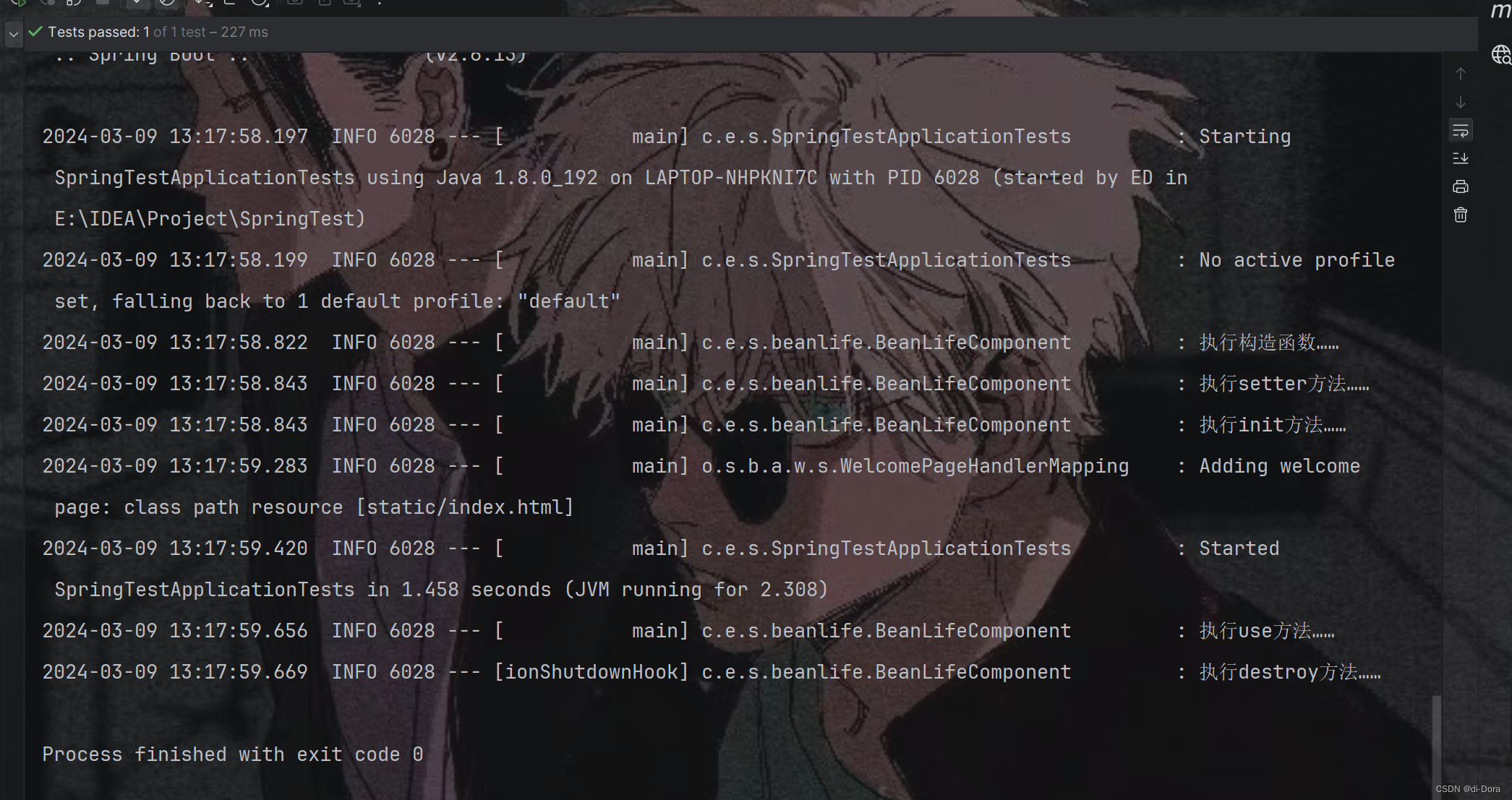
在我们的代码中,虽然只调用了use()方法,但是Spring Boot应用程序在启动时会扫描并加载所有的@Component、@Service、@Controller等注解标记的类,并且实例化这些类并加入到Spring容器中进行管理。
因此,即使只调用了use()方法,但是在Spring Boot应用程序启动时,BeanLifeComponent组件已经被实例化并加入了Spring容器中。而在实例化过程中,Spring会按照Bean的生命周期顺序执行相应的方法,包括构造函数、属性注入、初始化方法等。也就是说,在Spring Boot应用程序启动时,BeanLifeComponent的生命周期方法已经被执行了。
源码阅读
以上步骤在源码中皆有体现. 创建Bean的代码入口在:AbstractAutowireCapableBeanFactory的createBean:
这段代码是Spring Framework中创建Bean实例的核心方法之一,主要负责根据Bean的定义信息创建Bean实例。
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException {// 如果日志级别为TRACE,则记录创建bean实例的日志if (this.logger.isTraceEnabled()) {this.logger.trace("Creating instance of bean '" + beanName + "'");}// 复制原始的RootBeanDefinition对象RootBeanDefinition mbdToUse = mbd;// 解析Bean的类Class<?> resolvedClass = this.resolveBeanClass(mbd, beanName, new Class[0]);// 如果解析到了类,并且RootBeanDefinition中未设置beanClass,则将解析到的类设置为beanClassif (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) {mbdToUse = new RootBeanDefinition(mbd);mbdToUse.setBeanClass(resolvedClass);}try {// 准备方法覆盖mbdToUse.prepareMethodOverrides();} catch (BeanDefinitionValidationException var9) {// 如果准备方法覆盖失败,则抛出BeanDefinitionStoreException异常throw new BeanDefinitionStoreException(mbdToUse.getResourceDescription(), beanName, "Validation of method overrides failed", var9);}Object beanInstance;try {// 在实例化之前解析BeanbeanInstance = this.resolveBeforeInstantiation(beanName, mbdToUse);// 如果解析到了Bean实例,则直接返回if (beanInstance != null) {return beanInstance;}} catch (Throwable var10) {// 如果解析失败,则抛出BeanCreationException异常throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName, "BeanPostProcessor before instantiation of bean failed", var10);}try {// 创建Bean实例beanInstance = this.doCreateBean(beanName, mbdToUse, args);// 如果日志级别为TRACE,则记录创建bean实例完成的日志if (this.logger.isTraceEnabled()) {this.logger.trace("Finished creating instance of bean '" + beanName + "'");}// 返回创建的Bean实例return beanInstance;} catch (ImplicitlyAppearedSingletonException | BeanCreationException var7) {// 如果出现单例异常或者Bean创建异常,则直接抛出throw var7;} catch (Throwable var8) {// 如果创建Bean过程中出现其他异常,则抛出BeanCreationException异常throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName, "Unexpected exception during bean creation", var8);}
}
大致流程和思想如下:
- 解析Bean的定义信息,包括Bean的类和方法覆盖等信息。
- 在实例化Bean之前,执行BeanPostProcessor的前置处理器。
- 实例化Bean对象,并根据Bean的定义信息进行属性注入等操作。
- 执行BeanPostProcessor的后置处理器,完成Bean的初始化工作。
- 返回创建的Bean实例。
总的来说,这段代码负责实现了Bean的创建过程,包括解析Bean定义、实例化Bean、属性注入、Bean的前置处理和后置处理等。
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException {// 创建BeanWrapper对象实例,用于包装BeanBeanWrapper instanceWrapper = null;// 如果Bean是单例模式,并且存在于factoryBeanInstanceCache中,则从缓存中移除if (mbd.isSingleton()) {instanceWrapper = (BeanWrapper)this.factoryBeanInstanceCache.remove(beanName);}// 如果instanceWrapper为null,则通过createBeanInstance方法创建Bean实例if (instanceWrapper == null) {instanceWrapper = this.createBeanInstance(beanName, mbd, args);}// 获取包装实例的Bean对象Object bean = instanceWrapper.getWrappedInstance();// 获取包装实例的Bean对象的类型Class<?> beanType = instanceWrapper.getWrappedClass();// 如果Bean类型不为NullBean,则设置mbd的resolvedTargetType为beanTypeif (beanType != NullBean.class) {mbd.resolvedTargetType = beanType;}// 同步块,确保后续处理的原子性synchronized(mbd.postProcessingLock) {// 如果BeanDefinition尚未被后处理,则进行后处理if (!mbd.postProcessed) {try {this.applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);} catch (Throwable var17) {throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Post-processing of merged bean definition failed", var17);}// 标记BeanDefinition已经被后处理mbd.postProcessed = true;}}// 是否提前暴露单例Bean,用于解决循环依赖boolean earlySingletonExposure = mbd.isSingleton() && this.allowCircularReferences && this.isSingletonCurrentlyInCreation(beanName);// 