文章目录
- 前言
- 0、论文摘要
- 一、Introduction
- 1.1目标问题
- 1.2相关的尝试
- 1.3本文贡献
- 二.相关工作
- 2.1优势
- 三.本文方法——抽象概括的对比学习框架
- 3.1 第一阶段:候选生成
- 3.2 第二阶段:无参考评估
- 3.3对比训练
- 四 实验效果
- 4.1数据集
- 4.2 对比模型
- 4.3实施细节
- 4.4评估指标
- 4.5 实验结果
- 4.6 细粒度分析
- 4.6.1 实体级
- 4.6.2 句子级
- 4.7 XSum 数据集的结果
- 五 总结
前言

SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization(2106)
code
0、论文摘要
在本文中,我们提出了一个概念上简单但经验上强大的抽象概括框架 SIMCLS,它可以通过将文本生成作为参考来弥合当前占主导地位的序列到序列学习框架所产生的学习目标和评估指标之间的差距-对比学习辅助的自由评估问题(即质量估计)。
实验结果表明,通过对现有顶级评分系统进行微小修改,SimCLS 可以大幅提高现有顶级模型的性能。特别是,在 CNN/DailyMail 数据集上,ROUGE-1 相对于 BART(Lewis 等人,2020)有 2.51 的绝对提升,比 PEGASUS(Zhang 等人,2020a)有 2.50 的绝对提升,将最先进的性能推向了新的水平。
一、Introduction
1.1目标问题
序列到序列(Seq2Seq)神经模型(Sutskever et al., 2014)已广泛用于语言生成任务,例如抽象摘要(Nallapati et al., 2016)和神经机器翻译(Wu et al., 2016) )。虽然抽象模型(Lewis et al., 2020;Zhang et al., 2020a)在摘要任务中显示出巨大的潜力,但它们也面临着广泛认可的 Seq2Seq 模型训练的挑战。具体来说,Seq2Seq 模型通常在最大似然估计 (MLE) 框架下进行训练,并且在实践中,它们通常使用教师强制(Williams 和Zipser,1989)算法。这在目标函数和评估指标之间引入了差距,因为目标函数基于局部、令牌级预测,而评估指标(例如 ROUGE(Lin,2004))将比较黄金参考和系统之间的整体相似性输出。此外,在测试阶段,模型需要自回归生成输出,这意味着前面步骤中产生的误差将会累积。训练和测试之间的这种差距在之前的工作中被称为暴露偏差(Bengio et al., 2015; Ranzato et al., 2016)。
1.2相关的尝试
主要方法(Paulus 等人,2018 年;Li 等人,2019 年)提出使用强化学习(RL)范式来弥补上述差距。虽然强化学习训练可以根据全局预测并与评估指标密切相关的奖励来训练模型,但它引入了深度强化学习的常见挑战。具体来说,基于强化学习的训练面临着噪声梯度估计(Greensmith et al., 2004)问题,这通常使得训练变得不那么容易。稳定且对超参数敏感。作为替代方案,最小风险训练也被用于语言生成任务中(Shen 等人,2016;Wieting 等人,2019)。然而,估计损失的准确性受到采样输出数量的限制。其他方法(Wiseman 和 Rush,2016;Norouzi 等,2016;Edunov 等,2018)旨在扩展 MLE 的框架,将句子级分数纳入目标函数。虽然这些方法可以减轻 MLE 训练的局限性,但其方法中使用的评估指标和目标函数之间的关系可能是间接和隐式的。
