leetcode-28 实现strStr()
更熟悉的字符串匹配算法可能是KMP算法, 但在Golang中,使用的是Rabin–Karp算法
一般中文译作 拉宾-卡普算法,由迈克尔·拉宾与理查德·卡普于1987年提出
“要在一段文本中找出单个模式串的一个匹配,此算法具有线性时间的平均复杂度,其运行时间与待匹配文本和模式串的长度成线性关系。虽然平均情况下,此算法表现优异,但最坏情况下,其复杂度为文本长与模式串长的乘积
尽可能多的利用上一步的结果,这是优化时间复杂度的一大核心
对于数字类型的字符串,可有如下匹配方法:
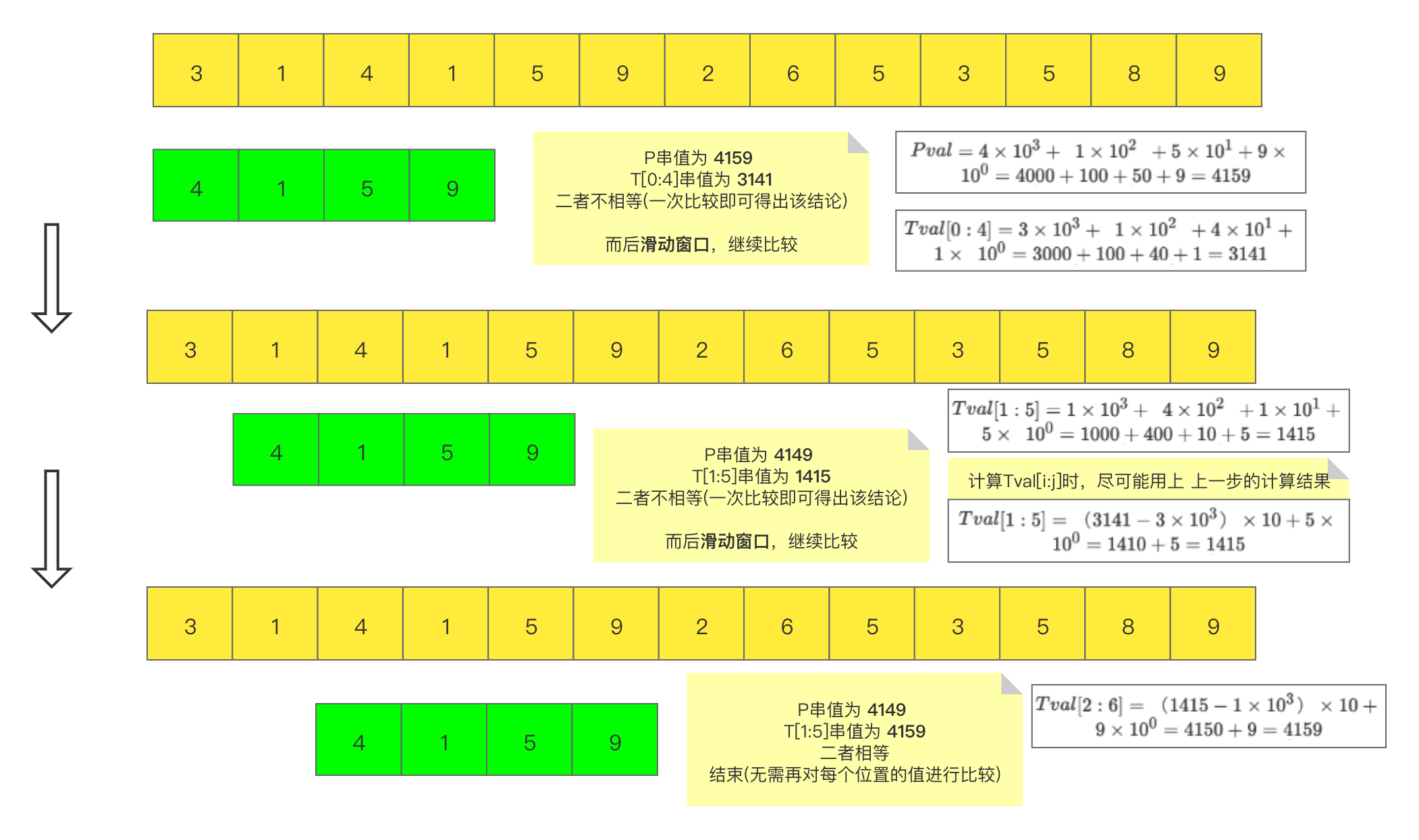
将该方法扩展到非数字类型的字符串:

$$\begin{gather}
对于长度为n的字符串 x_{0} x_{1} x_{2} ... x_{n-1},\\其对应的“值”val为\\