如果允许提前暴露单例Beanif (earlySingletonExposure) {// 输出日志,表示将Bean放入早期缓存以解决潜在的循环引用if (this.logger.isTraceEnabled()) {this.logger.trace("Eagerly caching bean '" + beanName + "' to allow for resolving potential circular references");}// 将Bean的提前引用放入单例工厂this.addSingletonFactory(beanName, () -> {return this.getEarlyBeanReference(beanName, mbd, bean);});}// 暴露Bean对象Object exposedObject = bean;try {// 填充Bean属性this.populateBean(beanName, mbd, instanceWrapper);// 初始化BeanexposedObject = this.initializeBean(beanName, exposedObject, mbd);} catch (Throwable var18) {if (var18 instanceof BeanCreationException && beanName.equals(((BeanCreationException)var18).getBeanName())) {throw (BeanCreationException)var18;}throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Initialization of bean failed", var18);}// 如果允许提前暴露单例Beanif (earlySingletonExposure) {Object earlySingletonReference = this.getSingleton(beanName, false);if (earlySingletonReference != null) {if (exposedObject == bean) {exposedObject = earlySingletonReference;} else if (!this.allowRawInjectionDespiteWrapping && this.hasDependentBean(beanName)) {String[] dependentBeans = this.getDependentBeans(beanName);Set<String> actualDependentBeans = new LinkedHashSet(dependentBeans.length);String[] var12 = dependentBeans;int var13 = dependentBeans.length;for(int var14 = 0; var14 < var13; ++var14) {String dependentBean = var12[var14];if (!this.removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {actualDependentBeans.add(dependentBean);}}if (!actualDependentBeans.isEmpty()) {throw new BeanCurrentlyInCreationException(beanName, "Bean with name '" + beanName + "' has been injected into other beans [" + StringUtils.collectionToCommaDelimitedString(actualDependentBeans) + "] in its raw version as part of a circular reference, but has eventually been wrapped. This means that said other beans do not use the final version of the bean. This is often the result of over-eager type matching - consider using 'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.");}}}}try {// 注册可销毁的Bean,如果有必要的话this.registerDisposableBeanIfNecessary(beanName, bean, mbd);return exposedObject;} catch (BeanDefinitionValidationException var16) {throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Invalid destruction signature", var16);}
}
上面提供的代码是Spring框架中用于创建Bean实例的关键方法doCreateBean()。该方法负责完成Bean的实例化、属性填充、初始化等过程,并且处理了循环依赖的情况。
大致流程:
- 创建BeanWrapper对象: 首先,声明了一个BeanWrapper对象实例,用于包装Bean。
- 检查是否从缓存中获取Bean: 如果Bean是单例模式,并且在factoryBeanInstanceCache中存在,则从缓存中移除。
- 创建Bean实例: 如果无法从缓存中获取Bean,则调用createBeanInstance()方法创建Bean实例。
- 获取Bean的类型并设置到BeanDefinition中: 获取Bean的实例和类型,如果Bean类型不是NullBean,则将其设置到BeanDefinition的resolvedTargetType属性中。
- 后处理BeanDefinition: 使用同步块确保后续处理的原子性,如果BeanDefinition尚未被后处理,则进行后处理操作,并标记为已处理。
- 提前暴露单例Bean: 根据配置,如果允许提前暴露单例Bean,则将Bean放入早期缓存以解决潜在的循环引用。
- 填充Bean属性和初始化Bean: 调用populateBean()方法填充Bean属性,然后调用initializeBean()方法初始化Bean。
- 处理循环依赖: 如果允许提前暴露单例Bean,则在此处处理循环依赖的情况。
- 注册可销毁的Bean: 最后,如果有必要,注册可销毁的Bean。
总的来说,这段代码是Spring中创建Bean的核心逻辑。它负责实例化Bean、处理Bean的属性注入、初始化Bean、处理循环依赖等任务,确保了Bean能够正确地被创建和管理。该方法通过调用一系列的子方法来完成这些任务,包括 createBeanInstance()、populateBean()、initializeBean()等。
这三个方法与Bean的生命周期的不同阶段对应:
-
createBeanInstance() -> 实例化:这个方法负责创建Bean的实例。在这个阶段,会调用构造函数来实例化对象,并且初始化其成员变量。这一过程可以看作是Bean的诞生过程,即从无到有的过程。
-
populateBean() -> 属性赋值:在实例化完成后,容器会对Bean进行属性赋值,也就是将所需的属性值设置到相应的属性中。这一阶段涉及到依赖注入、装配等过程,确保Bean的各个属性都被正确地初始化和设置。
-
initializeBean() -> 初始化:在属性赋值完成后,容器会调用初始化方法对Bean进行初始化。这一阶段包括执行各种初始化操作,比如调用init-method指定的初始化方法、执行@PostConstruct注解标注的方法等。在这个阶段,开发者可以进行一些自定义的初始化操作,确保Bean在被使用前已经做好了准备。
这三个方法依次对应了Bean生命周期的不同阶段,确保了Bean在被实例化、属性赋值和初始化之后能够正确地被使用。
所以说这段代码实现了Spring容器对Bean的创建和初始化过程的管理,其中涉及到了对单例Bean的缓存处理,以及对循环依赖的解决。
