在ChatGPT火爆全网的一年后,OpenAI公司又一次大显身手:推出了全新的文生视频大模型Sora。直接输入文字提示词,即可直接生成长达60秒的视频。
“现实真的要不存在了。”
马斯克直接大呼:人类彻底完蛋了!

马斯克为什么这么说?
OpenAI科学家Tim Brooks表示,没通过人类预先设定,Sora就自己通过观察大量数据,自然而然学会了关于3D几何形状和一致性的知识。
从本质上说,Sora的技术,就是机器模拟我们世界的一个里程碑。
外媒Decoder直言:OpenAI令人惊叹的视频模型处女作Sora的诞生,感觉就像是GPT-4时刻。

更有人表示,在Sora之中,我切实感受到了AGI。

各大社交平台瞬间被这句话刷屏,Sora掀起了2024年科技圈的第一场风暴。股市动荡,“就业焦虑”卷土重来。
宛如“灭霸”一般的Sora到底是什么?它给大模型带来了什么样的冲击?
“60秒长度”、“多视角镜头”、“模拟现实世界”,这三个词正是Sora给人带来震撼的核心所在。
此前大模型文生视频的最高成就也只是在4s的边缘挣扎徘徊,但 Sora在保证prompt与视觉呈现效果的前提下,生成了长达一分钟的视频。
如下是一段Sora生成的东京街头场景视频,长达60s:
生成该视频的指令为:
A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.
(一位时尚女性走在充满温暖霓虹灯和动画城市标牌的东京街道上。她穿着黑色皮夹克、红色长裙和黑色靴子,拎着黑色钱包。她戴着太阳镜,涂着红色口红。她走路自信又随意。街道潮湿而且有真实的反光效果,在彩色灯光的照射下形成镜面效果。许多行人走来走去。)
这段60s的视频一镜到底,视频中的主要人物呈现效果十分稳定,更意外的是,视频中作为背景辅助的人物视觉效果都很真实。
Open AI官方对这一工作给出的大致解释为:通过一次性地为模型提供多帧预测,完成了当目标主体暂时离开主视野时整体视觉呈现也能稳定不变的目标。

