HashMap 的原理
HashMap 的内部可以看做数组+链表的复合结构。数组被分为一个个的桶(bucket)。哈希值决定了键值对在数组中的寻址。具有相同哈希值的键值对会组成链表。需要注意的是当链表长度超过阈值(默认是8)的时候会触发树化,链表会变成树形结构。
把握HashMap的原理需要关注4个方法:hash、put、get、resize。
hash方法。 将 key 的 hashCode 值的高位数据移位到低位进行异或运算。这么做的原因是有些 key 的 hashCode 值的差异集中在高位,而哈希寻址是忽略容量以上高位的,这种做法可以有效避免哈希冲突。
put 方法。put 方法主要有以下几个步骤:
1、通过 hash 方法获取 hash 值,根据 hash 值寻址。
2、如果未发生碰撞,直接放到桶中。
3、如果发生碰撞,则以链表形式放在桶后。
4、当链表长度大于阈值后会触发树化,将链表转换为红黑树。
5、如果数组长度达到阈值,会调用 resize 方法扩展容量。
get方法。get 方法主要有以下几个步骤:
1、通过 hash 方法获取 hash 值,根据 hash 值寻址。
2、如果与寻址到桶的 key 相等,直接返回对应的 value。
3、如果发生冲突,分两种情况。如果是树,则调用 getTreeNode 获取 value;如果是链表则通过循环遍历查找对应的 value。
resize 方法。resize 做了两件事:
将原数组扩展为原来的 2 倍
重新计算 index 索引值,将原节点重新放到新的数组中。这一步可以将原先冲突的节点分散到新的桶中。
LruCache的原理
LruCache 的核心原理就是对 LinkedHashMap 的有效利用,它的内部存在一个 LinkedHashMap 成员变量。值得我们关注的有四个方法:构造方法、get、put、trimToSize。
构造方法: 在 LruCache 的构造方法中做了两件事,设置了 maxSize、创建了一个 LinkedHashMap。这里值得注意的是 LruCache 将 LinkedHashMap的accessOrder 设置为了 true,accessOrder 就是遍历这个LinkedHashMap 的输出顺序。true 代表按照访问顺序输出,false代表按添加顺序输出,因为通常都是按照添加顺序输出,所以 accessOrder 这个属性默认是 false,但我们的 LruCache 需要按访问顺序输出,所以显式的将 accessOrder 设置为 true。
get方法: 本质上是调用 LinkedHashMap 的 get 方法,由于我们将 accessOrder 设置为了 true,所以每调用一次get方法,就会将我们访问的当前元素放置到这个LinkedHashMap的尾部。
put方法: 本质上也是调用了 LinkedHashMap 的 put 方法,由于 LinkedHashMap 的特性,每调用一次 put 方法,也会将新加入的元素放置到 LinkedHashMap 的尾部。添加之后会调用 trimToSize 方法来保证添加后的内存不超过 maxSize。
trimToSize方法: trimToSize 方法的内部其实是开启了一个 while(true)的死循环,不断的从 LinkedHashMap 的首部删除元素,直到删除之后的内存小于 maxSize 之后使用 break 跳出循环。
其实到这里我们可以总结一下,为什么这个算法叫 最近最少使用 算法呢?原理很简单,我们的每次 put 或者get都可以看做一次访问,由于 LinkedHashMap 的特性,会将每次访问到的元素放置到尾部。当我们的内存达到阈值后,会触发 trimToSize 方法来删除 LinkedHashMap 首部的元素,直到当前内存小于 maxSize。为什么删除首部的元素,原因很明显:我们最近经常访问的元素都会放置到尾部,那首部的元素肯定就是 最近最少使用 的元素了,因此当内存不足时应当优先删除这些元素。
