背景
开源生态的上下游中,漏洞可能存在多种成因有渊源的其它缺陷,统称为“同源漏洞”,典型如:
- 上游代码复用缺陷。开源贡献者在实现功能相似的模块时,常复用已有模块代码或逻辑;当其中某个模块发现漏洞后,该漏洞可能随复用也出现在相似模块中。
- 接口或代码误用。某些接口,特别是欠缺充分文档的项目内部接口,可能误导开发者以相同错误方式调用;而某些不完备的代码,例如示例代码或开源代码片段,也常被开发者直接使用。
- 版本分支与碎片化中的残留漏洞。上游的多分支,与下游二次开发者的定制化,使碎片版本与主线差异扩大,以致难以分析上游代码漏洞是否(可能以不同形态)存在于下游。
- 其它开发实践风险。例如,松散的开发协作中,可能存在开发者在开发分支回滚时将他人的缺陷修复一并覆盖;同时也存在恶意开发者仿照历史漏洞植入可利用缺陷的投毒可能。
同源漏洞的威胁,在真实世界中缺少足够的研究,却影响深重。例如,上游开源项目的漏洞与补丁完全公开,使得黑客人工分析与历史高危漏洞相似的缺陷并利用,成本更低。而下游项目开发者常常不会主动跟踪其使用的开源代码的安全漏洞,导致很多关键系统可能带着多年漏洞运转,更是为黑灰产无感知地渗透进去提供了方便。
作为软件供应链研究重点,腾讯安全云鼎实验室通过对开源上下游的典型实践的长期分析和漏洞挖掘,论证了供应链的典型威胁,特别是“同源漏洞”的风险模型。基于此,我们提出一种区别于传统静态分析和成分分析的方法,统一解决两个问题:开源软件有哪些与历史漏洞相似的缺陷?自研代码中引入了哪些开源代码的漏洞?
现有技术缺陷
开源漏洞挖掘检测,现有技术手段包括SAST与SCA/SBOM,但二者均难以有效解决同源漏洞问题。
狭义的SAST即源代码分析,可依据典型缺陷模式构建规则库,分析项目中语法、数据流匹配的片段。但此类规则,一方面依照通用缺陷类型编写,却无法检测包含复杂或项目特定逻辑的漏洞;另一方面受制于过程间分析等限定,难以在没有人工定制前提下适配每个项目的接口规约。这导致真实世界漏洞可被这些SAST工具检出比例很低。
SCA/SBOM的核心是源代码成分判定,依照显式的依赖配置、版本号、特征文本或模糊的代码指纹,以从不同粒度确定代码组成的最相似开源来源,进而判断是否存在陈旧成分带有漏洞。但对于C/C++这种没有统一包管理机制的生态,SCA只能通过指纹相似性匹配来实现,又面临三个问题:基于文本相似性的指纹匹配方法,无法保证对基于开源二次开发项目的抵抗,导致无法对应到来源;基于代码骨架、数据流等构建特征向量的匹配方法,应用范围和实际效果难以保证;而代码片段级或复杂的指纹库对真实项目扫描,运算开销又很难降低到可行范围。
一个简单的实验可以说明如上问题。选取8款漏洞较多的开源基础软件,将其代码置为2020年1月的版本,统计其截止到2023年10月的已知CVE数量;之后使用三款工具对这8个代码库进行扫描,统计其总报告漏洞数量(Positives)以及命中的CVE数量(TP)。三款工具分别为代表SAST业界基准的Coverity,基于文本相似性的类SCA项目VUDDY,以及基于数据依赖相似性的类SCA项目TRACER。检测结果如下:
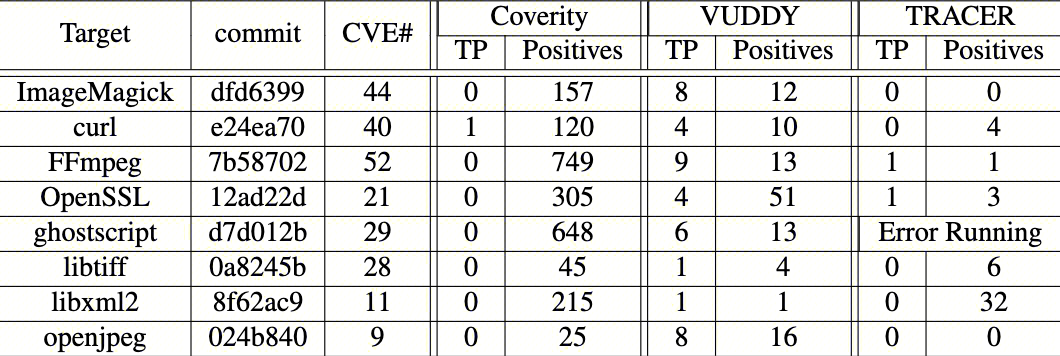