1.3本文贡献
在此背景下,在这项工作中,我们概括了对比学习的范式(Chopra et al., 2005),引入了一种抽象概括的方法,该方法达到了用相应的评估指标直接优化模型的目标,从而缩小了训练之间的差距MLE 训练中的和测试阶段。虽然一些相关工作(Lee et al., 2021; Pan et al., 2021)提出引入对比损失作为条件文本生成任务的 MLE 训练的增强,但我们选择将对比损失和 MLE 的功能分开通过在我们提出的框架的不同阶段引入它们来减少损失。
具体来说,受到Zhong等人最近工作的启发。 (2020);刘等人。 (2021b)关于文本摘要,我们建议使用两阶段模型进行抽象摘要,其中首先训练 Seq2Seq 模型以生成具有 MLE 损失的候选摘要,然后训练参数化评估模型以对比对比对生成的候选进行排序学习。通过在不同阶段优化生成模型和评估模型,我们能够通过监督学习来训练这两个模块,从而绕过基于强化学习方法的具有挑战性和复杂的优化过程。
我们在这项工作中的主要贡献是通过提出一种具有对比学习的生成然后评估两阶段框架来实现抽象摘要的面向度量的训练,这不仅将 CNN/DailyMail 上的最先进性能提升到了新的水平水平(2.2 ROUGE-1相对于基线模型的改进)也展示了这个两阶段框架的巨大潜力,呼吁未来努力使用超越最大似然估计的方法来优化Seq2Seq模型。
总之,我们的贡献如下:
二.相关工作
2.1优势
三.本文方法——抽象概括的对比学习框架
给定源文档 D 和参考摘要 ˆ S,抽象摘要模型 f 的目标是生成候选摘要 S = f (D),使其获得由下式分配的最高分数 m = M (S, ˆ S)评估指标 M 。
在这项工作中,我们将整体生成过程分为两个阶段,其中包括用于生成候选摘要的生成模型 g 和用于评分和选择最佳候选的评估模型 h。图 1 说明了总体框架。
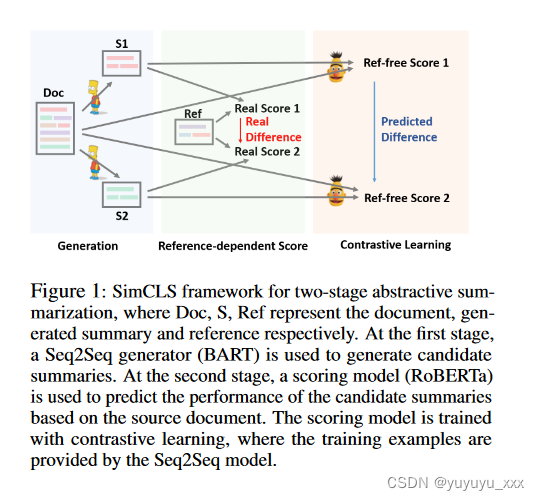
3.1 第一阶段:候选生成
生成模型 g(·) 是一个 Seq2Seq 模型,经过训练以最大化给定源文档 D 的参考摘要 ˆ S 的可能性。然后使用预训练的 g(·) 生成多个候选摘要 S1, ···,Sn采用Beam Search等采样策略,其中n是采样候选者的数量。
3.2 第二阶段:无参考评估
高级思想是更好的候选摘要 Si 应该获得相对于源文档 D 更高的质量分数。
我们通过对比学习来实现上述思想,并定义一个评估函数 h(·),旨在分配不同的分数 r1,···· , rn 仅根据源文档与候选 Si 之间的相似度生成候选,即 ri = h(Si, D)。最终输出摘要S是得分最高的候选者:
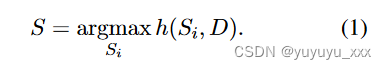
在这里,我们将 h(·) 实例化为一个大型预训练自注意力模型 RoBERTa(Liu et al., 2019)。用于分别对Si和D进行编码,第一个token的编码之间的余弦相似度作为相似度得分ri。
3.3对比训练