DiskLruCache原理
设计一个图片的异步加载框架
设计一个图片加载框架,肯定要用到图片加载的三级缓存的思想。三级缓存分为内存缓存、本地缓存和网络缓存。
内存缓存:将Bitmap缓存到内存中,运行速度快,但是内存容量小。
本地缓存:将图片缓存到文件中,速度较慢,但容量较大。
网络缓存:从网络获取图片,速度受网络影响。
如果我们设计一个图片加载框架,流程一定是这样的:
1、拿到图片url后首先从内存中查找Bitmap,如果找到直接加载。
2、内存中没有找到,会从本地缓存中查找,如果本地缓存可以找到,则直接加载。
3、内存和本地都没有找到,这时会从网络下载图片,下载到后会加载图片,并且将下载到的图片放到内存缓存和本地缓存中。
上面是一些基本的概念,如果是具体的代码实现的话,大概需要这么几个方面的文件:
1、首先需要确定我们的内存缓存,这里一般用的都是 LruCache。
2、确定本地缓存,通常用的是 DiskLruCache,这里需要注意的是图片缓存的文件名一般是 url 被 MD5 加密后的字符串,为了避免文件名直接暴露图片的 url。
3、内存缓存和本地缓存确定之后,需要我们创建一个新的类 MemeryAndDiskCache,当然,名字随便起,这个类包含了之前提到的 LruCache 和 DiskLruCache。在 MemeryAndDiskCache 这个类中我们定义两个方法,一个是 getBitmap,另一个是 putBitmap,对应着图片的获取和缓存,内部的逻辑也很简单。getBitmap中按内存、本地的优先级去取 BItmap,putBitmap 中先缓存内存,之后缓存到本地。
4、在缓存策略类确定好之后,我们创建一个 ImageLoader 类,这个类必须包含两个方法,一个是展示图片 displayImage(url,imageView),另一个是从网络获取图片downloadImage(url,imageView)。在展示图片方法中首先要通过 ImageView.setTag(url),将 url 和 imageView 进行绑定,这是为了避免在列表中加载网络图片时会由于ImageView的复用导致的图片错位的 bug。之后会从 MemeryAndDiskCache 中获取缓存,如果存在,直接加载;如果不存在,则调用从网络获取图片这个方法。从网络获取图片方法很多,这里我一般都会使用 OkHttp+Retrofit。当从网络中获取到图片之后,首先判断一下imageView.getTag()与图片的 url 是否一致,如果一致则加载图片,如果不一致则不加载图片,通过这样的方式避免了列表中异步加载图片的错位。同时在获取到图片之后会通过 MemeryAndDiskCache 来缓存图片。
SparseArray 原理
SparseArray,通常来讲是 Android 中用来替代 HashMap 的一个数据结构。 准确来讲,是用来替换key为 Integer 类型,value为Object 类型的HashMap。需要注意的是 SparseArray 仅仅实现了 Cloneable 接口,所以不能用Map来声明。 从内部结构来讲,SparseArray 内部由两个数组组成,一个是 int[]类型的 mKeys,用来存放所有的键;另一个是 Object[]类型的 mValues,用来存放所有的值。 最常见的是拿 SparseArray 跟HashMap 来做对比,由于 SparseArray 内部组成是两个数组,所以占用内存比 HashMap 要小。我们都知道,增删改查等操作都首先需要找到相应的键值对,而 SparseArray 内部是通过二分查找来寻址的,效率很明显要低于 HashMap 的常数级别的时间复杂度。提到二分查找,这里还需要提一下的是二分查找的前提是数组已经是排好序的,没错,SparseArray 中就是按照key进行升序排列的。 综合起来来说,SparseArray 所占空间优于 HashMap,而效率低于 HashMap,是典型的时间换空间,适合较小容量的存储。 从源码角度来说,我认为需要注意的是 SparseArray的remove()、put()和 gc()方法。