可见,SAST搭配默认规则集,会产生大量的检出报告,但却几乎没有命中真实的漏洞。而作为学术领域最前沿的探索,两款类SCA工具具备一定检出效果,但难以达成足够的召回指标,同时分析的开销也难以接受。此外,使用后文中提及的数据库、系统内核的下游二次开发项目,测试如上工具,以及传统SCA工具如FossID,面对存在变形、改写的代码,效果更难以评价。
新方向:Patch2QL
深入分析SAST与SCA的限制,总结其无法解决开源同源漏洞的根本原因在于:SCA尝试用模糊匹配方法结合一定的语义信息实现泛化的查找,但本质仍是相似度判定;而SAST天然可以通过规则实现对语义模式的匹配,但缺少针对已知漏洞的针对性规则。
由此,Patch2QL的基本思想就是:针对已知漏洞,自动化生成可以匹配目标代码的规则,应用于SAST工具使其具备SCA的能力。
原理与实现
Patch2QL的核心任务就是处理漏洞关键代码,使用规则条件描述漏洞语义,组成完备的规则并适当泛化。工具整体原理流程如下。
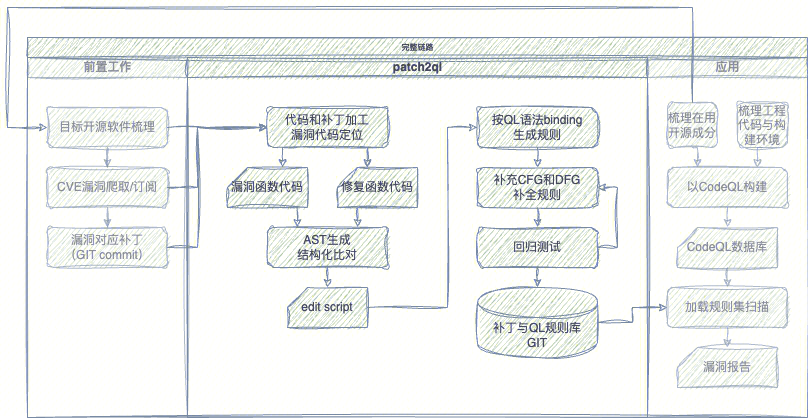
漏洞语义的获取,通过对漏洞补丁前后的代码上下文分析提取。虽然部分补丁是实现漏洞利用路径的封堵,但多数仍然是直接修复缺陷根因,因此可以认为承载了漏洞语义信息。将打补丁前后版本代码转换为抽象语法树(AST),使用一种结构化比对算法执行比对,可以获得关键差异及其类型,即增删改和移动的语法结构。
为从语法差异中还原语义信息,需要补充差异结构的上下文,一方面为必要的控制结构,例如差异关联的判断或循环条件、前后的相关调用序列;另一方面为相关的数据依赖,提取出差异结构中所访问的内存对象,并前向分析直接影响的赋值或判断访问,或后向分析数据流向的变量施效节点。由此补充得到可充分限定目标节点,同时又可无视无关语法结构的组合查询条件。
Patch2QL当前选取CodeQL作为底座SAST工具,这得益于CodeQL类SQL查询的规则格式,方便程序将差异条件翻译为规则语句;同时,QL也具备作为源代码分析的通行语言潜力,可保证生成的规则集的公开可用。当然,工具的思想并不局限于特定底座,例如基于Clang AST Matcher或者Semgrep均可以生成有效的规则代码。
目标与覆盖
当前Patch2QL重点完成了对C语言生态的能力建设,主要由于C在基础设施软件和系统中的统治地位,以及漫长开发历史中难以理清的复杂问题。对C++的支持也在同步研发中,以支持更多数据库、浏览器内核等应用生态。但值得注意的是,开源同源漏洞的问题并不仅存在于C/C++,在前期研究中,在Java的一些开源项目中也发现有Maven包引用与源码包含并存的现象,表明其它语言均不同程度存在类似问题。
在应用方面,目前参考Google OSS-Fuzz项目收录的安全测试重点项目列表以及近年来披露漏洞一定数量以上的C语言开源项目,完成了对top 111个项目的历史漏洞规则覆盖。以Linux Kernel为例,覆盖了2004-2024的2267个CVE漏洞补丁,目前对开源社区公开的规则集中,排除默认环境编译失败或非代码修改的部分外,生成规则3967条,覆盖80%以上漏洞。
实战:上游开源项目漏洞挖掘
