12.3 双链表
单链表的替代方案就是双链表。在一个双链表中,每个节点都包含两个指针——指向前一个节点的指针和指向后一个节点的指针。这可以使我们以任何方向遍历双链表,甚至可以随意在双链表中访问。下面的图展示了一个双链表。
下面是节点类型的声明:
typedf struct NODE {struct NODE *fwd;struct NODE *bwd;int value; } Node;现在,存在两个根指针:一个指向链表的第一个节点,另一个指向最后一个节点。这两个指针允许从链表的任何一端开始遍历链表。
我们可能想把两个根指针分开声明为两个变量。但这样一来,我们必须把两个指针都传递给插入函数。为根指针声明一个完整的节点更为方便,只是它的值字段绝不会被使用。在我们的例子中,这个技巧只是浪费了一个整型值的内存空间。对于值字段非常大的链表,分开声明两个指针可能更好一些。另外,也可以在根节点的值字段中保存其他一些关于链表的信息,例如链表当前包含的节点数量。
根节点的fwd字段指向链表的第1个节点,根节点的bwd字段指向链表的最后1个节点。如果链表为空,这两个字段都为NULL。链表第1个节点的bwd字段和最后1个节点的rwd字段都为NULL。在一个有序的链表中,各个节点将根据value字段的值以升序排列。

12.3.1 在双链表中插入
这一次,我们要编写一个函数,把一个值插入到一个有序的双链表中。dll_insert函数接受2个参数:一个指向根节点的指针和一个整型值。
我们先前所编写的单链表插入函数把重复的值也添加到链表中。在有些应用程序中,不插入重复的值可能更为合适。dll_insert函数只有当待插入的值原先不存在于链表中时才将其插入。
让我们用一种更为规范的方法来编写这个函数。当把一个节点插入到一个链表时,可能出现4种情况:
1.新值可能必须插入到链表的中间位置;
2.新值可能必须插入到链表的起始位置;
3.新值可能必须插入到链表的结束位置;
4.新值可能必须既插入到链表的起始位置,又插入到链表的结束位置(即原链表为空)。
在每种情况下,有4个指针必须进行修改。
在情况1和情况2中,新节点的fwd字段必须设置为指向链表的下一个节点,链表下一个节点的bwd字段必须设置为指向这个新节点。在情况3和情况4中,新节点的fwd字段必须设置为NULL,根节点的bwd字段必须设置为指向新节点。
在情况1和情况3中,新节点的bwd字段必须设置为指向链表的前一个节点,而链表前一个节点的fwd字段必须设置为指向新节点。在情况2和情况4中,新节点的bwd字段必须设置为NULL,根节点的fwd字段必须设置为指向新节点。
/* ** 把一个值插入到一个双链表,rootp是一个指向根节点的指针, ** value是待插入的新值。 ** 返回值:如果欲插值原先已存在于链表中,函数返回0; ** 如果内存不足导致无法插入,函数返回-1;如果插入成功,函数返回1。 */ #include <stdlib.h> #include <stdio.h> #include "doubly_linked_list_node.h" int dll_insert( Node *rootp, int value ) {Node *this;Node *next;Node *newnode;/*** 查看value是否已经存在于链表中,如果是就返回。