Pytorch从零开始实战——人脸图像生成
本系列来源于365天深度学习训练营
原作者K同学
文章目录
- Pytorch从零开始实战——人脸图像生成
- 环境准备
- 模型定义
- 开始训练
- 可视化
- 总结
环境准备
本文基于Jupyter notebook,使用Python3.8,Pytorch2.0.1+cu118,torchvision0.15.2,需读者自行配置好环境且有一些深度学习理论基础。本次实验的目的是了解并使用DCGAN模型,完成人脸图生成。
第一步,导入常用包
import torch, random, random, os
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
import torchvision
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
os.environ['KMP_DUPLICATE_LIB_OK']='True' # 用于避免jupyter环境突然关闭
torch.backends.cudnn.benchmark=True # 用于加速GPU运算的代码
设置随机数种子
torch.manual_seed(428)
torch.cuda.manual_seed(428)
torch.cuda.manual_seed_all(428)
random.seed(428)
np.random.seed(428)
检查设备对象
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device, torch.cuda.device_count()
设置超参数,其中数据集源于K同学
dataroot = "./data/face" # 数据路径
batch_size = 128 # 训练过程中的批次大小
image_size = 64 # 图像的尺寸(宽度和高度)
nz = 100 # z潜在向量的大小(生成器输入的尺寸)
ngf = 64 # 生成器中的特征图大小
ndf = 64 # 判别器中的特征图大小
num_epochs = 50 # 训练的总轮数,如果你显卡不太行,可调小,但是生成效果会随之降低
lr = 0.0002 # 学习率
beta1 = 0.5 # Adam优化器的Beta1超参数
使用datasets读取数据
dataset = datasets.ImageFolder(root=dataroot,transform=transforms.Compose([transforms.Resize(image_size), # 调整图像大小transforms.CenterCrop(image_size), # 中心裁剪图像transforms.ToTensor(), # 将图像转换为张量transforms.Normalize((0.5, 0.5, 0.5), # 标准化图像张量(0.5, 0.5, 0.5)),]))
随机查看五张数据
def plotsample(data):fig, axs = plt.subplots(1, 5, figsize=(10, 10)) #建立子图for i in range(5):num = random.randint(0, len(data) - 1) #首先选取随机数,随机选取五次#抽取数据中对应的图像对象,make_grid函数可将任意格式的图像的通道数升为3,而不改变图像原始的数据#而展示图像用的imshow函数最常见的输入格式也是3通道npimg = torchvision.utils.make_grid(data[num][0]).numpy()nplabel = data[num][1] #提取标签 #将图像由(3, weight, height)转化为(weight, height, 3),并放入imshow函数中读取axs[i].imshow(np.transpose(npimg, (1, 2, 0))) axs[i].set_title(nplabel) #给每个子图加上标签axs[i].axis("off") #消除每个子图的坐标轴plotsample(dataset)

