目录
一、业务介绍
二、早期架构及痛点
2.1 早期架构
2.2 架构痛点
三、技术选型
四、新的架构及方案
五、搭建经验
5.1 数据建模
5.2 数据开发
5.3 库表设计
5.4 数据管理
5.4.1 监控告警
5.4.2 数据备份与恢复
六、收益总结
七、未来规划
原文大佬这篇Doris腾讯云实时数仓的实战文章整体写的很深入,这里直接摘抄下来用作学习和知识沉淀。
前言
腾讯云数据仓库Doris助力荔枝微课构建了规范的、计算统一的实时数仓平台。目前腾讯云数据仓库Doris已经支撑了荔枝微课内部90%以上的业务场景,整体可达到毫秒级的查询响应,数据时效性完成T+1到分钟级的提升,开发效率更是实现了50%的增长,满足了各业务场景需求,实现将本提效。
一、业务介绍
荔枝微课是一个免费使用的在线教育平台,拥有海量直播视频、录播视频、音频等数据内容。大数据平台旨在集成各种数据源的数据,整合形成数据资产,为业务提供用户全链路生命周期、实时指标分析、标签圈选等分析服务。
二、早期架构及痛点

2.1 早期架构
早期架构选用的是Hadoop生态圈组件,以spark批计算引擎为核心构建了离线数仓架构,基于flink计算引擎进行实时处理。从源端采集到的业务数据和日志数据将分为实时和离线两条链路:在实时部分,业务库数据通过Binlog的方式接入,日志数据使用Flume-Kafka-Sink进行实时采集,利用flink将数据计算写入到kafka和mysql中。在实时数仓内部,遵守数据分层的理论以实现最大程度的数据复用。
在离线部分,利用sqoop和datax对全量和增量业务库中的数据进行定时同步,日志数据通过flume和日志服务进行采集。当不同数据源进入到离线数仓后,首先使用hive on spark进行定时调度处理,接着根据维度建模将数仓分为ods,dwd,dws,ads层,每层数据存储在HDFS和对象存储COS上,最终利用Presto 进行数据即席查询,并通过 Metabase 提供交互式分析服务。同时为了保障数据的一致性,我们会通过离线数据对实时数据进行定期覆盖。
2.2 架构痛点
基于Hadoop的早期架构可以满足我们的初步需求,而面对较为复杂的分析诉求则显得心有余而力不足。再加上近年来,荔枝微课用户体量不断上升,数据量呈指数级上升,为了更好地为业务赋能,提高用户使用体验,业务侧对数据的实时性、可用性、响应速度也提出了更高的要求。在这样的背景下,早期架构暴露的问题也越发明显:
- 组件繁多,维护复杂,运维难度非常高
- 数据处理链路过长,导致查询延迟变高
- 当有新的数据需求时,牵一发而动全身,所需开发周期比较长
- 数据时效性低,只可满足T+1的数据需求,从而也导致数据分析效率低下
三、技术选型
通过对数据规模及早期架构存在的问题进行评估,我们决定引入一款实时数仓来搭建新的数据平台,同时希望新的olap引擎可以具备以下能力:
- 支持Join操作,可满足不同业务用户灵活多变的分析需求
- 支持高并发查询,可满足日常业务的报表分析需求
- 性能强悍,可以在海量数据场景下实现快速响应
- 运维简单,缩减运维人力的投入和成本的支持,实现降本提效
