一、导入必要的模块:
这篇博客将介绍如何使用Python编写一个爬虫程序,从斗鱼直播网站上获取图片信息并保存到本地。我们将使用requests模块发送HTTP请求和接收响应,以及os模块处理文件和目录操作。
如果出现模块报错
进入控制台输入:建议使用国内镜像源
pip install requests -i https://mirrors.aliyun.com/pypi/simple
我大致罗列了以下几种国内镜像源:
清华大学
https://pypi.tuna.tsinghua.edu.cn/simple阿里云
https://mirrors.aliyun.com/pypi/simple/豆瓣
https://pypi.douban.com/simple/ 百度云
https://mirror.baidu.com/pypi/simple/中科大
https://pypi.mirrors.ustc.edu.cn/simple/华为云
https://mirrors.huaweicloud.com/repository/pypi/simple/腾讯云
https://mirrors.cloud.tencent.com/pypi/simple/
二、发送GET请求获取响应数据:
设置了请求头部信息,以模拟浏览器的请求,函数返回响应数据的JSON格式内容。
def get_html(url):header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}response = requests.get(url=url, headers=header)# print(response.json())html = response.json()return html如何获取请求头:
火狐浏览器:
- 打开目标网页并右键点击页面空白处。
- 选择“检查元素”选项,或按下快捷键Ctrl + Shift + C(Windows)
- 在开发者工具窗口中,切换到“网络”选项卡。
- 刷新页面以捕获所有的网络请求。
- 在请求列表中选择您感兴趣的请求。
- 在右侧的“请求标头”或“Request Headers”部分,即可找到请求头信息。
将以下请求头信息复制出来即可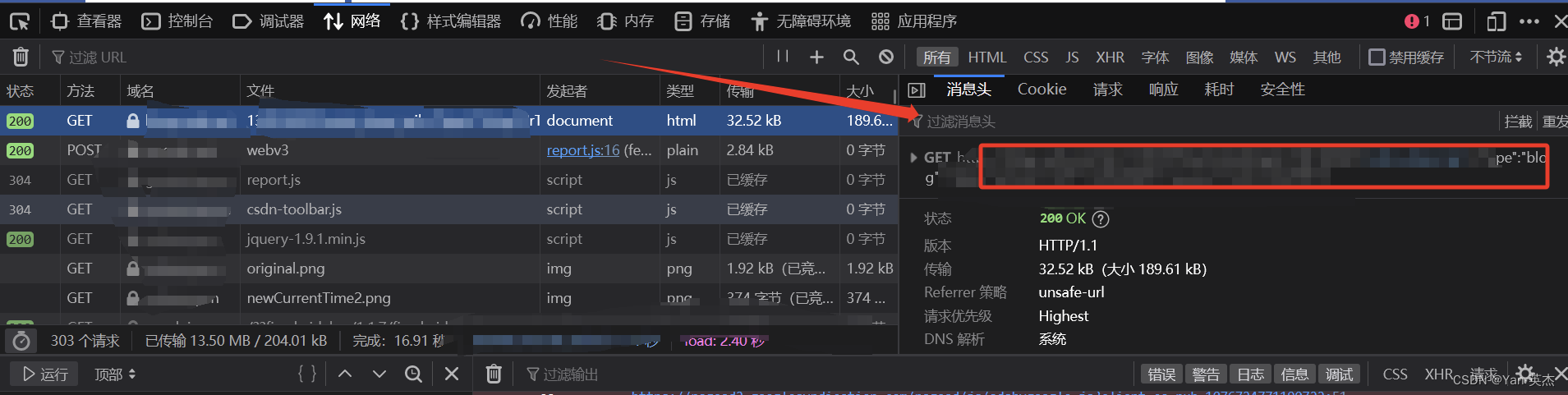
3.解析响应数据中的图片信息
用于解析响应数据中的图片信息。通过分析响应数据的结构,提取出每个图片的URL和标题,并将其存储在一个字典中,然后将所有字典组成的列表返回。
def parse_html(html):image_info_list = []for item in html['data']:image_url = item['image_url']title = item['title']image_info = {'url': image_url, 'title': title}image_info_list.append(image_info)return image_info_list4.保存图片到本地:
用于保存图片到本地。首先创建一个目录"directory",如果目录不存在的话。然后遍历图片信息列表,依次下载每个图片并保存到目录中,图片的文件名为标题加上".jpg"后缀。
def save_to_images(img_info_list):directory = 'images'if not os.path.exists(directory):os.makedirs(directory)for img_info in img_info_list:image_url = img_info['url']title = img_info['title']response = requests.get(image_url)with open(os.path.join(directory, f'{title}.jpg'), 'wb') as f:f.write(response.content)

