文章目录
- HDFS 写数据流程
- HDFS 读数据流程
- HDFS 节点距离计算
- HDFS 机架感知
- HDFS NN和2NN工作机制
- HDFS FsImage镜像文件
- HDFS Edits编辑日志
- HDFS 检查点CheckPoint时间设置
- HDFS 退役旧数据节点
- HDFS DataNode多目录配置
- HDFS DataNode工作机制
- HDFS 数据完整性
- HDFS 掉线时限参数设置
HDFS 写数据流程

(1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
(2)NameNode返回是否可以上传。
(3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
(4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
(5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3逐级应答客户端。
(7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
(8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
HDFS 读数据流程
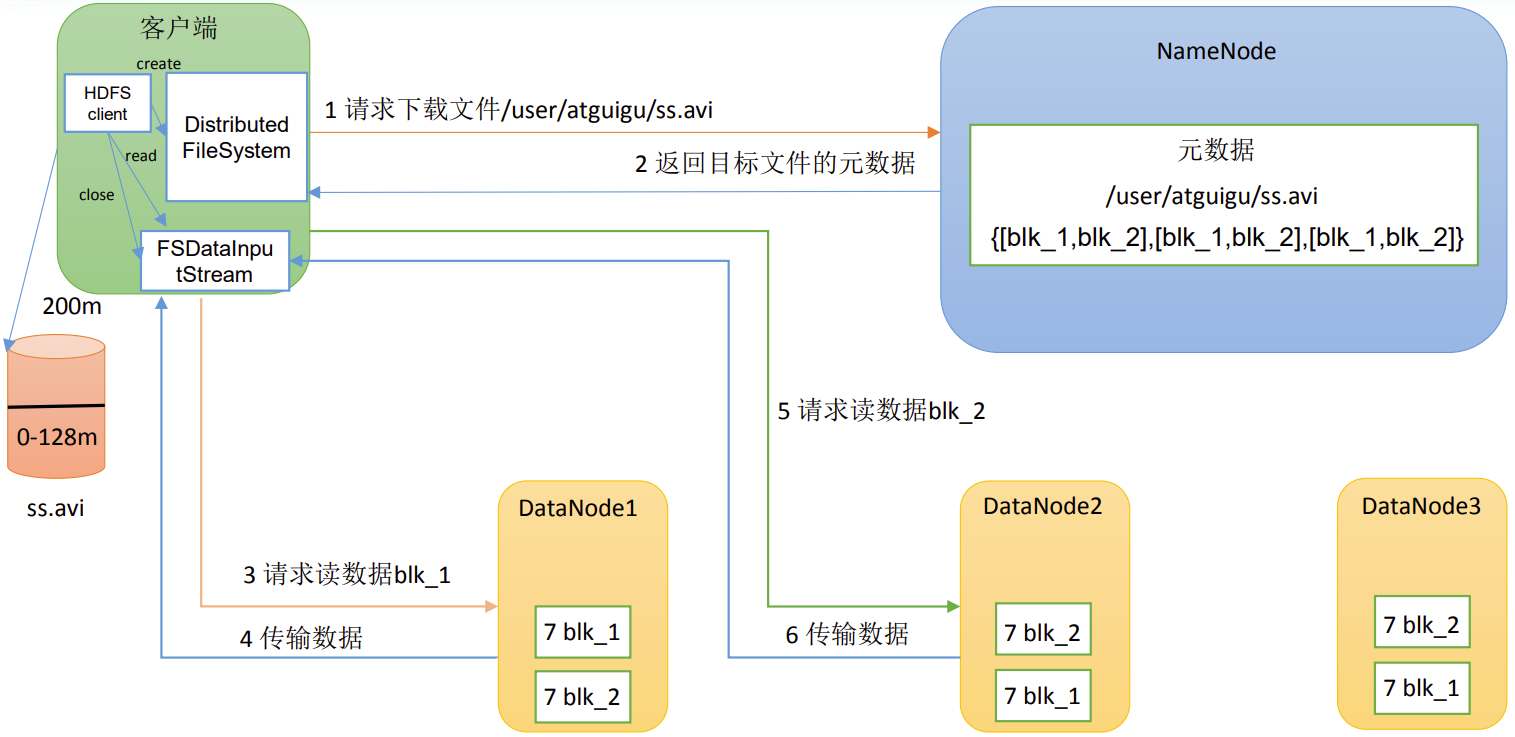
(1)客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
(2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
(3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
(4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
HDFS 节点距离计算
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。

例如,假设有数据中心d1机架r1中的节点n1。该节点可以表示为/d1/r1/n1。利用这种标记,这里给出四种距离描述。
d1/r1/n0 到 d1/r1/n1 的路径: d1/r1/n0 --> d1/r1 --> d1/r1/n1 总共2步
d1/r1/n0 到 d1/r2/n1 的路径: d1/r1/n0 --> d1/r1 --> d1 --> d1/r2 --> d1/r2/n1 总共四步
d1/r1/n0 到 d2/r1/n1 的路径: d1/r1/no --> d1/r1 --> d1 -->路由 --> d2 --> d2/r1 --> d2/r1/n1 总共6步
HDFS 机架感知
Apache Hadoop 3.1.3 – HDFS Architecture

第一个副本在Client所处的节点上;如果客户端在集群外,随机选一个。
第二个副本在另一个机架的随机一个节点。
第三个副本在第二个副本所在机架的随机节点。

HDFS NN和2NN工作机制
思考:NameNode中的元数据是存储在哪里的?
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
元数据信息要保存在哪?
1.1 保存到磁盘
– 不足:读写速度慢 效率低!
1.2 保存内存
– 不足:数据不安全
1.3 最终的解决方案: 磁盘 + 内存内存中的元数据和磁盘中的元数据如何进行同步。(元数据的维护策略)
当我们对元数据进行操作的时候,首先在内存进行合并,其次还要把相关操作记录追加到edits编辑日志文件中,在满足一定条件下,将edits文件中的记录合并到元数据信息文件中 fsimage谁负责对NN的元数据信息进行合并?
