目录
单机改集群注意事项
问题
思考
建议
单机改集群注意事项
之前是使用的单机版,但后面查询压力过大,一个方案是改成集群。
由于是同一个集群的,元数据没有变化,所以,直接将原本的kylin使用scp的方式发送到其他节点即可。hive客户端也是,也要保证有hbase、zookeeper等。
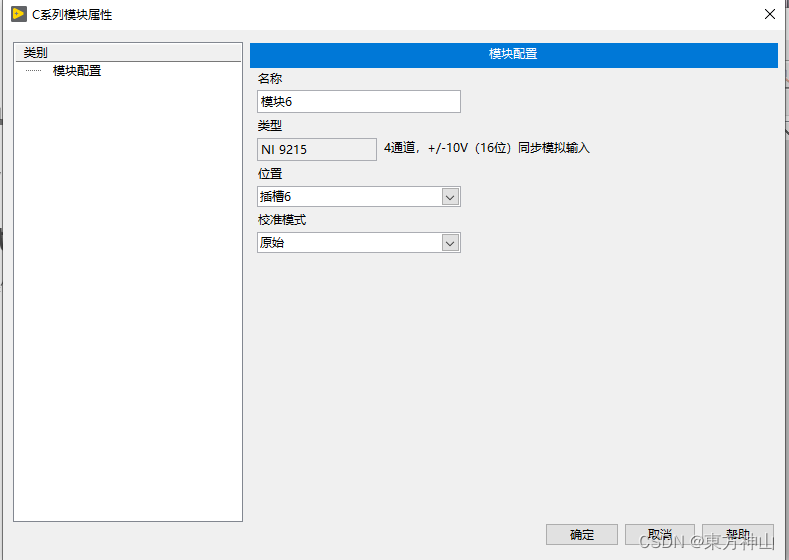
需要修改的配置如下(截图官网):

下面说一下需要注意的地方。
- -name '*jackson*',需要加在find-hive-dependency.sh和find-spark-dependency.sh里面,不然就会导致kylin启动出问题。
- 还有一点,我看了很多其他博客,都没写一点,每台的kylin.env.zookeeper-base-path=这个配置必须修改为不同的路径。不然会出现读取加锁错误。(这里有些不同,我测了几个版本。部分需要改路径,部分不用改。如果出现报错再改吧)
我在第一台设置的kylin.server.mode=job,第二台配置的kylin.server.mode=all,第三台配置了第二台配置的kylin.server.mode=query
所以我在第一台查询就出现了:
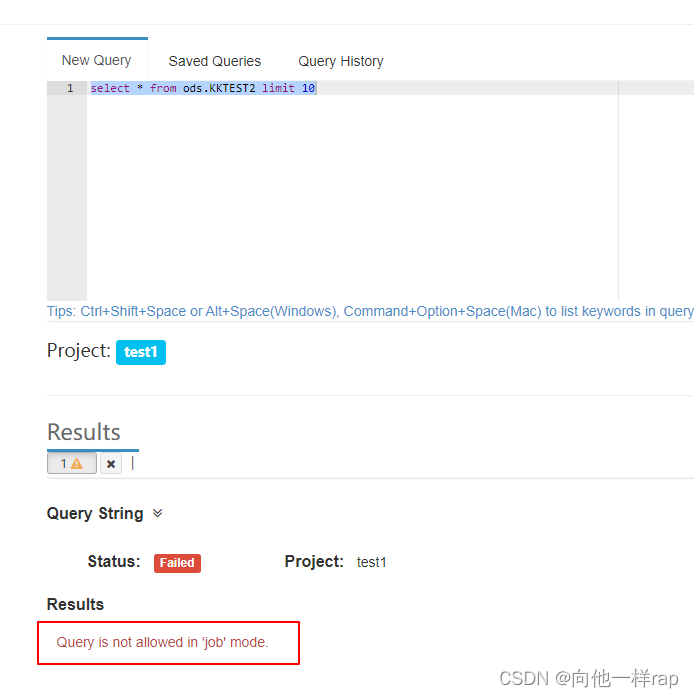
而构建cube在每一台都可以。
问题
由于第三台设置的query,所以构建cube时,不会出现Built By XXX@第三台ip。只可能在第一、第二台进行built。
我试过很多次,构建分别在第一台第二台都测试过,我发现如下
- 设置kylin.server.mode=job 在上面进行built的几率比kylin.server.mode=all大。
思考
- 这是配置原因吗?让job>all
- 不是配置原因,是根据负载均衡原因,但我没配置这些啊,而且两台资源相当。
- kylin有个自己的选择算法,选择合适的机器上面进行cube构建。
建议
不要设置job,只设置query,all。多数query,少数all。毕竟使用kylin,更多是用的查询,构建放少数机器上即可。而且yarn也不可能给你分配很多队列,让你一个节点构建cube进入一个队列。
请看下篇,kylin集群使用nginx代理:
kylin集群使用nginx反向代理-CSDN博客文章浏览阅读2次。由于是同一个集群的,元数据没有变化,所以,直接将原本的kylin使用scp的方式发送到其他节点即可。说明一下,192.168.200.12是我nginx的安装的节点,192.168.200.11、192.168.200.12、192.168.200.13是我3台kylin安装的节点,7070是kylin端口。对于多个节点的查询,我需要进行一下优化,所以我最终选用了nginx,对3台kylin进行了反向代理。分别运行这段代码3次,发现两次成功,成功访问到了kylin的数据,一次失败。https://blog.csdn.net/qq_40209679/article/details/135526638?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22135526638%22%2C%22source%22%3A%22qq_40209679%22%7D
后面将持续更新和修改kylin集群部分,遇到问题欢迎留言,谢谢。






![[UI5] ODATA V4中的CRUD](https://img-blog.csdnimg.cn/direct/00d16da0cf4b44aa9b1d6efdb7eed8f5.png)