摘要
本文介绍了使用 ChatGPT逐步创建 一个简单的Java框架,包括构思、交流、深入优化、逐步完善和性能测试等步骤。
亲爱的Javaer们,在平时编码的过程中,你是否曾想过编写一个Java框架去为开发提效?但是要么编写框架时感觉无从下手,不知道从哪开始。要么有思路了后对某个功能实现的技术细节不了解,空有想法而无法实现。如果你遇到了这些问题,看完这篇文章你也能用ChatGPT编写一个简单的JAVA框架。
构思清晰
首先,你需要明确你的框架要解决什么问题,具有什么特性。这将有助于ChatGPT更好的理解你的需求。
例如:我在一个前后端分离的需求中发现有太多的枚举类的描述需要给前端返回。传统的方式是后端根据枚举类的映射,每个枚举值编写代码映射成描述给前端返回。但这次需求需要给前端返回的枚举描述太多了。这让我和我的小伙伴们感觉无从下手。所以我就思考能否编写一个注解自动帮我们扫描这些枚举类,然后生成key和描述的map,最终放到容器中去呢?
解决问题:解决前后端分离过程中需要手动编写代码将枚举key的描述映射给前端。
特性:框架有一个注解,注解有三个字段name,key,和desc,修饰在枚举类上。框架需提供外部获取枚举map的接口。
与 ChatGPT 交流
启动 ChatGPT,向它讲述你的构想和需求。它可以为你生成初始代码、提供结构建议,甚至帮你处理一些逻辑。
想好了框架要解决的问题和框架的特性之后,接下来就要将框架要解决的问题和特性给总结成一段文字发给ChatGPT。
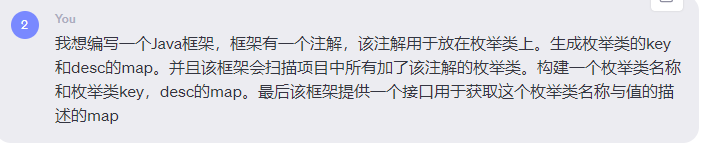
chatgpt根据我的需求大概生成了下框架的demo版本。可以看到和我设想的还是有些区别的,我想是将枚举放在类上。然后枚举的属性有name,key,和desc。
name:代表枚举map在最外层map中的key。
key:代表枚举的key或值字段。
desc:代表枚举的描述字段。
