一、流程控制
Lua 编程语言流程控制语句通过程序设定一个或多个条件语句来设定。在条件为 true 时执行指定程序代码,在条件为 false 时执行其他指定代码。
控制结构的条件表达式结果可以是任何值,Lua认为false和nil为假,true和非nil为真。
要注意的是Lua中 0 为 true:
结构控制语句:
if if...else if嵌套
二、函数
Lua函数的两种主要用途(但感觉别的语言不也一样是这俩...)
1.完成指定的任务,作为调用语句使用
2.计算并返回值,作为赋值语句的表达式使用
1.函数定义
定义格式如下:
optional_function_scope function function_name( argument1, argument2, argument3..., argumentn)function_bodyreturn result_params_comma_separated
end
-
optional_function_scope: 该参数是可选的指定函数是全局函数还是局部函数,未设置该参数默认为全局函数,如果你需要设置函数为局部函数需要使用关键字 local。
-
function是固定关键字。
-
function_name: 指定函数名称。
-
argument1, argument2, argument3..., argumentn: 函数参数,多个参数以逗号隔开,函数也可以不带参数。
-
function_body: 函数体,函数中需要执行的代码语句块。
-
result_params_comma_separated: 函数返回值,Lua语言函数可以返回多个值,每个值以逗号隔开。
可以将函数作为参数传递
myprint = function(param)print("这是打印函数 - ##",param,"##")
endfunction add(num1,num2,functionPrint)result = num1 + num2-- 调用传递的函数参数functionPrint(result)
end
myprint(10)
-- myprint 函数作为参数传递
add(2,5,myprint)2.多返回值
Lua函数可以返回多个结果值,比如string.find,其返回匹配串“开始和结束的下标”(不存在则返回nil)
> s, e = string.find("www.runoob.com", "runoob")
> print(s, e)
5 10
Lua函数中,在return后列出要返回的值的列表即可返回多值,如:
function maximum (a)local mi = 1 -- 最大值索引local m = a[mi] -- 最大值for i,val in ipairs(a) doif val > m thenmi = im = valendendreturn m, mi
endprint(maximum({8,10,23,12,5}))执行结果为
23 3
3.可变参数
Lua函数可以接受可变数目的参数,和C语言类似,在函数参数列表中使用三点...表示函数有可变的参数。
function add(...)
local s = 0 for i, v in ipairs{...} do --> {...} 表示一个由所有变长参数构成的数组 s = s + v end return s
end
print(add(3,4,5,6,7)) --->25可以将可变参数赋值给一个变量,比如下边吧...这个未知的可变参数赋值给变量arg
function average(...)result = 0local arg={...} --> arg 为一个表,局部变量for i,v in ipairs(arg) doresult = result + vendprint("总共传入 " .. #arg .. " 个数")return result/#arg
endprint("平均值为",average(10,5,3,4,5,6))#表 为求表内元素数量
总共传入 6 个数
平均值为 5.5
也可以通过select("#",...)来获取可变参数的数量
function average(...)result = 0local arg={...}for i,v in ipairs(arg) doresult = result + vendprint("总共传入 " .. select("#",...) .. " 个数")return result/select("#",...)
endprint("平均值为",average(10,5,3,4,5,6))总共传入 6 个数
平均值为 5.5
如果有固定参数,固定参数必须放在变长参数之前
function fwrite(fmt, ...) ---> 固定的参数fmtreturn io.write(string.format(fmt, ...))