val = x_{0} \times r^{n-1} + x_{1}\times r^{n-2} + ... + x_{n-1}\times r^{0}
\\其中r为进制数\end{gather}$
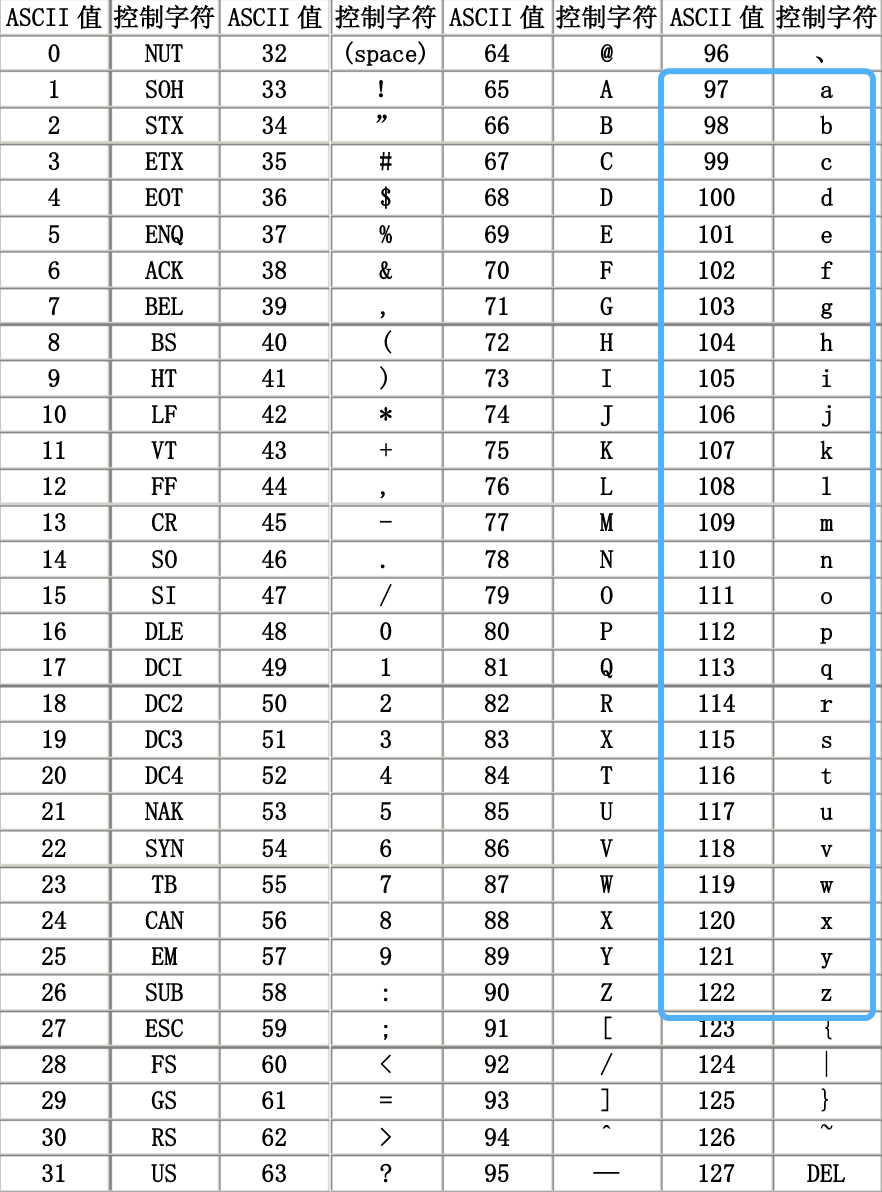
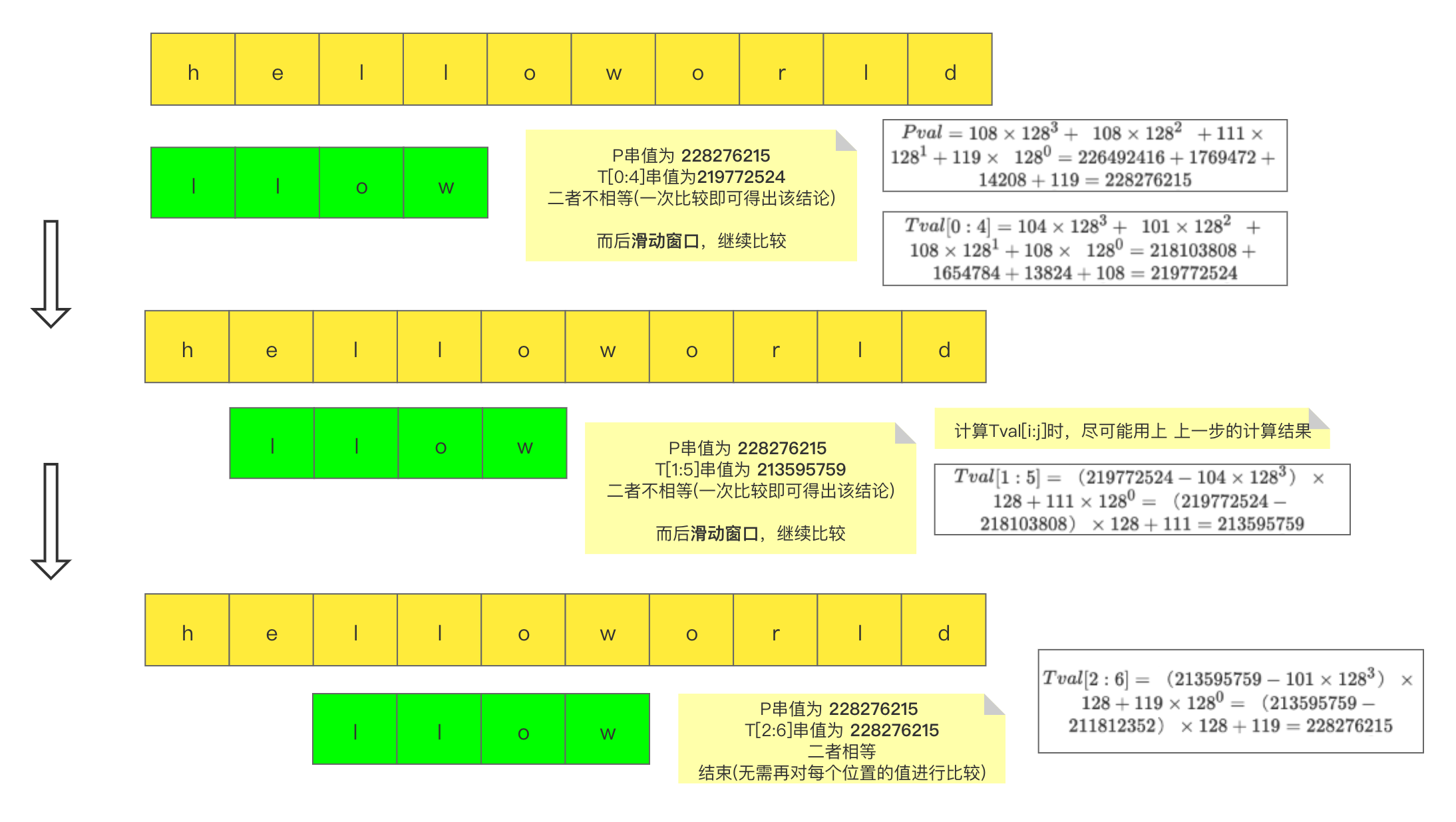
ASCII:英语字符与二进制位之间的关系 (其他语言??)