Spring框架中通过三级缓存来解决循环依赖的问题。
当一个Bean A依赖于另一个Bean B,而Bean B又依赖于Bean A时,就会产生循环依赖的问题。为了解决这个问题,Spring使用了三级缓存的机制。
-
第一级缓存: 在第一次创建Bean A的过程中,如果发现了循环依赖,Spring会将Bean A的创建过程放入第一级缓存中。这样,在创建Bean A的过程中,如果需要依赖Bean B,Spring会发现Bean B的创建过程已经在进行中,而不会再次创建Bean B,从而避免了循环依赖问题。
-
第二级缓存: 如果第一级缓存中无法解决循环依赖问题,那么Spring会将Bean A的半成品(还未完成初始化)放入第二级缓存中。这样,在创建Bean B的过程中,如果需要依赖Bean A,Spring会发现Bean A的半成品已经存在,从而避免了循环依赖问题。
因为当Spring发现Bean A的半成品已经存在于第二级缓存中时,说明Bean A已经被实例化但尚未完成初始化。这时候,如果Bean B需要依赖Bean A,Spring可以获取到Bean A的半成品,即可使用它来满足Bean B的依赖关系。这种情况下,虽然Bean A的实例尚未完全初始化,但已经足够提供给其他Bean使用,因为它的实例已经存在并且可以被引用。因此,通过将Bean A的半成品放入第二级缓存中,Spring能够解决循环依赖问题,确保了Bean的实例化过程不会出现死锁或循环引用的情况。 -
第三级缓存: 如果第二级缓存也无法解决循环依赖问题,那么Spring会将Bean A的ObjectFactory放入第三级缓存中。这样,在创建Bean B的过程中,如果需要依赖Bean A,Spring会使用ObjectFactory创建Bean A的代理对象,从而避免了循环依赖问题。
通过这三级缓存的机制,Spring能够在创建Bean时,动态地解决循环依赖问题,确保了Bean的正确创建和初始化。
这个过程可以简单地概括为以下几个步骤:
-
创建Bean的原始定义: 在Spring容器启动时,首先会读取配置文件或者扫描注解,将Bean的原始定义(比如Bean的类名、属性、依赖等)解析为一个BeanDefinition对象。
-
实例化Bean并放入一级缓存: 在Bean的原始定义得到解析后,Spring会尝试实例化这些Bean对象。如果Bean的实例化过程中发现了循环依赖,Spring会将尚未完成实例化的Bean放入一级缓存中。
-
提前暴露半成品Bean并放入二级缓存: 当有循环依赖时,Spring会提前暴露尚未完成实例化的Bean,使得其他Bean可以引用到它的半成品状态。这样,一旦其他Bean需要引用该Bean,就可以通过二级缓存中的半成品对象来满足依赖关系。
-
完成Bean的实例化并放入三级缓存: 当Bean的实例化完成后,Spring会将其放入三级缓存中,以便后续的Bean的实例化过程中能够直接获取到该Bean的完整实例,而不再需要递归实例化依赖的Bean。
-
循环依赖的处理: 在实例化Bean的过程中,如果发现了循环依赖,Spring会通过提前暴露半成品Bean的方式来破解循环依赖,从而保证Bean的实例化过程能够正常完成。
总结来说,Spring通过三级缓存的机制来解决循环依赖的问题,保证了Bean的实例化过程能够顺利进行,并且能够正确处理循环依赖的情况,确保了Spring容器的稳定运行。
接回上面的代码,我们再点进去看看:
protected Object initializeBean(String beanName, Object bean, @Nullable RootBeanDefinition mbd) {// 检查是否有安全管理器,如果有,则使用特权执行,否则直接调用invokeAwareMethods方法if (System.getSecurityManager() != null) {AccessController.doPrivileged(() -> {this.invokeAwareMethods(beanName, bean);return null;}, this.getAccessControlContext());} else {this.invokeAwareMethods(beanName, bean);}// 初始化时的Bean实例Object wrappedBean = bean;// 如果Bean定义不是合成的,则应用初始化之前的Bean后置处理器if (mbd == null || !mbd.isSynthetic()) {wrappedBean = this.applyBeanPostProcessorsBeforeInitialization(bean, beanName);}try {// 调用初始化方法this.invokeInitMethods(beanName, wrappedBean, mbd);} catch (Throwable var6) {// 捕获异常并抛出BeanCreationExceptionthrow new BeanCreationException(mbd != null ? mbd.getResourceDescription() : null, beanName, "Invocation of init method failed", var6);}// 如果Bean定义不是合成的,则应用初始化之后的Bean后置处理器if (mbd == null || !mbd.isSynthetic()) {wrappedBean = this.applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);}// 返回初始化后的Bean实例return wrappedBean;
}// 调用Aware接口的相关方法
private void invokeAwareMethods(String beanName, Object bean) {// 如果Bean实现了Aware接口,则调用相关的方法if (bean instanceof Aware) {// 如果Bean实现了BeanNameAware接口,则调用setBeanName方法设置Bean名称if (bean instanceof BeanNameAware) {((BeanNameAware)bean).setBeanName(beanName);}// 如果Bean实现了BeanClassLoaderAware接口,则调用setBeanClassLoader方法设置Bean类加载器if (bean instanceof BeanClassLoaderAware) {ClassLoader bcl = this.getBeanClassLoader();if (bcl != null) {((BeanClassLoaderAware)bean).setBeanClassLoader(bcl);}}// 如果Bean实现了BeanFactoryAware接口,则调用setBeanFactory方法设置BeanFactoryif (bean instanceof BeanFactoryAware) {((BeanFactoryAware)bean).setBeanFactory(this);}}
}
这段代码主要负责Bean的初始化过程,包括调用Aware接口的相关方法、应用初始化前后的Bean后置处理器以及调用初始化方法。其中,invokeAwareMethods方法用于调用Bean实现了Aware接口的相关方法,而initializeBean方法则包含了整个Bean初始化过程的核心逻辑。
- initializeBean方法首先检查是否有安全管理器,如果有则使用特权执行,否则直接调用invokeAwareMethods方法。
- 在调用Aware接口的相关方法后,应用初始化之前的Bean后置处理器。
- 接着,调用Bean的初始化方法。
- 如果初始化过程中出现异常,则捕获异常并抛出BeanCreationException。
- 最后,应用初始化之后的Bean后置处理器,并返回初始化后的Bean实例。
这一段代码展示了Spring容器在初始化Bean时的核心流程,确保了Bean能够正确地完成初始化过程。
我们通过代码再来演示一下:
package com.example.springtest.beanlife;import com.example.springtest.scope.Dog;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanWrapperImpl;