endfwrite("runoob\n") --->fmt = "runoob", 没有变长参数。
fwrite("%d%d\n", 1, 2) --->fmt = "%d%d", 变长参数为 1 和 2runoob
12
通常在遍历变长参数的时候只需要使用 {…},然而变长参数可能会包含一些 nil,那么就可以用 select 函数来访问变长参数了:select('#', …) 或者 select(n, …)
调用 select 时,必须传入一个固定实参 selector(选择开关) 和一系列变长参数。如果 selector 为数字 n,那么 select 返回参数列表中从索引 n 开始到结束位置的所有参数列表,否则只能为字符串 #,这样 select 返回变长参数的总数。
- select('#', …) 返回可变参数的长度。
- select(n, …) 用于返回从起点 n 开始到结束位置的所有参数列表。
function f(...)a = select(3,...) -->从第三个位置开始,变量 a 对应右边变量列表的第一个参数print (a)print (select(3,...)) -->打印所有列表参数
endf(0,1,2,3,4,5)2
2 3 4 5do function foo(...) for i = 1, select('#', ...) do -->获取参数总数local arg = select(i, ...); -->读取参数,arg 对应的是右边变量列表的第一个参数print("arg", arg); end end foo(1, 2, 3, 4);
endarg 1
arg 2
arg 3
arg 4
三、运算符
1.算数运算符
+ - * / % ^ -负号 //整除
a = 21
b = 10
c = a + b
print("Line 1 - c 的值为 ", c )
c = a - b
print("Line 2 - c 的值为 ", c )
c = a * b
print("Line 3 - c 的值为 ", c )
c = a / b
print("Line 4 - c 的值为 ", c )
c = a % b
print("Line 5 - c 的值为 ", c )
c = a^2
print("Line 6 - c 的值为 ", c )
c = -a
print("Line 7 - c 的值为 ", c )Line 1 - c 的值为 31
Line 2 - c 的值为 11
Line 3 - c 的值为 210
Line 4 - c 的值为 2.1
Line 5 - c 的值为 1
Line 6 - c 的值为 441
Line 7 - c 的值为 -21
a = 5
b = 2print("除法运算 - a/b 的值为 ", a / b )
print("整除运算 - a//b 的值为 ", a // b )除法运算 - a/b 的值为 2.5
整除运算 - a//b 的值为 22.关系运算符
== ~=不等于 > < >= <=
3.逻辑运算符
and与 or或 not非
4.其他运算符
..连接两个字符串
#返回字符串或表的长度
a = "Hello "
b = "World"print("连接字符串 a 和 b ", a..b )print("b 字符串长度 ",#b )print("字符串 Test 长度 ",#"Test" )print("菜鸟教程网址长度 ",#"www.runoob.com" )连接字符串 a 和 b Hello World
b 字符串长度 5
字符串 Test 长度 4
菜鸟教程网址长度 14
5.运算符优先级
^
not - (unary)
* / %
+ -
..
< > <= >= ~= ==
and
or
除了^和..外所有的二元运算符都是左连接的。
四、字符串
1.表示方法
- 单引号间的一串字符。
- 双引号间的一串字符。
- [[ 与 ]] 间的一串字符。
2.长度计算
在 Lua 中,要计算字符串的长度(即字符串中字符的个数),你可以使用 string.len函数或 utf8.len 函数,包含中文的一般用 utf8.len,string.len 函数用于计算只包含 ASCII 字符串的长度。