Unicode:将世界上所有的符号都纳入其中, 每个符号都对应一个独一无二的编码,最多可以容纳1114112个字符(2021年9月公布的14.0.0,已经收录超过14万个字符) (有个问题是浪费空间。。) 也译作统一码/万国码/国际码
UTF-8: 使用最广的一种 Unicode 的实现方式 (最大特点是 变长的编码方式)
字符编码笔记:ASCII,Unicode 和 UTF-8
中日韩汉字Unicode编码表
源码注释:
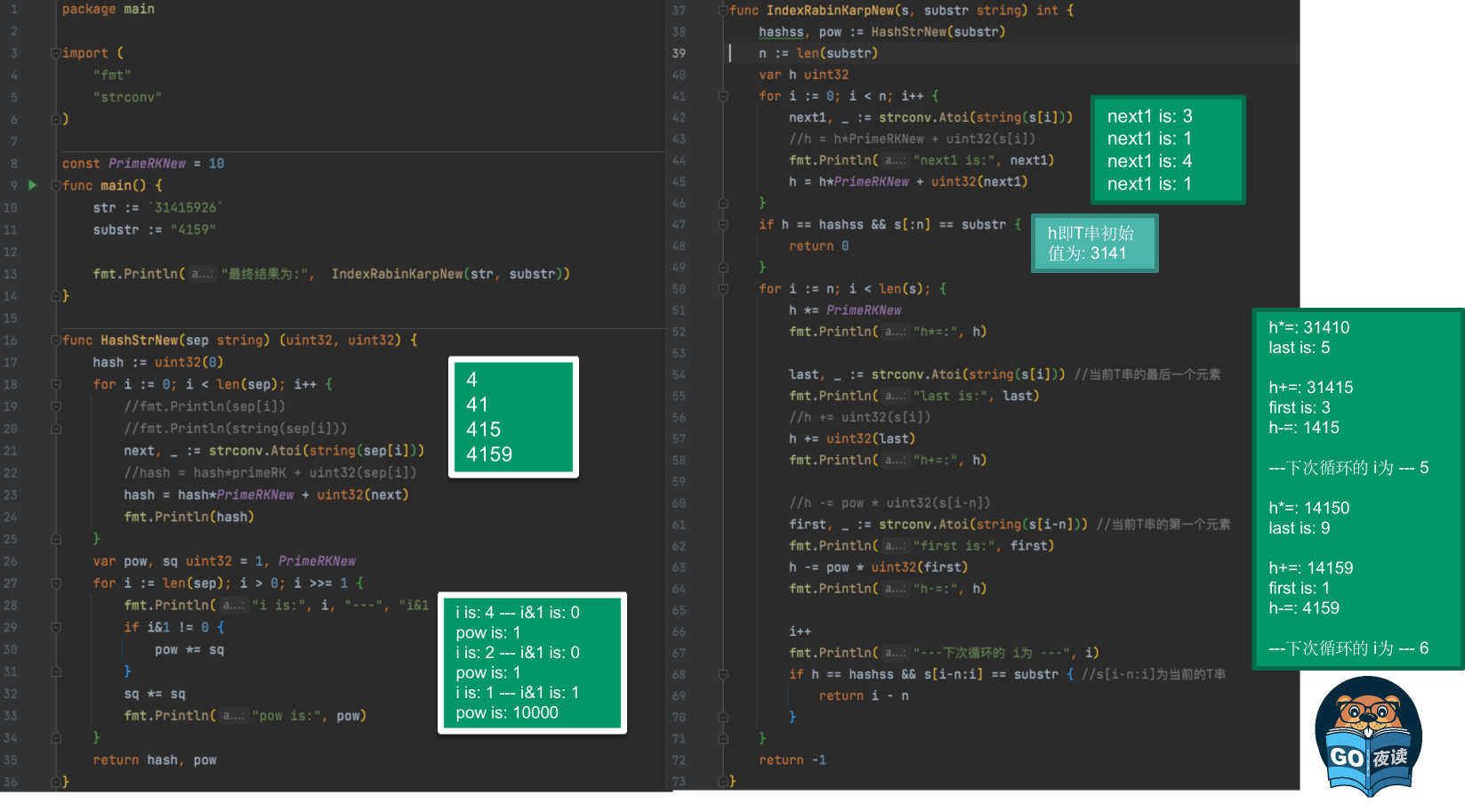
将源码中的16777619进制改为10进制,从字符串31415926中搜索4159:
4159
package main
import (
"fmt"
"strconv"
)
func main() {
var primeRK uint32 = 10
sep := "4159"
hash := uint32(0)
for i := 0; i < len(sep); i++ {
//fmt.Println(sep[i])
//fmt.Println(string(sep[i]))
next, _ := strconv.Atoi(string(sep[i]))
//hash = hash*primeRK + uint32(sep[i])
hash = hash*primeRK + uint32(next)
fmt.Println(hash)
}
}
输出为:
4
41
415
4159
完整的以10为primeRK,从31415926中搜索4159的代码:
package main
import (
"fmt"
"strconv"
)
const PrimeRKNew = 10
func main() {
str := `31415926`
substr := "4159"
fmt.Println("最终结果为:", IndexRabinKarpNew(str, substr))
}
func HashStrNew(sep string) (uint32, uint32) {
hash := uint32(0)
for i := 0; i < len(sep); i++ {
//fmt.Println(sep[i])
//fmt.Println(string(sep[i]))
next, _ := strconv.Atoi(string(sep[i]))
//hash = hash*primeRK + uint32(sep[i])
hash = hash*PrimeRKNew + uint32(next)
fmt.Println(hash)
}
var pow, sq uint32 = 1, PrimeRKNew
for i := len(sep); i > 0; i >>= 1 {
fmt.Println("i is:", i, "---", "i&1 is:", i&1)
if i&1 != 0 {
pow *= sq
}
sq *= sq
fmt.Println("pow is:", pow)
}
return hash, pow
}
func IndexRabinKarpNew(s, substr string) int {
// Rabin-Karp search
hashss, pow := HashStrNew(substr)
fmt.Println("hashss, pow:", hashss, pow)
fmt.Println("~~~分割线~~~")
n := len(substr)
var h uint32
for i := 0; i < n; i++ {
next1, _ := strconv.Atoi(string(s[i]))