2NN主要负责对NN的元数据精心合并,当满足一定条件的下,2NN会检测本地时间,每隔一个小时会主动对NN的edits文件和fsimage文件进行一次合并。合并的时候,首先会通知NN,这时候NN就会停止对正在使用的edits文件的追加,同时会新建一个新的edits编辑日志文件,保证NN的正常工作。接下来 2NN会把NN本地的fsimage文件和edits编辑日志拉取2NN的本地,在内存中对二者进行合并,最后产生最新fsimage文件。把最新的fsimage文件再发送给NN的本地。注意还有一个情况,当NN的edits文件中的操作次数累计达到100万次,即便还没到1小时,2NN(每隔60秒会检测一次NN方的edits文件的操作次数)也会进行合并。
2NN 也会自己把最新的fsimage文件备份一份。

1)第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。
2)第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
NN和2NN工作机制详解:
Fsimage:NameNode内存中元数据序列化后形成的文件。
Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。
由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。
SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了)。直接带回NameNode是否检查结果。SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中。
HDFS FsImage镜像文件
1)oiv查看Fsimage文件
(1)查看oiv和oev命令
hdfsoiv apply the offline fsimage viewer to an fsimageoev apply the offline edits viewer to an edits file(2)基本语法
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
(3)案例实操
pwd
/opt/module/hadoop-3.1.3/data/dfs/name/current
hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-3.1.3/fsimage.xml
cat /opt/module/hadoop-3.1.3/fsimage.xml
cd /opt/module/hadoop-3.1.3
sz fsimage.xml # 下载到本地将显示的xml文件内容拷贝到Idea中创建的xml文件中,并格式化。部分显示结果如下。
<inode><id>16386</id><type>DIRECTORY</type><name>user</name><mtime>1512722284477</mtime><permission>xu1an:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota>
</inode>
<inode><id>16387</id><type>DIRECTORY</type><name>xu1an</name><mtime>1512790549080</mtime><permission>xu1an:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota>
</inode>
<inode><id>16389</id><type>FILE</type><name>wc.input</name><replication>3</replication><mtime>1512722322219</mtime><atime>1512722321610</atime><perferredBlockSize>134217728</perferredBlockSize><permission>xu1an:supergroup:rw-r--r--</permission><blocks><block><id>1073741825</id><genstamp>1001</genstamp><numBytes>59</numBytes></block></blocks>
</inode >思考:可以看出,Fsimage中没有记录块所对应DataNode,为什么?