使用dataloader进行批量划分和打乱
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, # 批量大小shuffle=True, # 是否打乱数据集num_workers=5 # 使用多个线程加载数据的工作进程数)
模型定义
深度卷积对抗网络(Deep Convolutional Generative Adversarial Networks, DCGAN)是生成对抗网络的一种模型改进,其将卷积运算的思想引入到生成式模型当中来做无监督的训练,利用卷积网络强大的特征提取能力来提高生成网络的学习效果。
判别器网络和生成器网络: DCGAN包括两个主要部分,即判别器(Discriminator)和生成器(Generator)。判别器负责评估输入图像是真实图像还是生成图像,而生成器则试图生成逼真的图像以欺骗判别器。
卷积层和批量归一化: DCGAN使用卷积神经网络(CNN)作为判别器和生成器的主要组件,以有效地捕捉图像的空间结构。此外,引入批量归一化来稳定训练过程,加速收敛。
生成器输入和输出: 生成器接收一个随机噪声向量作为输入,通过反卷积(或称为转置卷积)操作生成图像。这使得生成器能够从随机噪声中学到数据分布的特征。
判别器的激活函数和损失函数: 判别器使用Leaky ReLU(带有泄漏的修正线性单元)作为激活函数,以防止梯度消失问题。损失函数采用二元交叉熵,用于判断生成图像和真实图像的相似度。
避免全连接层: DCGAN的设计避免使用全连接层,而是主要使用卷积和反卷积层,以减少模型参数,降低过拟合风险。
其中,反卷积核心思想是通过在输入特征图之间插入一些新的值(通常用零填充),使得输出的尺寸比输入更大。
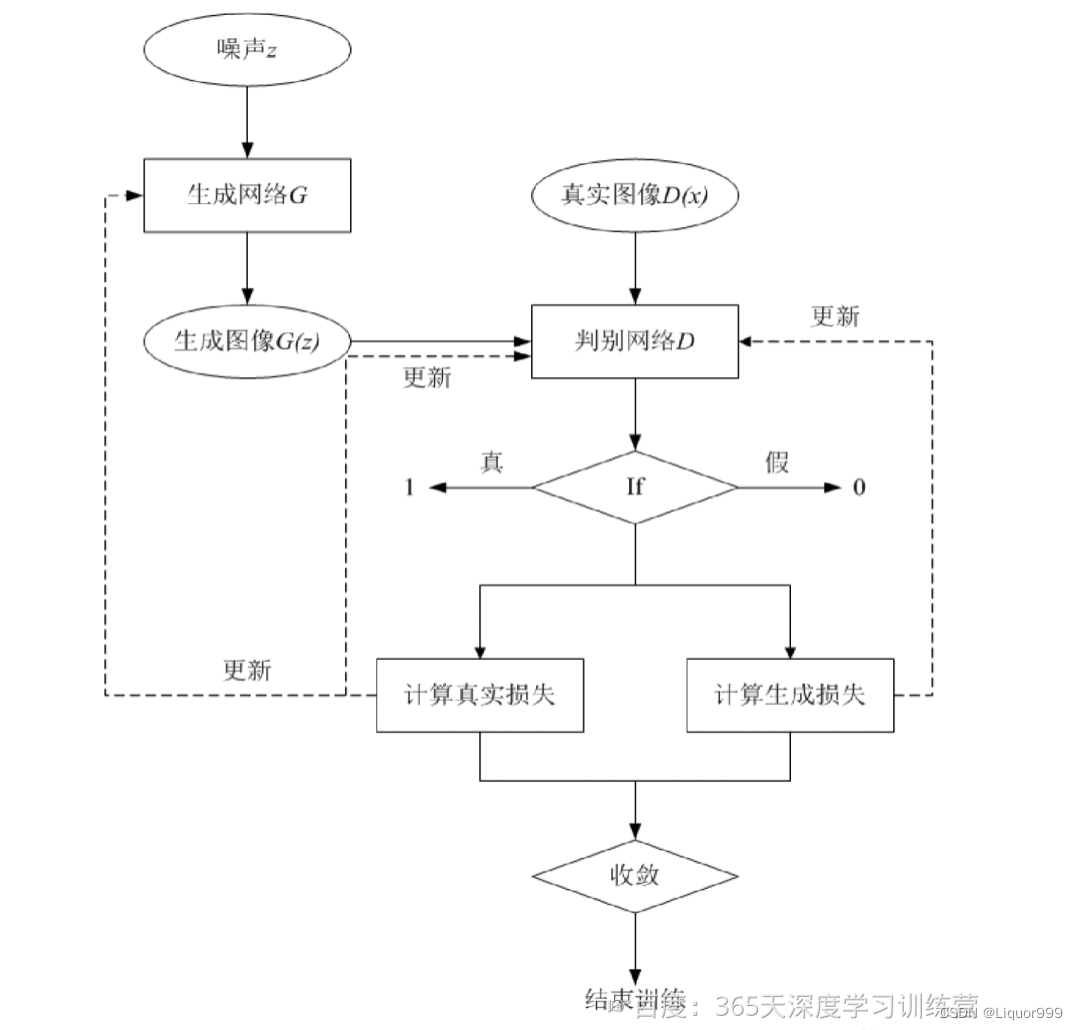
DCGAN模型主要包括了一个生成网络 G 和一个判别网络 D,生成网络 G 负责生成图像,它接受一个随机的噪声z,通过该噪声生成图像,将生成的图像记为G(z),判别网络D负责判别一张图像是否为真实的,它的输入是x,代表一张图像,输出D(x)表示x为真实图像的概率。
实际上判别网络D是对数据的来源进行一个判别:究竟这个数据是来自真实的数据分布Pd(x)判别为“1”),还是来自于一个生成网络G所产生的一个数据分布Pg(z)(判别为“0”)。所以在整个训练过程中,生成网络G的目标是生成可以以假乱真的图像G(z),当判别网络D无法区分,即D(G(z))=0.5时,便得到了一个生成网络G用来生成图像扩充数据集。
初始化权重
# 自定义权重初始化函数,作用于netG和netD
def weights_init(m):# 获取当前层的类名classname = m.__class__.__name__# 如果类名中包含'Conv',即当前层是卷积层if classname.find('Conv') != -1:# 使用正态分布初始化权重数据,均值为0,标准差为0.02nn.init.normal_(m.weight.data, 0.0, 0.02)# 如果类名中包含'BatchNorm',即当前层是批归一化层elif classname.find('BatchNorm') != -1:# 使用正态分布初始化权重数据,均值为1,标准差为0.02nn.init.normal_(m.weight.data, 1.0, 0.02)# 使用常数初始化偏置项数据,值为0nn.init.constant_(m.bias.data, 0)
定义生成器网络
