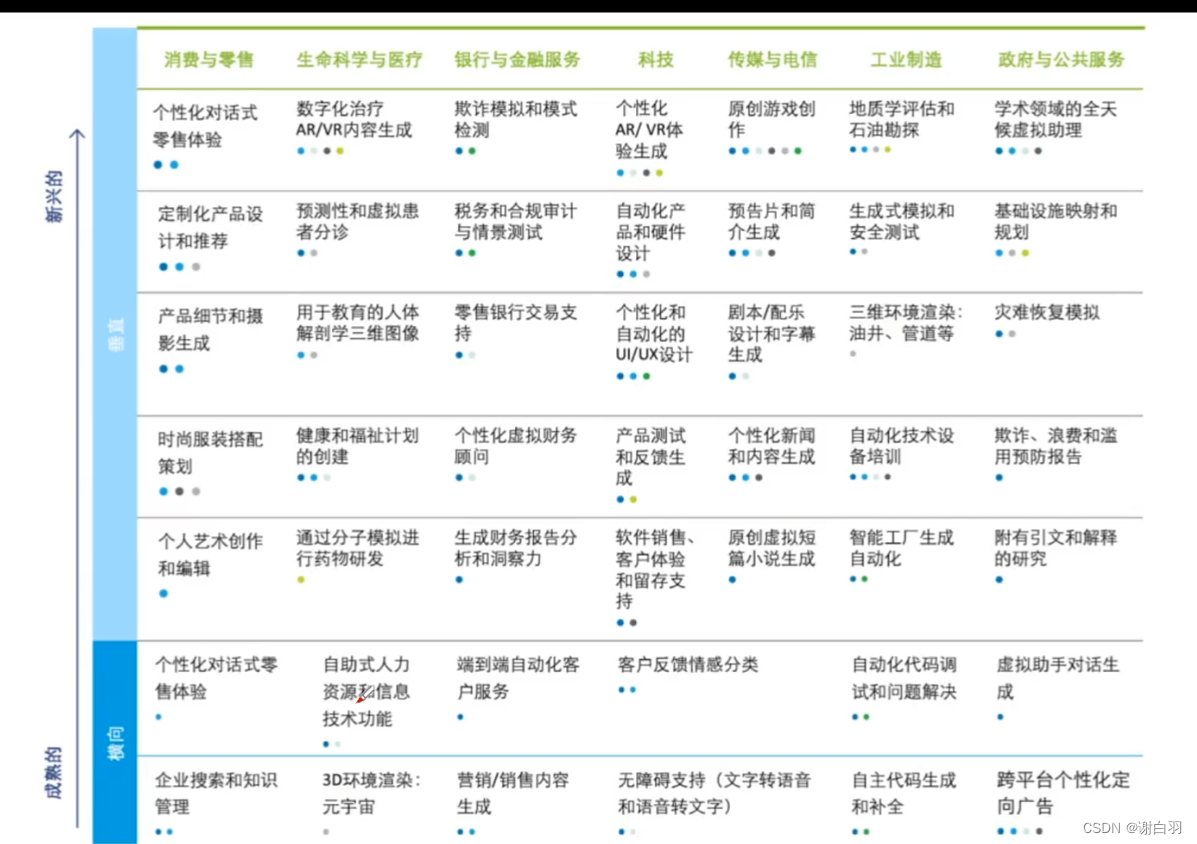
一、商业观点:企业借助大模型获得业务增长可能
二、底层原理:transformer
1)备注
①下面每个步骤都是自回归的过程(aotu-regressive):已输出内容的每个字作为输入,一起生成下一个字
②合起来就是:y1输出之后,y1和x序列一起作为输出,来生成y2;y1和y2加x序列作为输入,来输出y3
③GPT3.5有1750亿参数,也就是1750亿维
2)运行步骤
①把一串输入的字符串拆分成x序列的结构
②再把这串x序列的输入字符串映射成z序列
(z序列是:z1、z2、z3、z4等,不一定必须是512维),每个z是512维坐标的向量,由512个坐标构成
③解码器根据传入的z序列生成y序列
3)编码器框架图
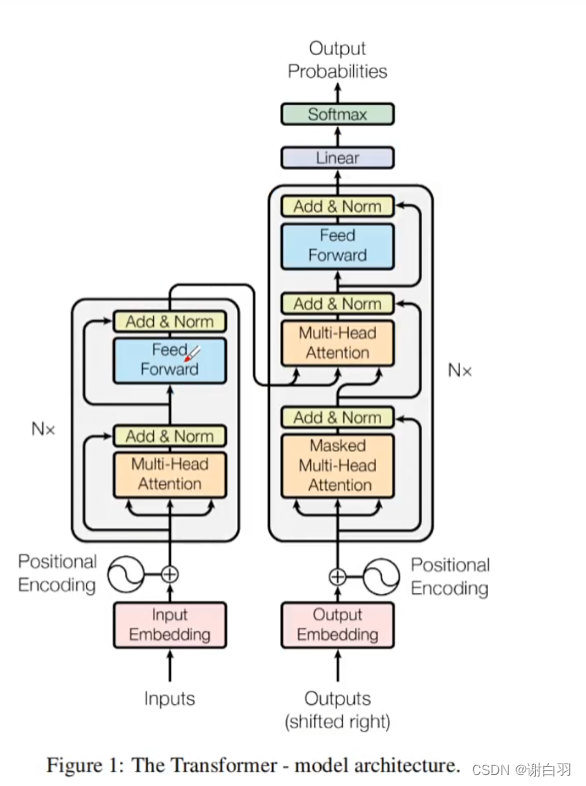
①左边是编码器,右边是解码器
②输入有两个预处理
1)input Embedding:把每个字都变成512个字去描述
2)positionnal Encoding:不仅要把每个字换成512个描述,而是还要关注每个字的位置(也就是关注词的主谓宾)
③linear做类似线性回归的东西
④softmax:把前序所有的计算结果转化成概率数字,有了概率数字才会知道蹦出来的下个数字是什么
⑤注意力机制(attention机制):抓住主要的词汇(每个词的重要程度通过权重数值和权重矩阵体现出来)
⑥self-attention(自注意力模型):不是给某些搜索方向提前标注大权重的词 (从注意到self-attention自注意力机制)