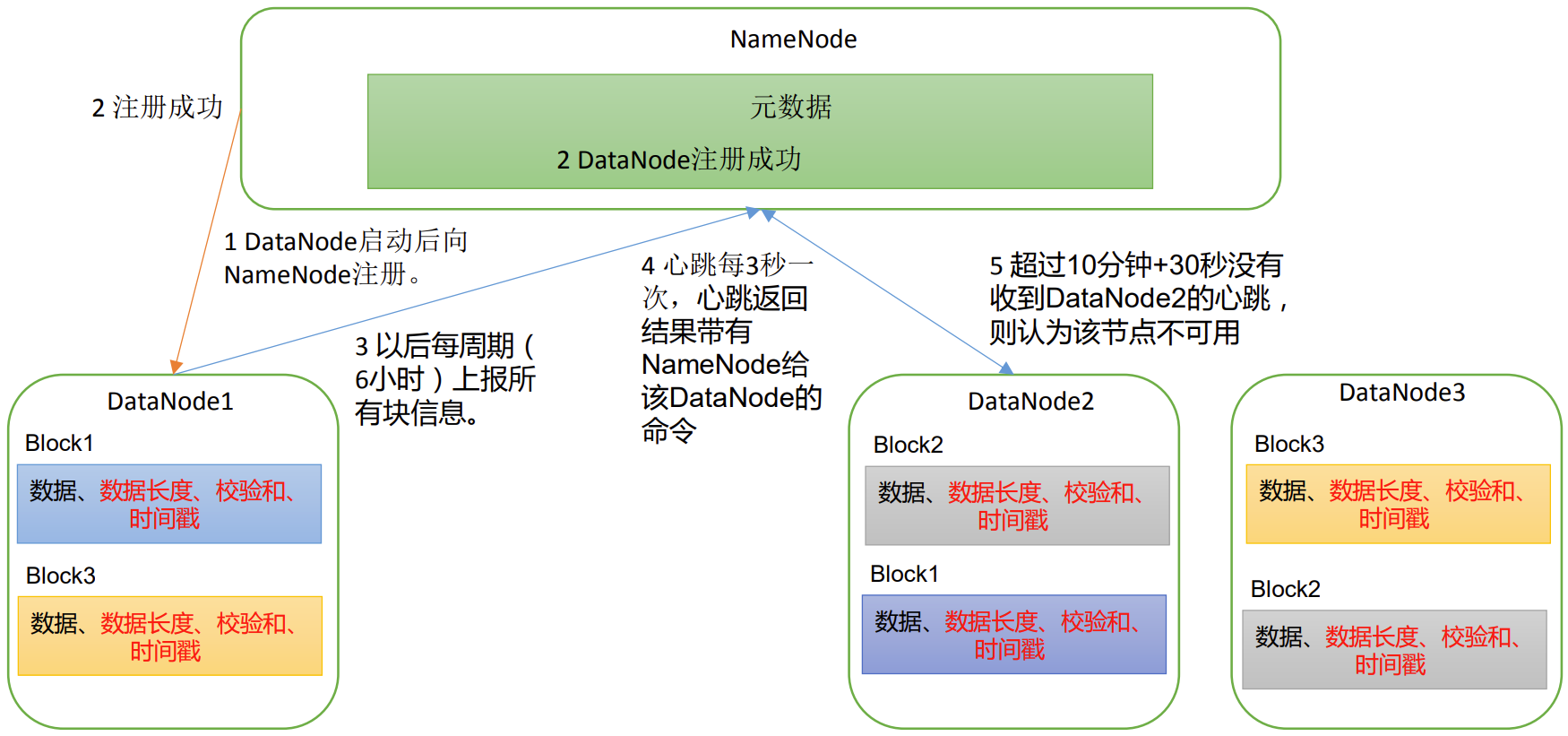
在集群启动后,要求DataNode上报数据块信息,并间隔一段时间后再次上报。
HDFS Edits编辑日志
2)oev查看Edits文件
(1)基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
(2)案例实操
hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-3.1.3/edits.xml
cat /opt/module/hadoop-3.1.3/edits.xml将显示的xml文件内容拷贝到Idea中创建的xml文件中,并格式化。显示结果如下。
<?xml version="1.0" encoding="UTF-8"?>
<EDITS><EDITS_VERSION>-63</EDITS_VERSION><RECORD><OPCODE>OP_START_LOG_SEGMENT</OPCODE><DATA><TXID>129</TXID></DATA></RECORD><RECORD><OPCODE>OP_ADD</OPCODE><DATA><TXID>130</TXID><LENGTH>0</LENGTH><INODEID>16407</INODEID><PATH>/hello7.txt</PATH><REPLICATION>2</REPLICATION><MTIME>1512943607866</MTIME><ATIME>1512943607866</ATIME><BLOCKSIZE>134217728</BLOCKSIZE><CLIENT_NAME>DFSClient_NONMAPREDUCE_-1544295051_1</CLIENT_NAME><CLIENT_MACHINE>192.168.1.5</CLIENT_MACHINE><OVERWRITE>true</OVERWRITE><PERMISSION_STATUS><USERNAME>atguigu</USERNAME><GROUPNAME>supergroup</GROUPNAME><MODE>420</MODE></PERMISSION_STATUS><RPC_CLIENTID>908eafd4-9aec-4288-96f1-e8011d181561</RPC_CLIENTID><RPC_CALLID>0</RPC_CALLID></DATA></RECORD><RECORD><OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE><DATA><TXID>131</TXID><BLOCK_ID>1073741839</BLOCK_ID></DATA></RECORD><RECORD><OPCODE>OP_SET_GENSTAMP_V2</OPCODE><DATA><TXID>132</TXID><GENSTAMPV2>1016</GENSTAMPV2></DATA></RECORD><RECORD><OPCODE>OP_ADD_BLOCK</OPCODE><DATA><TXID>133</TXID><PATH>/hello7.txt</PATH><BLOCK><BLOCK_ID>1073741839</BLOCK_ID><NUM_BYTES>0</NUM_BYTES><GENSTAMP>1016</GENSTAMP></BLOCK><RPC_CLIENTID></RPC_CLIENTID><RPC_CALLID>-2</RPC_CALLID></DATA></RECORD><RECORD><OPCODE>OP_CLOSE</OPCODE><DATA><TXID>134</TXID><LENGTH>0</LENGTH><INODEID>0</INODEID><PATH>/hello7.txt</PATH><REPLICATION>2</REPLICATION><MTIME>1512943608761</MTIME><ATIME>1512943607866</ATIME><BLOCKSIZE>134217728</BLOCKSIZE><CLIENT_NAME></CLIENT_NAME><CLIENT_MACHINE></CLIENT_MACHINE><OVERWRITE>false</OVERWRITE><BLOCK><BLOCK_ID>1073741839</BLOCK_ID><NUM_BYTES>25</NUM_BYTES><GENSTAMP>1016</GENSTAMP></BLOCK><PERMISSION_STATUS><USERNAME>atguigu</USERNAME><GROUPNAME>supergroup</GROUPNAME><MODE>420</MODE></PERMISSION_STATUS></DATA></RECORD>
</EDITS >思考:NameNode如何确定下次开机启动的时候合并哪些Edits?