local myString = "Hello, 世界!"-- 计算字符串的长度(字符个数)
local length1 = utf8.len(myString)
print(length1) -- 输出 9-- string.len 函数会导致结果不准确
local length2 = string.len(myString)
print(length2) -- 输出 143.转义字符
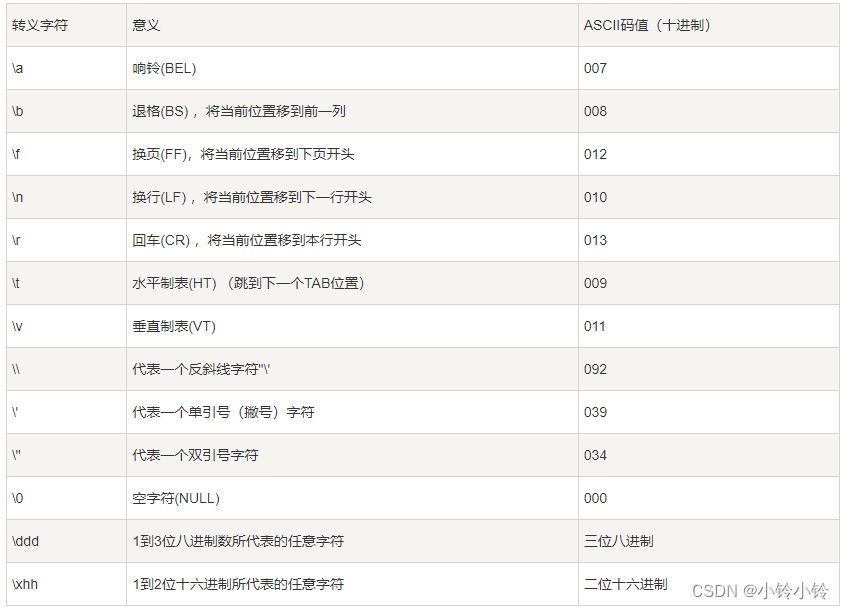
4.字符串操作
1.upper 转大写
string.upper(argument) 全部转为大写
2.lower 转小写
string.lower(argument) 全部转为小写
3.gsub 替换
string.gsub(main String,find String,replace String,num) 在字符中替换
在字符串中替换。
mainString 为要操作的字符串, findString 为被替换的字符,replaceString 要替换的字符,num 替换次数(可以忽略,则全部替换),如:
> string.gsub("aaaa","a","z",3);
zzza 3
4.find 查找
string.find (str, substr, [init, [plain]])
在一个指定的目标字符串 str 中搜索指定的内容 substr,如果找到了一个匹配的子串,就会返回这个子串的起始索引和结束索引,不存在则返回 nil。
init 指定了搜索的起始位置,默认为 1,可以一个负数,表示从后往前数的字符个数。
plain 表示是否使用简单模式,默认为 false,true 只做简单的查找子串的操作,false 表示使用使用正则模式匹配。
以下实例查找字符串 "Lua" 的起始索引和结束索引位置:
> string.find("Hello Lua user", "Lua", 1)
7 9
5.reverse 反转
string.reverse(arg) 字符串反转
> string.reverse("Lua")
auL6.format 格式化
string.format(...) 返回一个类似printf的格式化字符串
> string.format("the value is:%d",4)
the value is:4
Lua 提供了 string.format() 函数来生成具有特定格式的字符串, 函数的第一个参数是格式 , 之后是对应格式中每个代号的各种数据。
由于格式字符串的存在, 使得产生的长字符串可读性大大提高了。这个函数的格式很像 C 语言中的 printf()。
以下实例演示了如何对字符串进行格式化操作:
格式字符串可能包含以下的转义码:
- %c - 接受一个数字, 并将其转化为ASCII码表中对应的字符
- %d, %i - 接受一个数字并将其转化为有符号的整数格式
- %o - 接受一个数字并将其转化为八进制数格式
- %u - 接受一个数字并将其转化为无符号整数格式
- %x - 接受一个数字并将其转化为十六进制数格式, 使用小写字母
- %X - 接受一个数字并将其转化为十六进制数格式, 使用大写字母
- %e - 接受一个数字并将其转化为科学记数法格式, 使用小写字母e
- %E - 接受一个数字并将其转化为科学记数法格式, 使用大写字母E
- %f - 接受一个数字并将其转化为浮点数格式
- %g(%G) - 接受一个数字并将其转化为%e(%E, 对应%G)及%f中较短的一种格式
- %q - 接受一个字符串并将其转化为可安全被Lua编译器读入的格式
- %s - 接受一个字符串并按照给定的参数格式化该字符串
为进一步细化格式, 可以在%号后添加参数. 参数将以如下的顺序读入:
- (1) 符号: 一个+号表示其后的数字转义符将让正数显示正号. 默认情况下只有负数显示符号.
- (2) 占位符: 一个0, 在后面指定了字串宽度时占位用. 不填时的默认占位符是空格.
- (3) 对齐标识: 在指定了字串宽度时, 默认为右对齐, 增加-号可以改为左对齐.
- (4) 宽度数值
- (5) 小数位数/字串裁切: 在宽度数值后增加的小数部分n, 若后接f(浮点数转义符, 如%6.3f)则设定该浮点数的小数只保留n位, 若后接s(字符串转义符, 如%5.3s)则设定该字符串只显示前n位.