import org.springframework.beans.factory.BeanNameAware;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;@Slf4j
@Component
public class BeanLifeComponent implements BeanNameAware {private Dog dog;public BeanLifeComponent() {log.info("执行构造函数……");}@Autowiredpublic void setDog(Dog dog) {this.dog = dog;log.info("执行setter方法……");}@PostConstructpublic void init(){log.info("执行init方法……");}public void use(){log.info("执行use方法……");}@PreDestroypublic void destroy(){log.info("执行destroy方法……");}@Overridepublic void setBeanName(String s) {log.info("执行setBeanName方法……"+s);}
}
Spring Boot自动配置
Spring Boot的自动配置是Spring Boot框架提供的一项特性,它在Spring容器启动后会自动加载一些配置类和Bean对象到IoC容器中,无需手动声明,从而简化了开发流程,减少了繁琐的配置操作。
具体来说,Spring Boot的自动配置是通过扫描classpath下的各种配置类和标记了特定注解的类来实现的。这些配置类通常位于依赖jar包中,其中可能包含了一些默认的配置信息、Bean定义以及各种组件。Spring Boot会自动识别这些配置类,并根据特定的规则将它们加载到Spring IoC容器中。
在加载这些配置类时,Spring Boot会根据条件判断是否需要应用这些配置。例如,它会检查当前项目中的其他配置、环境变量、系统属性等,来决定是否应用某个配置类。这样一来,开发者可以根据自己的需求对自动配置进行定制,从而实现更灵活和个性化的配置。
总的来说,Spring Boot的自动配置使得开发者可以更加专注于业务逻辑的实现,而无需过多关注底层的配置细节,极大地提高了开发效率和代码质量。
我们了解主要分以下两个方面:
1. Spring 是如何把对象加载到SpringIoC容器中的
2. SpringBoot 是如何实现的
Spring 加载Bean
问题描述
需求:使用Spring管理第三方的jar包配置。
引入第三方的包,其实就是在该项目下,引⼊第三方的代码。我们采⽤在该项目下创建不同的目录来模拟第三方的代码引入。
数据准备:
第三方文件代码:
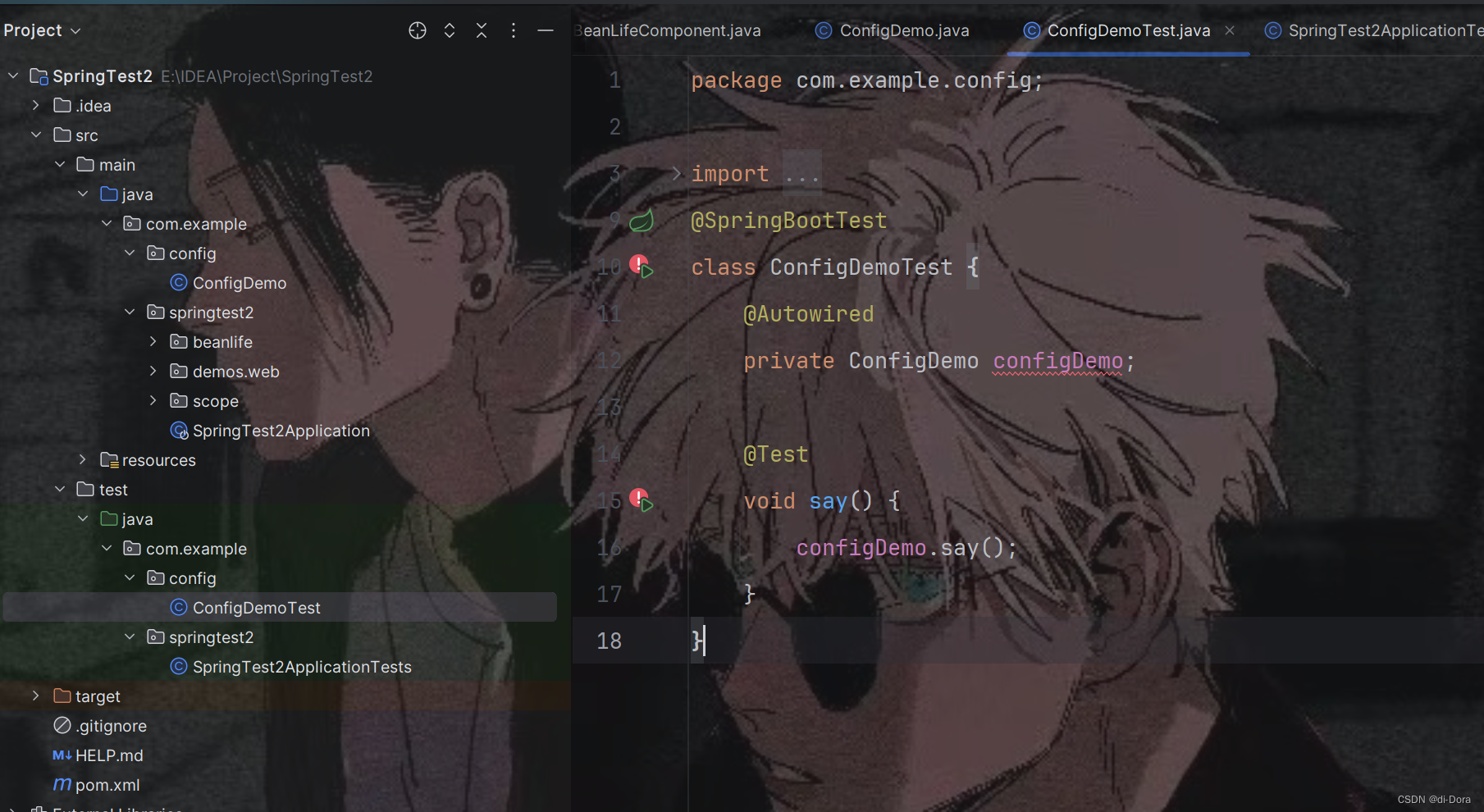
写测试代码:
运行程序:
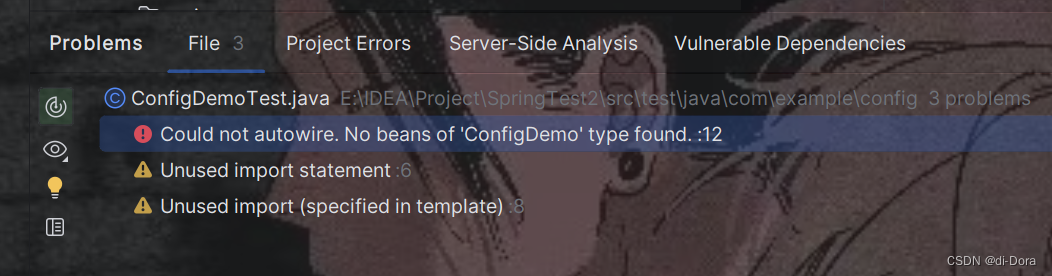
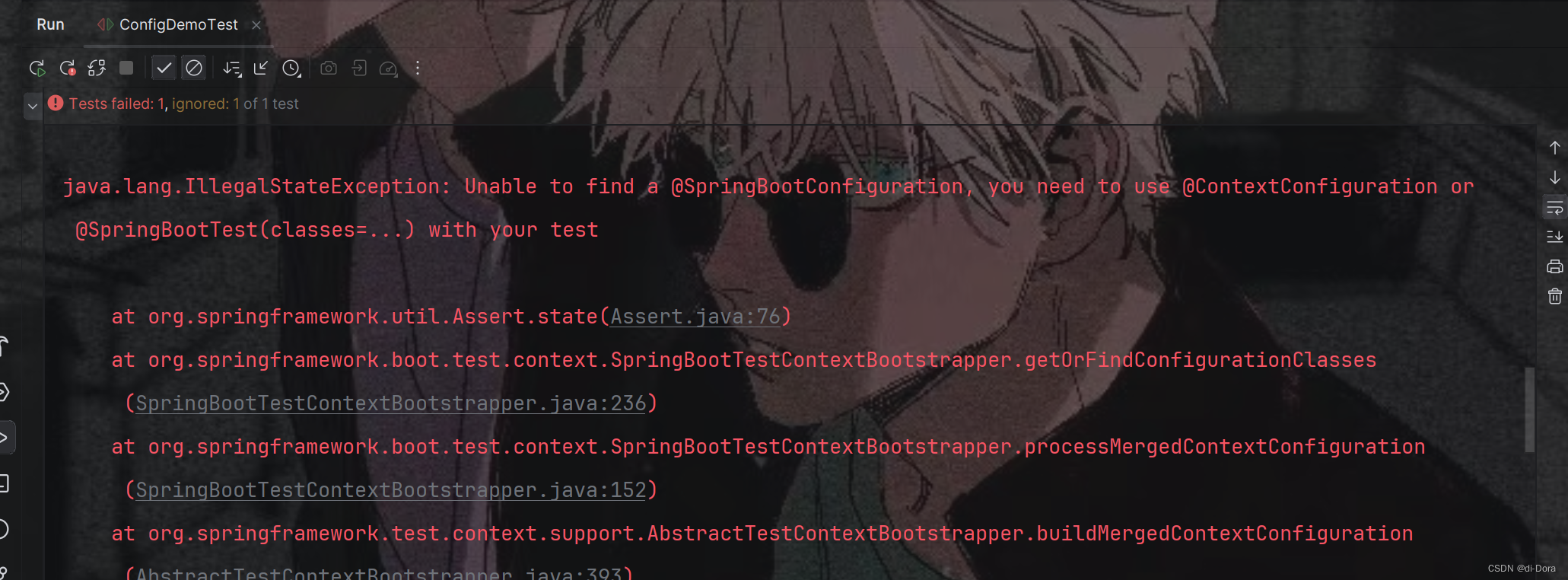
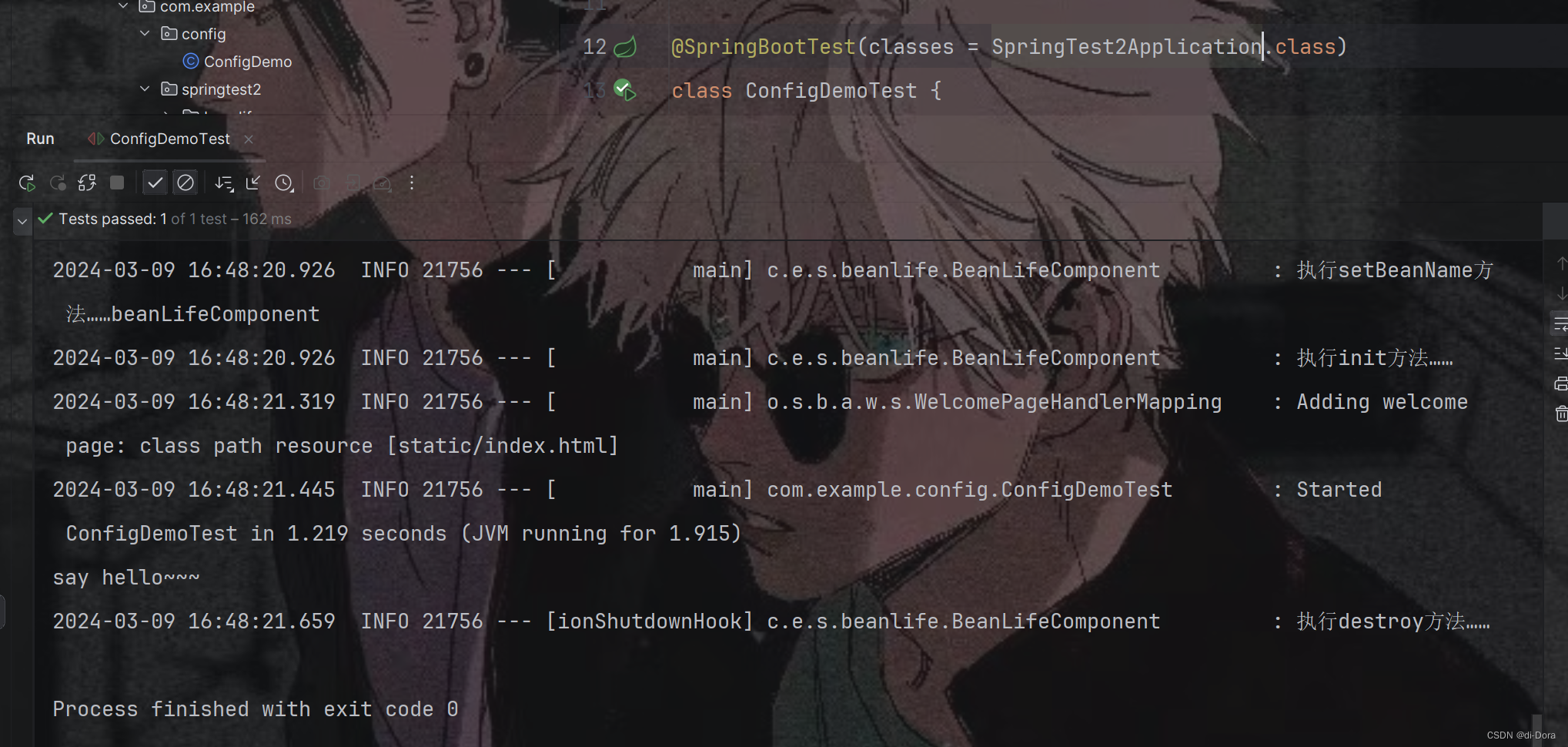
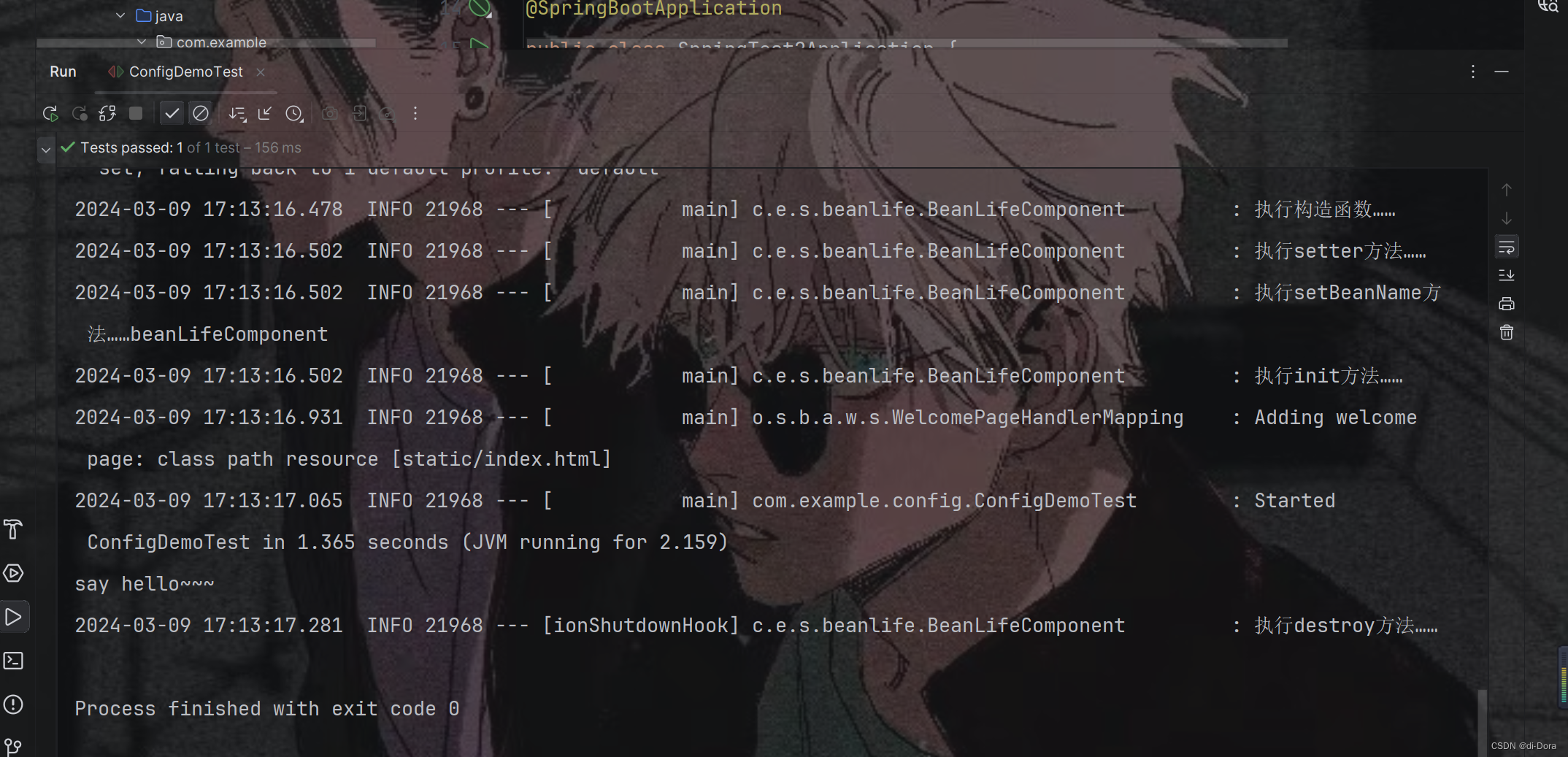
观察日志:
在我们的测试类 ConfigDemoTest 中,已经使用了 @SpringBootTest 注解来加载 Spring 上下文,这通常可以自动配置并加载所有的 bean。但是,我们收到了一个错误,说明找不到 ConfigDemo 类型的 bean。
这可能是由于 Spring 上下文没有正确加载 ConfigDemo 类,或者 ConfigDemo 类没有被正确识别为一个 bean。在这种情况下,我们需要确保以下几点:
1、ConfigDemo 类被正确标记为一个 bean。我们已经在 ConfigDemo 类上使用了 @Component 注解,这是正确的。但是,确保这个注解被正确导入……
但是我们明明加了@Component了。
2、ConfigDemo 类所在的包被正确扫描。在 Spring Boot 项目中,通常会将 @SpringBootApplication 注解添加到启动类上,以确保所有包都被正确扫描。如果 ConfigDemo 类不在启动类所在的包或其子包中,我们可能需要在启动类上添加 @ComponentScan 注解来指定要扫描的包。
我们需要确保 ConfigDemo 类所在的包在测试类的包或其父包下。否则,ConfigDemo 类可能不会被扫描到。如果我们使用的是自定义配置文件来配置 bean,则需要确保配置文件被正确加载。在 @SpringBootTest 注解中,可以使用 properties 参数来指定要加载的配置文件。
检查以上几点,只能猜测是第二个原因了。
原因分析
Spring通过五大注解和 @Bean 注解可以帮助我们把Bean加载到SpringIoC容器中,但是以上有个前提就是这些注解类需要和SpringBoot启动类在同一个项目下,即 @SpringBootApplication 标注的类,也就是SpringBoot项⽬的启动类。
当我们引入第三方的Jar包时,第三方的Jar代码目录肯定不在启动类的目录下。
此时我们如何告诉Spring帮忙管理这些Bean呢?
解决方案
当我们引入第三方的 jar 包时,其代码目录通常不会与 Spring Boot 项目的启动类在同一个目录下。为了让 Spring 能够扫描到这些第三方 jar 包中的组件并加载到 Spring IoC 容器中,我们需要采取一些解决方案。常见的解决方案有两种:
-
@ComponentScan 组件扫描: 在 Spring Boot 项目中,通常会有一个主启动类,该类上会使用 @SpringBootApplication 注解进行标注。这个注解会自动进行组件扫描并将其加载到 Spring IoC 容器中。除了主启动类之外,其他需要被 Spring 管理的组件也可以使用 @ComponentScan 注解或者其他方式指定扫描的包路径,以确保它们被 Spring 框架扫描到并加载到 IoC 容器中。
-
@Import 导入: 使用 @Import 注解可以导入其他的配置类或者普通的 Java 类,被导入的类会被 Spring 加载到 IoC 容器中。通过在主配置类上使用 @Import 注解导入需要加载的类,可以让 Spring 加载这些类并管理它们。
我们通过代码来看如何解决:
@ComponentScan:
通过 @ComponentScan 注解,指定Spring扫描路径。
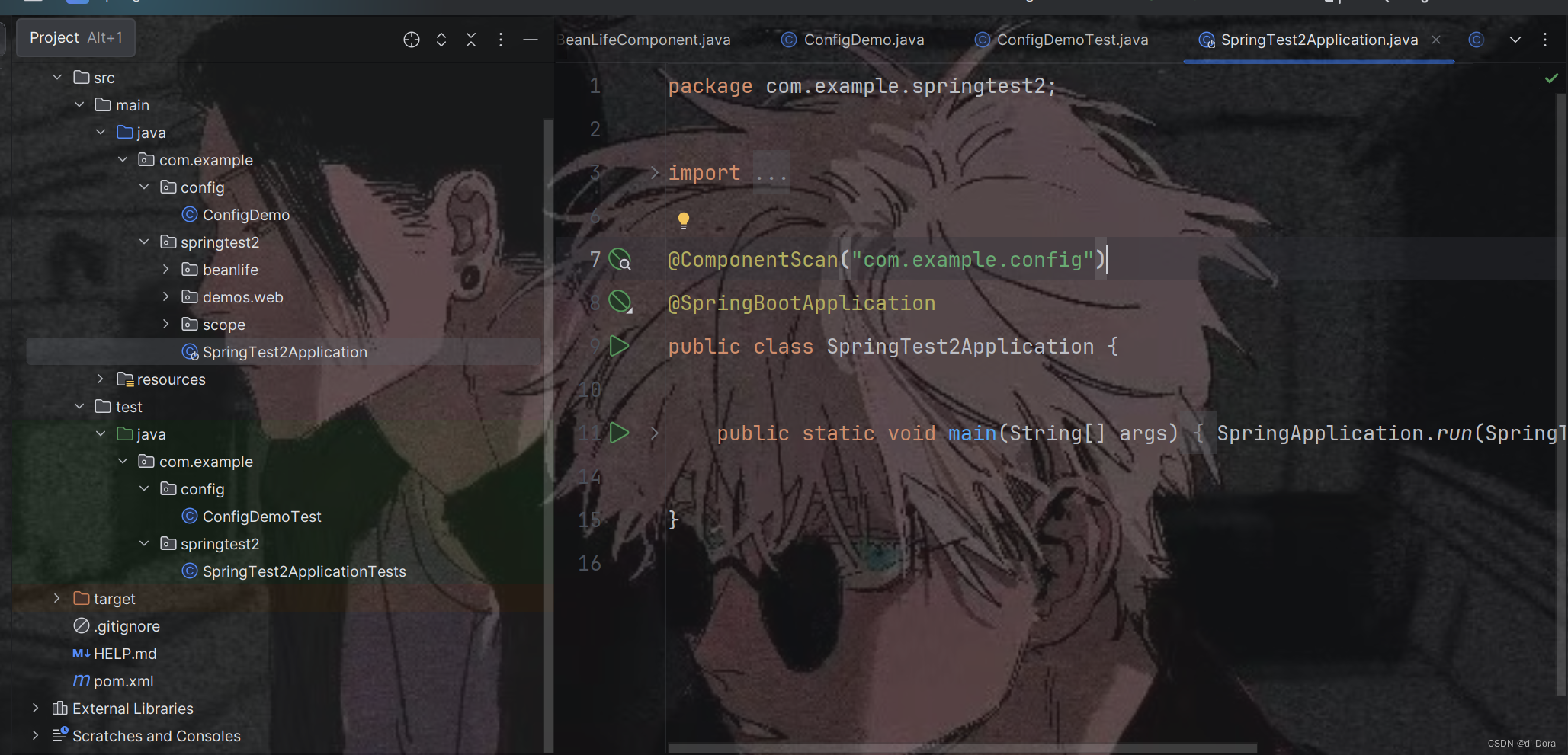
此时我们已经在 SpringTest2Application 类中使用了 @ComponentScan("com.example") 来指定要扫描的包及其子包。因此,理论上来说,Spring 应该能够扫描到 com.example.config 包中的 ConfigDemo 类。
然而,可能还会遇到问题,这是由于测试类 ConfigDemoTest 没有指定要加载的 Spring Boot 配置类所致。由于 ConfigDemoTest 测试类位于一个不是 Spring Boot 主配置类的地方,Spring Boot 并不知道应该加载哪个配置类来创建应用程序上下文。这可能导致无法自动扫描到 ConfigDemo 类型的 bean。
为了解决这个问题,我们可以使用 @SpringBootTest 注解的 classes 参数来显式指定要加载的配置类。
例如,我们可以在 @SpringBootTest 注解中添加 classes = SpringTest2Application.class,以告诉 Spring Boot 在测试时使用 SpringTest2Application 主配置类。
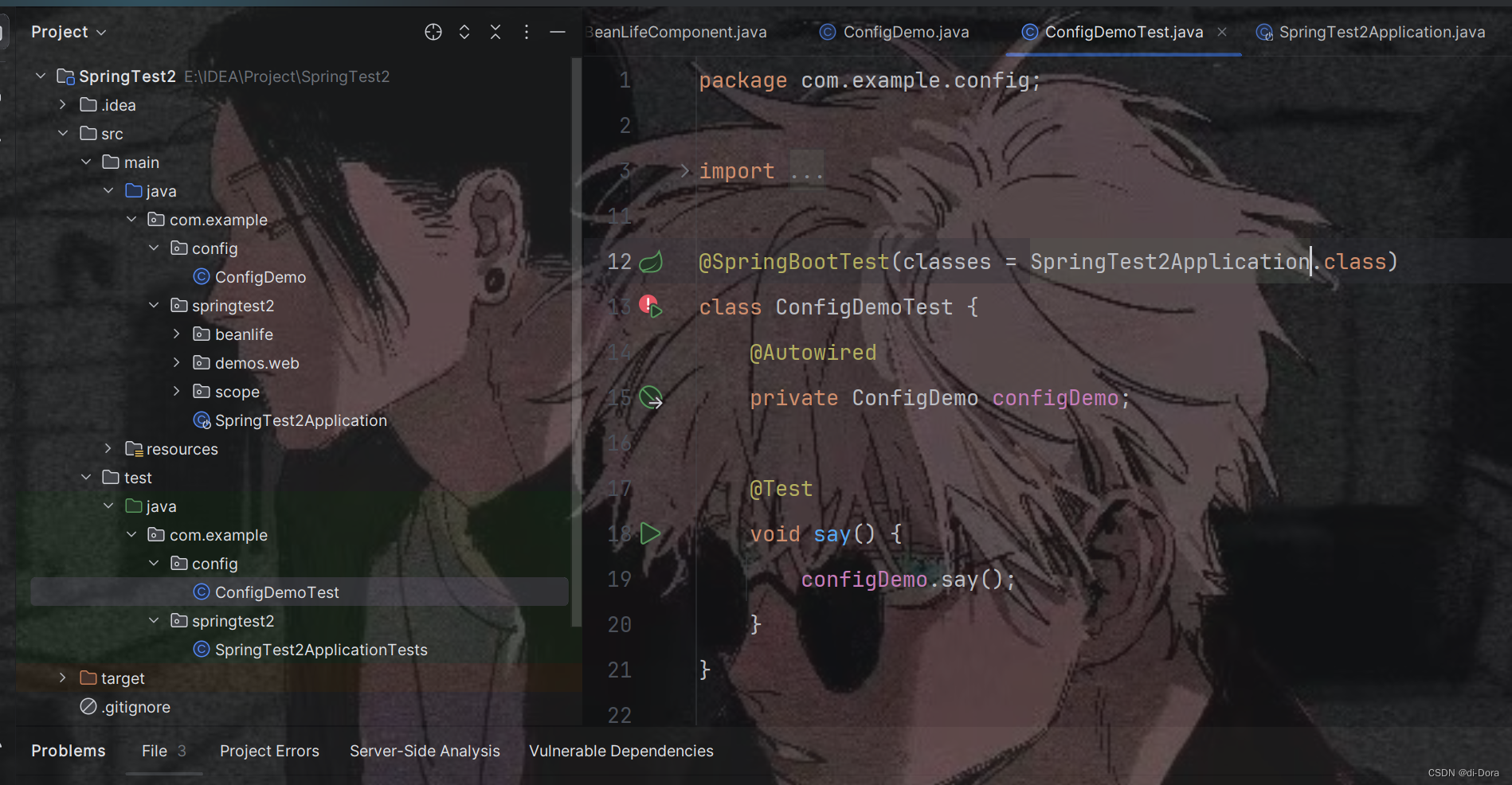
现在运行:
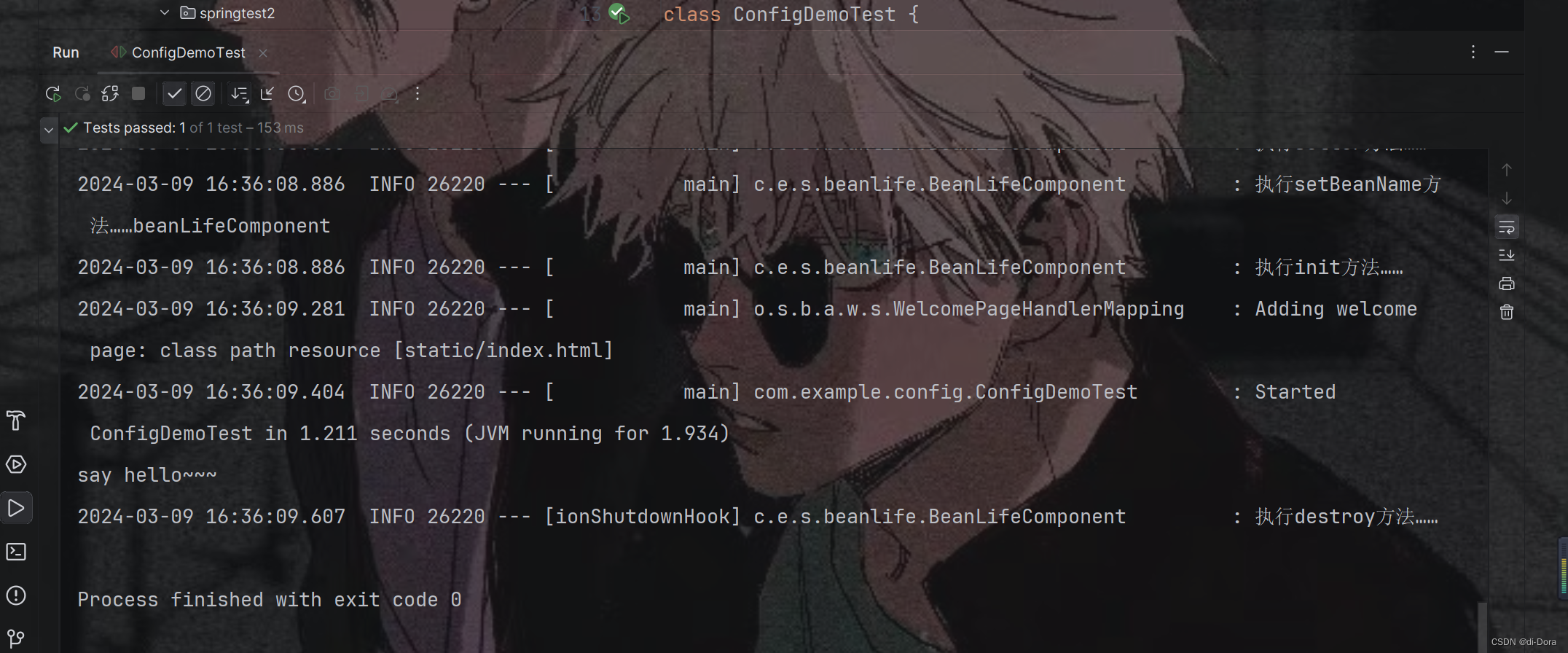
除此之外,@ComponentScan 注解允许我们指定要扫描的多个包,可以通过传递一个包含包名的字符串数组来实现。
例如,我们可以这样使用 @ComponentScan 注解来同时扫描 com.bite.autoconfig 和 com.example.demo 包及其子包:
@ComponentScan({"com.bite.autoconfig", "com.example.demo"})