** 否则,为新值创建一个新节点("newnode"将指向它)。** "this"将指向应该在新节点之前的那个节点,** "next"将指向应该在新节点之后的那个节点。*/for( this = rootp; (next = this->fwd) != NULL; this = next ){if( next->value == value )return 0;if( next->value > value )break; } newnode = (Node *)malloc( sizeof( Node ) ); if( newnode == NULL )return -1; newnode->value = value; /* ** 把新值添加到链表中。 */ if( next != NULL ){ /* ** 情况1或2: 并非位于链表尾部。 */if( this != rootp ){ /* 情况1: 并非位于链表起始位置。 */newnode->fwd = next;this->fwd = newnode;newnode->bwd = this;next->bwd = newnode;}else { /* 情况2: 位于链表起始位置。 */newnode->fwd = next;rootp->fwd = newnode;newnode->bwd = NULL;next->bwd = newnode;}}else {/*** 情况3或4: 位于链表的尾部。*/if( this != rootp ){ /* 情况3: 并非位于链表的起始位置。 */newnode->fwd = NULL;this->fwd = newnode;newnode->bwd = this;rootp->bwd = newnode;}else { /* 情况4: 位于链表的起始位置。 */newnode->fwd = NULL;rootp->fwd = newnode;newnode->bwd = NULL;rootp->bwd = newnode;}}return 1; }一开始,函数使this指向根节点。next指针始终指向this之后的那个节点。它的思路是这两个指针同步前进,直到新节点应该插入到这两者之间。for循环检查next所指节点的值,判断是否到达需要插入的位置。
如果在链表中找到新值,函数就简单地返回;否则,当到达链表尾部或找到适当的插入位置时循环终止。在任何一种情况下,新节点都应该插入到this所指的节点后面。注意,在决定新值是否应该实际插入到链表之前,并不为它分配内存。如果事先分配内存,但发现新值原先已经存在于链表中,就有可能发生内存泄漏。
4种情况是分开实现的。让我们通过把12插入到链表中来观察情况1。下面这张图显示了for循环终止之后几个变量的状态。
然后,函数为新节点分配内存,下面几条语句执行之后,
newnode->fwd = next; this->fwd = newnode;链表的样子如下所示。
然后,执行下列语句:
newnode->bwd = this; next->bwd = newnode;这就完成了把新值插入到链表的过程。
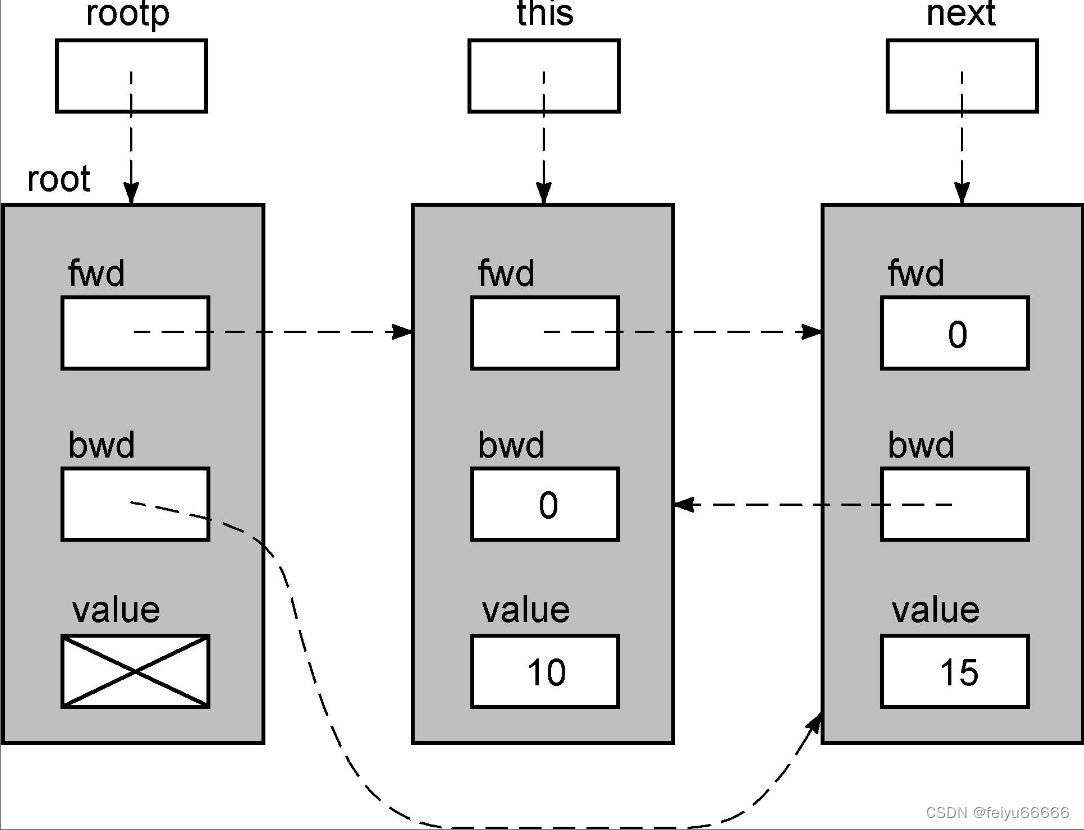