Patch2QL的关键应用之一,是挖掘上游开源项目自身由于复杂的开发历史和人员构成,所存在的与历史漏洞相同成因的缺陷。在2023年6-7月为期2个月的简单测试中,在已覆盖的111个上游开源项目中,使用生成的历史漏洞规则扫描各项目最新分支代码,均有不同程度的检测发现。
考虑到开源社区漏洞认定一般需要触发PoC与修复补丁,在2个月期间选取了部分初判中高危以上、原始漏洞原理清晰且可复现的漏洞的同源检出,分析后提交社区,共挖掘7个CVE漏洞;对短时间难以构造PoC但可明确问题的检出,以issue形式反馈社区并按bug修复。此外,近期刚刚启动的工作是使用Linux Kernel规则集扫描上游内核代码以及LTS分支代码,也在逐步有漏洞产出。一份持续增长的漏洞挖掘列表如下。
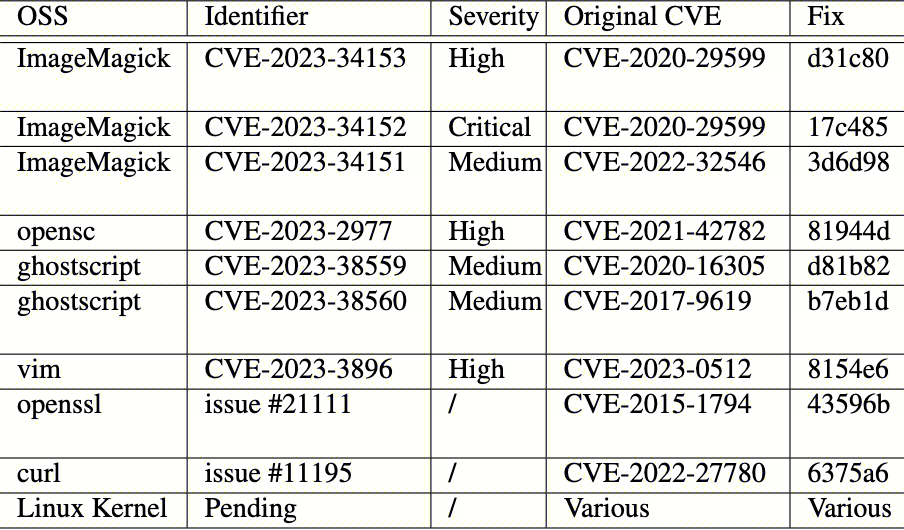
在挖掘的漏洞中,多数成因为项目对多种格式、协议、设备驱动等的实现中,仅对发现历史漏洞的模块进行了修复,但并未审计其他开发者仿照该模块修复前版本实现的其它模块。例如,其中的ImageMagick漏洞CVE-2023-34153,其同源的原始漏洞为CVE-2020-29599,是在ImageMagick处理PDF格式图像时,如果存在密码保护需要调用外部命令执行认证,但对用户传入的密码没有充分过滤非法字符,拼接后构成命令注入。该漏洞的修复是针对PDF格式处理,添加了单独的命令字符串过滤,替代原有全局通用过滤函数的调用。但在一年后实现的对视频格式的支持中,调用ffmpeg命令解码的功能拼接的用户传入参数,仍然使用有缺陷的字符串过滤方法,形成了新的命令注入漏洞。
同时,也有部分新挖掘的漏洞并不伴随着代码复用而来,因而也无法依靠相似代码检测来发现。例如,VIM漏洞CVE-2023-0512,是一个VIM在ex模式下重新计算窗口字符宽度中出现的除零错误。而Patch2QL发现的CVE-2023-3896漏洞存在于窗口指针在平滑滚动后重绘的功能中,这两处漏洞的代码上下文不存在可见的复用关系,仅在计算窗口宽度变量赋值存在2行重复,且距离后续除法(求模)运算距离不等,可以认为无法用SCA或克隆检测的能力发现。
实战:下游开源成分漏洞检测
很多组织或厂商会基于上游开源项目,进行功能的定制;很多二次开发项目没有选择将定制部分贡献合入上游项目,而以独立形态持续维护,长时间后形成与上游的硬分叉。同时,为追求相对稳定性,这些二次开发项目常常选取上游一个稳定版本为基准,随时间推移更加剧了与上游的差异化,增加了判断上游漏洞在下游存在性和补丁适用性的难度。
在2023年4月和9月,以Patch2QL当时的规则储备,对操作系统内核和数据库两个重点二次开发领域,针对国内外主流厂商的开源项目进行了小范围分析。结果揭示了开源供应链下游实践中不同程度的来由的问题,并通过向相关厂商和社区反馈,及时封堵了这些长时间存在的风险。
需要说明的是,当时的一次性全量漏洞检测,基本消除了相关软件的历史漏洞包袱;而从检测到目前,Patch2QL也经历了多轮的技术迭代。因此,本次披露的历史检测结果,并不说明相关软件当前的安全态势。
二次开发数据库
数据库领域,选取了两款上游代表性开源项目的下游。其一是sqlite3,因其简洁性而被普遍作为数据存储模块,源码形式包含编译到其它项目中,并根据需要存在各种改造提升。其二是PostgreSQL,作为国内外最流行的开源数据库引擎,它孵化了最多样式的下游DBMS开源项目,同时也由于宽松的许可而被很多厂商用作商业数据库的底座。