HDFS 检查点CheckPoint时间设置
CheckPoint时间设置
1)通常情况下,SecondaryNameNode每隔一小时执行一次。
[hdfs-default.xml]
<property><name>dfs.namenode.checkpoint.period</name><value>3600s</value>
</property>2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property><name>dfs.namenode.checkpoint.txns</name><value>1000000</value>
<description>操作动作次数</description>
</property><property><name>dfs.namenode.checkpoint.check.period</name><value>60s</value>
<description> 1分钟检查一次操作次数</description>
</property >HDFS 退役旧数据节点
添加白名单和黑名单
白名单和黑名单是hadoop管理集群主机的一种机制。
添加到白名单的主机节点,都允许访问NameNode,不在白名单的主机节点,都会被退出。添加到黑名单的主机节点,不允许访问NameNode,会在数据迁移后退出。
实际情况下,白名单用于确定允许访问NameNode的DataNode节点,内容配置一般与workers文件内容一致。 黑名单用于在集群运行过程中退役DataNode节点。
配置白名单和黑名单的具体步骤如下:
1)在NameNode节点的/opt/module/hadoop-3.1.3/etc/hadoop目录下分别创建whitelist 和blacklist文件
pwd
/opt/module/hadoop-3.1.3/etc/hadoop
touch whitelist
touch blacklist在whitelist中添加如下主机名称,假如集群正常工作的节点为102 103 104 105
hadoop102
hadoop103
hadoop104
hadoop105
2)在hdfs-site.xml配置文件中增加dfs.hosts和 dfs.hosts.exclude配置参数
<!-- 白名单 -->
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/whitelist</value>
</property>
<!-- 黑名单 -->
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>3)分发配置文件whitelist,blacklist,hdfs-site.xml (注意:105节点也要发一份)
my_rsync hadoop/
rsync -av hadoop/ xu1an@hadoop105:/opt/module/hadoop-3.1.3/etc/hadoop/
4)重新启动集群(注意:105节点没有添加到workers,因此要单独起停)
[hadoop102 hadoop-3.1.3]$ stop-dfs.sh
[hadoop102 hadoop-3.1.3]$ start-dfs.sh
[hadoop105 hadoop-3.1.3]$ hdfs –daemon start datanode
5)在web浏览器上查看目前正常工作的DN节点
2.4.2 黑名单退役
1)编辑/opt/module/hadoop-3.1.3/etc/hadoop目录下的blacklist文件
[@hadoop102 hadoop] vim blacklist
添加如下主机名称(要退役的节点)
hadoop1052)分发blacklist到所有节点
[@hadoop102 etc]$ my_rsync hadoop/
[@hadoop102 etc]$ rsync -av hadoop/ atguigu@hadoop105:/opt/module/hadoop-3.1.3/etc/hadoop/3)刷新NameNode、刷新ResourceManager
[@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful[@hadoop102 hadoop-3.1.3]$ yarn rmadmin -refreshNodes
17/06/24 14:55:56 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:80334)检查Web浏览器,退役节点的状态为decommission in progress(退役中),说明数据节点正在复制块到其他节点
5)等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役
