8. BBDM: Image-to-Image Translation with Brownian Bridge Diffusion Models
本文提出一种基于布朗桥(Brownian Bridge)的扩散模型用于图像到图像的转换。图像到图像转换的目标是将源域 A A A中的图像 I A I_A IA,映射到目标域 B B B中得到图像 I B I_B IB。在一般的扩散模型中(如DDPM),是从目标域 B B B中采集样本作为起点 x 0 x_0 x0对其进行扩散,得到纯噪声 x T x_T xT;然后,再从纯噪声中采样进行反向去噪,生成目标图像 x 0 {x}_0 x0。为了实现图像到图像的转换,一般会将参考图像作为条件 y y y,引入到生成过程中,噪声估计网络 ϵ θ \epsilon_{\theta} ϵθ同时根据前一步的结果 x t x_t xt,时刻 t t t和条件 y y y来估计噪声,进而得到新的去噪结果 x t − 1 x_{t-1} xt−1,如下图A所示。
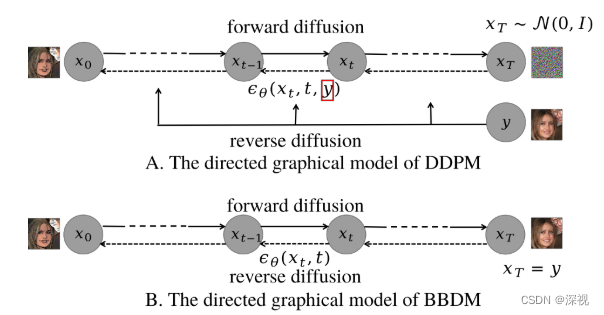
不同于一般的扩散模型,其扩散过程只依赖于起始点 x 0 x_0 x0,布朗桥扩散过程同时依赖起点 x 0 x_0 x0和终点 x T x_T xT,其数学表达如下 p ( x t ∣ x 0 , x T ) = N ( ( 1 − t T ) x 0 + t T x T , t ( T − t ) T I ) (8-1) p\left(\boldsymbol{x}_{t} \mid \boldsymbol{x}_{0}, \boldsymbol{x}_{T}\right)=\mathcal{N}\left(\left(1-\frac{t}{T}\right) \boldsymbol{x}_{0}+\frac{t}{T} \boldsymbol{x}_{T}, \frac{t(T-t)}{T} \boldsymbol{I}\right)\tag{8-1} p(xt∣x0,xT)=N((1−Tt)x0+TtxT,Tt(T−t)I)(8-1)基于此,作者将条件 y y y取代纯噪声作为终点 x T x_T xT,然后从条件 y y y开始进行反向去噪得到目标图像 x 0 {x}_0 x0。值得注意的是,在生成过程中,条件 y y y只作为起点,而不作为噪声估计网络 ϵ θ \epsilon_{\theta} ϵθ的条件,如上图B所示。
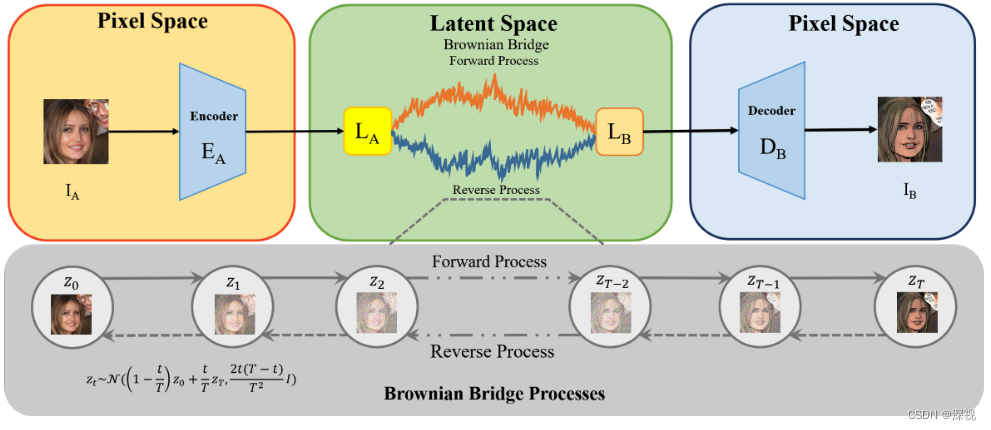
为了提升学习的效率和泛化能力,作者在浅层空间中完成扩散和重建过程,而不是在图像空间中,作者先利用VQGAN的编码器将图像 I A I_A IA映射到潜在空间中 L A L_A LA,经过扩散和重建后得到目标域的潜在特征 L A → B L_{A\rightarrow B} LA→B,最后再利用VQGAN的解码器恢复得到图像 I A → B I_{A\rightarrow B} IA→B。
这篇文章我读着很迷惑,从源域转换到目标域,那么根据上图的表示源域应该是真实图片,目标域是漫画图像,那么所谓的条件也就是参考图像 y y y应该是来自于源域啊。为什么文章中又说从目标域 B B B中采样得到 y y y呢?而且前文一直在讲,把 y y y作为前向扩散过程的终点和反向去噪过程的起点,那为什么上图灰色区域中前向扩散的终点是目标域的图像呢?不知道是我自己的理解问题,还是作者本身的写作有误。下文会按照我自己的理解来写,可能会与原文有一点点微弱的出入。
分别从源域 A A A和目标域 B B B中采集成对的样本 ( y , x ) (y,x) (y,x),经过VQGAN的编码器处理后得到对应的特征向量 y , x \boldsymbol{y,x} y,x,则布朗桥前向扩散过程可写为 q B B ( x t ∣ x 0 , y ) = N ( x t ; ( 1 − m t ) x 0 + m t y , δ t I ) (8-2) q_{B B}\left(\boldsymbol{x}_{t} \mid \boldsymbol{x}_{0}, \boldsymbol{y}\right)=\mathcal{N}\left(\boldsymbol{x}_{t} ;\left(1-m_{t}\right) \boldsymbol{x}_{0}+m_{t} \boldsymbol{y}, \delta_{t} \boldsymbol{I}\right)\tag{8-2} qBB(xt∣x0,y)=N(xt;(1−mt)x0+mty,δtI)(8-2)其中 