阿丹:
突然发现公司给配置的电脑是NVIDIA RTX 4060的显卡,这不搞一搞本地部署的大模型玩一玩???
从0-》1记录一下本地部署的全过程。
本地模型下载地址:
Build a Custom LLM with Chat With RTX | NVIDIA
GitHub上的开发者下载地址:
GitHub - NVIDIA/trt-llm-rag-windows: A developer reference project for creating Retrieval Augmented Generation (RAG) chatbots on Windows using TensorRT-LLM
下载的文件有32个G!!
开始安装:
为了方便观看我直接放翻译的版本:(跟着红色箭头就可以了)
安装许可: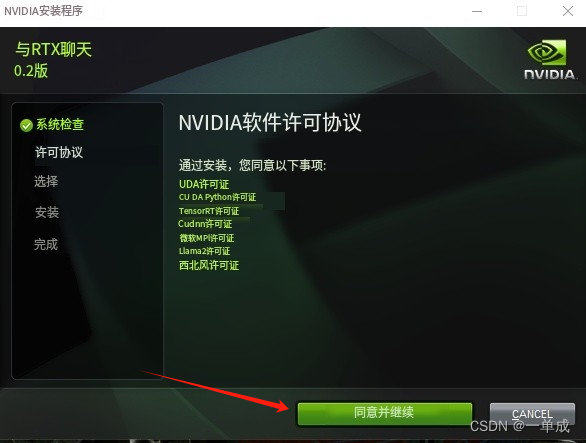
这个应该是选择安装的功能:
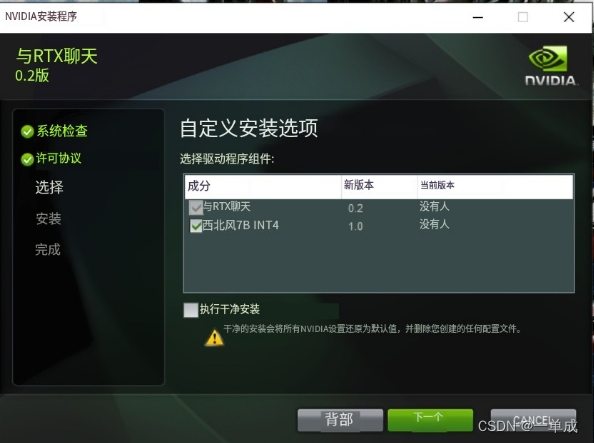
选择安装的位置:
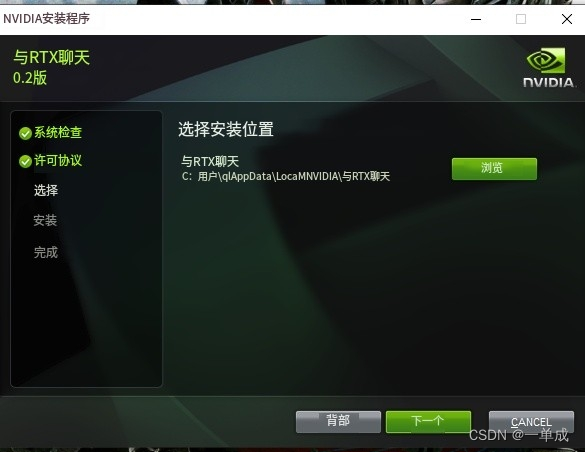
开始安装:(这个下载的过程需要使用科学的上网环境!)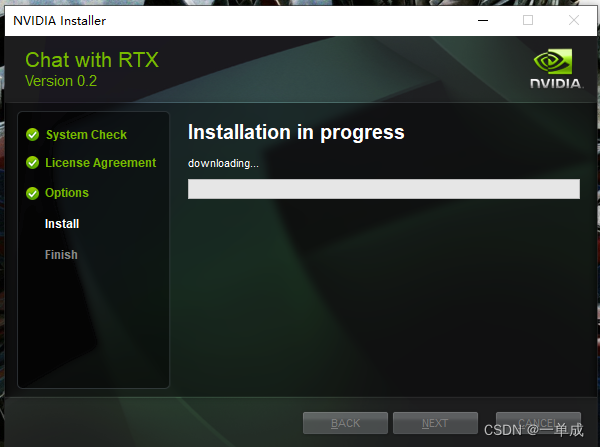
然后开始漫长的等待安装。。。。。。
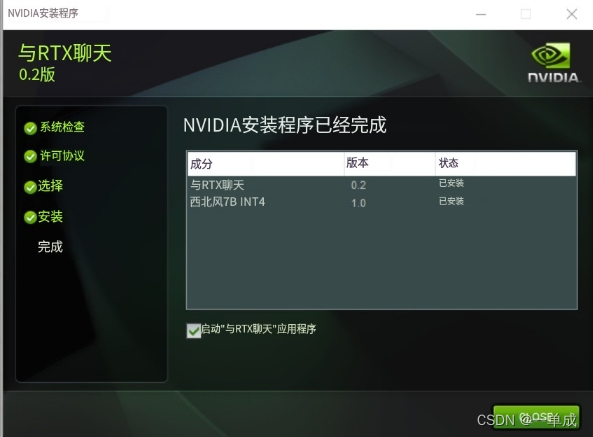
点击完成:

双击第一次会开始下载数据也是一些依赖
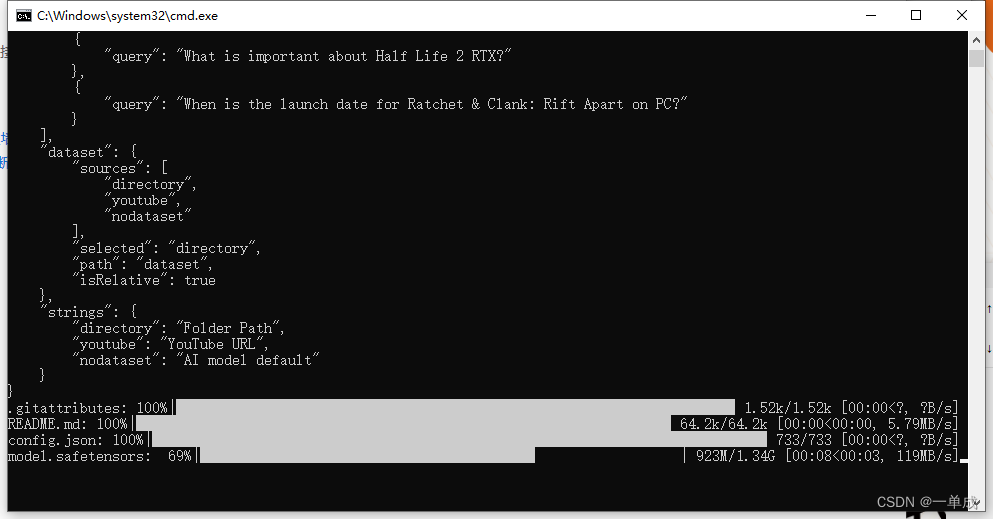
这些依赖下载完毕就欧克了。
会自己将网页打开。
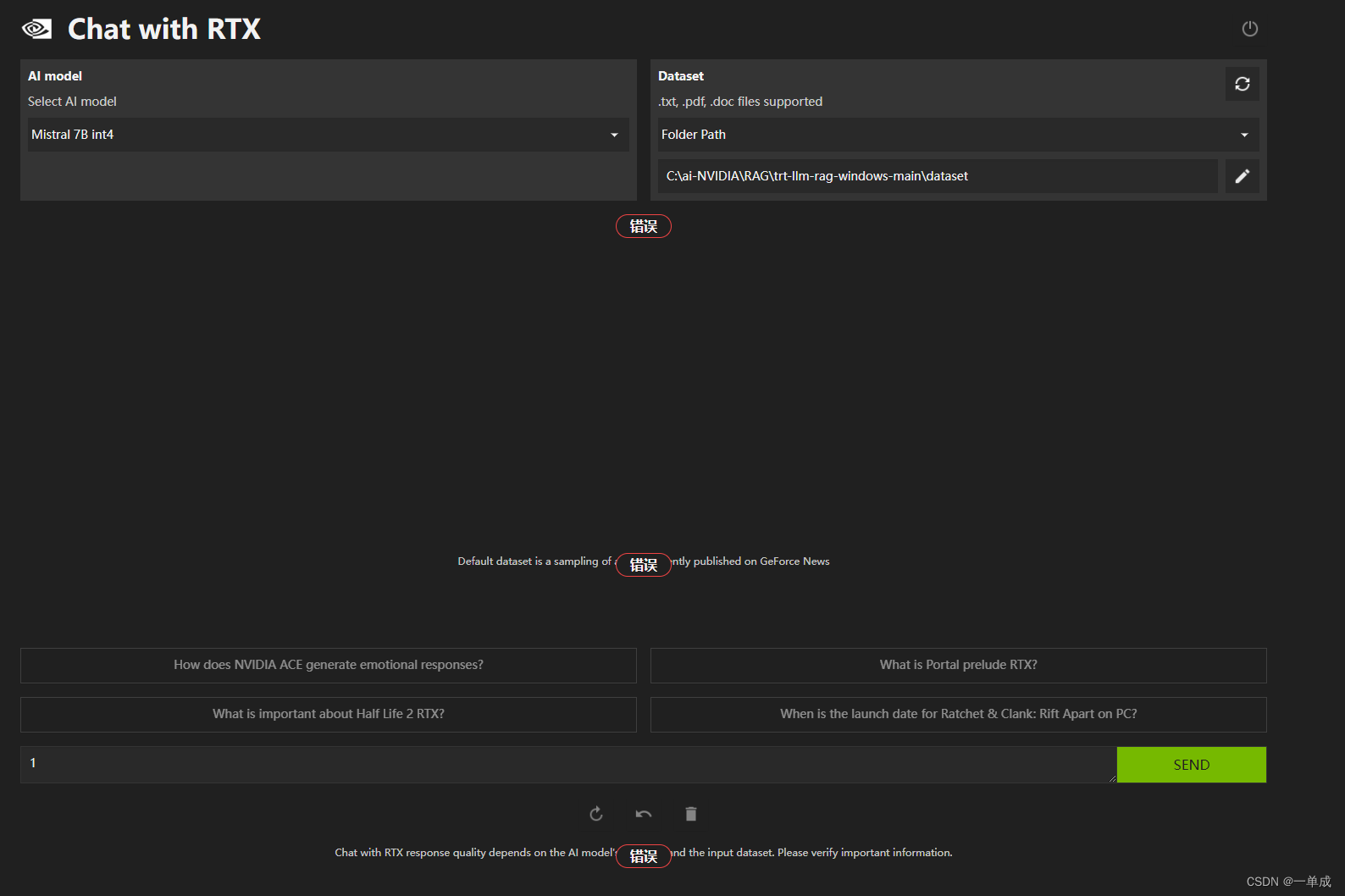 但是在本地访问的时候出现了一些问题。
但是在本地访问的时候出现了一些问题。
要注意的是。在本地运行的时候需要开启科学的上网环境。
下个文章我会重点解决和汇总一下我在安装的时候出现的问题。集中一起解决。
部署问题解决文章:
《英伟达-本地AI》--NVIDIA Chat with RTX--部署问题:ValueError: When localhost is not accessible-CSDN博客



非监督学习的进阶探索)

)


:面向过程和面象对象其实很简单!)





)

-----Cache的原理及相关知识点)