其“真实性”还体现在镜头的丝滑切换上。
此前的大模型文生视频工作基本都是单镜头单生成,而这次Sora生成的视频中创建了多镜头场景、模拟模拟复杂的镜头应用,且准确地保持角色的完美一致性,确保视觉表现的高水准,堪称大模型研发的极大突破。
“模拟现实”当属Sora这次引起火热讨论的一个最重要的突破。
如下是Sora根据“A beautiful silhouette animation shows a wolf howling at the moon, feeling lonely, until it finds its pack.”(一个美丽的剪影动画展示了一只狼对着月亮嚎叫,感到孤独,直到它找到狼群。)这样一段指令生成的视频。
“孤独”这一在现实世界中十分抽象的情绪表达,被AI呈现得惟妙惟肖。你可以说它或许对真实的“孤独”情感还理解不够,但其对于这个指令的答卷足够标准。
颠覆现实,难分真假。只存在于镜花水月中的“元宇宙”概念似乎露出了一缕成型的苗头。
惊人的成果背后必定包含更令人伏地的技术栈。虽然Open AI官方目前公布的技术文档中还缺少一些细节,但也足见其原理和技术的成熟。
在此前大模型的研究中,递归网络、生成对抗网络、自回归Transformer和扩散模型等各种方法都被屡试不鲜。然而,这些工作十分有限,只能生成较短且镜头单一的极小视频。也就是大众所说的“AI味太重”。相比之下,Sora生成的跨越不同持续时间、长达一分钟、且纵横比和分辨率十分高清的图频,到底是怎么完成的呢?
■2.1 采用patches统一训练数据格式
Sora首先通过一个encoder(VAE结构)将视频帧压缩到一个低维度隐式空间(包含时间和空间上的压缩),然后展开成序列的形式送入模型训练,同样的模型预测也是隐式的序列,然后用decoder解码器去解码映射回像素空间形成视频。
有大佬推测,在编码成Spacetime latent patches的过程中Sora可能用到了ViViT的时空编码方式。
■2.2 DiT网络结构
b站up主@ZOMI酱对Sora原理进行了详细剖析:
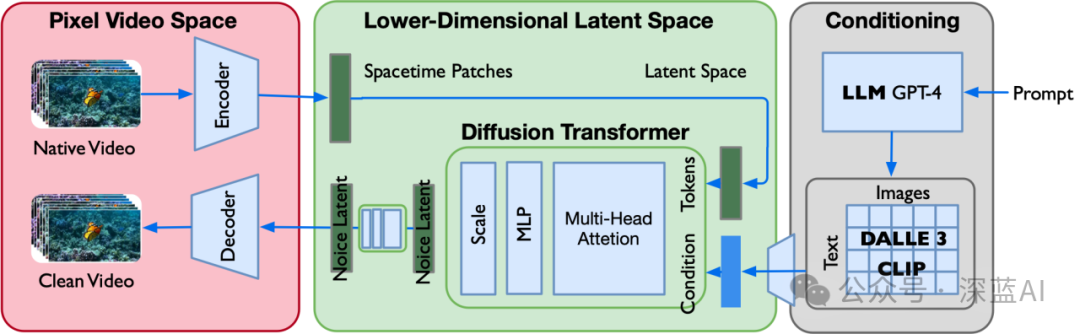
▲图2|Sora模型结构
总的来说,Sora=[ VAE encoder + DiT (DDPM) + VAE decoder + CLIP ],其中的DiT(即Diffusion Transformer)是比较关键的一个模型结构,其核心是用tansformer结构探索新的扩散模型,成功用transformer替换掉stable diffusion中的U-Net主干,来预测噪声实现去噪。这个替换有以下亮点优势:
● 随着数据规模或者训练时间的增强,模型表现的效果越好(大力出奇迹的前置条件);
● 实验表明,模型越大,patches越小,效果越好。
DiT的详细工作流程如下:
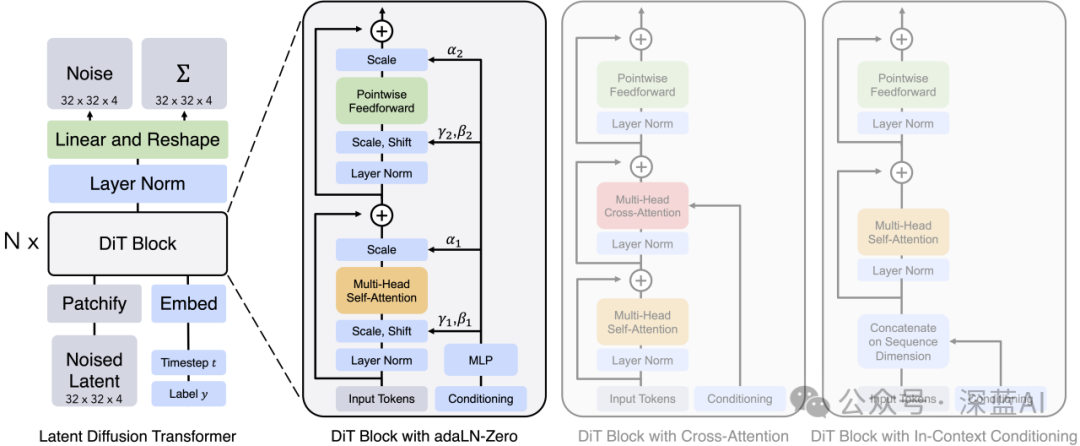
▲图3|DiT模型结构pipeline©️【深蓝AI】
首先将每个 patch 空间表示 Latent 输入到第一层网络,以此将空间输入转换为 tokens 序列。接着将标准基于 ViT 的 Patch 和 Position Embedding 应用于所有输入 token,最后将输入 token 由 Transformer 处理。此外,DiT 还会处理额外信息,例如时间步长、类别标签、文本语义等。
■2.3 世界模型——强大的模拟能力
Sora是否具备世界模型的标准,是大家最为关注的一个话题。根据Open AI目前展示的技术文档得知,Sora能够被衡量为世界模型,是因为其具备以下能力:
●3D一致性:Sora能够生成带有动态摄像头运动的视频。随着摄像头的移动和旋转,人物和场景元素在三维空间中始终保持一致的运动规律。
●较长视频的连贯性和对象持久性:Sora在大部分时间下能够有效地为短期和长期物体间的依赖关系建模。例如,在生成的视频中,人物、动物和物体即使在被遮挡或离开画面后,仍能被准确地保存和呈现。同样地,Sora能够在单个样本中生成同一角色的多个镜头,并在整个视频中保持其外观的一致性。
●与世界互动:Sora有时还能以简单的方式模拟影响世界状态的行为。例如,画家可以在画布上留下新的笔触等。
●模拟数字世界:Sora还能够模拟人工过程。Sora可以同时使用基本策略控制Minecraft中的玩家,同时以高保真度渲染世界及其动态。通过提示Sora提到“Minecraft”的标题,可以激发这些能力。
Sora的出现让影视文艺工作者再一次感觉到了无措,“‘AI’是否生来是要与我们为敌?”
曾经在b站风生水起的千万级剪刀手,在Sora面前似乎成了班门弄斧,PR、Ae工程里上百条的帧文件都抵不上一句简单的指令。未来好莱坞的星光大道是否都要为AI让步?
但即便是再有创世意义的成果,在没有大量被使用之前,都有着明确不可忽视的局限性。伴随老生常谈的“取代恐慌”,被人们说了千百遍的“是否真的理解了真实人类世界的规律”也是Sora这次卷面上的空白。
谷歌AI研究员及Keras创始人François Chollet从独特的角度深入分析了Sora模型。他认为,尽管Sora模型融合了物理模型,但模型的准确性和在新环境下的泛化能力才是决定其应用范围的核心因素。Sora并不是完美的,它可能难以准确模拟复杂场景的物理特性,并且可能无法理解因果关系的具体实例。例如,一个人可能会咬一口饼干,但饼干可能没有咬痕。同时,该模型还可能混淆提示的空间细节,例如,左右混淆,并且可能难以精确描述随时间推移发生的事件,例如遵循特定的相机轨迹。
但我们不能否认,Sora所展示的人工智能在理解真实世界场景并与之互动的能力,是朝着实现通用人工智能(AGI)的重要一步。
正如,Runway公司CEO克里斯托瓦尔·巴伦苏埃拉在X平台上发布的简单推文:“Game On(游戏开始了)。”