x 0 = x , m t = t T \boldsymbol{x}_{0}=\boldsymbol{x}, \quad m_{t}=\frac{t}{T} x0=x,mt=Tt T T T表示扩散过程的总步数,方差 δ t \delta_t δt定义为 δ t = 2 s ( m t − m t 2 ) (8-3) \delta_{t}=2 s\left(m_{t}-m_{t}^{2}\right)\tag{8-3} δt=2s(mt−mt2)(8-3)其中 s s s作为一个放缩系数,用于控制采样的多样性,默认值为1。这样的设置,保证了当 t = 0 t=0 t=0和 t = T t=T t=T时, δ t \delta_t δt都为0,而 x t x_t xt分别为 x 0 x_0 x0和 y y y,满足了前文所述的扩散的起点和终点。扩散过程中单步的转移公式如下 q B B ( x t ∣ x t − 1 , y ) = N ( x t ; 1 − m t 1 − m t − 1 x t − 1 + ( m t − 1 − m t 1 − m t − 1 m t − 1 ) y , δ t ∣ t − 1 I ) (8-4) q_{B B}\left(\boldsymbol{x}_{t} \mid \boldsymbol{x}_{t-1}, \boldsymbol{y}\right)=\mathcal{N}\left(\boldsymbol{x}_{t} ; \frac{1-m_{t}}{1-m_{t-1}} \boldsymbol{x}_{t-1}+\left(m_{t}-\frac{1-m_{t}}{1-m_{t-1}} m_{t-1}\right) \boldsymbol{y}, \delta_{t \mid t-1} \boldsymbol{I}\right) \tag{8-4} qBB(xt∣xt−1,y)=N(xt;1−mt−11−mtxt−1+(mt−1−mt−11−mtmt−1)y,δt∣t−1I)(8-4)其中 δ t ∣ t − 1 = δ t − δ t − 1 ( 1 − m t ) 2 ( 1 − m t − 1 ) 2 (8-5) \delta_{t \mid t-1}=\delta_{t}-\delta_{t-1} \frac{\left(1-m_{t}\right)^{2}}{\left(1-m_{t-1}\right)^{2}}\tag{8-5} δt∣t−1=δt−δt−1(1−mt−1)2(1−mt)2(8-5)
经过前向扩散过程,我们将目标域的图像 x 0 x_0 x0映射到源域中的 x T = y x_T=y xT=y,在接下来的反向去噪过程中,我们将从 y y y出发逐步去噪生成一个新的目标域图像 x 0 {x}_0 x0,单步的去噪过程如下 p θ ( x t − 1 ∣ x t , y ) = N ( x t − 1 ; μ θ ( x t , t ) , δ ~ t I ) (8-6) p_{\theta}\left(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_{t}, \boldsymbol{y}\right)=\mathcal{N}\left(\boldsymbol{x}_{t-1} ; \boldsymbol{\mu}_{\theta}\left(\boldsymbol{x}_{t}, t\right), \tilde{\delta}_{t} \boldsymbol{I}\right)\tag{8-6} pθ(xt−1∣xt,y)=N(xt−1;μθ(xt,t),δ~tI)(8-6)其中均值 μ θ ( x t , t ) \boldsymbol{\mu}_{\theta}\left(\boldsymbol{x}_{t}, t\right) μθ(xt,t)是由一个神经网络根据 x t , t \boldsymbol{x}_{t}, t xt,t估计得到的,而方差 δ ~ t \tilde{\delta}_{t} δ~t则是一个无需学习的仅与 t t t有关的变量。那么下面的任务就是如何训练一个网络来估计均值 μ θ ( x t , t ) \boldsymbol{\mu}_{\theta}\left(\boldsymbol{x}_{t}, t\right) μθ(xt,t)了。