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.main = nn.Sequential(# 输入为Z,经过一个转置卷积层nn.ConvTranspose2d(nz, ngf * 8, 4, 1, 0, bias=False),nn.BatchNorm2d(ngf * 8), # 批归一化层,用于加速收敛和稳定训练过程nn.ReLU(True), # ReLU激活函数# 输出尺寸:(ngf*8) x 4 x 4nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 4),nn.ReLU(True),# 输出尺寸:(ngf*4) x 8 x 8nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 2),nn.ReLU(True),# 输出尺寸:(ngf*2) x 16 x 16nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf),nn.ReLU(True),# 输出尺寸:(ngf) x 32 x 32nn.ConvTranspose2d(ngf, 3, 4, 2, 1, bias=False),nn.Tanh() # Tanh激活函数# 输出尺寸:3 x 64 x 64)def forward(self, input):return self.main(input)netG = Generator().to(device)
netG.apply(weights_init) # 使用 "weights_init" 函数来随机初始化所有权重
print(netG)

定义判别器
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()# 定义判别器的主要结构,使用Sequential容器将多个层按顺序组合在一起self.main = nn.Sequential(# 输入大小为3 x 64 x 64nn.Conv2d(3, ndf, 4, 2, 1, bias=False),nn.LeakyReLU(0.2, inplace=True),# 输出大小为(ndf) x 32 x 32nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 2),nn.LeakyReLU(0.2, inplace=True),# 输出大小为(ndf*2) x 16 x 16nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 4),nn.LeakyReLU(0.2, inplace=True),# 输出大小为(ndf*4) x 8 x 8nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 8),nn.LeakyReLU(0.2, inplace=True),# 输出大小为(ndf*8) x 4 x 4nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),nn.Sigmoid())def forward(self, input):# 将输入通过判别器的主要结构进行前向传播return self.main(input)# 创建判别器模型
netD = Discriminator().to(device)
netD.apply(weights_init) # 使用 "weights_init" 函数来随机初始化所有权重
print(netD)

开始训练
定义损失函数和优化算法
# 损失函数
criterion = nn.BCELoss()# 创建用于可视化生成器进程的潜在向量批次
fixed_noise = torch.randn(64, nz, 1, 1, device=device)real_label = 1.
