回归 VS 分类
- 回归估计一个连续值
- 分类预测一个离散类别
从回归到多类分类
回归
- 单连续数值输出
- 输出的区间:自然区间 R \mathbb{R} R
- 损失:跟真实值的区别
分类
- 通常多个输出(这个输出的个数是等于类别的个数)
- 输出的第 i i i个元素是用来预测第 i i i类的置信度
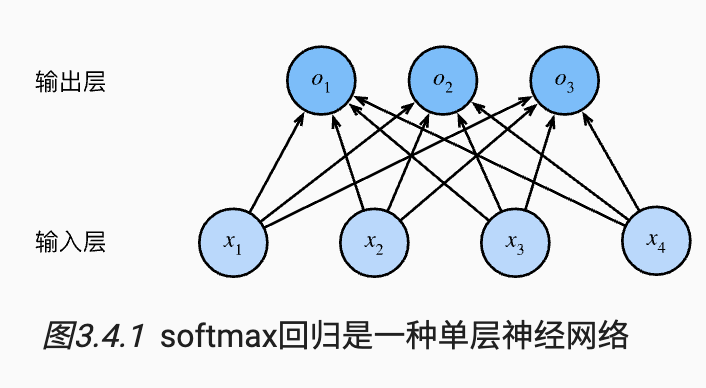
从回归到多类分类——均方损失
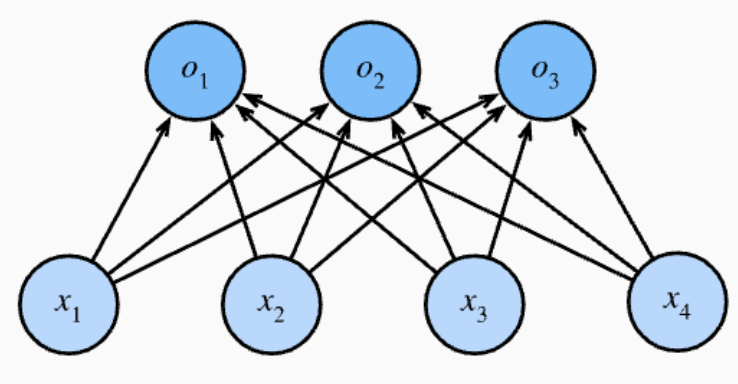
- 对类别进行一位有效编码(因为类别不是一个数,可能是一个字符串等等)
假设我们有 n n n个类别,我们可以用最简单的一位有效编码来进行编码。假设我们有 n n n个类别,那么我们的标号就是一个长为 n n n的向量,从 y 1 y_{1} y1到 y n y_{n} yn,其中,假设我的真实的类别是第 i i i个,那么 y i y_{i} yi等于 1 1 1,其他的元素全部等于 0 0 0。意思就是这个向量中,我们恰好有一个位置为 1 1 1,这个位置的下标表示第 i i i个元素,其他的元素全部为 0 0 0。
y = [ y 1 , y 2 , . . . , y n ] T \pmb{y}=[y_{1},y_{2},...,y_{n}]^{T} y=[y1,y2,...,yn]T
y i = { 1 i f i = y 0 o t h e r w i s e y_{i}= \begin{cases} 1 \quad if \quad i= y\\ 0 \quad otherwise \end{cases} yi={1ifi=y0otherwise - 使用均方损失训练(当我们有了编码以后,我们可以用最简单的回归问题的均方损失来训练,我们可以在不改动的情况下)
- 最大值最为预测(假设我们有我们训练出来的一个模型,我们做预测的时候,那么就是我们选取 i i i时的最大化 o i o_{i} oi即置信度的值,作为我的预测, i i i是我们预测的一个标号)
y ^ = a r g m a x i o i \hat{y}=\underset {i}{argmax} \ o_{i} y^=iargmax oi
从回归到多类分类——无校验比例
对于分类来讲,我们其实不关心,它们之间的实际的值,我们关心的是说,我是不是能够对正确类别的置信度特别大。
我们可以将我们的目标函数改为,我们需要使得我们对正确类 y y y的置信度,就是 o y o_{y} oy,要远远大于其他非正确类的 o i o_{i} oi,要大于某一个阈值, Δ \Delta Δ。
这样子能保证我的模型真正地能够将我的真正的类和不一样的类拉开距离。
虽然我们这里没有说你具体 o i o_{i} oi要什么样的值,大一点小一点都没关系,我们关心的是一个相对值,但是我们如果把值放在一个合适的区间,也会让我们后面的变得更加简单。
-
对类别进行一位有效编码
-
最大值最为预测 y ^ = a r g m a x i o i \hat{y}=\underset {i}{argmax} \ o_{i} y^=iargmax oi
-
需要更置信的识别正确类(大余量)
o y − o i ≥ Δ ( y , i ) o_{y}-o_{i}\geq\Delta(y,i) oy−oi≥Δ(y,i)
从回归到多类分类——校验比例
我们希望使得我们的输出能够是一个概率,现在我们的输出是 o 1 o_{1} o1一直到 o n o_{n} on,就是一个 o \pmb{o} o的一个向量。那么我们怎么做这个事情呢?