这样设置后,Spring 将会扫描这两个指定的包及其子包,以查找带有 @Component 或其他注解的组件,并将它们注册到 Spring IoC 容器中。这样做可以确保我们的应用程序中的所有相关组件都会被正确地扫描和加载。
Spring 是否使用了这种方式呢?
非常明显,Spring Boot 并没有采用这种方式来管理第三方依赖的配置。(因为我们引⼊第三方框架时,没有加扫描路径。比如mybatis)。如果每次引入一个第三方依赖都需要手动配置扫描路径,将会非常繁琐。Spring Boot 采用了自动配置的方式来简化开发流程,它会根据类路径下的依赖和条件自动配置 Spring应用程序。对于大多数常用的第三方库和框架,Spring Boot 已经提供了自动配置,无需手动干预。
具体来说:
Spring Boot 采用了自动配置的方式来管理第三方依赖,而不是使用 @ComponentScan 这种方式。自动配置是通过在 Spring Boot 启动类上使用 @SpringBootApplication 注解来实现的。这个注解包含了多个注解的功能,其中包括了 @ComponentScan 注解。
当我们引入第三方依赖时,Spring Boot 会根据依赖的类路径自动检测并配置相应的组件。例如,当引入 MyBatis 依赖时,Spring Boot 会自动检测到 MyBatis 相关的配置类,并将其集成到应用程序中。
因此,我们无需手动配置扫描路径或使用 @ComponentScan 注解来扫描第三方依赖的包。这种自动配置的方式大大简化了开发流程,并使得应用程序的配置更加简洁和易于维护。
@Import
@Import 注解主要有以下几种形式:
导入类: 可以直接将一个或多个类导入到当前的配置类中。这些类可以是普通的配置类、普通的 Bean 类或者其他注解类。
@Import({MyConfiguration.class, MyBean.class})
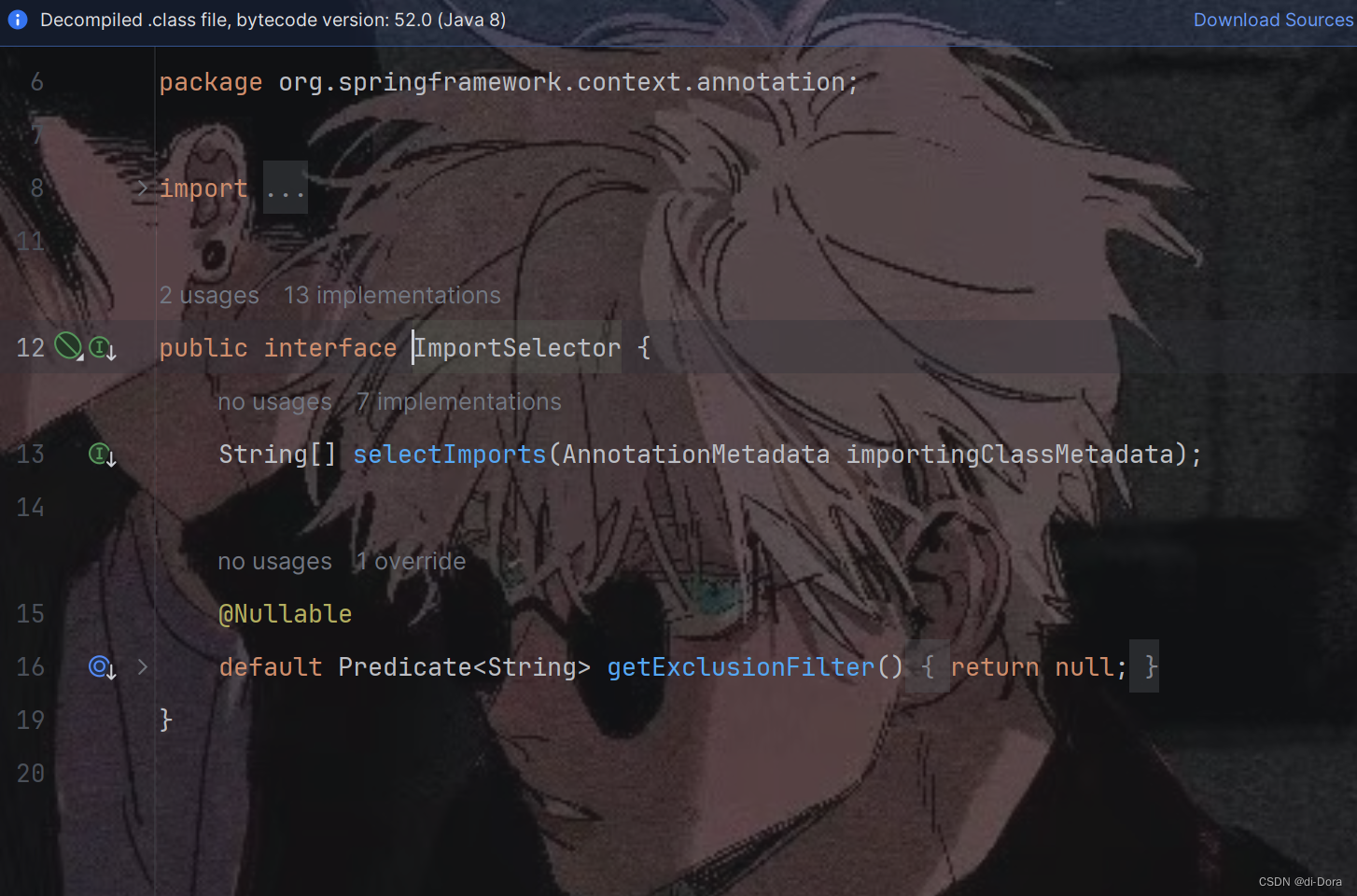
导入 ImportSelector 接口实现类: ImportSelector 接口允许我们根据条件动态地选择要导入的配置类。通过实现 ImportSelector 接口,我们可以根据条件返回需要导入的配置类的全限定名数组。
public class MyImportSelector implements ImportSelector {@Overridepublic String[] selectImports(AnnotationMetadata importingClassMetadata) {// 根据条件动态选择要导入的配置类if (someCondition) {return new String[]{MyConfiguration1.class.getName()};} else {return new String[]{MyConfiguration2.class.getName()};}}
}
然后需要在配置类中使用 @Import 注解导入 ImportSelector 接口实现类。
@Import(MyImportSelector.class)
导入类
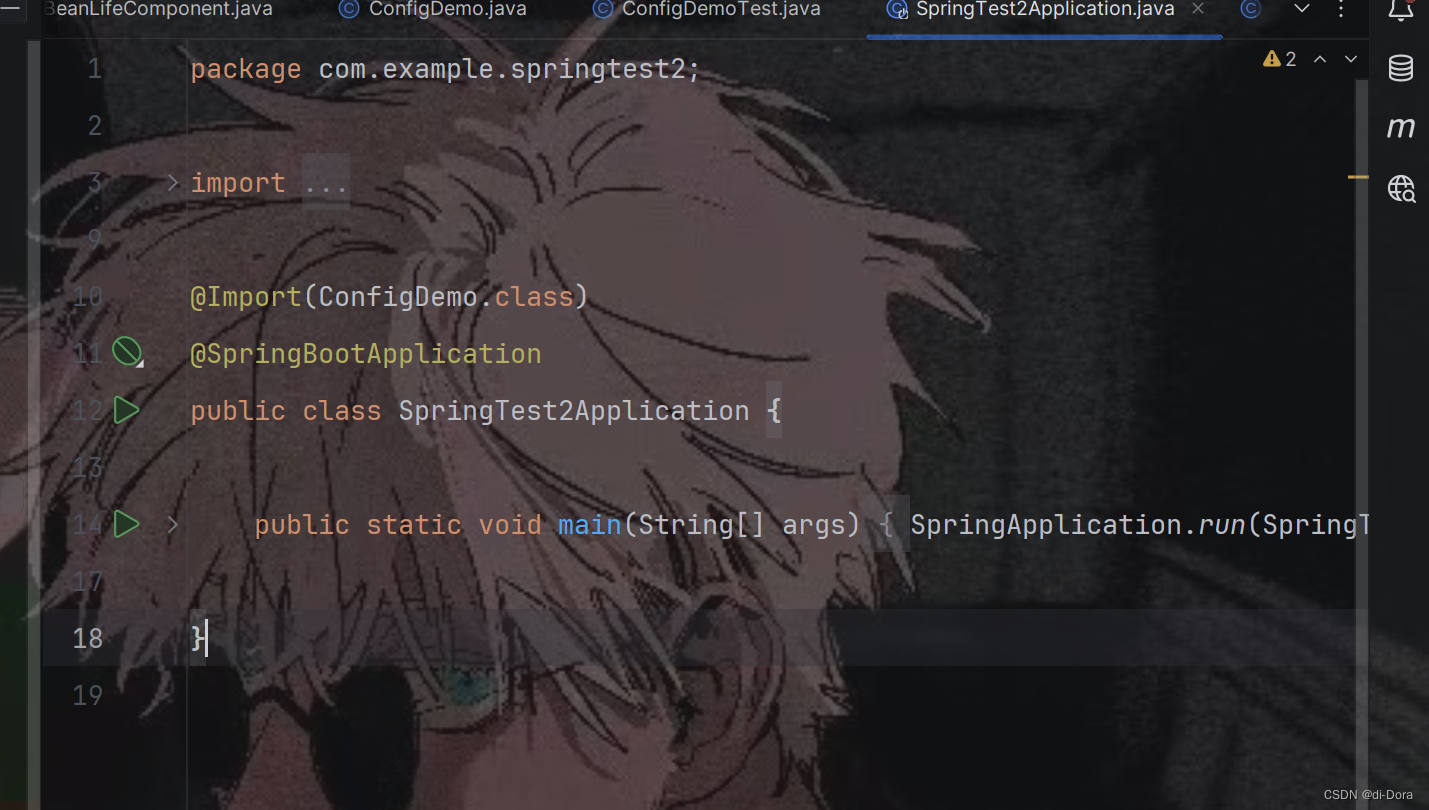
尽管 @Import 注解提供了一种动态导入类的方式,但它在实际使用中可能会显得繁琐,尤其是在需要导入多个类或根据条件动态选择导入类时。因此,虽然 @Import 注解是 Spring 框架提供的强大功能之一,但 Spring Boot 并没有采用这种方式来管理第三方依赖的配置,而是选择了更简洁、更智能的自动配置方式来简化开发流程。
导入ImportSelector接口实现类
ImportSelector 接口实现类:
package com.example.springtest2;import org.springframework.context.annotation.ImportSelector;
import org.springframework.core.type.AnnotationMetadata;import java.util.function.Predicate;public class MySelect implements ImportSelector {@Overridepublic String[] selectImports(AnnotationMetadata importingClassMetadata){//需要导入的全限定类名return new String[]{"com.example.config.ConfigDemo"};}
}
启动类:
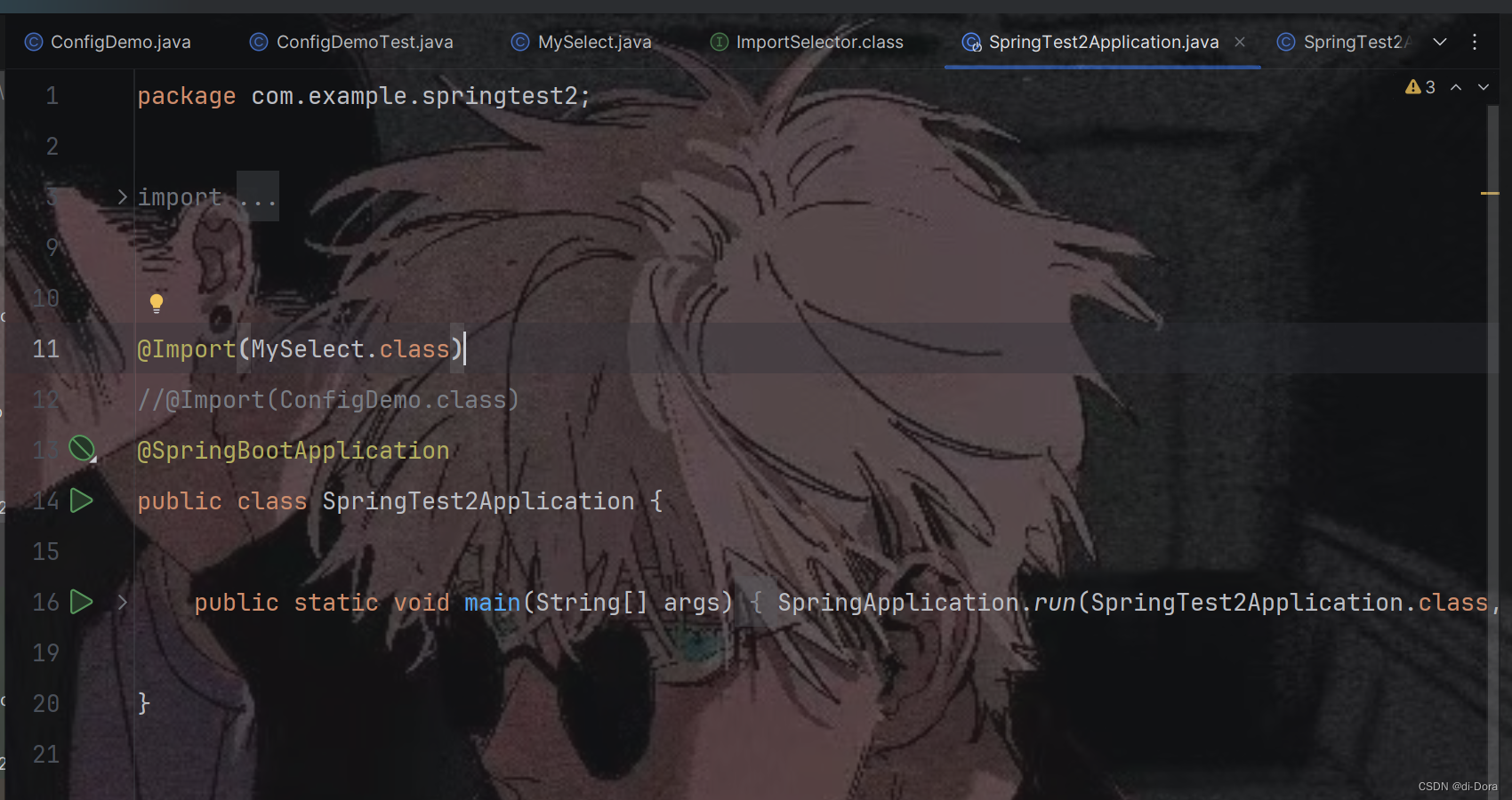

可以看到, 我们确实也采用这种方式导人第三方依赖提供的Bean。
但是使用导入类、实现 ImportSelector 接口的类、以及 @ComponentScan 注解等方式存在一个明显问题。这些方式需要使用者明确地知道第三方依赖中存在哪些Bean对象或配置类,并且手动进行相应的配置。如果使用者在配置过程中漏掉了其中的某些Bean,可能会导致项目出现严重的问题或者故障。
这对程序员来说是不友好的,因为他们需要花费额外的精力去了解第三方库中提供的所有组件,并且手动地配置它们。这增加了出错的风险,也降低了开发的效率。
依赖中有哪些Bean,使用时需要配置哪些bean,第三方依赖最清楚。那能否由第三方依赖来做这件事呢?
通常情况下,第三方依赖会提供一个专门的注解,以 @EnableXxxx 开头,通过这个注解来帮助使用者将第三方依赖中的相关组件自动配置到Spring应用程序中。这个注解内部可能会使用 @Import 注解来导入需要的类或配置类,从而简化了配置的过程,让程序员不需要手动管理第三方依赖中的Bean。
通过这种方式,第三方依赖可以清楚地告诉使用者需要哪些Bean以及如何配置这些Bean,使得使用者不需要深入了解第三方库的具体细节,从而降低了出错的可能性,提高了开发效率。
第三方依赖提供注解:
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Import(MySelect.class)public @interface EnableConfig {
}
注解中封装 @Import 注解,导入 MySelector.class
在启动类上使用第三方提供的注解:
SpringBoot原理分析
源码阅读
SpringBoot 是如何帮助我们做的呢? ⼀切的起源自SpringBoot的启动类:
定义一个注解 @SpringBootApplication,用于标识 Spring Boot 应用程序的主类。该注解包含了 @SpringBootConfiguration、@EnableAutoConfiguration 和 @ComponentScan 注解,并且提供了一些属性用于配置自动配置和组件扫描。
// 声明一个注解,用于标注 Spring Boot 应用的主类
package org.springframework.boot.autoconfigure;import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Inherited;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import org.springframework.beans.factory.support.BeanNameGenerator;
import org.springframework.boot.SpringBootConfiguration;
import org.springframework.boot.context.TypeExcludeFilter;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.FilterType;
import org.springframework.context.annotation.ComponentScan.Filter;
import org.springframework.core.annotation.AliasFor;@Target({ElementType.TYPE}) // 该注解可以作用于类上
@Retention(RetentionPolicy.RUNTIME) // 注解信息保留到运行时