⑦q\k\v三矩阵在做线性代数(q矩阵和k矩阵做了很多点乘和像素计算得到v矩阵):
q:问题
k:固定的二维数组
v:权重数值
三、应用技术:fine tune介绍
1)三层分层
①第一层:
指令编程(不停跟大模型对话总结经验)、AI编程、AI测试
②第二层:
向量数据库、向量检索、langchain、sk、智能体(autogpt这样的东西)
③第三层:
模型定制:fine tune(专业领域就不行了)
2)原理讲解
- 步骤
①收集示范数据(制定了很多prompt)
②收集比较数据,并训练奖励模型(fine tuning)
③使用强化学习针对奖励模型优化策略 - 解释
①fine tune就是对参数小范围的波动微调下
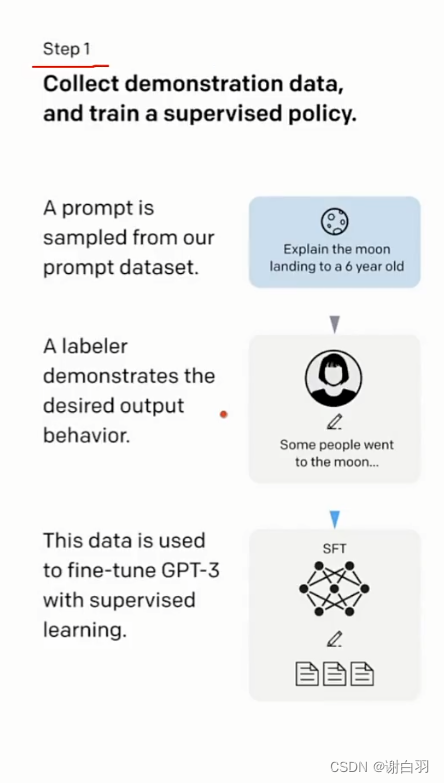
3)中文版原理讲解(第一步只要一次,第二和第三要很多次)
①step 1:
1)组织很多数据(a labeler),就比如说律师的官司一问一答(只做一次)
2)这些数据就是对这些不咋地的数据进行fine tune(模型精调,这些过程叫SFT)
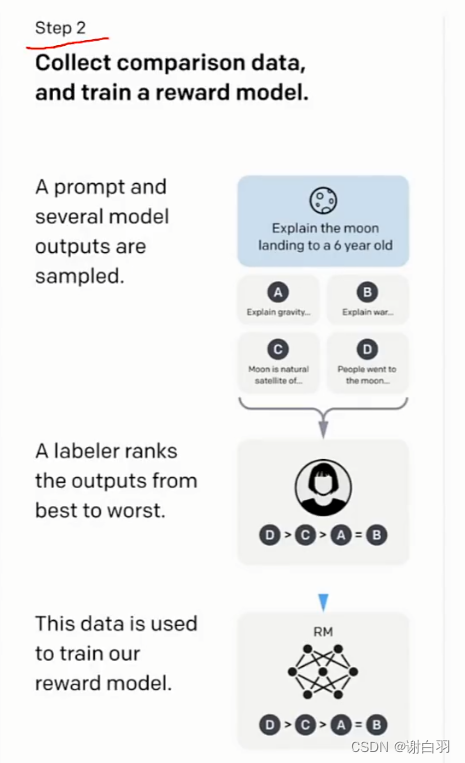
②step2:
根据你的问题排序(rank)之前生成的labelers
③step 3:
能得到人类更好的内容将会得到更多积分,强化学习

链接












)




![[oeasy]python005_退出游乐场_重启游乐场_系统态shell_应用态_quit](http://pic.xiahunao.cn/[oeasy]python005_退出游乐场_重启游乐场_系统态shell_应用态_quit)
)