- 统一数仓构建,简化繁琐的大数据技术栈
- 社区活跃,在使用过程中遇到问题,可迅速与社区取得联系
基于以上要求,我们快速定位了Doris 和 ClickHouse 这两款开源 OLAP 引擎 ,这两款引擎都是当下使用较为广泛、口碑不错的产品。在调研中发现,ClickHouse在宽表查询时有着非常出色的性能表现,写入速度快,对于大量的数据更新非常使用;但对于join场景,通常需要额外的调优才能有较好的表现。在大多数业务场景中都需要基于明细数据进行大数据量的join,对比而言,Doris的多表Join能力强悍,高并发能力优异,完全可以满足我们日常的业务报表分析需求。除此之外,Doris可以同时支持实时数据服务、交互数据分析和离线数据处理多种场景,并且支持 Multi Catalog(Multi Catalog:多源数据目录功能,旨在能够更方便对接外部数据目录,以增强Doris的数据湖分析和联邦数据查询能力),可以实现统一的数据门户,这几个特点都是我们核心考虑的几个能力。
同时,我们也了解到腾讯数据仓库这款产品,作为一款支持在线业务和多维分析的实时数仓产品,腾讯云数据仓库 Doris 100% 兼容开源 Apache Doris,整体架构简洁易用,极简运维,弹性伸缩,功能完备,一站式的分析解决方案,满足各种业务数据分析场景,能够助力企业快速构建云上数据分析平台。
在多源数据加工方面, Flink有着优秀的表现满足我们的实时数据加工诉求,我们选择了腾讯云大数据 EMR-Flink。腾讯云EMR是一款基于云原生技术和泛 Hadoop生态开源技术的安全、低成本、高可靠的开源大数据平台,提供了非常丰富的组件选项。而作为云原生大数据产品,腾讯云数据仓库Doris与EMR这两款产品之间能够无缝集成和联动。
基于以上优势,最终选择与腾讯云大数据合作,采用腾讯云数据仓库 Doris+EMR来搭建新的实时数仓架构体系。
四、新的架构及方案
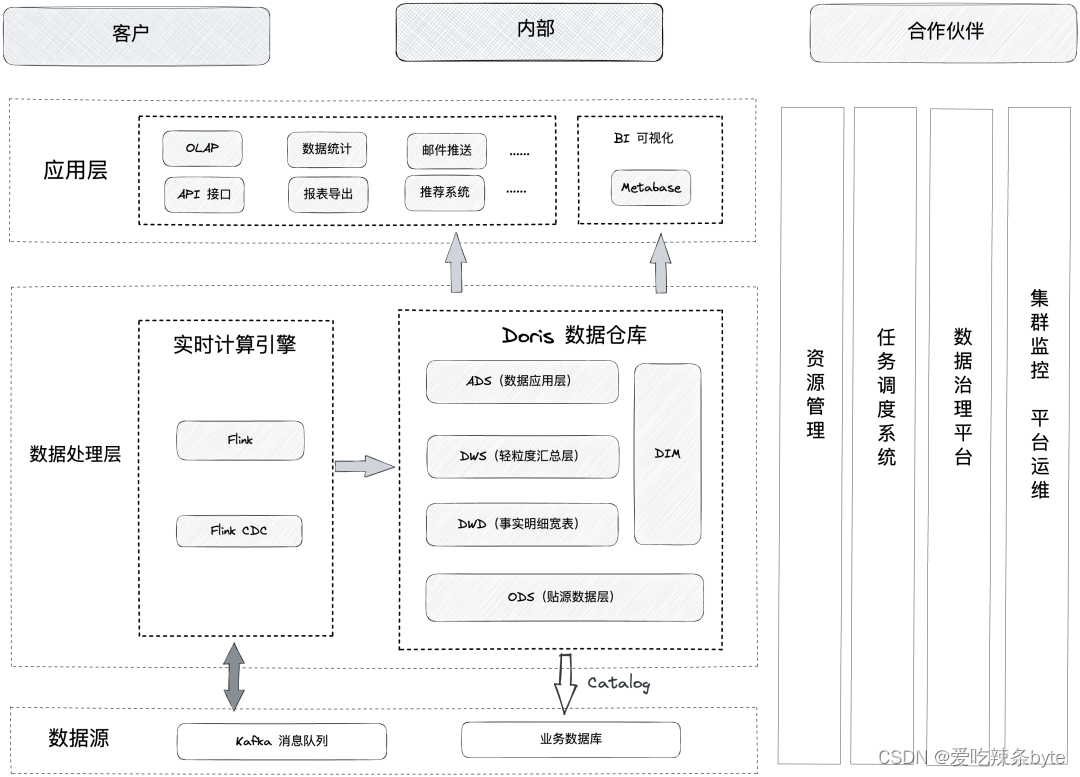
在新的架构中采取腾讯云数据仓库 Doris 和腾讯云EMR-Flink 来构建实时数仓,多种数据源的数据经过Flink CDC或Flink加工处理后,入库到kafka和Doris中,最终由Doris提供统一的查询服务。在数据同步上, 一般通过Flink CDC 将 RDS 数据实时同步到 Doris,通过 Flink 将 Kafka 的日志数据加工处理到 Doris,重要的指标数据一般由flink计算,再经过kafka分层处理写入到Doris中。
- 在存储媒介上,主要使用腾讯云数据仓库 Doris 进行流批数据的统一存储。
- 架构收益:成功构建了规范的、计算统一的实时数仓平台,腾讯云数据仓库 Doris的Multi Catalog功能助力我们统一了不同数据源出口,实现联邦后查询。同时利用外部表插入的方式进行快速同步和修复,真正实现了统一数据门户。
- 数据实时性有效提升,通过Flink+Doris架构,实时性从早期T+1缩短为分钟级别延迟。