@Documented // 注解包含在 Javadoc 中
@Inherited // 允许子类继承父类的注解
@SpringBootConfiguration // 该注解标注当前类是 Spring Boot 的配置类
@EnableAutoConfiguration // 启用自动配置
@ComponentScan(excludeFilters = {@Filter(type = FilterType.CUSTOM,classes = {TypeExcludeFilter.class}
), @Filter(type = FilterType.CUSTOM,classes = {AutoConfigurationExcludeFilter.class}
)}
)
public @interface SpringBootApplication {@AliasFor(annotation = EnableAutoConfiguration.class)Class<?>[] exclude() default {}; // 排除自动配置的类@AliasFor(annotation = EnableAutoConfiguration.class)String[] excludeName() default {}; // 排除自动配置的类的名称@AliasFor(annotation = ComponentScan.class,attribute = "basePackages")String[] scanBasePackages() default {}; // 扫描的基础包路径@AliasFor(annotation = ComponentScan.class,attribute = "basePackageClasses")Class<?>[] scanBasePackageClasses() default {}; // 扫描的基础包路径下的类@AliasFor(annotation = ComponentScan.class,attribute = "nameGenerator")Class<? extends BeanNameGenerator> nameGenerator() default BeanNameGenerator.class; // 生成 Bean 名称的策略类,默认为 BeanNameGenerator@AliasFor(annotation = Configuration.class)boolean proxyBeanMethods() default true; // 是否启用代理 Bean 方法,默认为 true
}
@SpringBootApplication 是一个组合注解,注解中包含了:
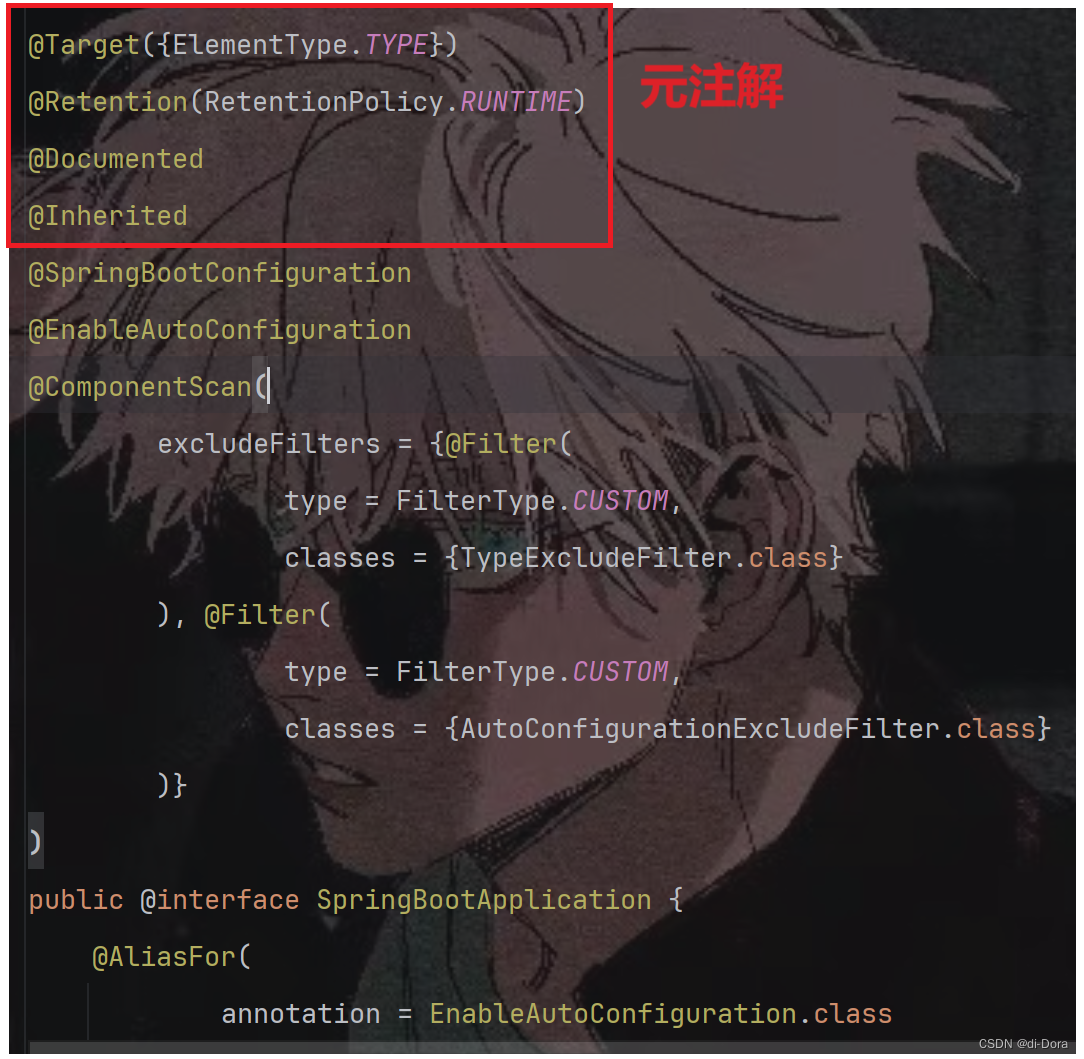
1、元注解
元注解是一种特殊类型的注解,用于对其他注解进行注解。在Java开发工具包(JDK)中,有四个标准的元注解,也称为meta-annotation,分别是@Target、@Retention、@Documented和@Inherited。
-
@Target:用于描述被修饰的注解可以应用的范围。这意味着它指定了注解可以放置在哪些元素上,例如类、方法、字段等。通过指定不同的ElementType参数,可以限制注解的使用范围,从而确保注解的正确使用。
-
@Retention:用于描述注解被保留的时间范围。这决定了注解的生命周期,即它在什么时候会被丢弃。有三种保留策略:
- RetentionPolicy.SOURCE:编译器将会丢弃该注解,它不会包含在编译后的类文件中。
- RetentionPolicy.CLASS:注解将会被包含在编译后的类文件中,但在运行时不可获取。
- RetentionPolicy.RUNTIME:注解将被包含在类文件中,并且在运行时可以通过反射机制获取到。
-
@Documented:用于描述是否在使用Java文档工具(如javadoc)为类生成文档时保留其注解信息。如果一个注解被@Documented修饰,那么在生成文档时,这个注解会被包含进去,使得开发者能够清晰地了解类的注解信息。
-
@Inherited:使被它修饰的注解具有继承性。如果某个类使用了被@Inherited修饰的注解,则其子类将自动具有该注解。这意味着如果一个类被标注为某个注解,那么它的子类也会继承这个注解,除非子类显式地覆盖了这个注解。这对于定义一些通用的行为或特征并让子类继承这些行为或特征是非常有用的。
2. @SpringBootConfiguration
这段代码定义了一个自定义的注解@SpringBootConfiguration,它实际上是对@Configuration注解的封装,并添加了一些额外的功能。
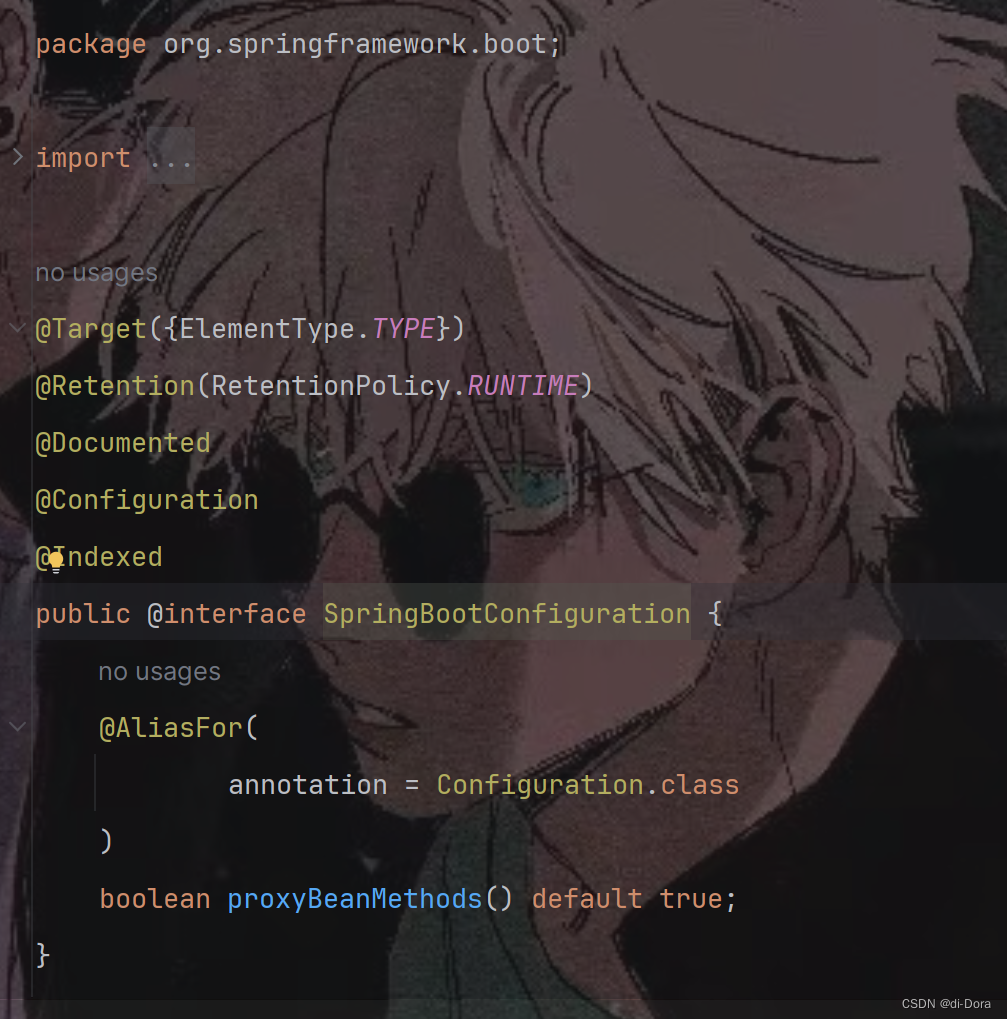
-
@Indexed:这是一个额外的注解,用于加速应用程序启动,但在这段描述中我们不需要关注该注解的作用。
-
@AliasFor(annotation = Configuration.class):这是一个别名注解,指定了该注解的属性proxyBeanMethods与@Configuration注解的proxyBeanMethods属性具有相同的语义,默认为true。这意味着通过@SpringBootConfiguration注解标注的类也会被视为@Configuration,并且proxyBeanMethods属性默认为true。
总之,@SpringBootConfiguration注解是对@Configuration的封装,并且提供了一些额外的功能,使得在Spring Boot应用中更加方便地使用。
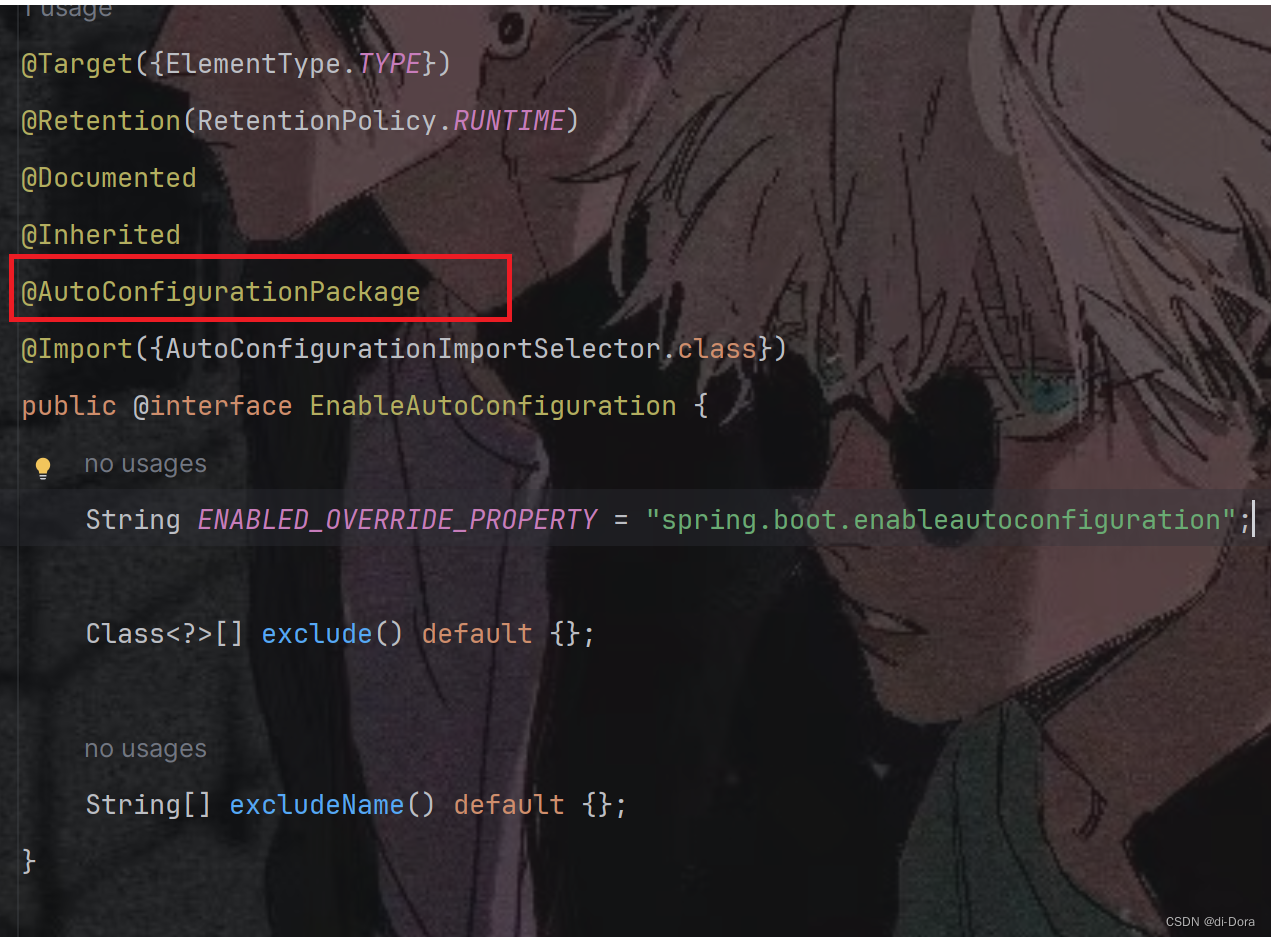
3.@EnableAutoConfiguration (开启自动配置)
@EnableAutoConfiguration注解是Spring Boot中开启自动配置的核心注解,它通过导入自动配置类来简化Spring应用程序的配置。
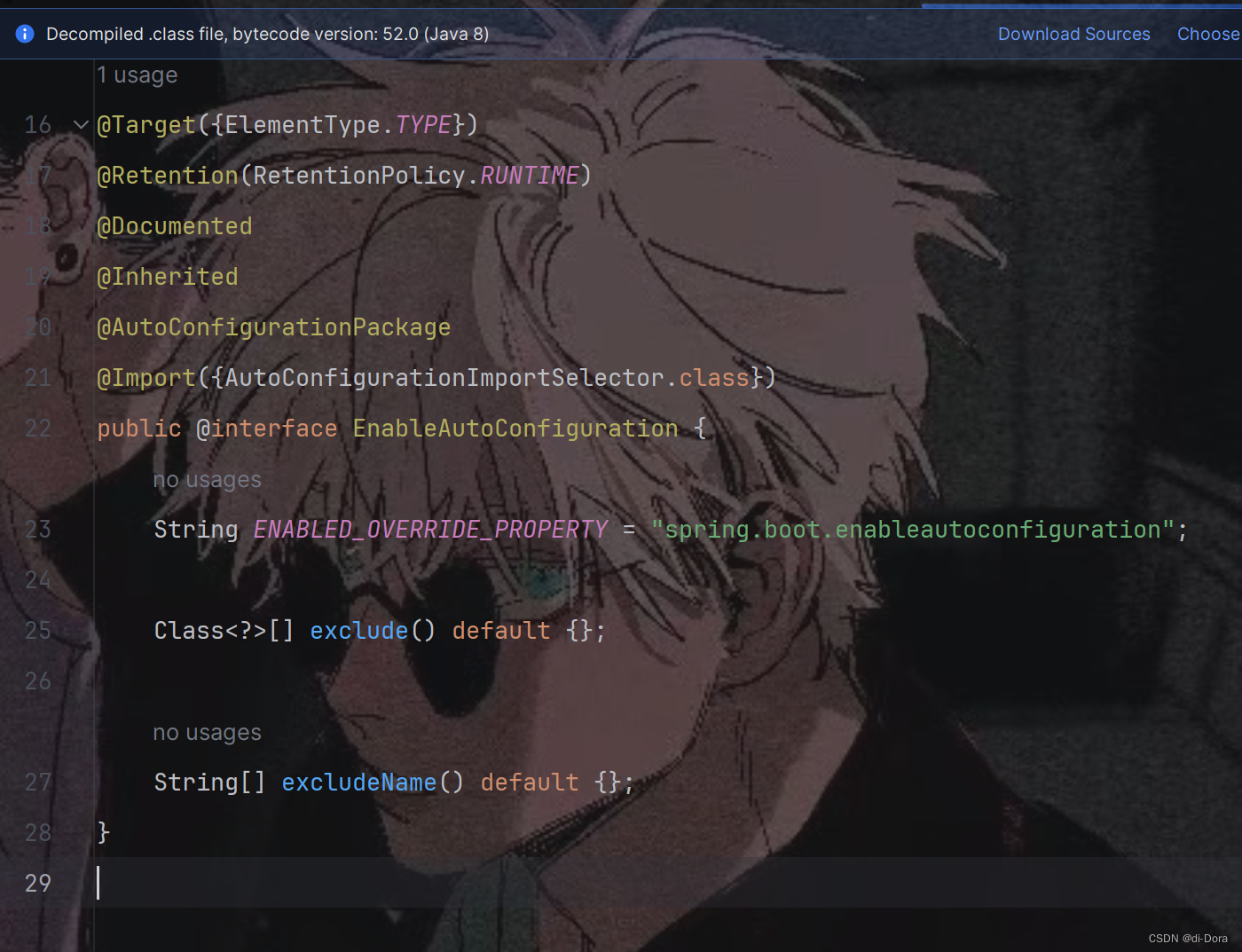
-
@AutoConfigurationPackage:这是一个额外的注解,用于指示Spring Boot应该在包的根目录下搜索@Configuration类,并将它们注册为Bean。
-
@Import({AutoConfigurationImportSelector.class}):用于导入其他配置类。在这里,导入了AutoConfigurationImportSelector类,该类是用于选择自动配置类并将它们导入Spring容器的重要组件。
这个注解非常重要,我们一会儿会详细讲解。
4.@ComponentScan (包扫描)
它用于告诉Spring在哪些包下扫描组件,并且可以通过一些参数进行定制。
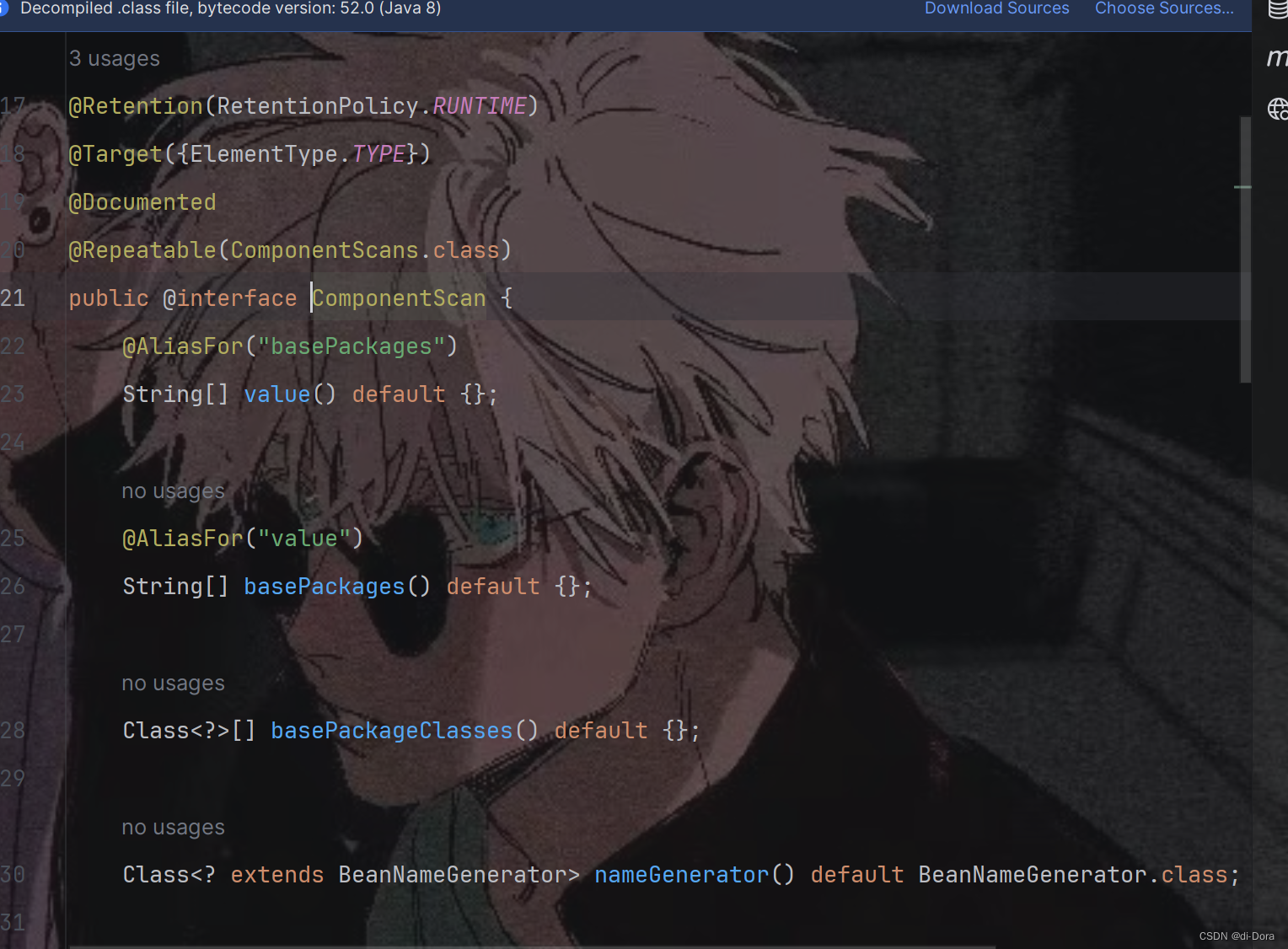
-
@Repeatable(ComponentScans.class):这个注解表明@ComponentScan是可重复的,可以在同一个类上多次使用@ComponentScan注解。
-
value()、basePackages()、basePackageClasses():这些属性用于指定要扫描的特定包。如果没有定义特定的包,则从声明该注解的类的包开始扫描。basePackages和value是别名,可以互相替代。basePackageClasses可以指定一些特定的类,Spring将扫描这些类所在的包。
-
nameGenerator():用于指定生成Bean名称的策略,默认为BeanNameGenerator.class。
-
scopeResolver():用于指定作用域解析器的类,默认为AnnotationScopeMetadataResolver.class。
-
scopedProxy():用于指定作用域代理模式,默认为ScopedProxyMode.DEFAULT。
-
resourcePattern():用于指定要扫描的资源模式,默认为"**/*.class"。
-
useDefaultFilters():用于指定是否使用默认的过滤器,默认为true。
-
includeFilters()、excludeFilters():用于自定义过滤器,通常用于包含或排除一些类、注解等。
-
lazyInit():用于指定是否使用懒加载初始化,默认为false。