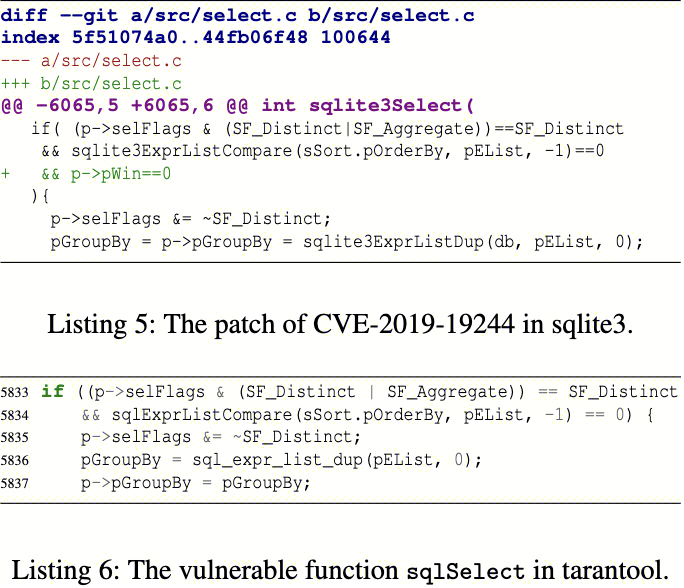
sqlite3的一个标志性下游项目为Tarantool,一款Nosql内存数据库。sqlite3作为其SQL语言解析器,被完全重构后嵌入项目中使用。这个重构包括所有几乎所有符号的重命名,代码语句同义语法变换,并消除了所有“sqlite”字样的文本特征,与上游项目相比,已经难以明确对应关系。在这种程度的重构下,现有SCA工具显然无法判断出其中的sqlite3成分和版本。但是使用Patch2QL规则,我们在其中发现了7个sqlite3的历史漏洞残留。以CVE-2019-19244为例,尽管漏洞所属函数、漏洞位置上下文中的被调用函数名称等均被改写,但人工仍然可以判断出来检测出的代码对应了原始漏洞,如下图所示。现实中,也存在大量项目的开发者,通过类似的方式将开源代码重构后嵌入并作为自研代码发布,而本次检查结果说明重构后代码往往也无法规避上游漏洞的威胁,而Patch2QL足以透过类似重构实现检测。
PostgreSQL的标志性项目为PolarDB for PostgreSQL(下文简称PolarDB),一款国产云原生数据库。PolarDB基于PostgreSQL 11.9分支进行了深度改造和重构。在GitHub上该项目的社区版本并没有舍弃对上游PostgreSQL的跟踪,并且可以观察到,在相当长时间内该项目也在持续回合上游的某些重要补丁。但是,11.9毕竟是PostgreSQL的一个比较陈旧的版本,同时根据PostgreSQL的版本政策,11大版本也已经在2023年11月停止更新支持,这意味着基于11的下游项目失去了可合入代码安全更新的来源。在本次分析中,我们检测出PolarDB项目中存在6个上游未修复漏洞;在上报社区后,得益于未与上游存在过大分叉,开发者在一天内确认并通过合并PR的方式完成了漏洞修复。对于这种二次开发项目基于的版本失去上游支持的情况,借助Patch2QL的能力,在对上游其它分支漏洞建立规则后,证明可以有效用于下游项目的漏洞存在性检测。
二次开发Linux内核
自研操作系统是信创中的重要基础,也是面临CentOS发行版和RedHat政策变化下的必选项。国内以openEuler、OpenAnolis、OpenCloudOS为代表的社区发行版均先后走上了从基于RedHat到基于上游社区,从内核到全系统的自研道路,并为各厂商商用发行版提供血液。
Linux内核自研一般选取上游的一个相对稳定(LTS)分支,不断增添新的特性和软硬件支持。这样的开发维护过程,在面对上游漏洞的场景下,主要有三方面挑战:
- 版本差异。下游发行版在选定一个固定LTS分支后难以再做底座的整体版本升级,但上游LTS分支仍在持续合入功能和补丁发布小版本,因而随着维护时间拉长,选取的分支与上游差距扩大,上游的漏洞未必存在于下游。反过来,下游分支也会存在从上游更高版本移植特定功能,这些也缺少跟踪。
- 二次开发。除驱动等外围功能,下游社区可能会对某些内核核心代码做定制化,也可能仿制上游模块自研新模块。这些定制一方面缺少与对应来源的跟踪,一方面影响了漏洞的快速判定。
- 响应策略。Linux内核几乎是漏洞新增最频繁的开源项目,下游做逐个漏洞判断、补丁合入与测试,有较大的安全背景研发需求。持续地跟进安全更新也是考验下游社区的关键。
openEuler的分析版本为22.03 LTS,基于上游5.10.0开发分支。在2023年4月的分析中,openEuler以规范化的开发流程,以及优秀的漏洞修复率,在分析中表现优异。尽管如此,仍在当时版本中仍然由Patch2QL自动生成的规则报告数例疑似问题,报告社区后快速响应分析,并确认了2例漏洞。其中一个典型是CVE-2022-1015(社区跟踪标识 openEuler-SA-2023-1253)。原始的 CVE 于2022年3月17日修复,最初于2022年4月29日披露。根据报告,此漏洞仅影响从v5.12-rc1开始的主线内核,补丁应用于5.15、5.16和5.17 LTS内核。当时,人们认为基于5.10上游版本的 openEuler 中的内核不受影响。然而Patch2QL分析结果表明,该漏洞模式与代码完美匹配openEuler以及上游5.10分支对应代码。随后,在2023年4月18日,openEuler 维护者确认了这一报告有效性,并合并了上游主线补丁。直到2023年6月28日,上游社区才将修复程序合入到维护的分支 linux-5.10.y,这中间留下了468天的时间窗口。
公开资源与规划
Patch2QL是一项服务于开源供应链安全的技术,为在开源生态中发挥最大化效能,其产出已由云鼎实验室面向开源生态公开使用。
前述针对关键基础设施类开源项目生成的规则集,已经公开发布在GitHub仓库中。该仓库在不定时对最新关键漏洞更新规则。同时,随着工具本身能力的迭代,规则集整体也可能会存在大幅度更新。
Patch2QL的核心工具当前仍在持续研发迭代中,尚未达到开源发布状态。但是工具本身功能和算法已经在arXiv上论文公开,详细披露了技术细节和更多的实验数据,期待得到学术和工业领域研究者的探讨贡献。
作为服务于操作系统质量保障的工具,当前Patch2QL在持续以Linux内核为重点分析目标,快速迭代规则生成方法,并对某些漏洞的对应补丁,半自动化调整润色规则,以实现更高召回率、更低误报率,并提升规则泛化性,以发现更多潜在同源漏洞。因为仍在不断更新中,这份调整的Linux内核规则集暂未同步更新到前述规则仓库中,如相关研究者与社区开发者有常识需求,欢迎与作者联系。
参考资料:
公开论文地址:https://arxiv.org/abs/2401.12443




)
)
![Node: opensslErrorStack: [ ‘error:03000086:digital envelope routines::initialization error‘ ]异常处理](http://pic.xiahunao.cn/Node: opensslErrorStack: [ ‘error:03000086:digital envelope routines::initialization error‘ ]异常处理)






![【C++杂货铺】详解类和对象 [下]](http://pic.xiahunao.cn/【C++杂货铺】详解类和对象 [下])
:数码管)



信号和槽)