大多数现有的对比学习工作都采用了明确构建正面或负面的例子(Chen et al., 2020; Wu et al., 2020),这里的“对比性”反映在评估的自然生成摘要的不同质量中通过参数化模型 h(·)。具体来说,我们向 h(·) 引入排名损失:
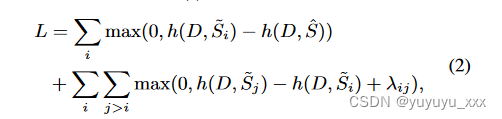
其中 ̃ S1, · · · , ̃ Sn 按 M( ̃ Si, ˆ S) 降序排序。这里, λij = (j −i)*λ 是我们根据Zhong等人定义的相应边距。 (2020),λ是一个超参数。1 M 可以是任何自动评估指标或人类判断,这里我们使用 ROUGE (Lin, 2004)。
四 实验效果
4.1数据集
我们使用两个数据集进行实验。数据集统计数据列于附录 A。 CNNDM CNN/DailyMail2 (Hermann et al., 2015; Nallapati et al., 2016) 数据集是一个大规模新闻文章数据集。 XSum XSum3(Narayan 等人,2018)数据集是一个高度抽象的数据集,包含来自英国广播公司(BBC)的在线文章。
4.2 对比模型
4.3实施细节
由于我们的两阶段框架中的生成模型和评估模型是分开训练的,因此我们使用预先训练的最先进的抽象摘要系统作为我们的生成模型。具体来说,我们使用 BART (Lewis et al., 2020) 和 Pegasus (Zhang et al., 2020a),因为它们很受欢迎并且已经过全面评估。
对于基线系统,我们使用 Transformers4(Wolf 等人,2020)库提供的检查点。我们使用多样化波束搜索(Vijayakumar et al., 2016)作为采样策略来生成候选摘要。我们使用 16 个组进行多样性抽样,从而产生 16 个候选者。为了训练评估模型,我们使用 Adam 优化器(Kingma 和 Ba,2015)和学习率调度。验证集上的模型性能用于选择检查点。附录 B 中描述了更多详细信息。
4.4评估指标
我们使用 ROUGE-1/2/L (R-1/2/L) 作为我们实验的主要评估指标。我们还根据最近开发的语义相似性度量来评估我们的模型,即 BERTScore(Zhang 等人,2020b)和 MoverScore(Zhao 等人,2019)。
4.5 实验结果
CNNDM 数据集的结果如表 1 所示。 1.我们使用预训练的BART5作为基础生成模型(Origin)。我们使用 BART、Pegasus、GSum (Dou et al., 2021) 和 ProphetNet (Qi et al., 2020) 进行比较。值得注意的是,总是选择最佳候选者的 Max 预言机比原始输出具有更好的性能,这表明使用多样化的采样策略可以进一步利用预训练抽象系统的潜在能力。
除了 ROUGE 之外,我们还展示了语义相似度度量的评估结果。我们的方法在所有指标上都优于基线模型,证明其改进超出了利用 ROUGE 的潜在工件的范围。虽然用这些指标很难解释改进的规模,但我们注意到改进能够通过显着性检验。

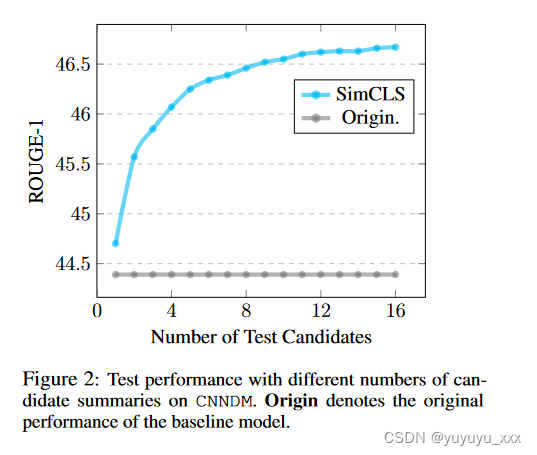
在计算能力的限制下,我们尝试使用尽可能多的候选者来进行评估模型训练。然而,我们也注意到我们的方法对于特定数量的候选者来说是稳健的,因为在测试过程中我们发现我们的模型仍然能够优于候选者较少的基线模型,如图 2 所示。
4.6 细粒度分析
4.6.1 实体级