[@hadoop105 hadoop-3.1.3]$ hdfs --daemon stop datanode
[@hadoop105 hadoop-3.1.3]$ yarn --daemon stop nodemanager
6)如果数据不均衡,可以用命令实现集群的再平衡
[@hadoop102 hadoop-3.1.3]$ sbin/start-balancer.sh
starting balancer, logging to /opt/module/hadoop-3.1.3/logs/hadoop-atguigu-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved注意:不允许白名单和黑名单中同时出现同一个主机名称,既然使用了黑名单blacklist成功退役了hadoop105节点,因此要将白名单whitelist里面的hadoop105去掉。
白名单退役编辑whitelist
hadoop102
hadoop103
hadoop104HDFS DataNode多目录配置
1)DataNode可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本
2)具体配置如下
(1)在hdfs-site.xml文件中添加如下内容
<property><name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value>
</property>(2)停止集群,删除三台节点的data和logs中所有数据。
[@hadoop102 hadoop-3.1.3]$ rm -rf data/ logs/
[@hadoop103 hadoop-3.1.3]$ rm -rf data/ logs/
[@hadoop104 hadoop-3.1.3]$ rm -rf data/ logs/(3)格式化集群并启动。
[@hadoop102 hadoop-3.1.3]$ bin/hdfs namenode –format
[@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh(4)查看结果
[@hadoop102 dfs]$ ll
其他节点
5)等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役
[@hadoop105 hadoop-3.1.3]$ hdfs --daemon stop datanode
[@hadoop105 hadoop-3.1.3]$ yarn --daemon stop nodemanager6)如果数据不均衡,可以用命令实现集群的再平衡
[@hadoop102 hadoop-3.1.3]$ sbin/start-balancer.sh
starting balancer, logging to /opt/module/hadoop-3.1.3/logs/hadoop-atguigu-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved注意:不允许白名单和黑名单中同时出现同一个主机名称,既然使用了黑名单blacklist成功退役了hadoop105节点,因此要将白名单whitelist里面的hadoop105去掉。
白名单退役编辑whitelist
hadoop102
hadoop103
hadoop104HDFS DataNode工作机制
HDFS 数据完整性
数据完整性
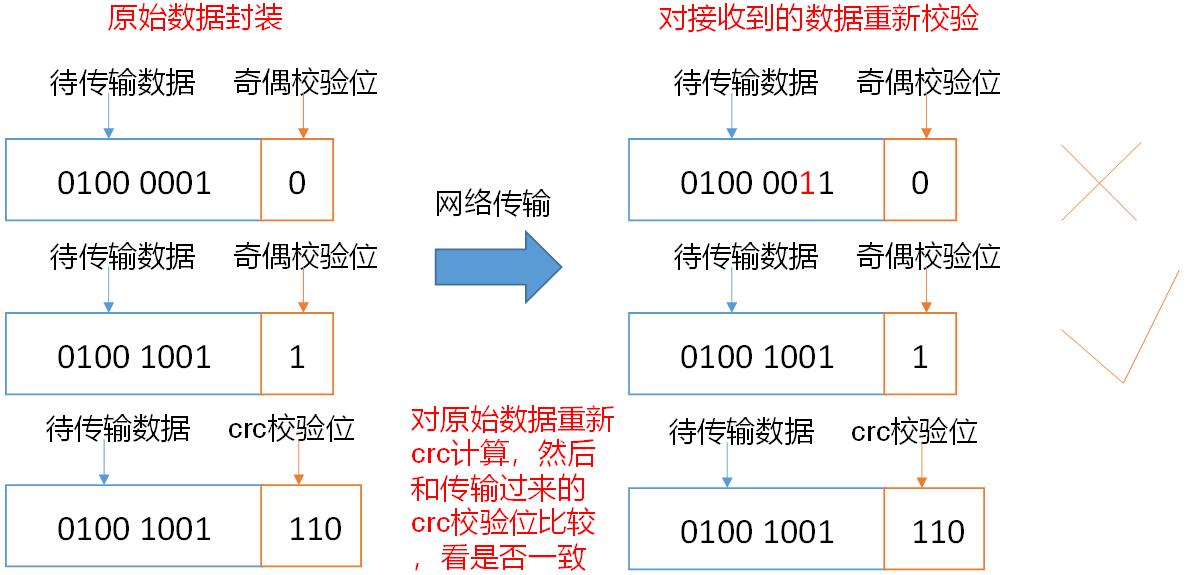
思考:如果电脑磁盘里面存储的数据是控制高铁信号灯的红灯信号(1)和绿灯信号(0),但是存储该数据的磁盘坏了,一直显示是绿灯,是否很危险?同理DataNode节点上的数据损坏了,却没有发现,是否也很危险,那么如何解决呢?
如下是DataNode节点保证数据完整性的方法。
(1)当DataNode读取Block的时候,它会计算CheckSum。
(2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
(3)Client读取其他DataNode上的Block。
(4)常见的校验算法crc(32),md5(128),sha1(160)
(5)DataNode在其文件创建后周期验证CheckSum。
CRC(循环冗余校验)在线计算_ip33.com
HDFS 掉线时限参数设置



![[oeasy]python005_退出游乐场_重启游乐场_系统态shell_应用态_quit](http://pic.xiahunao.cn/[oeasy]python005_退出游乐场_重启游乐场_系统态shell_应用态_quit)
)


:核心内容与学习收获(附大会核心PPT下载))

)

详解)



)