fake_label = 0.# 为生成器(G)和判别器(D)设置Adam优化器
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
对于每个dataloader中的atch,会进行以下步骤:
1.更新判别器网络: 通过最大化判别器对真实图像和生成图像的损失来训练判别器。这包括计算对真实图像的损失和对生成图像的损失,然后通过梯度反向传播来更新判别器的参数。
2.更新生成器网络: 通过最大化生成器在生成图像上的损失来训练生成器。生成器的目标是欺骗判别器,使其无法区分生成的图像和真实图像。同样,通过梯度反向传播来更新生成器的参数。
3.记录损失值,输出训练统计信息,并定期保存生成器在固定噪声上的输出图像。
img_list = [] # 用于存储生成的图像列表
G_losses = [] # 用于存储生成器的损失列表
D_losses = [] # 用于存储判别器的损失列表
iters = 0 # 迭代次数print("Starting Training Loop...") # 输出训练开始的提示信息
# 对于每个epoch(训练周期)
for epoch in range(num_epochs):# 对于dataloader中的每个batchfor i, data in enumerate(dataloader, 0):############################# (1) 更新判别器网络:最大化 log(D(x)) + log(1 - D(G(z)))############################# 使用真实图像样本训练netD.zero_grad() # 清除判别器网络的梯度# 准备真实图像的数据real_cpu = data[0].to(device)b_size = real_cpu.size(0)label = torch.full((b_size,), real_label, dtype=torch.float, device=device) # 创建一个全是真实标签的张量# 将真实图像样本输入判别器,进行前向传播output = netD(real_cpu).view(-1)# 计算真实图像样本的损失errD_real = criterion(output, label)# 通过反向传播计算判别器的梯度errD_real.backward()D_x = output.mean().item() # 计算判别器对真实图像样本的输出的平均值## 使用生成图像样本训练# 生成一批潜在向量noise = torch.randn(b_size, nz, 1, 1, device=device)# 使用生成器生成一批假图像样本fake = netG(noise)label.fill_(fake_label) # 创建一个全是假标签的张量# 将所有生成的图像样本输入判别器,进行前向传播output = netD(fake.detach()).view(-1)# 计算判别器对生成图像样本的损失errD_fake = criterion(output, label)# 通过反向传播计算判别器的梯度errD_fake.backward()D_G_z1 = output.mean().item() # 计算判别器对生成图像样本的输出的平均值# 计算判别器的总损失,包括真实图像样本和生成图像样本的损失之和errD = errD_real + errD_fake# 更新判别器的参数optimizerD.step()############################# (2) 更新生成器网络:最大化 log(D(G(z)))###########################netG.zero_grad() # 