string1 = "Lua"
string2 = "Tutorial"
number1 = 10
number2 = 20
-- 基本字符串格式化
print(string.format("基本格式化 %s %s",string1,string2))
-- 日期格式化
date = 2; month = 1; year = 2014
print(string.format("日期格式化 %02d/%02d/%04d", date, month, year))
-- 十进制格式化
print(string.format("%.4f",1/3))基本格式化 Lua Tutorial
日期格式化 02/01/2014
0.3333
string.format("%c", 83) -- 输出S
string.format("%+d", 17.0) -- 输出+17
string.format("%05d", 17) -- 输出00017
string.format("%o", 17) -- 输出21
string.format("%u", 3.14) -- 输出3
string.format("%x", 13) -- 输出d
string.format("%X", 13) -- 输出D
string.format("%e", 1000) -- 输出1.000000e+03
string.format("%E", 1000) -- 输出1.000000E+03
string.format("%6.3f", 13) -- 输出13.000
string.format("%q", "One\nTwo") -- 输出"One\-- Two"
string.format("%s", "monkey") -- 输出monkey
string.format("%10s", "monkey") -- 输出 monkey
string.format("%5.3s", "monkey") -- 输出 mon7.char byte 数字字符互转
string.char(arg) 和 string.byte(arg[,int])
char 将整型数字转成字符并连接, byte 转换字符为整数值(可以指定某个字符,默认第一个字符)。
> string.char(97,98,99,100)
abcd
> string.byte("ABCD",4)
68
> string.byte("ABCD")
65
>
-- 字符转换
-- 转换第一个字符
print(string.byte("Lua"))
-- 转换第三个字符
print(string.byte("Lua",3))
-- 转换末尾第一个字符
print(string.byte("Lua",-1))
-- 第二个字符
print(string.byte("Lua",2))
-- 转换末尾第二个字符
print(string.byte("Lua",-2))-- 整数 ASCII 码转换为字符
print(string.char(97))76
97
97
117
117
a
8.len 求长度
string.len(arg) 计算字符串长度。
9.rep 拷贝
string.rep(string, n) 返回字符串string的n个拷贝
> string.rep("abcd",2)
abcdabcd
10. .. 链接
链接两个字符串
11.gmatch 查找返回迭代器
string.gmatch(str, pattern)
返回一个迭代器函数,每一次调用这个函数,返回一个在字符串 str 找到的下一个符合 pattern 描述的子串。如果参数 pattern 描述的字符串没有找到,迭代函数返回nil。
> for word in string.gmatch("Hello Lua user", "%a+") do print(word) end
Hello
Lua
user
(%a+是什么意思???)
12.match 查找配对
string.match(str, pattern, init)
string.match()只寻找源字串str中的第一个配对. 参数init可选, 指定搜寻过程的起点, 默认为1。
在成功配对时, 函数将返回配对表达式中的所有捕获结果; 如果没有设置捕获标记, 则返回整个配对字符串. 当没有成功的配对时, 返回nil。
> = string.match("I have 2 questions for you.", "%d+ %a+")
2 questions> = string.format("%d, %q", string.match("I have 2 questions for you.", "(%d+) (%a+)"))
2, "questions"
13.sub 截取
string.sub() 字符串截取
string.sub(s, i [, j])- s:要截取的字符串。
- i:截取开始位置。
- j:截取结束位置,默认为 -1,最后一个字符。
-- 字符串
local sourcestr = "prefix--runoobgoogletaobao--suffix"
print("\n原始字符串", string.format("%q", sourcestr))-- 截取部分,第4个到第15个
local first_sub = string.sub(sourcestr, 4, 15)
print("\n第一次截取", string.format("%q", first_sub))-- 取字符串前缀,第1个到第8个
local second_sub = string.sub(sourcestr, 1, 8)
print("\n第二次截取", string.format("%q", second_sub))-- 截取最后10个
local third_sub = string.sub(sourcestr, -10)
print("\n第三次截取", string.format("%q", third_sub))-- 索引越界,输出原始字符串
local fourth_sub = string.sub(sourcestr, -100)
print("\n第四次截取", string.format("%q", fourth_sub))原始字符串 "prefix--runoobgoogletaobao--suffix"第一次截取 "fix--runoobg"第二次截取 "prefix--"第三次截取 "ao--suffix"第四次截取 "prefix--runoobgoogletaobao--suffix"14.匹配模式
Lua 中的匹配模式直接用常规的字符串来描述。 它用于模式匹配函数 string.find, string.gmatch, string.gsub, string.match。
你还可以在模式串中使用字符类。
字符类指可以匹配一个特定字符集合内任何字符的模式项。比如,字符类 %d 匹配任意数字。所以你可以使用模式串 %d%d/%d%d/%d%d%d%d 搜索 dd/mm/yyyy 格式的日期:
s = "Deadline is 30/05/1999, firm"
date = "%d%d/%d%d/%d%d%d%d"
print(string.sub(s, string.find(s, date))) --> 30/05/1999下面的表列出了Lua支持的所有字符类:
单个字符(除 ^$()%.[]*+-? 外): 与该字符自身配对
- .(点): 与任何字符配对
- %a: 与任何字母配对
- %c: 与任何控制符配对(例如\n)
- %d: 与任何数字配对
- %l: 与任何小写字母配对
- %p: 与任何标点(punctuation)配对
- %s: 与空白字符配对
- %u: 与任何大写字母配对
- %w: 与任何字母/数字配对
- %x: 与任何十六进制数配对
- %z: 与任何代表0的字符配对
- %x(此处x是非字母非数字字符): 与字符x配对. 主要用来处理表达式中有功能的字符(^$()%.[]*+-?)的配对问题, 例如%%与%配对
- [数个字符类]: 与任何[]中包含的字符类配对. 例如[%w_]与任何字母/数字, 或下划线符号(_)配对
- [^数个字符类]: 与任何不包含在[]中的字符类配对. 例如[^%s]与任何非空白字符配对
当上述的字符类用大写书写时, 表示与非此字符类的任何字符配对. 例如, %S表示与任何非空白字符配对.例如,'%A'非字母的字符:
> print(string.gsub("hello, up-down!", "%A", "."))