- 极大地减少了运维成本,Doris架构简单,只有FE和BE两个进程,不依赖其他系统;另外集群扩缩容非常简单,可实现用户无感知扩容。
- 开发周期从周级别降至天级别,开发周期大幅缩短,开发效率相比之前提升了50%
五、搭建经验
5.1 数据建模
结合腾讯云数据仓库 Doris 的特性,我们对数据仓库进行了建模,建模方式与传统数仓类似:
(1)ods层:ods层日志数据选择duplicate模型的分区表,分区表方便进行设计修复,duplicate模型还可以减少非必要的compaction。ods层业务数据采用unique数据模型(业务库mysql单表数据通过flink cdc实时同步到doris,kafka日志数据经过flink清洗,通过doris的rountine load写入doris做为ods层),distribute by hash key根据具体的业务场景进行选择:
如果考虑机器资源,可选择均匀分布的key,让tablet数据能够均匀分布,使得查询时各BE资源能够充分利用,避免出现木桶效应。如果考虑大表Join性能,可以依据Colocate join特性进行创建,让Join查询更高效。
Doris1.2版本中unique模型开始支持写时合并Merge on Write,进一步提升了Unique模型的查询性能。
(2)DWD层:对于通过Flink将数据进行Join打宽处理分别写入Doris和kafka中的场景,选择使用unique数据模型。
对于高频查询的宽表,选择Doris的aggregate模型,使用replace_if_not_null字段类型,将多个事实单表进行插入,通过Doris的compaction机制可以有效减少flink状态TTL导致的历史数据没有及时更新的问题。
(3)DWS层和AD层:主要采用unique数据模型,dws层按天,月进行分区。除此之外,我们还会利用insert into语句进行5分钟的任务调度和 T+1的任务修复来进行数仓分层,便于需求的快速开发和实时数据修复(离线数据对实时数据进行覆盖,确保两条链路的数据一致性)。对于duplicate模型的数据表,我们会创建rollup的物化视图,通过命中物化视图查询,加快上层表的查询效率。
5.2 数据开发
在荔枝微课业务中,运营人员经常会有调整直播课程信息、修改专栏名称等操作,针对维度快速变化但宽表中维度列没有及时更新的场景,为了能更好地满足业务需求,我们利用 Doris Aggregate 模型 的 REPLACE_IF_NOT_NULL字段特性(聚合函数设置为REPLACE_IF_NOT_NULL即可实现部分列更新的支持)。当课程维度表数据发生变化时,需要查询上层维度(专栏和直播间),对维度表补全后再插入到 Doris 中;当上层维度(专栏和直播间)发生变化时,需要下钻到课程表维度表,补全对应的课程 ID 后再将数据插入到 Doris 中。通过这两种方式可以确保维度表中所有字段的实时更新。
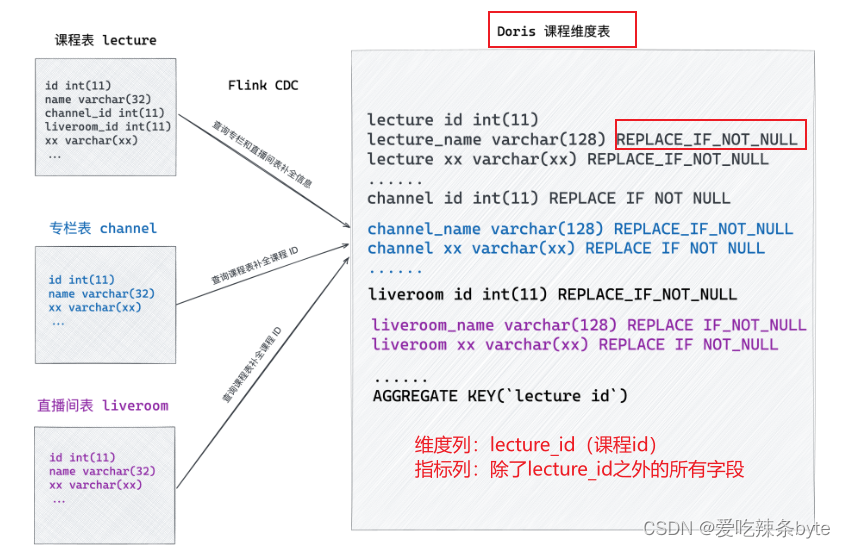
5.3 库表设计
在初期设计阶段,为了更好地利用腾讯云数据仓库 Doris 提供的Colocation Join功能,我们特别设计了事实表的主键,如下图示例:

上图中的业务库中课程表 A 和课程表 B 的关系是A.id=B.lecture_id,为了使用Colocation Join优化,我们会将B表的分桶列设置为lecture_id,即distributed by hash(lecture_id)。在数据量很大的情况下可能会导致数据倾斜,导致各个BE节点的Tablet大小不一致,在高并发查询时可能出现BE机器资源使用不均衡,从而影响查询稳定性,造成资源浪费。
基于以上问题,我们尝试进行调整,并对查询效率和机器资源的占用这两方面进行了评估权衡,最终决定在尽量不影响查询效率的前提下,尽可能提高资源利用率。
在资源利用上,我们在建表时利用colocate_with属性,在不同数量和类型的 Distributed Key 创建不同的 Group,实现机器资源能得以充分利用。
在查询效率上,根据业务场景和需求对前缀索引的字段顺序进行针对性调整,对于必选或高频的查询条件,将字段放在 UNIQUE KEY 前面,根据维度按照从高到低的顺序进行设计。其次我们利用物化视图对字段顺序进行调整,尽可能使用前缀索引进行查询,以加快数据查询 。除此之外,我们进行月、天分区,对明细数据进行分桶,通过合理库表的设计减少 FE元数据的压力。
5.4 数据管理
在数据管理方面,我们进行了以下操作:
5.4.1 监控告警
对于重要的单表,一般通过腾讯云数据仓库Doris来创建外部表,通过数据质量监控来对比业务库数据和Doris数据,进行数据质量稽查告警。
5.4.2 数据备份与恢复
我们会将Doris数据定期导入到HDFS进行备份,避免数据误删除或丢弃的情况发生。例如当因为某些原因导致Flink同步任务失败,无法从Checkpoint进行启动时,我们可以读取最新的数据进行同步,历史缺失数据通过外部表进行修复,使得同步任务快速恢复。
六、收益总结
在新架构中,我们从Hadoop生态完全的迁移到Flink +Doris上,在上层构建不同的数据应用,比如自主报表,自助数据提取,数据大屏,业务预警等,Doris通过应用层接口服务项目统一对外提供API查询,新架构的应用也为我们带来了许多收益,支撑了荔枝微课内部90%以上的业务场景,整体可达到毫秒级的查询响应。
(1)支持千万级甚至是亿级大表关联查询,可实现秒级甚至毫秒级响应。
(2)Doris统一了数据源出口,查询效率显著提升,支持多种数据的联邦查询,降低了多数据查询的复杂度以及数据链路处理成本。
(3)Doris架构简单,极大简化了大数据的架构体系,并高度兼容Mysql的语法,极大降低了开发人员接入成本。
七、未来规划
未来期待腾讯云数据仓库 Doris在实时数据处理场景的能力上有更进一步的提升,包括 Unique 模型上的部分列更新、单表物化视图上的计算增强、自动增量刷新的多表物化视图等,通过不断地迭代更新,使实时数仓的构建更加简单易用。
参考文章:
亿级大表毫秒关联,荔枝微课基于腾讯云数据仓库Doris的统一实时数仓建设实践

 C++)






 $HTTPD “$@“)



)
)




)