与DDPM类似,作者也是给出一个了可变分下界的目标函数 E L B O = − E q ( D K L ( q B B ( x T ∣ x 0 , y ) ∥ p ( x T ∣ y ) ) + ∑ t = 2 T D K L ( q B B ( x t − 1 ∣ x t , x 0 , y ) ∥ p θ ( x t − 1 ∣ x t , y ) ) − log p θ ( x 0 ∣ x 1 , y ) ) (8-7) \begin{aligned} E L B O & =-\mathbb{E}_{q}\left(D_{K L}\left(q_{B B}\left(\boldsymbol{x}_{T} \mid \boldsymbol{x}_{0}, \boldsymbol{y}\right) \| p\left(\boldsymbol{x}_{T} \mid \boldsymbol{y}\right)\right)\right. \\ & +\sum_{t=2}^{T} D_{K L}\left(q_{B B}\left(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_{t}, \boldsymbol{x}_{0}, \boldsymbol{y}\right) \| p_{\theta}\left(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_{t}, \boldsymbol{y}\right)\right) \\ & \left.-\log p_{\theta}\left(\boldsymbol{x}_{0} \mid \boldsymbol{x}_{1}, \boldsymbol{y}\right)\right) \end{aligned}\tag{8-7} ELBO=−Eq(DKL(qBB(xT∣x0,y)∥p(xT∣y))+t=2∑TDKL(qBB(xt−1∣xt,x0,y)∥pθ(xt−1∣xt,y))−logpθ(x0∣x1,y))(8-7)其中第一项为常数,可以忽略。重点看第二项, q B B ( x t − 1 ∣ x t , x 0 , y ) q_{B B}\left(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_{t}, \boldsymbol{x}_{0}, \boldsymbol{y}\right) qBB(xt−1∣xt,x0,y)根据贝叶斯理论可得 q B B ( x t − 1 ∣ x t , x 0 , y ) = q B B ( x t ∣ x t − 1 , y ) q B B ( x t − 1 ∣ x 0 , y ) q B B ( x t ∣ x 0 , y ) = N ( x t − 1 ; μ ~ t ( x t , x 0 , y ) , δ ~ t I ) (8-8) \begin{aligned} q_{B B}\left(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_{t}, \boldsymbol{x}_{0}, \boldsymbol{y}\right) & =\frac{q_{B B}\left(\boldsymbol{x}_{t} \mid \boldsymbol{x}_{t-1}, \boldsymbol{y}\right) q_{B B}\left(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_{0}, \boldsymbol{y}\right)}{q_{B B}\left(\boldsymbol{x}_{t} \mid \boldsymbol{x}_{0}, \boldsymbol{y}\right)} \\& =\mathcal{N}\left(\boldsymbol{x}_{t-1} ; \tilde{\boldsymbol{\mu}}_{t}\left(\boldsymbol{x}_{t}, \boldsymbol{x}_{0}, \boldsymbol{y}\right), \tilde{\delta}_{t} \boldsymbol{I}\right) \end{aligned}\tag{8-8} qBB(xt−1∣xt,x0,y)=qBB(xt∣x0,y)qBB(xt∣xt−1,y)qBB(xt−1∣x0,y)=N(xt−1;μ~t(xt,x0,y),δ~tI)(8-8)其中均值 μ ~ t ( x t , x 0 , y ) \tilde{\boldsymbol{\mu}}_{t}\left(\boldsymbol{x}_{t}, \boldsymbol{x}_{0}, \boldsymbol{y}\right) μ~t(xt,x0,y)为 μ ~ t ( x t , x 0 , y ) = δ t − 1 δ t 1 − m t 1 − m t − 1 x t + ( 1 − m t − 1 ) δ t ∣ t − 1 δ t x 0 + ( m t − 1 − m t 1 − m t 1 − m t − 1 δ t − 1 δ t ) y (8-9) \begin{aligned} \tilde{\boldsymbol{\mu}}_{t}\left(\boldsymbol{x}_{t}, \boldsymbol{x}_{0}, \boldsymbol{y}\right) & =\frac{\delta_{t-1}}{\delta_{t}} \frac{1-m_{t}}{1-m_{t-1}} \boldsymbol{x}_{t} \\ & +\left(1-m_{t-1}\right) \frac{\delta_{t \mid t-1}}{\delta_{t}} \boldsymbol{x}_{0} \\ & +\left(m_{t-1}-m_{t} \frac{1-m_{t}}{1-m_{t-1}} \frac{\delta_{t-1}}{\delta_{t}}\right) \boldsymbol{y} \end{aligned}\tag{8-9} μ~t(xt,x0,y)=δtδt−11−mt−11−mtxt+(1−mt−1)δtδt∣t−1x0+(mt−1−mt1−mt−11−mtδtδt−1)y(8-9)方差 δ ~ t \tilde{\delta}_{t} δ~t为 δ ~ t = δ t ∣ t − 1 ⋅ δ t − 1 δ t (8-10) \tilde{\delta}_{t}=\frac{\delta_{t \mid t-1} \cdot \delta_{t-1}}{\delta_{t}}\tag{8-10} δ~t=δtδt∣t−1⋅δt−1(8-10)由于在推理过程中 x 0 x_0 x0是未知的,因此可以根据公式8-2由当前的 x t x_t xt反向估计一个 x ^ 0 \hat{x}_0 x^0,将其带入公式8-9中可得 δ ~ t = δ t ∣ t − 1 ⋅ δ t − 1 δ t μ ~ t ( x t , y ) = c x t x t + c y t y + c ϵ t ( m t ( y − x 0 ) + δ t ϵ ) (8-11) \tilde{\delta}_{t}=\frac{\delta_{t \mid t-1} \cdot \delta_{t-1}}{\delta_{t}}\tilde{\boldsymbol{\mu}}_{t}\left(\boldsymbol{x}_{t}, \boldsymbol{y}\right)=c_{x t} \boldsymbol{x}_{t}+c_{y t} \boldsymbol{y}+c_{\epsilon t}\left(m_{t}\left(\boldsymbol{y}-\boldsymbol{x}_{0}\right)+\sqrt{\delta_{t}} \boldsymbol{\epsilon}\right)\tag{8-11} δ~t=δtδt∣t−1⋅δt−1μ~t(xt,y)=cxtxt+cyty+cϵt(mt(y−x0)+δtϵ)(8-11)其中 c x t = δ t − 1 δ t 1 − m t 1 − m t − 1 + δ t ∣ t − 1 δ t ( 1 − m t − 1 ) c y t = m t − 1 − m t 1 − m t 1 − m t − 1 δ t − 1 δ t c ϵ t = ( 1 − m t − 1 ) δ t ∣ t − 1 δ t (8-12) \begin{array}{l} c_{x t}=\frac{\delta_{t-1}}{\delta_{t}} \frac{1-m_{t}}{1-m_{t-1}}+\frac{\delta_{t \mid t-1}}{\delta_{t}}\left(1-m_{t-1}\right) \\ c_{y t}=m_{t-1}-m_{t} \frac{1-m_{t}}{1-m_{t-1}} \frac{\delta_{t-1}}{\delta_{t}} \\ c_{\epsilon t}=\left(1-m_{t-1}\right) \frac{\delta_{t \mid t-1}}{\delta_{t}} \end{array}\tag{8-12} cxt=δtδt−11−mt−11−mt+δtδt∣t−1(1−mt−1)cyt=mt−1−mt1−mt−11−mtδtδt−1cϵt=(1−mt−1)δtδt∣t−1(8-12)与DDPM中一样,作者不直接预测均值 μ ~ t \tilde{\mu}_t μ~t,而是对其中的噪声 ϵ \epsilon ϵ进行预测。 