//h = h*PrimeRKNew + uint32(s[i])
fmt.Println("next1 is:", next1)
h = h*PrimeRKNew + uint32(next1)
}
fmt.Println("h即T串初始值为:", h)
if h == hashss && s[:n] == substr {
return 0
}
for i := n; i < len(s); {
h *= PrimeRKNew
fmt.Println("h*=:", h)
last, _ := strconv.Atoi(string(s[i])) //当前T串的最后一个元素
fmt.Println("last is:", last)
//h += uint32(s[i])
h += uint32(last)
fmt.Println("h+=:", h)
//h -= pow * uint32(s[i-n])
first, _ := strconv.Atoi(string(s[i-n])) //当前T串的第一个元素
fmt.Println("first is:", first)
h -= pow * uint32(first)
fmt.Println("h-=:", h)
i++
fmt.Println("---下次循环的 i为 ---", i)
if h == hashss && s[i-n:i] == substr { //s[i-n:i]为当前的T串
return i - n
}
}
return -1
}
输出为:
4
41
415
4159
i is: 4 --- i&1 is: 0
pow is: 1
i is: 2 --- i&1 is: 0
pow is: 1
i is: 1 --- i&1 is: 1
pow is: 10000
hashss, pow: 4159 10000
~~~分割线~~~
next1 is: 3
next1 is: 1
next1 is: 4
next1 is: 1
h即T串初始值为: 3141
h*=: 31410
last is: 5
h+=: 31415
first is: 3
h-=: 1415
---下次循环的 i为 --- 5
h*=: 14150
last is: 9
h+=: 14159
first is: 1
h-=: 4159
---下次循环的 i为 --- 6
最终结果为: 2
strings.Contains()源码阅读暨internal/bytealg初探
书籍推荐
柔性字符串匹配
牛刀小试:
力扣28. 实现strStr()
力扣187. 重复的DNA序列
力扣686. 重复叠加字符串匹配
另:
除去KMP和RK算法,字符串匹配还有 Boyer-Moore算法(简称BM算法)系列算法,其核心思想是:
“在字符串匹配过程中,模式串发现不匹配时,跳过尽可能多的字符以进行下一步的匹配,从而提高匹配效率
BM算法的简化版Horspool算法
以及性能更好的Sunday算法
Python用的也不是KMP,而是boyer-moore和horspool, 源码点此
KMP 算法的实际应用有哪些?
图解字符串匹配之Horspool算法和Boyer-Moore算法
本文由 mdnice 多平台发布


)

)


漏洞CVE-2020-5421)




![服务器安装 anaconda 及 conda: command not found [解决方案]](http://pic.xiahunao.cn/服务器安装 anaconda 及 conda: command not found [解决方案])
利用opencv调用鼠标事件在图像上绘制图形)

)