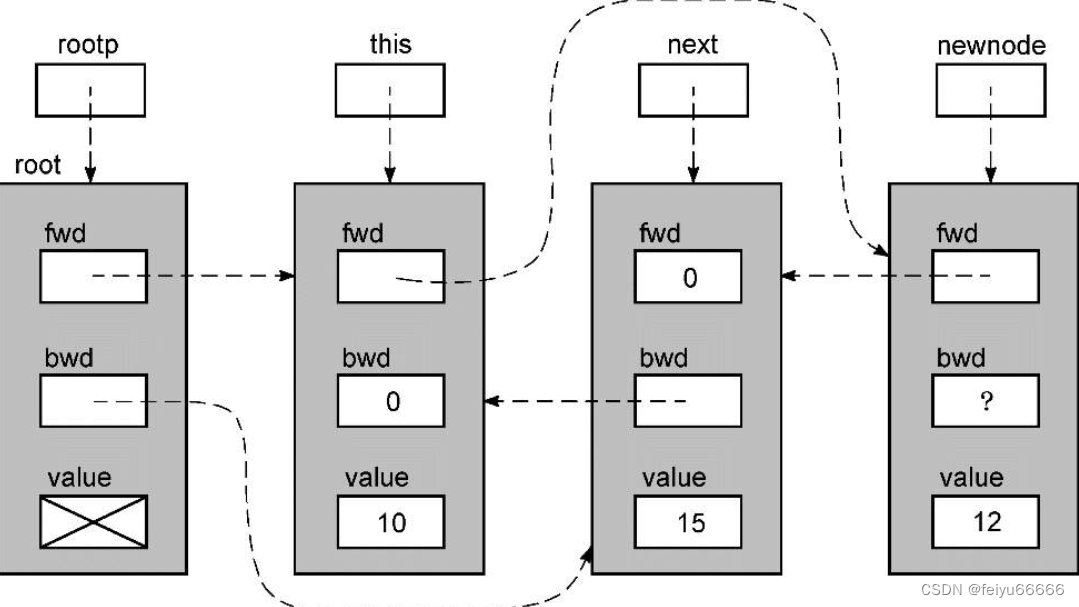
批注:书中给的图错了吧,,,如果执行newnode->bwd = this和next->bwd=newnode,应该不是上面的这张图吧。。。
简化插入函数
细心的程序员会注意到,在函数中各个嵌套的if语句群存在大量的相似之处,而优秀的程序员会对程序中出现这么多的重复代码感到厌烦。所以,我们现在将使用两个技巧消除这些重复的代码。第一个技巧是语句提炼(statement factoring),如下面的例子所示:
if( x == 3) {i = 1;something;j = 2; } else {i = 1;something different;j = 2; }注意,不管表达式x==3的值是真还是假,语句i=1和j=2都将执行。在if之前执行i=1不会影响x==3的测试结果,所以这两条语句都可以被提炼出来,这样就产生了更为简单但同样完整的语句:
i = 1; if( x == 3 )something; elsesomething different; j = 2;把上面程序最内层嵌套的if语句进行提炼,就产生了下面程序的代码段。请将这段代码和前面的函数进行比较,确认它们是等价的。
/* ** 把新节点添加到链表中。 */ if( next != NULL ){/*** 情况1或情况2: 并非位于链表的尾部。*/newnode->fwd = next;if( this != rootp ){ /* 情况1: 并非位于链表起始位置。 */this->fwd = newnode;newnode->bwd = this;}else { /* 情况2: 位于链表起始位置。 */rootp->fwd = newnode;newnode->bwd = NULL;}next->bwd = newnode; } else {/*** 情况3或情况4: 位于链表尾部。*/newnode->fwd = NULL;if( this != rootp ){ /* 情况3: 并不位于链表起始位置。 */this->fwd = newnode;newnode->bwd = this;}else { /* 情况4: 位于链表起始位置。 */rootp->fwd = newnode;newnode->bwd = NULL;}rootp->bwd = newnode;}第二个简化技巧很容易用下面这个例子进行说明:
if( pointer !=NULL )field = pointer; elsefileld = NULL;这段代码的意图是设置一个和pointer相等的变量,如果pointer未指向任何内容,这个变量就设置为NULL。但是,请看下面这条语句:
field = pointer;如果pointer的值不是NULL,field就像前面一样获得它的值的一份副本。但是,如果pointer的值是NULL,那么field将从pointer获得一份NULL的副本,这和把它赋值为常量NULL的效果是一样的。这条语句所执行的任务和前面那条if语句相同,但它明显简单多了。
在上面程序中运用这个技巧的关键是找出那些虽然看上去不一样但实际上执行相同任务的语句,然后对它们进行改写,写成同一种形式。我们可以把情况3和情况4的第一条语句改写为:
newnode->fwd = next;由于if语句刚刚判断出next==NULL,这个改动使if语句两边的第一条语句相等,因此可以把它提炼出来。请做好这个修改,然后对剩余的代码进行研究。
我们还可以对代码作进一步的完善。第一条if语句的else子句的第一条语句可以改写为:
this->fwd = newnode;这是因为if语句已经判断出this==rootp。现在,这条改写后的语句以及它的同类也可以被提炼出来。
下面的程序是实现了所有修改的完整版本。它所执行的任务和最初的函数相同,但体积要小得多。局部指针被声明为寄存器变量,进一步改善了代码的体积和执行速度。
/* ** 把一个新值插入到一个双链表中。rootp是一个指向根节点的指针, ** value是需要插入的新值** 返回值:如果链表原先已经存在这个值,函数返回0。** 如果为新值分配内存失败,函数返回-1。** 如果新值成功地插入到链表中,函数返回1。*/#include <stdlib.h>#include <stdio.h>#include "doubly_liked_list_node.h"intdll_insert( register Node *rootp, int value ){register Node *this;register Node *next;register Node *newnode;/*** 查看value是否已经存在于链表中,如果是就返回。** 否则,为新值创建一个新节点("newnode"将指向它)。** "this"将指向应该在新节点之前的那个节点,** "next"将指向应该在新节点之后的那个节点。*/for( this = rootp; (next = this->fwd) != NULL; this = next ){if( next->value == value )return 0;if( next->value > value )break;}newnode = (Node *)malloc( sizeof( Node ) );if( newnode == NULL )return -1;newnode->value = value;/*** 把新节点添加到链表中。*/newnode->fwd = next;this->fwd = newnode;if( this != rootp )newnode->bwd = this;elsenewnode->bwd = NULL;if( next != NULL )next->bwd = newnode;elserootp->bwd = newnode;return 1; }







)
)


)
)
)

)