p θ ( x t − 1 ∣ x t , y ) p_{\theta}\left(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_{t}, \boldsymbol{y}\right) pθ(xt−1∣xt,y)中的均值项 μ θ ( x t , t ) \boldsymbol{\mu}_{\theta}\left(\boldsymbol{x}_{t}, t\right) μθ(xt,t)可以重写为 x t , y \boldsymbol{x}_{t},\boldsymbol{y} xt,y和估计噪声 ϵ θ \epsilon_{\theta} ϵθ的线性组合 μ θ ( x t , y , t ) = c x t x t + c y t y + c ϵ t ϵ θ ( x t , t ) (8-13) \boldsymbol{\mu}_{\boldsymbol{\theta}}\left(\boldsymbol{x}_{t}, \boldsymbol{y}, t\right)=c_{x t} \boldsymbol{x}_{t}+c_{y t} \boldsymbol{y}+c_{\epsilon t} \boldsymbol{\epsilon}_{\theta}\left(\boldsymbol{x}_{t}, t\right)\tag{8-13} μθ(xt,y,t)=cxtxt+cyty+cϵtϵθ(xt,t)(8-13)则目标函数 E L B O ELBO ELBO可以简化为 E x 0 , y , ϵ [ c ϵ t ∥ m t ( y − x 0 ) + δ t ϵ − ϵ θ ( x t , t ) ∥ 2 ] (8-14) \mathbb{E}_{\boldsymbol{x}_{0}, \boldsymbol{y}, \boldsymbol{\epsilon}}\left[c_{\epsilon t}\left\|m_{t}\left(\boldsymbol{y}-\boldsymbol{x}_{0}\right)+\sqrt{\delta_{t}} \boldsymbol{\epsilon}-\boldsymbol{\epsilon}_{\theta}\left(\boldsymbol{x}_{t}, t\right)\right\|^{2}\right]\tag{8-14} Ex0,y,ϵ[cϵt mt(y−x0)+δtϵ−ϵθ(xt,t) 2](8-14)
完整的训练流程如下

经过训练得到噪声估计网络 ϵ θ ( x t , t ) \boldsymbol{\epsilon}_{\theta}\left(\boldsymbol{x}_{t}, t\right) ϵθ(xt,t),就可以从源域中任意采样一个条件输入 y \boldsymbol{y} y作为生成的起点 x T \boldsymbol{x}_T xT,经过反向去噪得到生成结果 x 0 x_0 x0,如下所示

上述的采样过程也可以利用DDIM提出的加速技巧进行加速。整体上而言,BBDM就是将原本扩散过程从图像到噪声的变换,改成了从目标图像到源图像的变换。然后,在反向去噪时,只需给定一个源图像就能据此生成对应目标域中的样本。虽然不用像其他条件扩散模型那样,将条件引入模型中用于训练,但在BBDM的训练过程需要成对的样本,这限制了BBDM在许多情景中的应用。


)


)

![[linux] GPUS=${1:-4} 如果$1为空,则使用其后的默认值](http://pic.xiahunao.cn/[linux] GPUS=${1:-4} 如果$1为空,则使用其后的默认值)
视觉里程计 2)



——服务器三次注册限制以及数据库化角色信息5--角色信息数据库化收尾)
:高级模拟算法真题 ★★★☆☆《公交消费》)


的详细指南)