受到 Gekhman 等人的工作的启发。 (2020)和贾恩等人。 (2020),我们比较了模型性能与显着实体,这些实体是出现在参考摘要中的源文档中的实体。具体来说,
(1)我们从源文档中提取实体,6
(2)根据参考摘要中的实体选择显着实体,
(3) 将显着实体与候选摘要中的实体进行比较。结果在选项卡中。图3表明我们的方法可以更好地捕获源文档的重要语义信息。
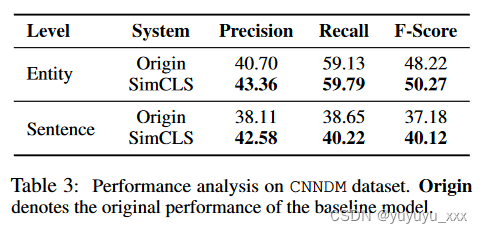
4.6.2 句子级
句子对齐在这里,我们研究我们的方法与基线模型相比是否存在句子级别的差异。具体来说,(1) 我们根据摘要中的每个句子与源文档中的句子的相似性(由 ROUGE 分数表示)进行匹配,7 (2) 根据以下条件计算参考摘要和系统生成的摘要之间的句子级相似度:源文档中匹配句子的重叠。结果如表所示。图 3 表明我们的方法生成的摘要与句子级别的参考摘要更相似。
选项卡中的位置偏差。 2、我们提出了句子对齐的案例研究。我们使用相同的匹配方法将摘要句子映射到源文章中的句子。在此示例中,我们方法的输出侧重于与参考摘要相同的句子,而基线摘要侧重于一些不同的句子。
有趣的是,参考摘要集中在文章的最后一句话,我们的方法可以遵循这种模式。在检查这种模式时,我们注意到在处理长源文章(超过30 句)。图 3 显示,与参考文献相比,基线摘要更有可能关注中心句,这可能是由于 Seq2Seq 模型的自回归生成过程造成的。我们的方法能够减轻这种偏差,因为候选采样过程(多样化波束搜索)生成的候选与原始输出不同,并且我们的评估模型可以评估候选的整体质量。
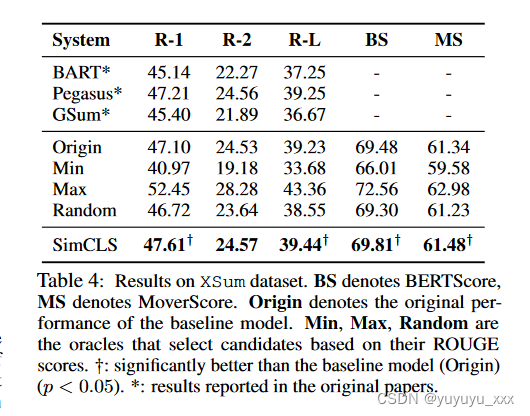
4.7 XSum 数据集的结果
为了评估我们的方法在 CNNDM 数据集之外的性能,我们还在 XSum 数据集上测试了我们的方法,结果如表 1 所示。 4. 这里,我们使用 Pegasus8 作为基础系统,因为它在 XSum 上比 BART 具有更好的性能。我们遵循相同的采样策略来生成训练数据。然而,由于此策略通常会导致 XSum 数据集上的 ROUGE-2 分数较低,因此我们使用不同的策略来生成验证和测试数据(由 4 个不同的组生成 4 个候选数据)。我们的方法仍然能够优于基线,但与 CNNDM 相比,差距较小。 XSum 中的摘要更短(一句话)且更抽象,这限制了候选者的语义多样性,并使做出有意义的改进变得更加困难。
五 总结
在这项工作中,我们提出了一个对比摘要框架,旨在优化摘要级别生成的摘要的质量,从而减少训练和测试之间的差异MLE 框架中的各个阶段。除了 CNNDM 数据集上的基线模型的显着改进之外,我们还提出了不同语义级别的综合评估,解释了我们的方法所取得的改进的来源。值得注意的是,我们的实验结果还表明,现有的抽象系统有可能生成比原始输出更好的候选摘要。因此,我们的工作为未来的方向开辟了可能性,包括
(1)将这种两阶段策略扩展到其他抽象模型数据集;
(2)改进抽象模型的训练算法,实现更全面的优化过程。





)






)



![[情商-6]:识别职场中、情侣之间的暗捧、暗拍、暗赞、暗赏,保持良好的关系](http://pic.xiahunao.cn/[情商-6]:识别职场中、情侣之间的暗捧、暗拍、暗赞、暗赏,保持良好的关系)

通过多模态信息瓶颈归因对图像文本表示的视觉解释)