我们可以引入一个新的操作子,叫做 s o f t m a x softmax softmax,我们将 s o f t m a x softmax softmax作用在 o o o上面,得到一个 y ^ \pmb{\hat{y}} y^,它是一个长为 n n n的向量,但是它有我们要的属性,即它的每个元素都非负,而且它的和为1。
- 输出匹配概率(非负,和为 1 1 1)
y ^ = s o f t m a x ( o ) \pmb{\hat{y}}=softmax(\pmb{o}) y^=softmax(o) y ^ i = e x p ( o i ) ∑ k e x p ( o k ) \hat{y}_{i}=\frac{exp(o_{i})}{\sum_{k}exp(o_{k})} y^i=∑kexp(ok)exp(oi)具体我们的操作是说, y ^ \pmb{\hat{y}} y^里面的第 i i i个元素,它是等于 o \pmb{o} o里面的第 i i i个元素,作指数,指数的好处是说我不管它里面的值是多少,我都能够把它变成非负;再除以所有的 o k o_{k} ok作指数的和,这样我们能够保证 y ^ \pmb{\hat{y}} y^所有的元素加起来的和为 1 1 1。这样的好处就是说,我们的 y ^ \pmb{\hat{y}} y^它其实就是一个概率啦。
回忆一下,我们对真实标号的 y \pmb{y} y,也是作成一个概率,因为他刚好只有一个元素为 1 1 1,剩下的全部为 0 0 0,任何满足所有元素非负,且和为 1 1 1的,都可以当作一个概率。
那么我们就得到两个概率,一个是真实的 y \pmb{y} y的概率,一个是预测的 y ^ \pmb{\hat{y}} y^的概率。
- 概率 y \pmb{y} y和 y ^ \pmb{\hat{y}} y^的区别作为损失
Softmax和交叉熵损失
我们假设有两个离散概率 p \pmb{p} p和 q \pmb{q} q,都有 n n n个元素
- 交叉熵常用来衡量两个概率的区别 H ( p , q ) = ∑ i − p i l o g ( q i ) H(\pmb{p},\pmb{q})=\underset {i}{\sum}-p_{i}log(q_{i}) H(p,q)=i∑−pilog(qi)
- 将它作为损失
l ( y , y ^ ) = − ∑ i y i l o g y ^ i = − l o g y ^ y l(\pmb{y},\hat{\pmb{y}})=-\underset {i}{\sum}y_{i}log\hat{y}_{i}=-log\hat{y}_{y} l(y,y^)=−i∑yilogy^i=−logy^y我们知道,真实值里面只有 1 1 1个为 1 1 1,其余都为 0 0 0,因而公式可以简写为,负的 l o g log log对真实类别 y y y它的预测的 y ^ \hat{y} y^,就是对真实类别我的预测值求 l o g log log然后求负数。
可以看到,对分类问题来讲,我们不关心对非正确类的预测值,我们只关心对正确类的预测值它要执行度要多大。 - 其梯度是真实概率和预测概率的区别
∂ o i l ( y , y ^ ) = s o f t m a x ( o ) i − y i \partial_{o_{i}}l(\pmb{y},\pmb{\hat{y}})=softmax(\pmb{o})_{i}-y_{i} ∂oil(y,y^)=softmax(o)i−yi
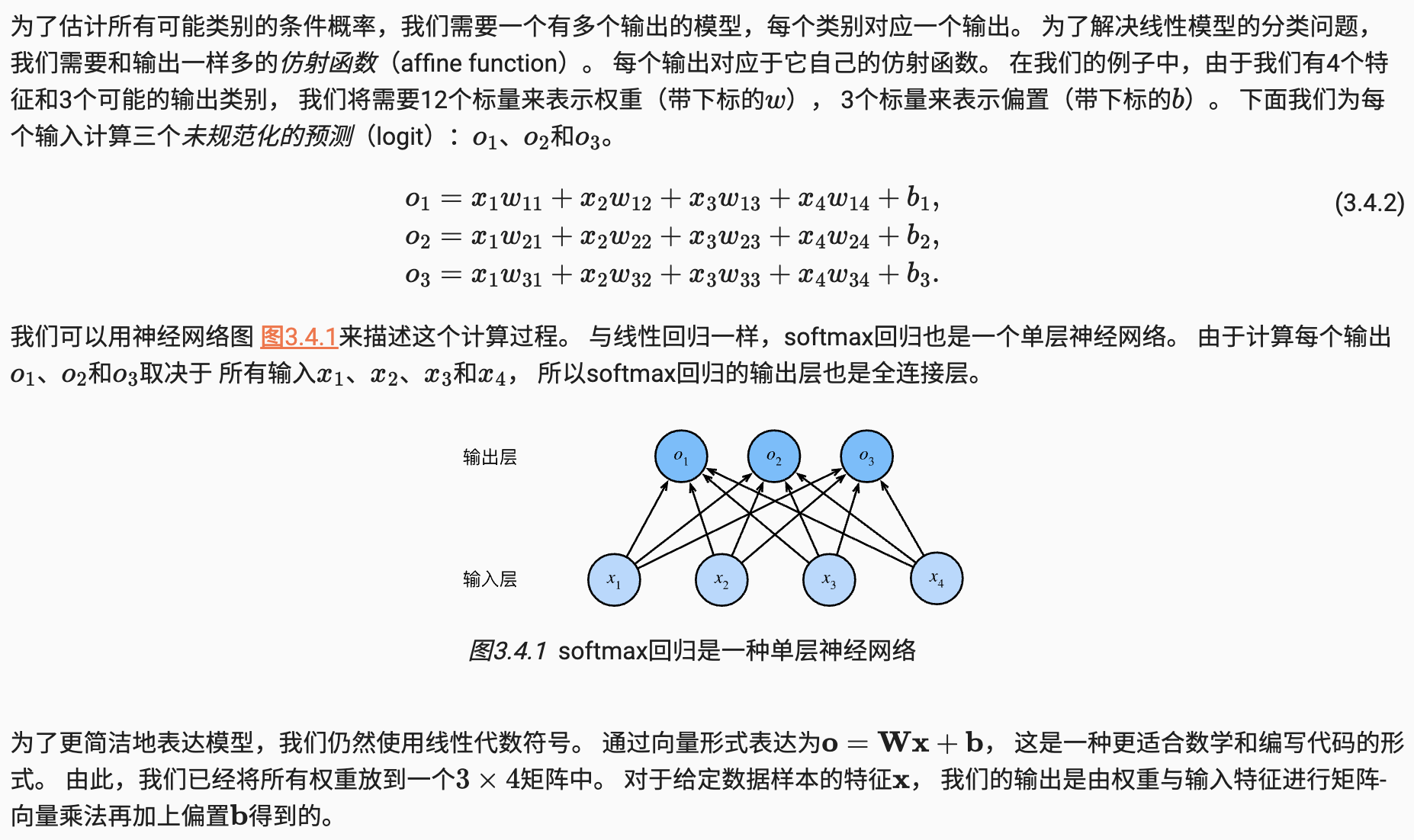