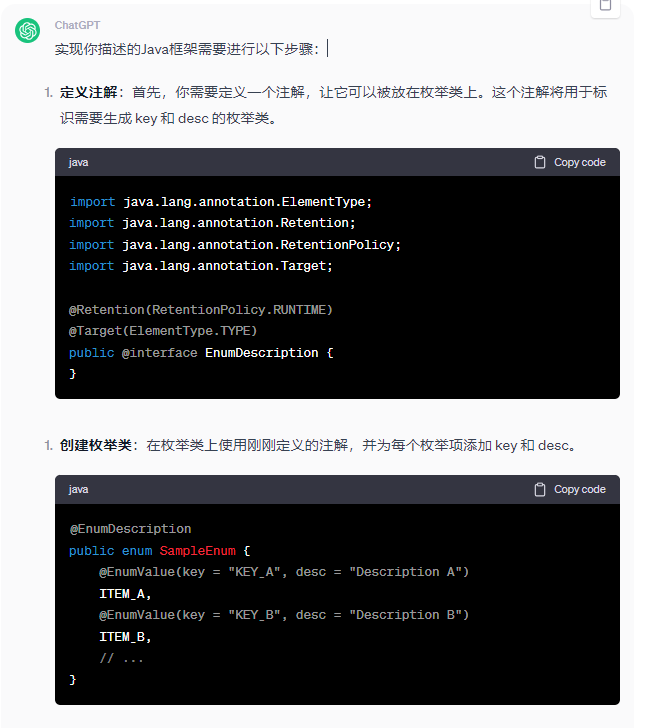
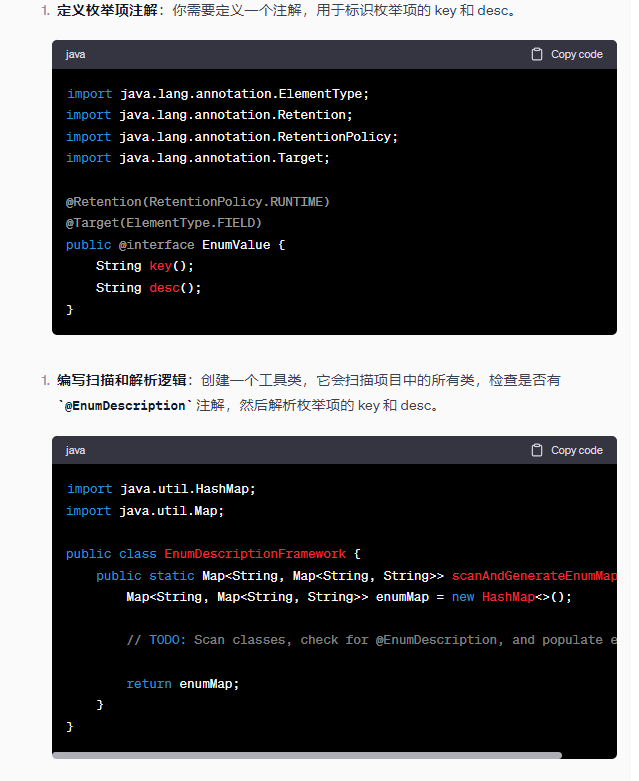

深入互动
与 ChatGPT 进行更深入的交流,询问它关于代码优化、异常处理等方面的建议。它可以帮你找到更好的解决方案。
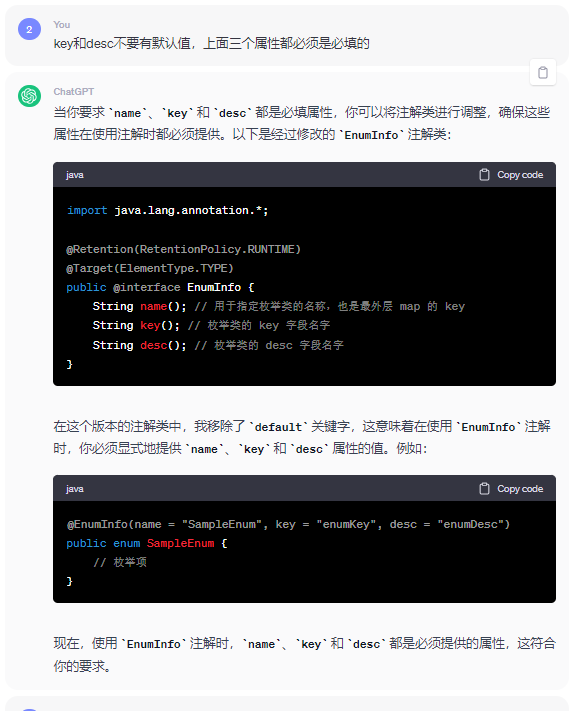
接下来需要与ChatGPT进一步交流,让ChatGPT将之前生成的代码进行优化。
EnumInfo注解优化前:

优化后:
逐步完善
逐步引导chatgpt完善框架
在 ChatGPT 的帮助下,逐步完善你的框架。亲自动手编写代码,与 ChatGPT 一起探讨每个细节。
最后可以和ChatGPT一步步交流,让它帮你构建一个完整的框架。
最终慢慢与ChatGPT不断对话迭代之后将框架的核心类生成,迭代过程由于太长故省略。
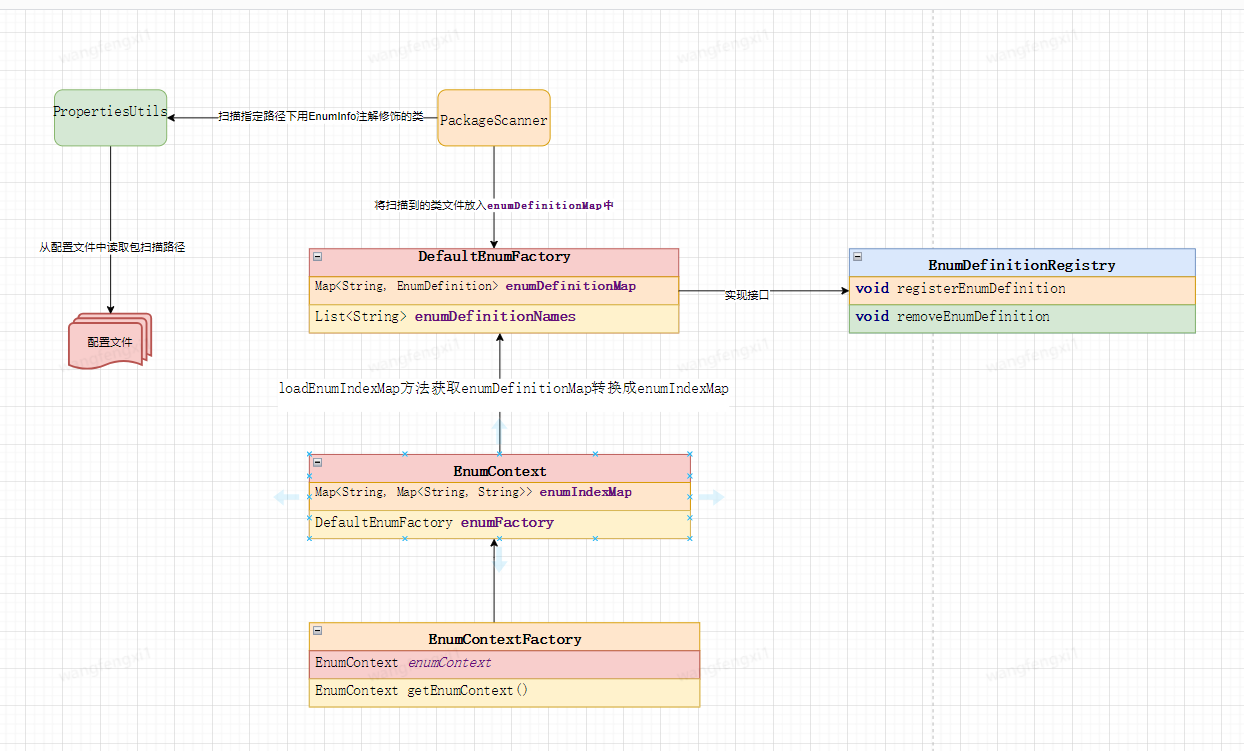
框架核心类说明
在ChatGPT给出核心代码之后,我参考Spring模块设计最终初版框架类如下:
PackageScanner:用于扫描给定包中带有指定注解的类的实用工具类。
PropertiesUtils:提供操作属性文件的实用方法的工具类。
EnumInfo:用于标注枚举类的注解,指定枚举项的名称、key 字段和 desc 字段信息。 通过在枚举类上添加该注解,可以为枚举项建立索引映射,并指定用于查找 key 和 desc 的字段名称。
EnumContext:枚举上下文类,用于管理枚举定义信息并提供获取枚举信息的方法。
EnumContextFactory:枚举上下文工厂类,用于创建和获取单例的枚举上下文对象。
EnumDefinition:表示枚举定义的类,用于存储枚举类的信息。
EnumDefinitionRegistry:枚举定义注册接口,用于注册、查询和管理枚举定义。
DefaultEnumFactory:默认的枚举定义工厂类,实现了 EnumDefinitionRegistry 接口。
看到这使用ChatGPT编写框架部分已经完成了。大件可以使用chatgpt开发自己的JAVA框架。但要想把框架实际应用到生产还需要做一些收尾流程。
框架使用测试
在于ChatGPT交流,完成框架编写之后需要将框架应用到实际项目中。
笔者业务系统管理端在进行前后端分离的过程中,研发们发现有许多枚举类对应的枚举描述需要给前端返回。
1)一开始设想的是每个枚举类都写代码给前端封装返回文字。但是由于笔者业务系统配置项过多,每个配置项都写代码太过麻烦。
2)于是研发们想能否使用一个统一的接口给前端返回枚举类对应的描述,前端只需要输入枚举类名称就可以获得对应的枚举key和描述的映射关系。
于是我们创建了一个接口,定义了一个Map对象给前端返回枚举类的key和描述的对应关系。但是由于笔者业务系统的渠道配置还是太多了。使用这种方式我们需要初始化这个Map。初始化Map代码如下:
public HashMap<String, Map<Integer, String>> initEnumMap() {enumMap = new HashMap<>();enumMap.put("前端获取枚举map的key", XXXEnum.getEnumMap());enumMap.put("前端获取枚举map的key", XXXEnum.getEnumMap());enumMap.put("前端获取枚举map的key", XXXEnum.getEnumMap());...return enumMap;
}可见,每新增一个枚举类。我们都需要在静态代码块中将映射关系放入map中。并且枚举类需要新增一个获取key和描述的映射关系方法。这样还是太麻烦了。并且后续新增映射关系还得更改这个类的代码。
能否将map初始化的步骤和枚举类创建map的步骤省略呢?