源码:
如果你对互联网变现感兴趣:可以关注:https://bbs.csdn.net/topics/617804998
#导入了必要的模块requests和os
import requests
import os# 定义了一个函数get_html(url),
# 用于发送GET请求获取指定URL的响应数据。函数中设置了请求头部信息,
# 以模拟浏览器的请求。函数返回响应数据的JSON格式内容
def get_html(url):header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}response = requests.get(url=url, headers=header)# print(response.json())html = response.json()return html# 定义了一个函数parse_html(html),
# 用于解析响应数据中的图片信息。通过分析响应数据的结构,
# 提取出每个图片的URL和标题,并将其存储在一个字典中,然后将所有字典组成的列表返回
def parse_html(html):rl_list = html['data']['rl']# print(rl_list)img_info_list = []for rl in rl_list:img_info = {}img_info['img_url'] = rl['rs1']img_info['title'] = rl['nn']# print(img_url)# exit()img_info_list.append(img_info)# print(img_info_list)return img_info_list# 定义了一个函数save_to_images(img_info_list),用于保存图片到本地。
# 首先创建一个目录"directory",如果目录不存在的话。然后遍历图片信息列表,
# 依次下载每个图片并保存到目录中,图片的文件名为标题加上".jpg"后缀。
def save_to_images(img_info_list):dir_path = 'directory'if not os.path.exists(dir_path):os.makedirs(dir_path)for img_info in img_info_list:img_path = os.path.join(dir_path, img_info['title'] + '.jpg')res = requests.get(img_info['img_url'])res_img = res.contentwith open(img_path, 'wb') as f:f.write(res_img)# exit()#在主程序中,设置了要爬取的URL,并调用前面定义的函数来执行爬取、解析和保存操作。
if __name__ == '__main__':url = 'https://www.douyu.com/gapi/rknc/directory/yzRec/1'html = get_html(url)img_info_list = parse_html(html)save_to_images(img_info_list)效果图:

【文末送书】
如果你对免费获取图书感兴趣:https://bbs.csdn.net/topics/617804998

内容简介
《Python网络爬虫从入门到精通》从初学者角度出发,通过通俗易懂的语言、丰富多彩的实例,详细介绍了使用Python实现网络爬虫开发应该掌握的技术。全书共分19章,内容包括初识网络爬虫、了解Web前端、请求模块urllib、请求模块urllib3、请求模块requests、高级网络请求模块、正则表达式、XPath解析、解析数据的BeautifulSoup、爬取动态渲染的信息、多线程与多进程爬虫、数据处理、数据存储、数据可视化、App抓包工具、识别验证码、Scrapy爬虫框架、Scrapy_Redis分布式爬虫、数据侦探。书中所有知识都结合具体实例进行介绍,涉及的程序代码给出了详细的注释,读者可轻松领会网络爬虫程序开发的精髓,快速提高开发技能。
作者简介
明日科技,全称是吉林省明日科技有限公司,是一家专业从事软件开发、教育培训以及软件开发教育资源整合的高科技公司,其编写的教材非常注重选取软件开发中的必需、常用内容,同时也很注重内容的易学、方便性以及相关知识的拓展性,深受读者喜爱。其教材多次荣获“全行业优秀畅销品种”“全国高校出版社优秀畅销书”等奖项,多个品种长期位居同类图书销售排行榜的前列。
购买链接:https://item.jd.com/13291912.html
参与活动
1️⃣参与方式:关注、点赞、收藏,评论(人生苦短,我用python)
2️⃣获奖方式:程序随机抽取 3位,每位小伙伴将获得一本书
3️⃣活动时间:截止到 2023-12-31 22:00:00



覆盖优化 - 附代码)





)
)




)