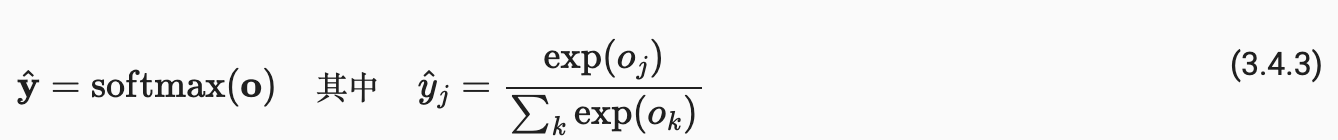
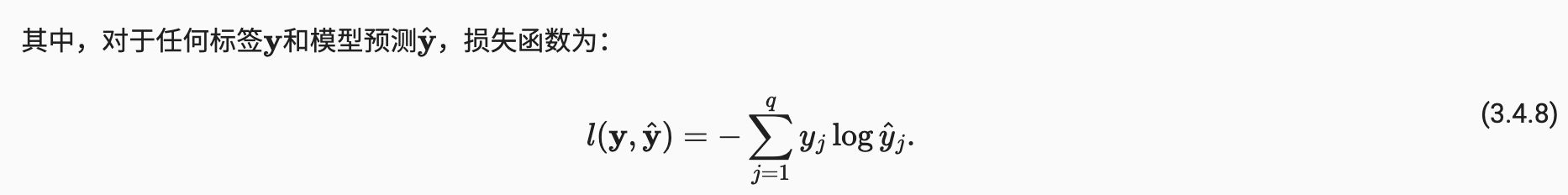

总结
- Softmax回归是一个多类分类模型
- 使用Softmax操作子得到每个类的预测置信度
- 使用交叉熵来衡量预测和标号的区别



)

)


heap2 UAF(use-after-free)漏洞)

)


![P9420 [蓝桥杯 2023 国 B] 子 2023 / 双子数--2024冲刺蓝桥杯省一](http://pic.xiahunao.cn/P9420 [蓝桥杯 2023 国 B] 子 2023 / 双子数--2024冲刺蓝桥杯省一)


搜索框-带历史记录)
基础知识)

)