@ComponentScan注解的主要作用是告诉Spring在哪些包下扫描组件,以及如何处理这些组件。通过使用该注解,我们可以方便地配置Spring应用程序的组件扫描行为。注意,如果没有参数,默认值为该注解所在类的路径。
@EnableAutoConfiguration 详解
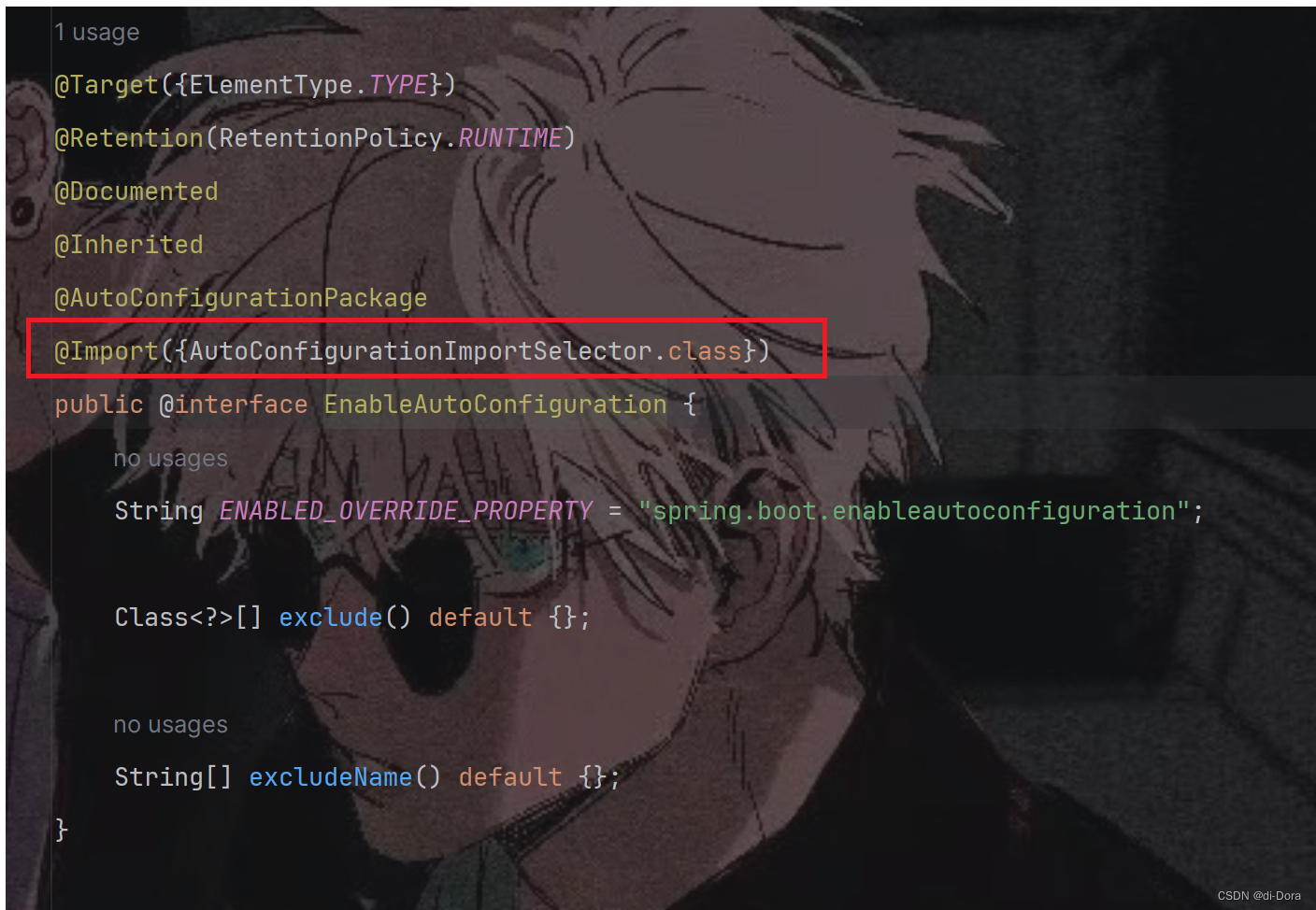
我们来一起看一下 @EnableAutoConfiguration 注解的实现:
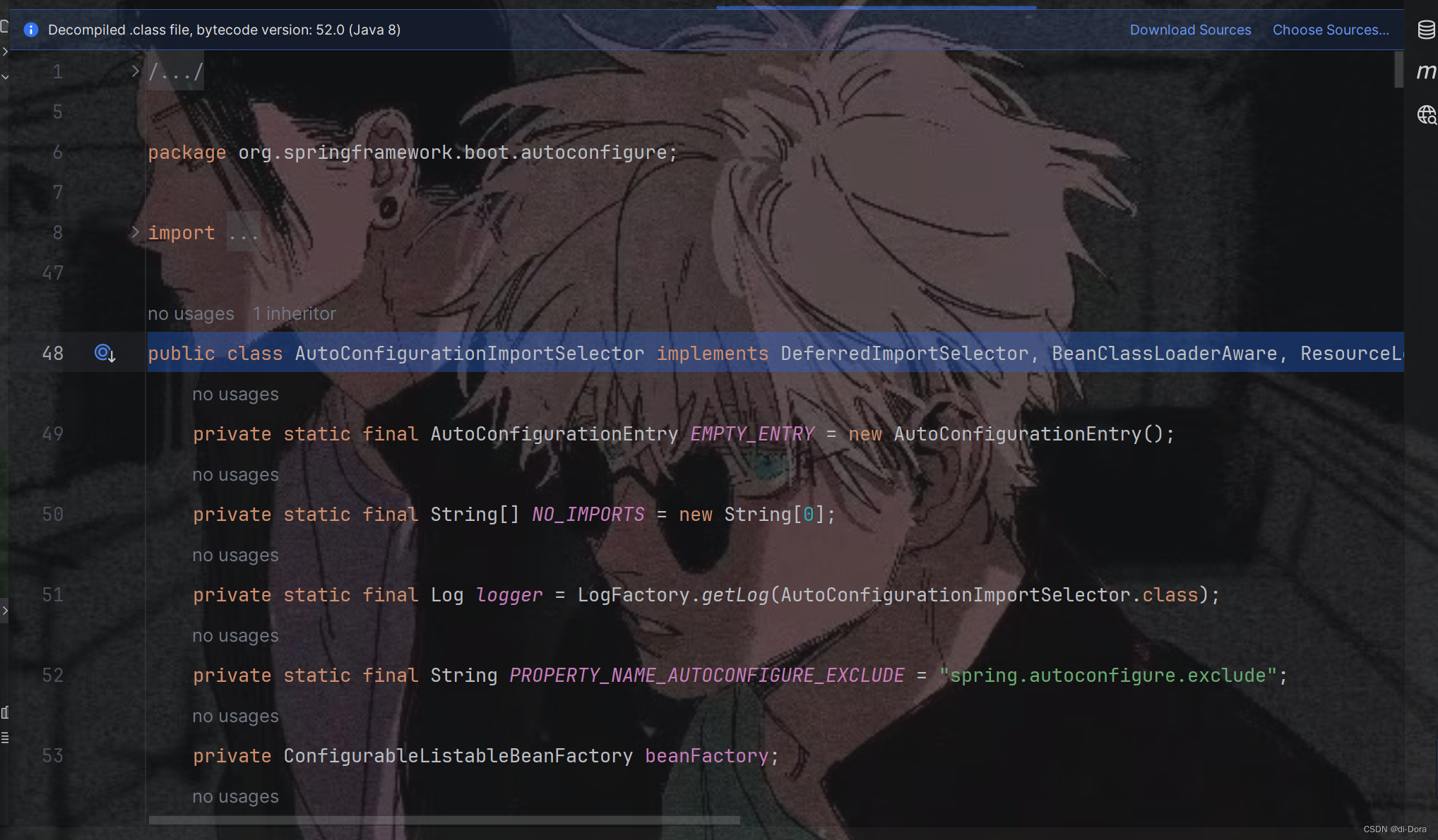
/*** 这个方法根据提供的注解元数据动态选择并导入自动配置类。** @param annotationMetadata 提供有关注解组件上的注解信息的注解元数据。* @return 一个字符串数组,表示所选自动配置类的类名*/
public String[] selectImports(AnnotationMetadata annotationMetadata) {// 根据注解元数据检查是否启用了自动配置if (!this.isEnabled(annotationMetadata)) {// 如果未启用自动配置,则返回一个空的导入数组return NO_IMPORTS;} else {// 如果启用了自动配置,则获取AutoConfigurationEntryAutoConfigurationEntry autoConfigurationEntry = this.getAutoConfigurationEntry(annotationMetadata);// 从AutoConfigurationEntry获取配置,并将其转换为字符串数组return StringUtils.toStringArray(autoConfigurationEntry.getConfigurations());}
}
这个方法负责根据提供的注解元数据动态选择并导入自动配置类。首先,它通过调用 isEnabled 方法检查自动配置是否已启用。如果启用了自动配置,则使用 getAutoConfigurationEntry 方法检索 AutoConfigurationEntry。然后,它从 AutoConfigurationEntry 获取配置,并将其转换为表示所选自动配置类的类名的字符串数组。最后,它返回这个类名数组。
从上面的代码可以发现,主方法就是getAutoConfigurationEntry 方法:
/*** 根据提供的注解元数据获取自动配置条目。** @param annotationMetadata 提供有关注解组件上的注解信息的注解元数据。* @return AutoConfigurationEntry,表示自动配置条目*/
protected AutoConfigurationEntry getAutoConfigurationEntry(AnnotationMetadata annotationMetadata) {// 如果未启用自动配置,则返回一个空的自动配置条目if (!this.isEnabled(annotationMetadata)) {return EMPTY_ENTRY;} else {// 获取注解属性AnnotationAttributes attributes = this.getAttributes(annotationMetadata);// 获取候选配置类列表List<String> configurations = this.getCandidateConfigurations(annotationMetadata, attributes);// 去除重复的配置类configurations = this.removeDuplicates(configurations);// 获取排除的配置类列表Set<String> exclusions = this.getExclusions(annotationMetadata, attributes);// 检查排除的配置类是否存在重复this.checkExcludedClasses(configurations, exclusions);// 从候选配置类中移除排除的配置类configurations.removeAll(exclusions);// 应用配置类过滤器configurations = this.getConfigurationClassFilter().filter(configurations);// 触发自动配置导入事件this.fireAutoConfigurationImportEvents(configurations, exclusions);// 返回新的自动配置条目return new AutoConfigurationEntry(configurations, exclusions);}
}
这个方法根据提供的注解元数据获取自动配置条目。首先,它检查自动配置是否已启用。如果未启用,则返回一个空的自动配置条目。接着,它获取注解的属性,并使用这些属性获取候选的配置类列表。然后,它去除重复的配置类,并获取排除的配置类列表。在检查排除的配置类是否存在重复后,它从候选配置类中移除排除的配置类。接下来,它应用配置类过滤器,将最终的配置类列表返回。最后,它触发自动配置导入事件,并返回新的自动配置条目。
从上面的代码可以发现,主方法就是getCandidateConfigurations 方法:
/*** 获取候选的自动配置类列表。** @param metadata 注解元数据,包含有关注解的信息* @param attributes 注解属性* @return 包含候选自动配置类的列表*/
protected List<String> getCandidateConfigurations(AnnotationMetadata metadata, AnnotationAttributes attributes) {// 从META-INF/spring.factories加载自动配置类列表List<String> configurations = SpringFactoriesLoader.loadFactoryNames(this.getSpringFactoriesLoaderFactoryClass(), this.getBeanClassLoader());// 如果找不到任何自动配置类,则抛出异常Assert.notEmpty(configurations, "No auto configuration classes found in META-INF/spring.factories. If you are using a custom packaging, make sure that file is correct.");return configurations;
}
这个方法用于获取候选的自动配置类列表。它通过SpringFactoriesLoader从META-INF/spring.factories文件中加载自动配置类的名称列表。如果找不到任何自动配置类,则会抛出异常。最后,它返回包含候选自动配置类的列表。
那么我们点开一个看看
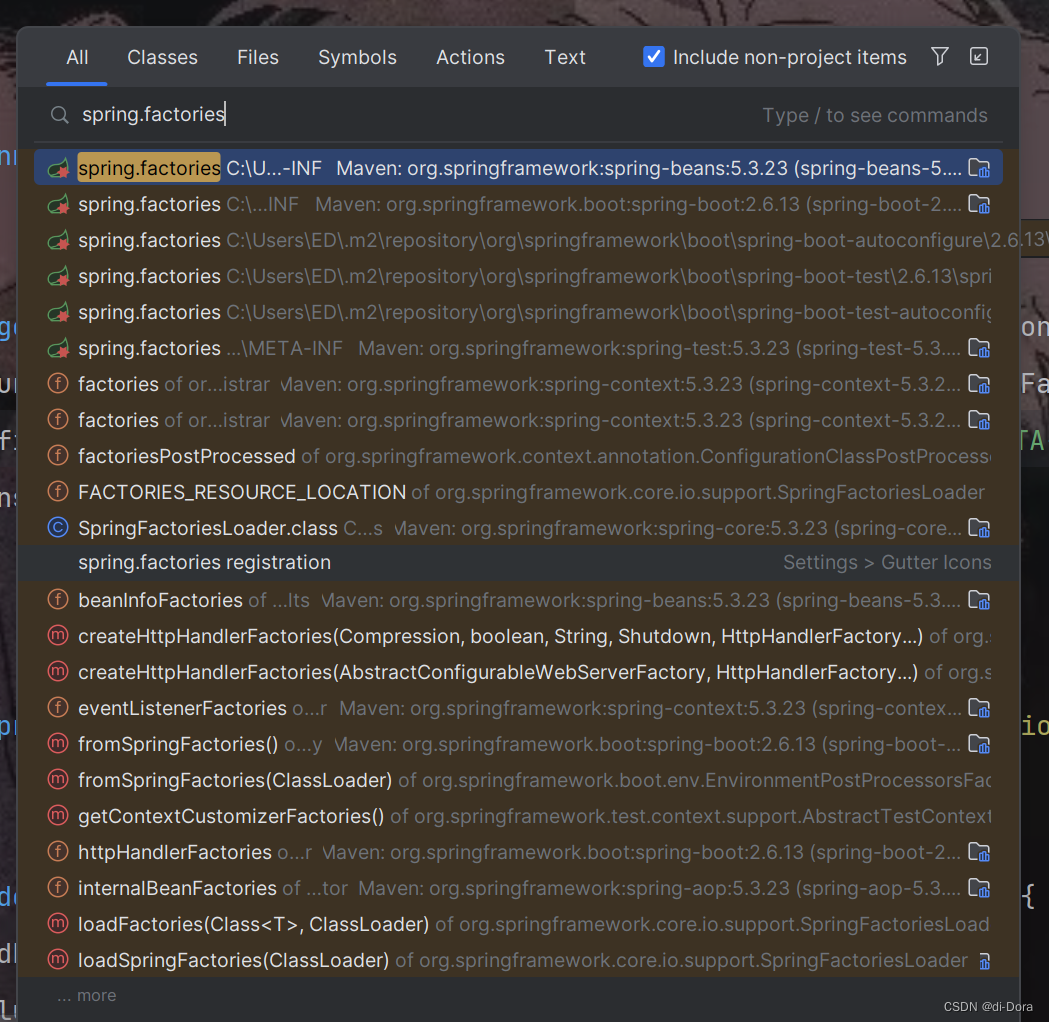

看样子都是一些.class文件:
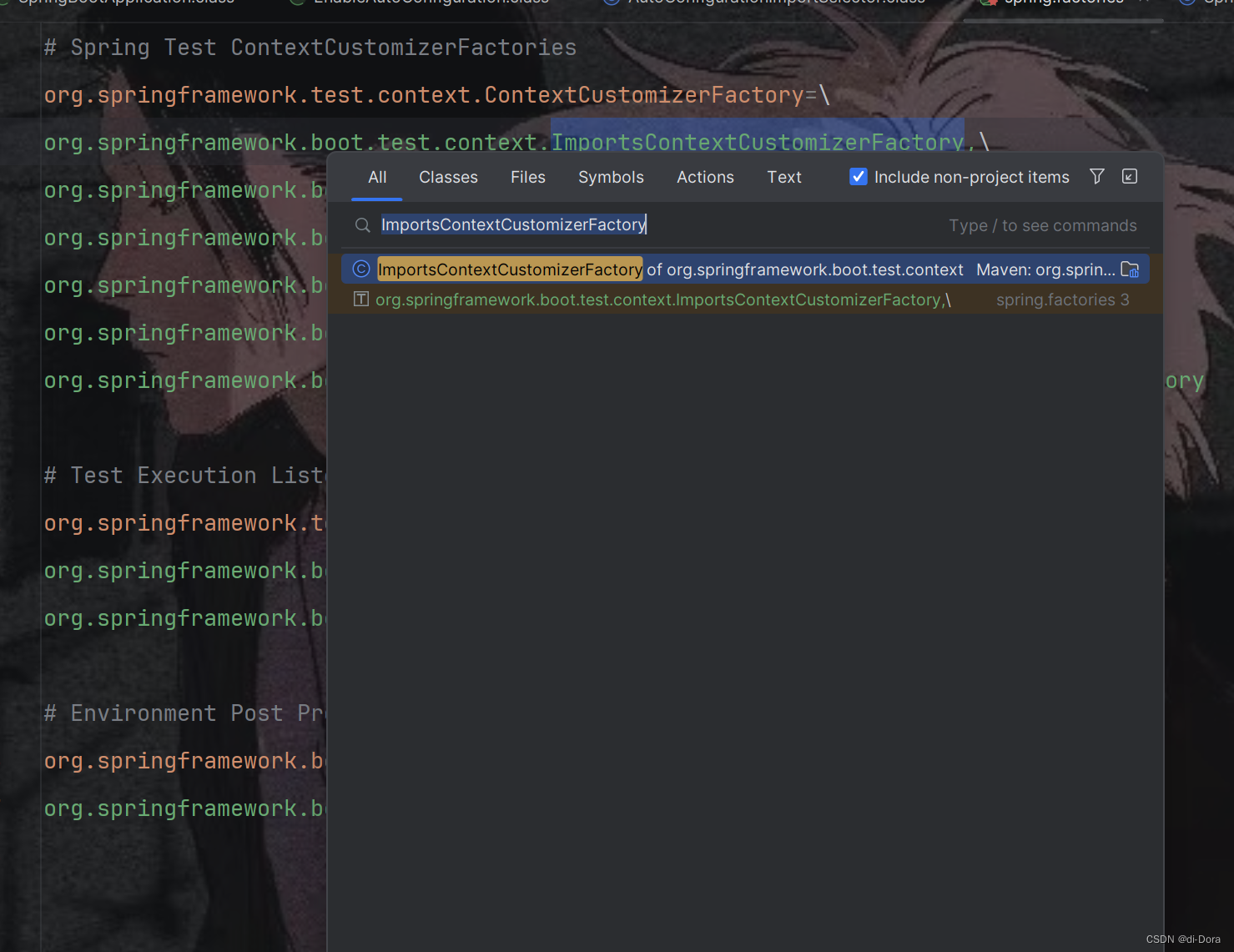
在很多文件里面我们还会发现名字中包含了“Conditional”注解,比如:
/*** 当资源链启用时才生效的条件注解* 用于在运行时根据资源链是否启用来决定是否应该创建一个bean或者配置一个bean*/
@Target({ ElementType.TYPE, ElementType.METHOD })
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Conditional({ OnEnabledResourceChainCondition.class })
public @interface ConditionalOnEnabledResourceChain {
}
它们其实都是来自于 “@Conditional”注解:
/*** 用于在运行时根据条件决定是否应该创建一个bean或者配置一个bean* Spring在处理bean定义时,会考虑是否满足@Conditional注解的条件* 如果满足条件,则会创建或者配置该bean,否则将会跳过该bean*/
@Target({ ElementType.TYPE, ElementType.METHOD })