1、remove()。 SparseArray 的 remove() 方法并不是直接删除之后再压缩数组,而是将要删除的 value 设置为 DELETE 这个 SparseArray 的静态属性,这个 DELETE 其实就是一个 Object 对象,同时会将 SparseArray 中的 mGarbage 这个属性设置为 true,这个属性是便于在合适的时候调用自身的 gc()方法压缩数组来避免浪费空间。这样可以提高效率,如果将来要添加的key等于删除的key,那么会将要添加的 value 覆盖 DELETE。
2、gc()。 SparseArray 中的 gc() 方法跟 JVM 的 GC 其实完全没有任何关系。``gc()` 方法的内部实际上就是一个for循环,将 value 不为 DELETE 的键值对往前移动覆盖value 为DELETE的键值对来实现数组的压缩,同时将 mGarbage 置为 false,避免内存的浪费。
3、put()。 put 方法是这么一个逻辑,如果通过二分查找 在 mKeys 数组中找到了 key,那么直接覆盖 value 即可。如果没有找到,会拿到与数组中与要添加的 key 最接近的 key 索引,如果这个索引对应的 value 为 DELETE,则直接把新的 value 覆盖 DELET 即可,在这里可以避免数组元素的移动,从而提高了效率。如果 value 不为 DELETE,会判断 mGarbage,如果为 true,则会调用 gc()方法压缩数组,之后会找到合适的索引,将索引之后的键值对后移,插入新的键值对,这个过程中可能会触发数组的扩容。
RecyclerView与ListView 对比:缓存机制
-
层级不同:RecyclerView比ListView多两级缓存,支持多个离屏ItemView缓存,支持开发者自定义缓存处理逻辑,支持所有RecyclerView共用同一个RecyclerViewPool(缓存池)。
具体来说:
ListView(两级缓存):
RecyclerView(四级缓存):
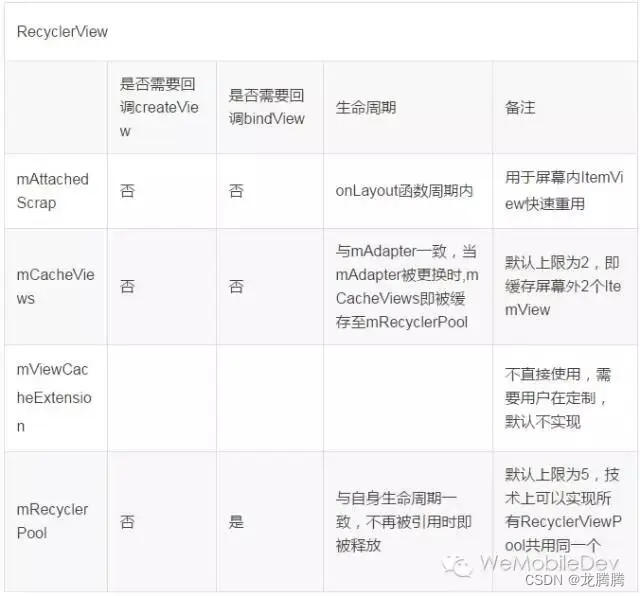
ListView和RecyclerView缓存机制基本一致:
1). mActiveViews和mAttachedScrap功能相似,意义在于快速重用屏幕上可见的列表项ItemView,而不需要重新createView和bindView;2). mScrapView和mCachedViews + mReyclerViewPool功能相似,意义在于缓存离开屏幕的ItemView,目的是让即将进入屏幕的ItemView重用.
3). RecyclerView的优势在于a.mCacheViews的使用,可以做到屏幕外的列表项ItemView进入屏幕内时也无须bindView快速重用;b.mRecyclerPool可以供多个RecyclerView共同使用,在特定场景下,如viewpaper+多个列表页下有优势.客观来说,RecyclerView在特定场景下对ListView的缓存机制做了补强和完善。 -
缓存不同:
1). RecyclerView缓存RecyclerView.ViewHolder,抽象可理解为:View + ViewHolder(避免每次createView时调用findViewById) + flag(标识状态);2). ListView缓存View。
数据库的事务:事务(Transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元(unit)。

)



)
)

---@在bash中的作用---positional parameter详解)



)



—概述需要掌握的内容)