游戏已经开始,你我都是玩家。虽然Sora目前存在许多局限性,且谷歌、Meta、Runway、百度、字节跳动等国内外公司都尚未推出可与其相争的对手,但借着这一风口,拨开迷障,无论是不让 Sora等一众大模型取代自己,还是借AI之势,找到属于我们的路才是首要之事。
在 Sora 及其技术报告推出后,我们看到了长达 60 秒,高清晰度且画面可控、能多角度切换的高水平效果。在背后的技术上,研究人员训练了一个基于 Diffusion Transformer(DiT)思路的新模型,其中的 Transformer 架构利用对视频和图像潜在代码的时空 patch 进行操作。
正如华为诺亚方舟实验室首席科学家刘群博士所言,Sora 展现了生成式模型的潜力(特别是多模态生成方面)显然还很大。加入预测模块是正确的方向。至于未来发展,还有很多需要我们探索,现在还没有像 Transformer 之于 NLP 领域那样的统一方法。
想要探求未来的路怎么走,我们或许可以先思考一下之前的路是怎么走过的。那么,Sora 是如何被 OpenAI 发掘出来的?
从 OpenAI 的技术报告末尾可知,相比去年 GPT-4 长篇幅的作者名单,Sora 的作者团队更简洁一些,需要点明的仅有 13 位成员:
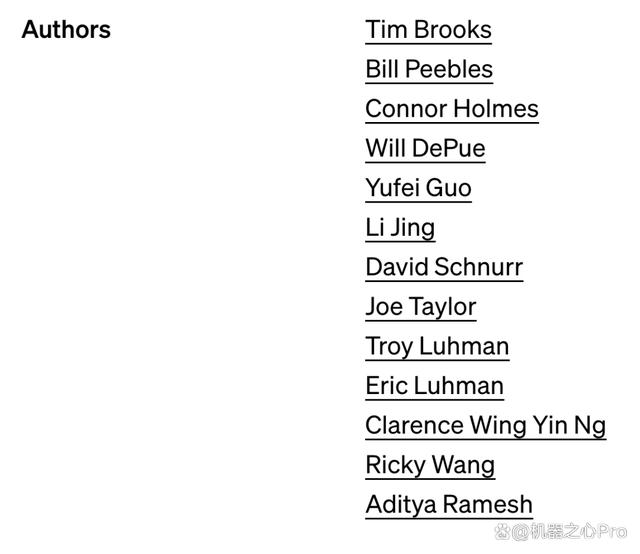
这些参与者中,已知的核心成员包括研发负责人 Tim Brooks、William Peebles、系统负责人 Connor Holmes 等。这些成员的信息也成为了众人关注的焦点。
比如,Sora 的共同领导者 Tim Brooks,博士毕业于 UC Berkeley 的「伯克利人工智能研究所」BAIR,导师为 Alyosha Efros。