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Conditional {/*** 返回用于评估条件的类的列表* 如果指定的条件类的所有条件都返回true,则应创建或配置该bean* 否则将跳过bean的创建或配置*/Class<? extends Condition>[] value();
}
综上,@Import({AutoConfigurationImportSelector.class})这一行代码的作用就是通过导入AutoConfigurationImportSelector类来选择自动配置类的注解,用于在配置类中通过导入指定的选择器类来动态地选择自动配置类。
我们还剩下一个注解:
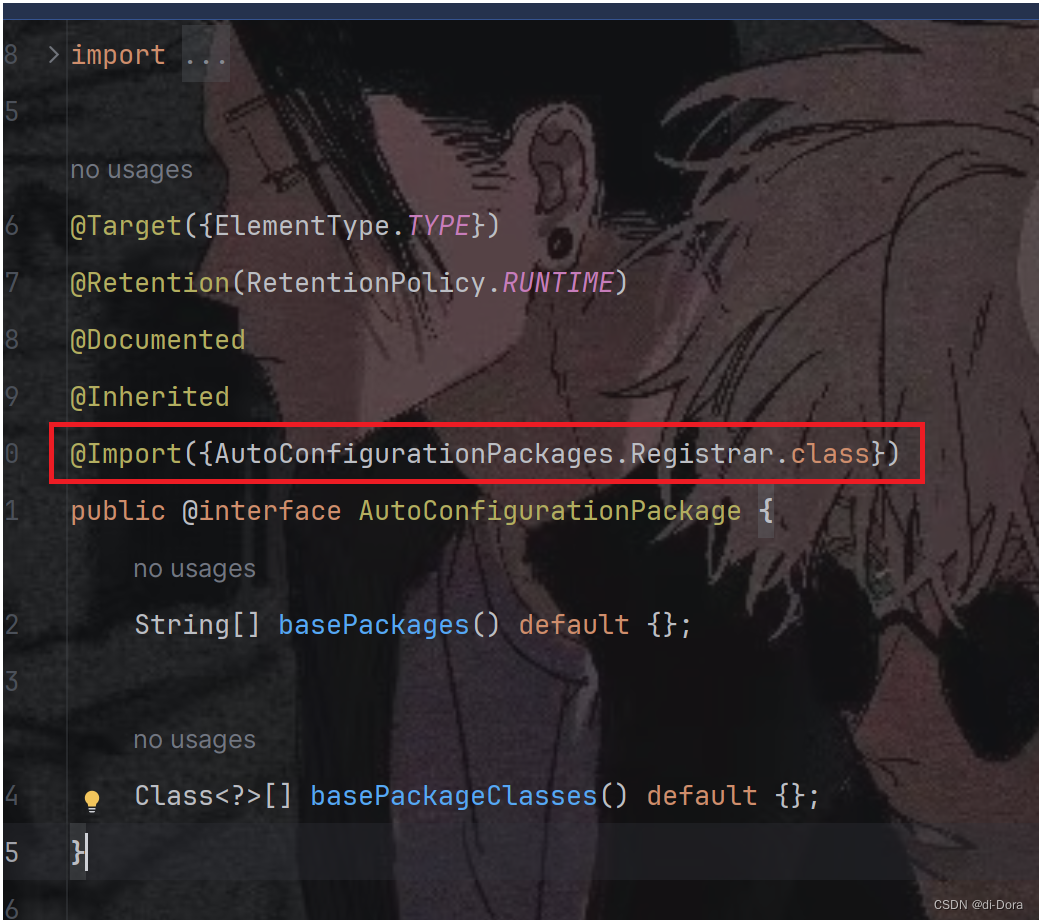
点进去往下扒拉:
/*** 内部静态类Registrar实现了ImportBeanDefinitionRegistrar和DeterminableImports接口* 用于注册Bean定义和确定导入项*/
static class Registrar implements ImportBeanDefinitionRegistrar, DeterminableImports {Registrar() {}/*** 注册Bean定义的方法,将自动配置包注册到注册表中* @param metadata 注解元数据* @param registry Bean定义注册表*/public void registerBeanDefinitions(AnnotationMetadata metadata, BeanDefinitionRegistry registry) {// 使用PackageImports类获取包名,并将其注册到自动配置包中AutoConfigurationPackages.register(registry, (String[])(new PackageImports(metadata)).getPackageNames().toArray(new String[0]));}/*** 确定导入项的方法* @param metadata 注解元数据* @return 包含PackageImports类的集合*/public Set<Object> determineImports(AnnotationMetadata metadata) {return Collections.singleton(new PackageImports(metadata));}
}
这段代码的目的是将特定的包名注册到Spring Boot的自动配置包中,以便Spring能够自动扫描这些包中的类,并将它们实例化为Bean,以供应用程序使用。
具体来说:
- PackageImports(metadata):这行代码创建了一个PackageImports对象,该对象从传入的metadata中获取了与注解相关的信息,然后通过这些信息确定了需要注册到自动配置包的包名。
- new PackageImports(metadata).getPackageNames():这部分代码调用了PackageImports对象的getPackageNames()方法,以获取到需要注册到自动配置包中的包名集合。
- .toArray(new String[0]):将获取到的包名集合转换为数组。
- AutoConfigurationPackages.register(registry, ...):这一行代码调用了AutoConfigurationPackages类的register方法,该方法接受一个BeanDefinitionRegistry对象和一个包名数组作为参数。在Spring Boot内部,AutoConfigurationPackages类负责管理自动配置包,并将注册的包名添加到自动配置包中。这样一来,Spring在启动时就会扫描这些包,寻找带有特定注解的类,并将它们实例化为Bean。
综上所述,我们可以来总结一下:
当我们使用@EnableAutoConfiguration注解时,它实际上是启动了Spring Boot的自动配置功能,其实现原理涉及几个关键部分:
-
@Import({AutoConfigurationImportSelector.class}):
通过@Import注解,导入了实现了ImportSelector接口的AutoConfigurationImportSelector类。ImportSelector接口的实现类可以根据条件动态地选择需要导入的配置类。 -
AutoConfigurationImportSelector:
AutoConfigurationImportSelector类的selectImports()方法负责选择需要导入的配置类。底层调用了getAutoConfigurationEntry()方法,获取可自动配置的配置类信息集合。 -
getAutoConfigurationEntry()方法:
getAutoConfigurationEntry()方法通过调用getCandidateConfigurations()方法获取在配置文件中配置的所有自动配置类的集合。 -
getCandidateConfigurations()方法:
getCandidateConfigurations()方法获取所有基于META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports文件和META-INF/spring.factories文件中配置类的集合。这些配置文件通常包含了许多第三方依赖的自动配置类。 -
动态加载自动配置类:
在加载自动配置类时,并不是将所有的配置全部加载进来,而是通过@Conditional等注解的判断进行动态加载。@Conditional是Spring底层注解,根据不同的条件进行不同的条件判断,如果满足指定的条件,配置类里边的配置才会生效。 -
@AutoConfigurationPackage注解:
@AutoConfigurationPackage注解将启动类所在的包下面所有的组件都扫描注册到Spring容器中。这样,Spring容器就能够扫描到启动类所在包及其子包中的所有组件,并将其注册为Spring Bean。
总的来说,@EnableAutoConfiguration注解启用了Spring Boot的自动配置功能,它通过导入AutoConfigurationImportSelector类和@AutoConfigurationPackage注解,动态加载自动配置类,并根据条件进行判断和加载,最终完成Spring应用程序的自动配置。
SpringBoot ⾃动配置原理的大概流程如下:
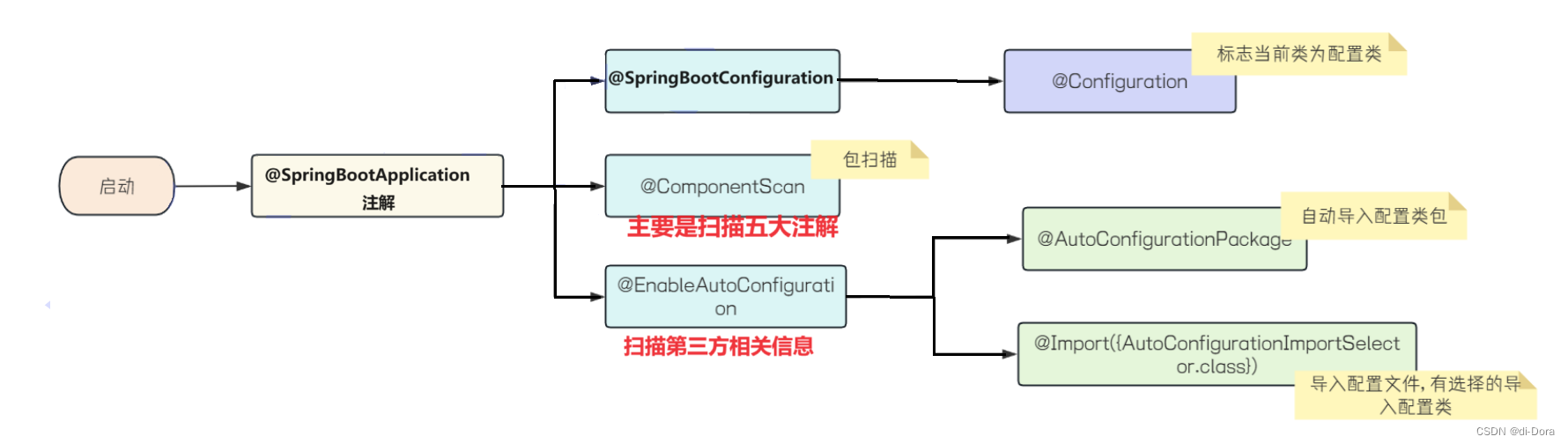
当Spring Boot程序启动时,会自动加载配置文件中所定义的配置类,并通过@Import注解将这些配置类全部加载到Spring的IOC容器中,交由IOC容器管理。这样做的目的是为了简化Spring应用的配置和开发过程,让开发者专注于业务逻辑的实现而不必过多关注框架的配置。
具体来说,Spring Boot的自动配置原理可以概括如下:
- 启动过程:当Spring Boot应用启动时,会自动扫描classpath下的META-INF/spring.factories文件,该文件中列出了所有自动配置类的全限定名。
- 自动配置类:Spring Boot通过这些自动配置类来自动配置应用的各种组件,比如数据源、JPA、Web容器等等。这些自动配置类通过注解@Configuration标识,告诉Spring这是一个配置类。
- 条件装配:自动配置类中的各个Bean的创建是有条件的,Spring Boot利用条件注解(如@ConditionalOnClass、@ConditionalOnMissingBean等)来根据类路径、Bean是否存在等条件来决定是否创建某个Bean。
- 加载配置:Spring Boot会加载应用的配置文件(application.properties或application.yml),并将这些配置信息注入到相应的Bean中。
- IOC容器管理:最终,这些自动配置类中的Bean会被添加到Spring的IOC容器中进行管理。开发者可以通过@Autowired注解或者其他方式来获取并使用这些Bean。
总之,Spring Boot的自动配置机制大大简化了Spring应用的开发和部署流程,我们只需要遵循约定大于配置的原则,即可快速搭建出一个功能完善的Spring应用。


MVC)








)




)