清除生成器网络的梯度label.fill_(real_label) # 对于生成器成本而言,将假标签视为真实标签# 由于刚刚更新了判别器,再次将所有生成的图像样本输入判别器,进行前向传播output = netD(fake).view(-1)# 根据判别器的输出计算生成器的损失errG = criterion(output, label)# 通过反向传播计算生成器的梯度errG.backward()D_G_z2 = output.mean().item() # 计算判别器对生成器输出的平均值# 更新生成器的参数optimizerG.step()# 输出训练统计信息if i % 400 == 0:print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'% (epoch, num_epochs, i, len(dataloader),errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))# 保存损失值以便后续绘图G_losses.append(errG.item())D_losses.append(errD.item())# 通过保存生成器在固定噪声上的输出来检查生成器的性能if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):with torch.no_grad():fake = netG(fixed_noise).detach().cpu()img_list.append(vutils.make_grid(fake, padding=2, normalize=True))iters += 1
可视化
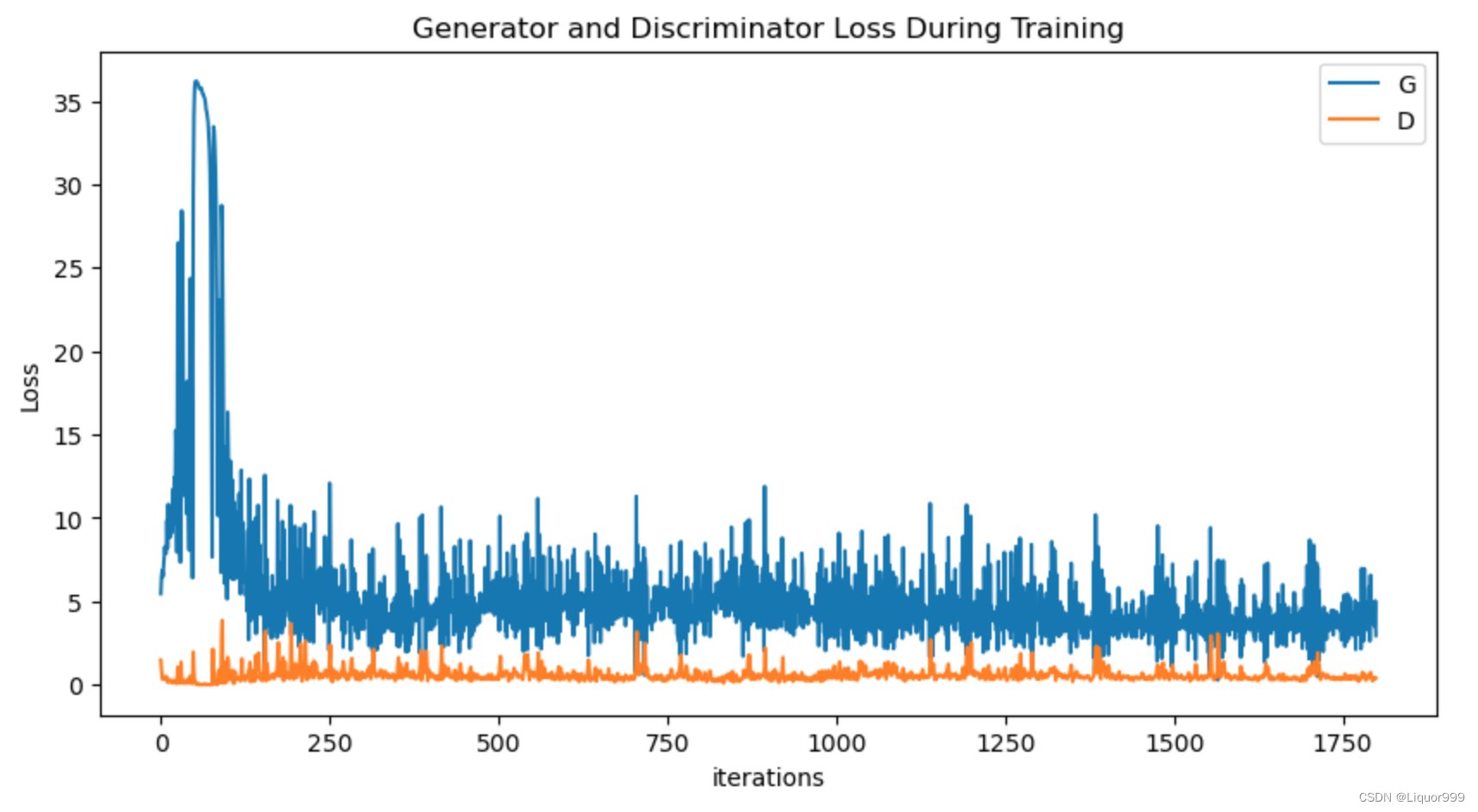
查看训练过程
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
查看生成的图像
# 创建一个大小为8x8的图形对象
fig = plt.figure(figsize=(8, 8))
# 不显示坐标轴
plt.axis("off")
# 将图像列表img_list中的图像转置并创建一个包含每个图像的单个列表ims
ims = [[plt.imshow(np.transpose(i, (1, 2, 0)), animated=True)] for i in img_list]
# 使用图形对象、图像列表ims以及其他参数创建一个动画对象ani
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
# 将动画以HTML形式呈现
HTML(ani.to_jshtml())

对比一下真实图像和生成的图像
# 从数据加载器中获取一批真实图像
real_batch = next(iter(dataloader))# 绘制真实图像
plt.figure(figsize=(15,15))
plt.subplot(1,2,1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),(1,2,0)))# 绘制上一个时期生成的假图像
plt.subplot(1,2,2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1],(1,2,0)))
plt.show()

总结
DCGAN是生成对抗网络的一种应用,包含生成器和判别器,通过对抗训练的方式,使得生成器能够生成逼真的数据,而判别器则学会区分真实数据和生成数据。总之,DCGAN的设计使得生成对抗网络在图像生成领域取得了显著的进展,促进了后续对GAN的研究和发展。

)






)


拷贝List注意事项)