3)于是我们设想定义一个注解。使用这个注解标记的类,框架扫描这些类。并生成获取枚举key和描述的映射关系的方法。最终完成初始化Map的过程。对外只提供获取总枚举Map的方法即可。用户无需关心Map如何构建。使用这个框架之后,笔者业务系统这个接口的代码如下:
/*** 获取枚举
** @param enumKey 枚举key* @return 返回值 Map<Integer,String>;code,描述
*/
@RequestMapping("/getEnum")
public Result<Map<String, Map<String, String>>> getEnum(String enumKey) {try {// 获取枚举上下文对象EnumContext enumContext = EnumContextFactory.getEnumContext();// 获取枚举mapnewEnumMap = enumContext.getEnumIndexMap();// buid映射从ducc中获取,所以需要手动设置newEnumMap.put(BUID.getKey(), getBuIdMap());} catch (Exception e) {log.error("获取枚举map出错!enumKey:{}", enumKey, e);return Result.createFail(e.getMessage());}// 如果枚举key为空则返回全部if (StringUtils.isBlank(enumKey)) {return Result.createWithSuc(newEnumMap);}// 如果枚举key不为空则返回指定值Map<String, Map<String, String>> resultMap = new HashMap<>();resultMap.put(enumKey, newEnumMap.get(enumKey));return Result.createWithSuc(resultMap);
}4)注解类代码如下:
在这举个测试枚举类的例子
@EnumInfo(name = "StatusEnum", key = "code", desc = "description")
public enum StatusEnum {SUCCESS(200, "Success"),ERROR(500, "Error");private final int code;private final String description;StatusEnum(int code, String description) {this.code = code;this.description = description;}public int getCode() {return code;}public String getDescription() {return description;}
}以后新增一个枚举类只需要标记@EnumInfo(name = "StatusEnum", key = "code", desc = "description")。将枚举类的name ,key字段名称和描述字段名称指定即可。无需修改接口的代码即可给前端返回该枚举的key和描述的映射关系。极大的减少了研发联调时间及测试回归时间。
框架性能压测
框架应用到实际生产项目中,需要对ChatGPT辅助编写的框架进行充分的测试验证。同时也要对框架的性能进行测试,知道框架的瓶颈。常见的接口压测工具有LoadRunner和Apache JMeter等。任选一种压测工具进行压测即可。
笔者将框架应用到项目中对外暴露了一个接口,该接口在4C4G机器配置下,单机最高可支持1000QPS,在1000QPS下,单机CPU使用率达到30%,系统负载接近0.9,内存使用率与压测前无明显变化。
总结
本文演示了如何使用ChatGPT逐步创建Java框架,解决前后端分离中的问题。以上使用ChatGPT逐步完善框架的经验分享给大家,希望对各位有所帮助。
作者:京东零售交易团队 王凤玺
来源:京东零售技术 转载请注明来源





)


)




![基于Springboot开发的JavaWeb作业查重系统[附源码]](http://pic.xiahunao.cn/基于Springboot开发的JavaWeb作业查重系统[附源码])

)