在博士就读期间,他曾提出了 InstructPix2Pix,他还曾在谷歌从事为 Pixel 手机摄像头提供 AI 算法的工作,并在英伟达研究过视频生成模型。
另一位共同领导者 William (Bill) Peebles 也来自于 UC Berkeley,他在 2023 年刚刚获得博士学位,同样也是 Alyosha Efros 的学生。在本科时,Peebles 就读于麻省理工,师从 Antonio Torralba。

值得注意的是,Peebles 等人的一篇论文被认为是这次 Sora 背后的重要技术基础之一。
论文《Scalable diffusion models with transformers》,一看名字就和 Sora 的理念很有关联,该论文入选了计算机视觉顶会 ICCV 2023。

论文链接:https://arxiv.org/abs/2212.09748
不过,这项研究在发表的过程还遇到了一些坎坷。上周五 Sora 发布时,图灵奖获得者、Meta 首席科学家 Yann LeCun 第一时间发推表示:该研究是我的同事谢赛宁和前学生 William Peebles 的贡献,不过因为「缺乏创新」,先被 CVPR 2023 拒绝,后来被 ICCV 2023 接收。
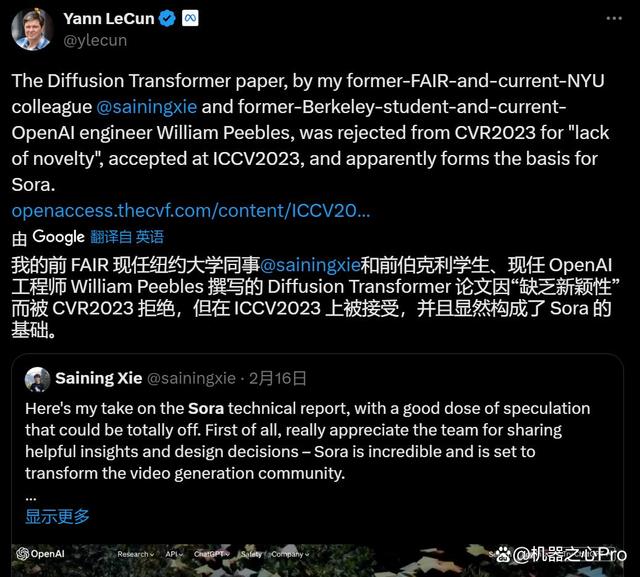
具体来说,这篇论文提出了一种基于 transformer 架构的新型扩散模型即 DiT。在该研究中,研究者训练了潜在扩散模型,用对潜在 patch 进行操作的 Transformer 替换常用的 U-Net 主干网络。他们通过以 Gflops 衡量的前向传递复杂度来分析扩散 Transformer (DiT) 的可扩展性。
研究者发现,通过增加 Transformer 深度 / 宽度或增加输入 token 数量,具有较高 Gflops 的 DiT 始终具有较低的 FID。除了良好的可扩展性之外,DiT-XL/2 模型在 class-conditional ImageNet 512×512 和 256×256 基准上的性能优于所有先前的扩散模型,在后者上实现了 2.27 的 FID SOTA 数据。
目前这篇论文的引用量仅有 191。同时可以看到,William (Bill) Peebles 所有研究中引用量最高的是一篇名为《GAN 无法生成什么》的论文:
当然,论文的作者之一,前 FAIR 研究科学家、现纽约大学助理教授谢赛宁否认了自己与 Sora 的直接关系。毕竟 Meta 与 OpenAI 互为竞争对手。
Sora 成功的背后,还有哪些重要技术?
除此之外,Sora 的成功,还有一系列近期业界、学界的计算机视觉、自然语言处理的技术进展作为支撑。
简单浏览一遍参考文献清单,我们发现,这些研究出自谷歌、Meta、微软、斯坦福、MIT、UC 伯克利、Runway 等多个机构,其中不乏华人学者的成果。
归根结底,Sora 今天的成就源自于整个 AI 社区多年来的求索。









)
:得供应链得天下不是空话。)








)
)