hello..up.down. 4
数字4不是字符串结果的一部分,他是gsub返回的第二个结果,代表发生替换的次数。
在模式匹配中有一些特殊字符,他们有特殊的意义,Lua中的特殊字符如下:
( ) . % + - * ? [ ^ $'%' 用作特殊字符的转义字符,因此 '%.' 匹配点;'%%' 匹配字符 '%'。转义字符 '%'不仅可以用来转义特殊字符,还可以用于所有的非字母的字符。
模式条目可以是:
- 单个字符类匹配该类别中任意单个字符;
- 单个字符类跟一个 '
*', 将匹配零或多个该类的字符。 这个条目总是匹配尽可能长的串; - 单个字符类跟一个 '
+', 将匹配一或更多个该类的字符。 这个条目总是匹配尽可能长的串; - 单个字符类跟一个 '
-', 将匹配零或更多个该类的字符。 和 '*' 不同, 这个条目总是匹配尽可能短的串; - 单个字符类跟一个 '
?', 将匹配零或一个该类的字符。 只要有可能,它会匹配一个; %n, 这里的 n 可以从 1 到 9; 这个条目匹配一个等于 n 号捕获物(后面有描述)的子串。%bxy, 这里的 x 和 y 是两个明确的字符; 这个条目匹配以 x 开始 y 结束, 且其中 x 和 y 保持 平衡 的字符串。 意思是,如果从左到右读这个字符串,对每次读到一个 x 就 +1 ,读到一个 y 就 -1, 最终结束处的那个 y 是第一个记数到 0 的 y。 举个例子,条目%b()可以匹配到括号平衡的表达式。%f[set], 指 边境模式; 这个条目会匹配到一个位于 set 内某个字符之前的一个空串, 且这个位置的前一个字符不属于 set 。 集合 set 的含义如前面所述。 匹配出的那个空串之开始和结束点的计算就看成该处有个字符 '\0' 一样。
模式:
模式 指一个模式条目的序列。 在模式最前面加上符号 '^' 将锚定从字符串的开始处做匹配。 在模式最后面加上符号 '$' 将使匹配过程锚定到字符串的结尾。 如果 '^' 和 '$' 出现在其它位置,它们均没有特殊含义,只表示自身。
捕获:
模式可以在内部用小括号括起一个子模式; 这些子模式被称为 捕获物。 当匹配成功时,由 捕获物 匹配到的字符串中的子串被保存起来用于未来的用途。 捕获物以它们左括号的次序来编号。 例如,对于模式 "(a*(.)%w(%s*))" , 字符串中匹配到 "a*(.)%w(%s*)" 的部分保存在第一个捕获物中 (因此是编号 1 ); 由 "." 匹配到的字符是 2 号捕获物, 匹配到 "%s*" 的那部分是 3 号。
作为一个特例,空的捕获 () 将捕获到当前字符串的位置(它是一个数字)。 例如,如果将模式 "()aa()" 作用到字符串 "flaaap" 上,将产生两个捕获物: 3 和 5 。
没看懂(




)

)



)


)


)


